

参照カラムを指定し、この列に基づいて、他の列をマージします。
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '003'],
'num1': [120, 101, 104],
'num2': [110, 102, 121],
'num3': [105, 120, 113]})
df2 = pd.DataFrame({'id': ['001', '002', '003'],
'num4': [80, 86, 79]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")
df_merge = pd.merge(df1, df2, on='id')
print(df_merge)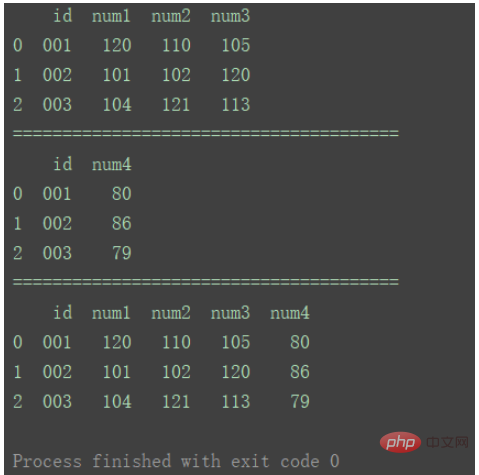
このマージを実現するには、インデックスを使用して、つまりインデックス列に基づいてマージすることもできます。 left_index と right_index の両方を True
に設定するだけです。 (left_index と right_index の両方のデフォルトは False です。left_index は、左側のテーブルが左側のテーブル データのインデックスに基づいていることを意味し、right_index は、右側のテーブルが右側のテーブル データのインデックスに基づいていることを意味します。)
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '003'],
'num1': [120, 101, 104],
'num2': [110, 102, 121],
'num3': [105, 120, 113]})
df2 = pd.DataFrame({'id': ['001', '002', '003'],
'num4': [80, 86, 79]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")
df_merge = pd.merge(df1, df2, left_index=True, right_index=True)
print(df_merge)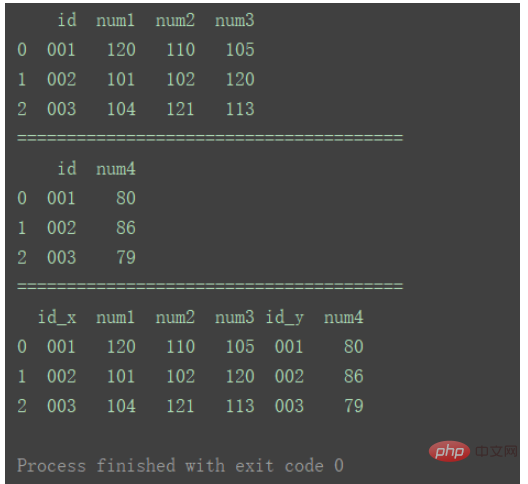
方法①と比較すると、図に示すように、方法②でマージされたデータには重複する列が存在することが異なります。
pd.merge(right,how=‘inner’, on=“なし”, left_on=“なし”, right_on=“なし”, left_index= False、right_index=False )
| パラメータ | 説明 |
|---|---|
| left | 左のテーブル、マージされたオブジェクト、DataFrame または Series |
| right | 右のテーブル、マージされたオブジェクト、DataFrame または Series |
| 方法 | マージ方法には、左 (左マージ)、右 (右マージ)、外側 (外側マージ)、内側 (内側マージ) があります。 | on
| left_on | |
