

Institute of Automationが開発した非侵襲的なマルチモーダル学習モデルは、脳信号のデコードと意味解析を実現します


- 紙のアドレス: https://ieeexplore.ieee.org/document/10089190
- #コード アドレス: https://github.com/ChangdeDu/BraVL ##データ アドレス: https:// figshare。 com/articles/dataset/BraVL/17024591
- ##長すぎてバージョンを読むことができません
を解読することが可能です。この記事は、3 つの「脳-絵-テキスト」3 モーダル マッチング データ セット にも貢献します。 実験結果は、いくつかの興味深い結論と認知的洞察を示しています: 1) 人間の脳活動から新しい視覚カテゴリを解読することは高精度で達成可能; 2) 視覚的特徴と言語的特徴を組み合わせた解読モデルを使用する1 つだけを使用したモデルよりも優れたパフォーマンスを発揮する; 3) 視覚知覚には、視覚刺激の意味論を表すための言語的影響が伴う可能性があります。これらの発見は、人間の視覚システムの理解を明らかにするだけでなく、将来の脳とコンピューターのインターフェース技術に新しいアイデアを提供します。この研究のコードとデータセットはオープンソースです。
研究の背景
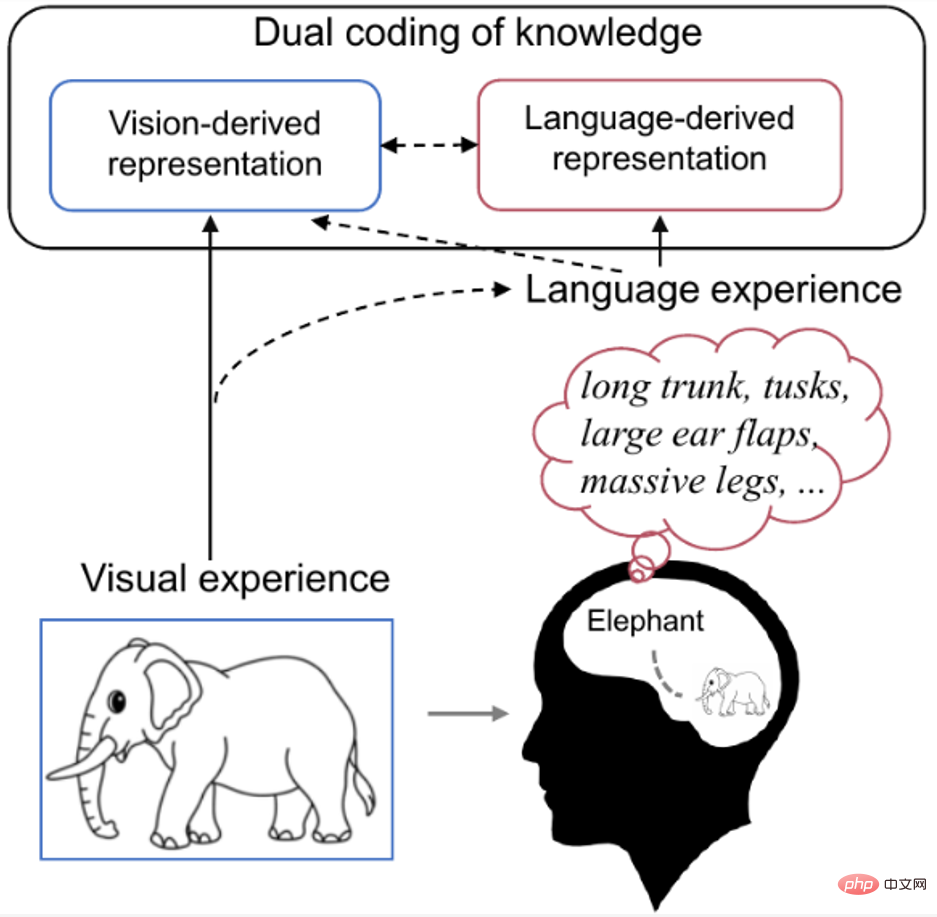
人間の視覚神経表現の解読は、視覚処理メカニズムを解明し、脳科学と人工知能の発展を促進できる重要な科学的意義を持つ課題です。 。ただし、現在のニューラル デコード方法は、トレーニング データを超えて新しいカテゴリに一般化することが困難です。. 主な理由は 2 つあります: まず、既存の方法では、ニューラルの背後にある多くの機能が十分に活用されていません。第二に、利用可能なペアリング (刺激と脳の反応) のトレーニング データがほとんどありません。 研究によると、人間の視覚刺激の知覚と認識は、視覚的特徴と人間の過去の経験の影響を受けることがわかっています。たとえば、見慣れた物体を見ると、私たちの脳は自然にその物体に関連する知識を検索します。以下の図 1 に示すように、二重コーディング理論に関する認知神経科学研究 [9] では、特定の概念が視覚と言語の両方で脳内にエンコードされており、効果的な事前経験としての言語が視覚によって生成される表現を形成するのに役立つと考えられています。
したがって、著者は、記録された脳信号をより適切に解読するには、実際に提示された視覚的意味論的特徴を使用するだけでなく、視覚的対象オブジェクトに関連するより豊富な特徴も使用する必要があると考えています。デコードは、言語的な意味論的特徴の組み合わせによって実行されます。
以下の図 2 に示すように、さまざまな視覚カテゴリの人間の脳活動を収集するのは非常にコストがかかるため、研究者は通常、視覚に関する非常に限られた脳活動のみを収集しています。カテゴリー。ただし、画像やテキスト データは豊富にあり、追加の有用な情報を提供できます。
