Python を使用してテキスト データを処理する
実験の目的
Python の基本的なデータ構造とファイルの入出力について理解します。
実験データ
xxxx での xx 機械学習カンファレンスの評価データと評価タスクを使用します。データにはトレーニング セットとテスト セットが含まれます。評価タスクは次のとおりです。指定されたトレーニング データを渡し、テスト セット内の関係が正の例か負の例かを予測し、各サンプルの最後に 1 または 0 を与えます。
データは次のように記述されます。最初の列は関係のタイプ、2 番目と 3 番目の列は人物の名前、4 番目の列はタイトル、5 番目の列は関係が肯定的であるかどうかです。または負の例、1 は正の例、0 は負の例、6 列目はトレーニング セットを表します。
| イベント |
文字 1 |
文字 2 |
タイトル |
関係 (0 または 1) ) |
トレーニング セット |
テスト セットは次のように説明されます。形式は基本的にトレーニング セットと似ています。唯一の違いは、5 列目であることです。正の例でも負の例でも構いません。
関係 | キャラクター 1 | キャラクター 2 | イベント |
実験内容
最初の 5 列のみを残してトレーニング セット データを処理すると、出力テキストの名前は exp1_1.txt になります。
最初のステップで取得したデータに基づいて、19 種類の関係を分類します。生成されたテキストは、exp1_train フォルダーに保存されます。関係カテゴリの出現順序に従って、最初の関係カテゴリのデータは、 2 番目の関係カテゴリは 1.txt に保存され、19.txt までは 2.txt に保存されます。
テスト セットは、トレーニング セットの 19 カテゴリの順序で関係カテゴリに従って各サンプルを分類します。つまり、同じ関係タイプのデータがテキスト ファイルに置かれ、テスト ファイルが19 カテゴリも生成されますが、形式は同じです。テスト ファイルと一貫性があります。 exp1_test フォルダーに保存されている各カテゴリのファイルは、引き続き 1_test.txt、2_test.txt... という名前が付けられます。同時に、元のテスト セット内の各サンプルの位置が記録され、19 個のテスト ファイルに対応します。一つ。たとえば、原文の最初の種類の「噂の不仲説」の各サンプルの行は、インデックス ファイルに記録され、index1.txt、index2.txt...
## というファイルに保存されます。 #解決策の質問のアイデア
1. 最初の質問は、ファイル操作とリストに関する知識をテストすることです。主な困難は、新しいファイルを読み取ることです。要件に従って処理した後、 txt ファイルを参照してください。具体的なコード実装を見てみましょう: import os
# 创建一个列表用来存储新的内容
list = []
with open("task1.trainSentence.new", "r",encoding='xxx') as file_input: # 打开.new文件,xxx根据自己的编码格式填写
with open("exp1_1.txt", "w", encoding='xxx') as file_output: # 打开exp1_1.txt,xxx根据自己的编码格式填写文件如果没有就创建一个
for Line in file_input: # 遍历每一行的文件
arr = Line.split('\t') # 以\t为分隔符读取
if arr[0] not in list: # if the word is not in the list
list.append(arr[0]) # add the word to the list
file_output.write(arr[0]+"\t"+arr[1]+"\t"+arr[2]+"\t"+arr[3]+"\t"+arr[4]+"\n") # write the line to the file
file_input.close() #关闭.new文件
file_output.close() #关闭创建的txt文件ログイン後にコピー
コード実装
import os
file_1 = open("exp1_1.txt", encoding='xxx') # 打开文件,xxx根据自己的编码格式填写
os.mkdir("exp1_train") # 创建目录
os.chdir("exp1_train") # 修改进程的工作目录(使用该目录)
a = file.readline() # 按行读取exp1_1.txt文件
arr = a.split("\t") # 按\t间隔符作为分割
b = 1 #设置分组文件的序列
file_2 = open("{}.txt".format(b), "w", encoding="xxx") # 打开文件,xxx根据自己的编码格式填写
for line in file_1: # 按行读取文件
arr_1 = line.split("\t") # 按\t间隔符作为分割
if arr[0] != arr_1[0]: # 如果读取文件的第一列内容与存入新文件的第一列类型不同
file_2.close() # 关掉该文件
b += 1 # 文件序列加一
f_2 = open("{}.txt".format(b), "w", encoding="xxx") # 创建新文件,以另一种类型分类,xxx根据自己的编码格式填写
arr = line.split("\t") # 按\t间隔符作为分割
f_2.write(arr[0]+"\t"+arr[1]+"\t"+arr[2]+"\t"+arr[3]+"t"+arr[4]+"\t""\n") # 将相同类型的文件写入
f_1.close() # 关闭题目一创建的exp1_1.txt文件
f_2.close() # 关闭创建的最后一个类型的文件ログイン後にコピー
import os