| right_on | |
| left_index | |
| right_index | |
マージ メソッド left right external inner
新しいデータ セットの準備:
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '003'],
'num1': [120, 101, 104],
'num2': [110, 102, 121],
'num3': [105, 120, 113]})
df2 = pd.DataFrame({'id': ['001', '004', '003'],
'num4': [80, 86, 79]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")#inner (デフォルト) 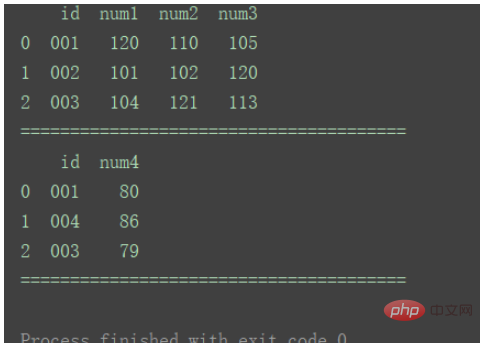
両方のデータセットのキーの共通部分を使用します
df_merge = pd.merge(df1, df2, on='id') print(df_merge)
outer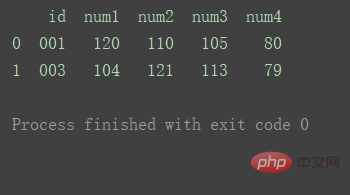
両方のデータセットのキーの結合を使用する
df_merge = pd.merge(df1, df2, on='id', how="outer") print(df_merge)
left
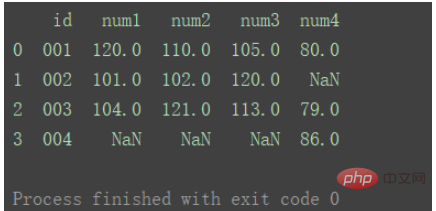 左のデータ セットのキーを使用
左のデータ セットのキーを使用
df_merge = pd.merge(df1, df2, on='id', how='left') print(df_merge)
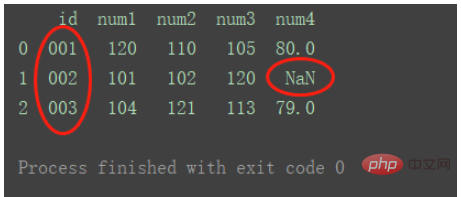 右のデータ セットのキーを使用
右のデータ セットのキーを使用
df_merge = pd.merge(df1, df2, on='id', how='right') print(df_merge)
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '003'],
'num1': [120, 101, 104],
'num2': [110, 102, 121],
'num3': [105, 120, 113]})
df2 = pd.DataFrame({'id': ['001', '001', '003'],
'num4': [80, 86, 79]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")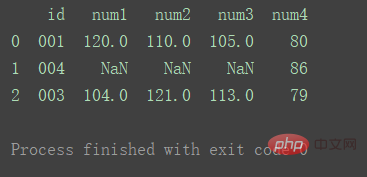 図に示すように、df2 には重複した id1 データがあります。
図に示すように、df2 には重複した id1 データがあります。 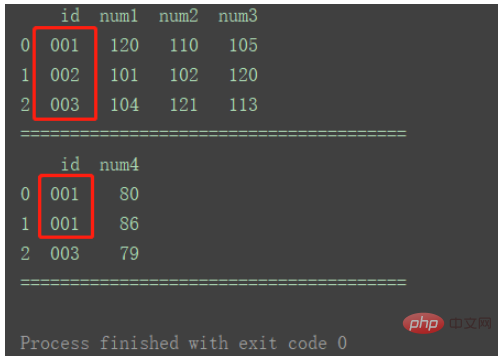 Merge
Merge
df_merge = pd.merge(df1, df2, on='id') print(df_merge)