この記事の方法では、あらゆる種類のデータ (三峰性、二峰性、単峰性) を最大限に活用して、ニューラル デコーディングの汎化能力を向上させることができます。
図 2. 画像刺激、誘発された脳活動、およびそれらに対応するテキスト データ。脳活動データはいくつかのカテゴリについてしか収集できませんが、画像やテキスト データはほぼすべてのカテゴリについて簡単に収集できます。したがって、既知のカテゴリの場合は、脳活動、視覚的画像、および対応するテキストの説明がすべてトレーニングに利用できると想定しますが、新しいカテゴリの場合は、視覚的画像とテキストの説明のみがトレーニングに利用できます。テストデータは、新しいカテゴリの脳活動データです。
「脳-絵-テキスト」マルチモーダル学習
以下の図 3A に示すように、この方法の鍵は以下を組み合わせることです。各モデル 学習された分布は、新しいカテゴリに関連する重要なマルチモーダル情報を含む共有潜在空間に整列されます。
#具体的には、著者は、#マルチモーダル自動エンコーディング変分ベイジアン学習フレームワーク## を提案します。 -Products-of-Experts (MoPoE) モデルを使用して潜在エンコーディングを推論し、3 つすべてのモダリティの共同生成を実現します。脳活動データが限られている場合に、より関連性の高い結合表現を学習し、データ効率を向上させるために、著者らはさらに、モーダル内およびモーダル間の相互情報量正則化項を導入しています。さらに、BraVL モデルは、さまざまな半教師あり学習シナリオの下でトレーニングして、大規模な画像カテゴリの追加の視覚的およびテキスト的特徴を組み込むことができます。 #図 3B では、著者らは
#新しいカテゴリの視覚的およびテキスト的特徴の潜在表現から SVM 分類器をトレーニングしています#。このステップではエンコーダ E_v と E_t がフリーズされ、SVM 分類器 (グレー モジュール) のみが最適化されることに注意してください。 図 3C に示すように、このアプリケーションでは、このメソッドの 入力は新しいカテゴリの脳信号のみであり、他のデータ は必要ありません。大規模なほとんどのニューラル デコーディング シナリオに簡単に適用できます。これら 3 つのモダリティの基礎となる表現が A ですでに調整されているため、SVM 分類器は (B) から (C) まで一般化できます。
 図 3 この記事で提案する「脳・絵・テキスト」の 3 モーダル共同学習フレームワーク、BraVLと呼ばれます。
図 3 この記事で提案する「脳・絵・テキスト」の 3 モーダル共同学習フレームワーク、BraVLと呼ばれます。
さらに、同じ視覚刺激であっても、脳信号は試行ごとに変化します。ニューラル デコーディングの安定性を向上させるために、著者らは安定性選択法を使用して fMRI データを処理しました。すべてのボクセルの安定性スコアを以下の図 4 に示します。著者は、ニューラル デコード プロセスに参加するために、最も安定性の高いボクセルの上位 15% を選択しました。この操作により、脳の特徴の識別能力に重大な影響を与えることなく、fMRI データの次元を効果的に削減し、ノイズの多いボクセルによって引き起こされる干渉を抑制できます。