with open("exp1_1.txt", encoding='xxx') as file_in1: # 打开文件,xxx根据自己的编码格式填写
i = 1 # 类型序列
arr2 = {} # 创建字典
for line in file_in1: # 按行遍历
arr3 = line[0:2] # 读取关系
if arr3 not in arr2.keys():
arr2[arr3] = i
i += 1 # 类型+1
file_in = open("task1.test.new") # 打开文件task1.test.new
os.mkdir("exp1_test") # 创建目录
os.chdir("exp1_test") # 修改进程的工作目录(使用该目录)
for line in file_in:
arr = line[0:2]
with open("{}_test.txt".format(arr2[arr]), "a", encoding='xxx') as file_out:
arr = line.split('\t')
file_out.write(line)
i = 1
file_in.seek(0)
os.mkdir("exp1_index")
os.chdir("exp1_index")
for line in file_in:
arr = line[0:2]
with open("index{}.txt".format(arr2[arr]), "a", encoding='xxx') as file_out:
arr = line.split('\t')
line = line[0:-1]
file_out.write(line + '\t' + "{}".format(i) + "\n")
i += 1ログイン後にコピー
実験目的
Python の基本的なデータ構造と入出力について理解するファイルの。 実験データ
XXXXのXX Tianchi Competitionは、中国の大学のXX回ビッグデータチャレンジのデータでもあります。データには、ユーザー行動テーブル mars_tianchi_user_actions.csv とソング アーティスト テーブル mars_tianchi_songs.csv の 2 つのテーブルが含まれています。このコンテストでは、サンプリングされた楽曲アーティスト データと、これらのアーティストに関連する 6 か月以内のユーザー行動履歴記録 (20150301 ~ 20150831) が公開されます。出場者は、アーティストの今後 2 か月間、つまり 60 日間 (20150901 ~ 20151030) の再生データを予測する必要があります。 
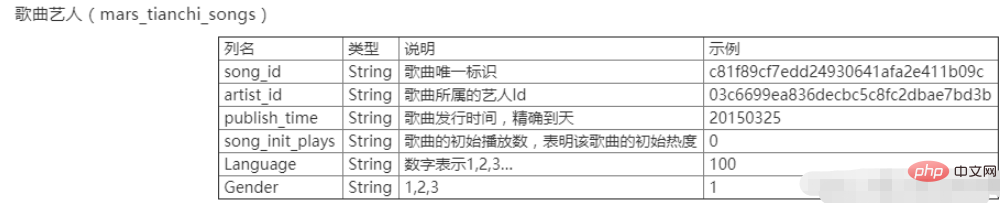

##実験内容
曲のアーティスト データ mars_tianchi_songs を処理し、アーティスト数と各アーティストの曲数をカウントします。出力ファイルの形式は exp2_1.csv で、最初の列はアーティスト ID、2 列目はアーティスト別の曲数です。最後の行はアーティストの数を出力します。
1.
(1) .drop_duplicates() を使用して重複する値を削除します
(2) .loc[:,‘artist_id’].value_counts() を使用して、歌手がリピートする回数、つまり各歌手の曲数を確認します
(3 ) .loc[:,‘ songs_id’].value_counts() を使用して重複する曲がないかどうかを確認します
import pandas as pd
data = pd.read_csv(r"C:\mars_tianchi_songs.csv") # 读取数据
Newdata = data.drop_duplicates(subset=['artist_id']) # 删除重复值
artist_sum = Newdata['artist_id'].count()
#artistChongFu_count = data.duplicated(subset=['artist_id']).count() artistChongFu_count = data.loc[:,'artist_id'].value_counts() 重复次数,即每个歌手的歌曲数目
songChongFu_count = data.loc[:,'songs_id'].value_counts() # 没有重复(歌手)
artistChongFu_count.loc['artist_sum'] = artist_sum # 没有重复(歌曲)artistChongFu_count.to_csv('exp2_1.csv') # 输出文件格式为exp2_1.csv
ログイン後にコピー
merge() を使用して 2 つのテーブルをマージします
import pandas as pd import os
data = pd.read_csv(r"C:\mars_tianchi_songs.csv")
data_two = pd.read_csv(r"C:\mars_tianchi_user_actions.csv")
num=pd.merge(data_two, data) num.to_csv('exp2_2.csv')
ログイン後にコピー
groupby() を使用します[].sum() 繰り返し加算
import pandas as pd
data =pd.read_csv('exp2_2.csv')
DataCHongfu = data.groupby(['artist_id','Ds'])['gmt_create'].sum()#重复项相加DataCHongfu.to_csv('exp2_3.csv')
ログイン後にコピー
以上がPythonを使用してテキストデータを操作するにはどうすればよいですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