マージされた結果は次の図に示すとおりです。
データを使用するデフォルトの Inner メソッドに従います。 2 つのデータセットからのキーの共通部分。また、重複キーを持つ行はマージ結果に複数の行として反映されます。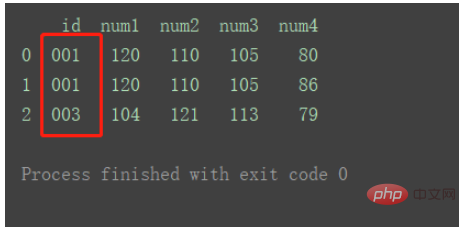 3. 多対多のマージ
3. 多対多のマージ
たとえば、グラフ 1 と表 2 の両方に、重複する ID を持つ複数の行があります。
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '002', '002', '003'],
'num1': [120, 101, 104, 114, 123],
'num2': [110, 102, 121, 113, 126],
'num3': [105, 120, 113, 124, 128]})
df2 = pd.DataFrame({'id': ['001', '001', '002', '003', '001'],
'num4': [80, 86, 79, 88, 93]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")df_merge = pd.merge(df1, df2, on='id') print(df_merge)
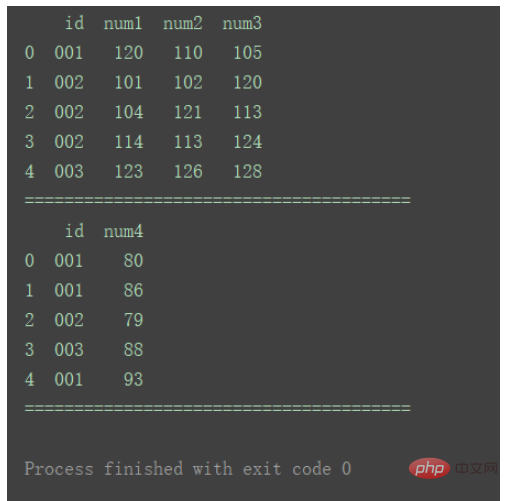
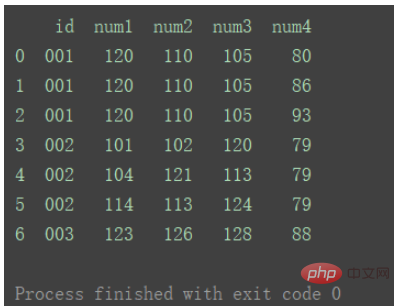
パラメータ
| axis | |
| #join | |
| ignore_index | |
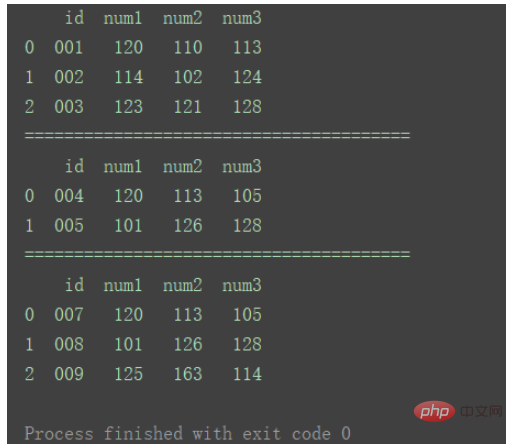
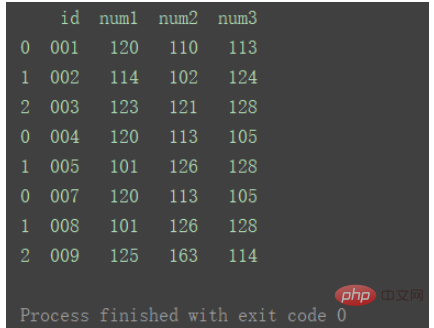
其他重要参数通过实例说明。 1.相同字段的表首位相连首先准备三组DataFrame数据: import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '003'],
'num1': [120, 114, 123],
'num2': [110, 102, 121],
'num3': [113, 124, 128]})
df2 = pd.DataFrame({'id': ['004', '005'],
'num1': [120, 101],
'num2': [113, 126],
'num3': [105, 128]})
df3 = pd.DataFrame({'id': ['007', '008', '009'],
'num1': [120, 101, 125],
'num2': [113, 126, 163],
'num3': [105, 128, 114]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")
print(df3)ログイン後にコピー
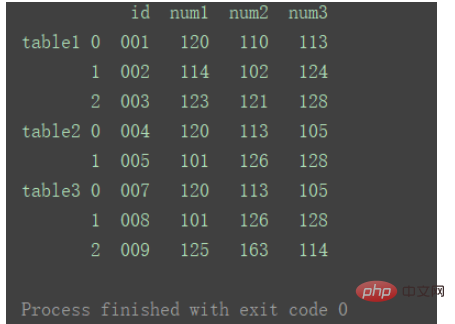
合并 dfs = [df1, df2, df3] result = pd.concat(dfs) print(result) ログイン後にコピー