 # 図 4. 脳の視覚野のボクセル活動安定性スコア マップ。
# 図 4. 脳の視覚野のボクセル活動安定性スコア マップ。
# 既存のニューラル エンコードおよびデコード データ セットには、多くの場合、画像刺激と脳反応のみが含まれています。視覚的概念に対応する言語的記述を取得するために、著者は半自動の Wikipedia 記事抽出方法 # を採用しました。
具体的には、作成者はまず、ImageNet クラスとそれに対応する Wikipedia ページの自動マッチングを作成します。このマッチングは、ImageNet クラスと Wikipedia タイトルの構文単語間の類似性に基づいています。それらの親カテゴリ。以下の図 5 に示すように、残念ながら、同じ名前のクラスが非常に異なる概念を表す可能性があるため、この種のマッチングでは誤検知が発生する場合があります。三峰性データセットを構築する際、視覚的特徴と言語的特徴の間の高品質な一致を保証するために、著者は一致しない記事を手動で削除しました。
#図 5. 半自動の視覚的概念説明の取得
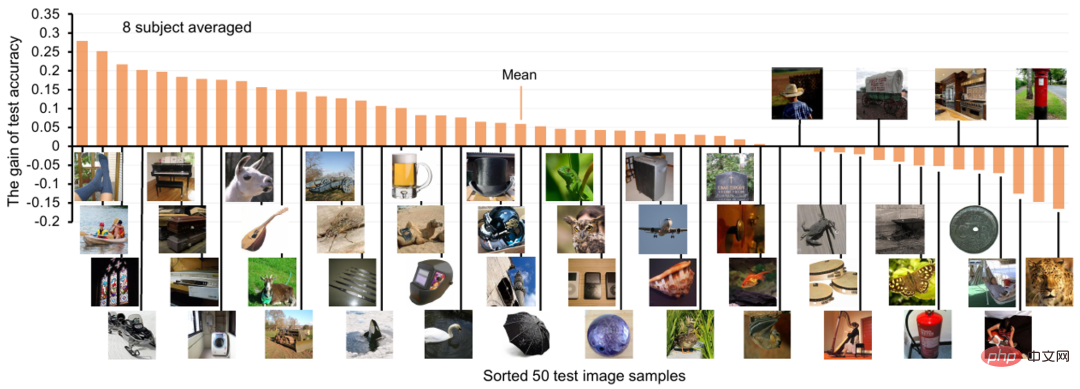
実験結果著者「脳-画像-テキスト」の 3 モーダル マッチング データ セットに対して、広範なゼロショット ニューラル デコード実験が複数回行われ、実験結果が以下の表に示されています。ご覧のとおり、ビジュアル機能とテキスト機能 (V&T) を組み合わせて使用する モデルは、どちらか一方を単独で使用するモデルよりもはるかに優れたパフォーマンスを発揮します。特に、V&T 機能に基づく BraVL は、両方のデータセットのトップ 5 の平均精度を大幅に向上させます。これらの結果は、被験者に提示された刺激には視覚情報のみが含まれているにもかかわらず、被験者は無意識のうちに適切な言語表現を呼び出し、それによって視覚処理に影響を与えていると考えられることを示唆しています。 各ビジュアル コンセプト カテゴリについて、著者らは、以下の図 6 に示すように、テキスト機能を追加した後のニューラル デコード精度の向上も示しています。ほとんどのテスト クラスでは、テキスト機能の追加がプラスの影響を及ぼし、トップ 1 の平均デコード精度が約 6% 向上していることがわかります。
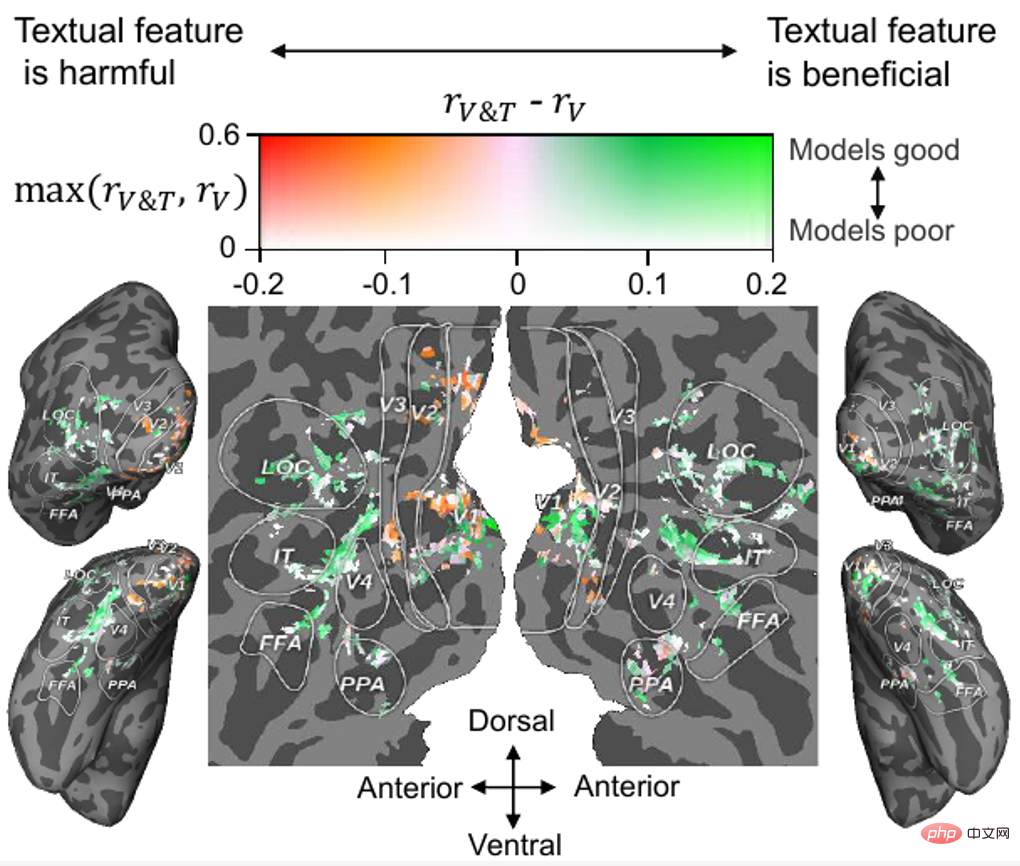
#著者らは、ニューラル デコーディング分析に加えて、ボクセル レベルのニューラル エンコーディング (視覚的または視覚的情報に基づいて対応する脳を予測する) における テキスト特徴の寄与も分析しました。テキスト フィーチャー ボクセル アクティビティ)
、結果を図 7 に示します。ほとんどの高レベル視覚野 (FFA、LOC、IT などの HVC) では、視覚特徴に基づいてテキスト特徴を融合することで脳活動の予測精度が向上することがわかりますが、ほとんどの低レベル視覚野では(LVC、V1、V2、V3 など)、テキスト機能の融合は有益ではなく、有害ですらあります。 認知神経科学の観点から見ると、HVC はオブジェクトのカテゴリ情報や運動情報などのより高次の意味情報の処理を担当していると一般に考えられているため、今回の結果は合理的です。 LVC は、方向や概要などの低レベルの情報の処理を担当します。さらに、最近の神経科学的研究では、視覚的および言語的意味表現が人間の視覚野の境界で整列していることが判明しており(すなわち、「意味的整列仮説」)[10]、著者の実験結果もこの仮説を裏付けています