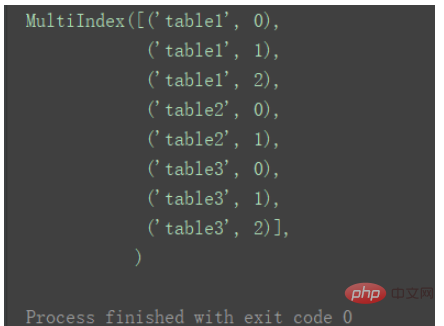
如果想要在合并后,标记一下数据都来自于哪张表或者数据的某类别,则也可以给concat加上 参数keys 。 result = pd.concat(dfs, keys=['table1', 'table2', 'table3']) print(result) ログイン後にコピー
此时,添加的keys与原来的index组成元组,共同成为新的index。 print(result.index) ログイン後にコピー
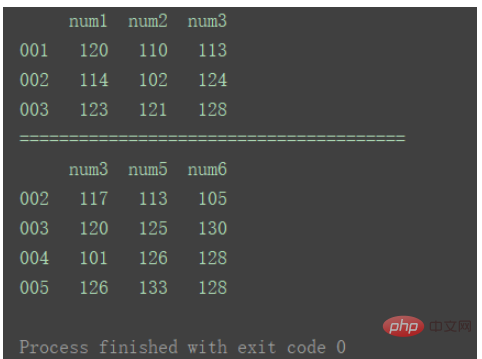
2.横向表合并(行对齐)准备两组DataFrame数据: import pandas as pd
df1 = pd.DataFrame({'num1': [120, 114, 123],
'num2': [110, 102, 121],
'num3': [113, 124, 128]}, index=['001', '002', '003'])
df2 = pd.DataFrame({'num3': [117, 120, 101, 126],
'num5': [113, 125, 126, 133],
'num6': [105, 130, 128, 128]}, index=['002', '003', '004', '005'])
print(df1)
print("=======================================")
print(df2)ログイン後にコピー
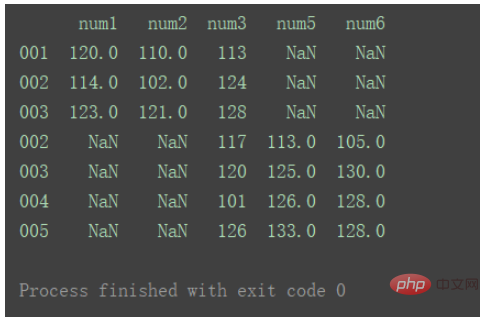
当axis为默认值0时: result = pd.concat([df1, df2]) print(result) ログイン後にコピー
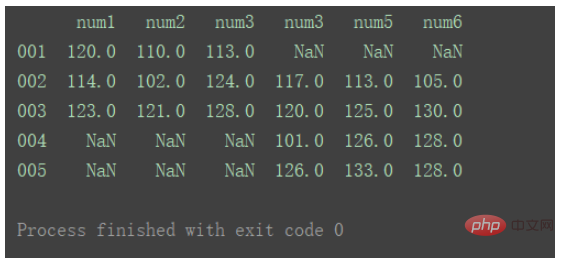
横向合并需要将axis设置为1 : result = pd.concat([df1, df2], axis=1) print(result) ログイン後にコピー
对比以上输出差异。
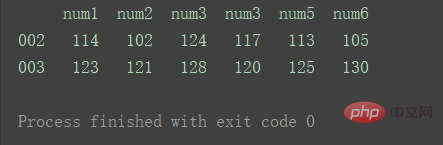
3.交叉合并result = pd.concat([df1, df2], axis=1, join='inner') print(result) ログイン後にコピー
以上がPython で DataFrame を使用してデータをマージおよび結合するにはどうすればよいですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。 このウェブサイトの声明
この記事の内容はネチズンが自主的に寄稿したものであり、著作権は原著者に帰属します。このサイトは、それに相当する法的責任を負いません。盗作または侵害の疑いのあるコンテンツを見つけた場合は、admin@php.cn までご連絡ください。
著者別の最新記事
最新の問題
関連トピック
詳細>
|
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