その他の実験結果については、原文を参照してください。
全体として、この論文はいくつかの興味深い結論と認知的洞察を導き出します: 1) 人間の脳活動から新しい視覚カテゴリーを解読することは高精度で達成可能です; 2) 視覚と視覚の組み合わせを使用してモデルを解読します。言語特徴は、どちらか一方を単独で使用したモデルのデコードよりもはるかに優れたパフォーマンスを発揮します; 3) 視覚刺激の意味論を表すために、視覚認識には言語の影響が伴う可能性があります; 4) 概念の説明として自然言語を使用すると、クラス名を使用するよりも高いニューラル デコード パフォーマンスが得られます; 5 ) 単峰性と双峰性の両方でデータを追加すると、デコード精度が大幅に向上します。
議論と展望この論文の筆頭著者であり、中国科学院オートメーション研究所の特別研究助手であるDu Changde氏は次のように述べています。研究では、脳活動、視覚的画像、およびテキストが説明で抽出された特徴が神経信号の解読に有効であることが確認されています。ただし、抽出された視覚的特徴は人間の視覚処理のすべての段階を正確に反映しているとは限らず、より優れた特徴セットが完成に役立ちます。たとえば、より大きな事前トレーニング済み言語モデル (GPT-3 など) は、ゼロショット汎化の能力がより高いテキスト特徴を抽出するために使用されます。さらに、ウィキペディアの記事には豊富な視覚情報が含まれていますが、この情報はこの問題は、視覚的な文章を抽出したり、ChatGPT や GPT-4 などのモデルを使用してより正確で豊富な視覚的な説明を収集したりすることで解決できます。 「比較的多くの三峰性データを使用しました。より大規模でより多様なデータセットはより有益です。これらの側面は将来の研究に任せます。」
この論文の責任著者である中国科学院オートメーション研究所の研究員He Huiguang氏は、「この論文で提案されている方法には、3つの潜在的な用途がある。1) ニューラル意味解読ツールとして」と指摘した。 , この方法は、人間の脳の新しいタイプの意味情報の読み取りに使用されます。神経補綴装置の開発において重要な役割を果たします。このアプリケーションはまだ成熟していませんが、この記事の方法はその技術的基盤を提供します。 2) モダリティ全体で脳活動を推測することにより、この記事の方法は、人間の大脳皮質で視覚および言語の特徴がどのように表現されるかを研究するために使用され、どの脳領域がマルチモーダルな特性を持っているかを明らかにする、ニューラルコーディングツールとしても使用できます。 3) AI モデルの内部表現の神経解読可能性は、モデルの脳のようなレベルの指標とみなすことができるため、本稿の方法も使用できます。どのモデル (視覚的または言語) 表現が人間の脳の活動に近いかをテストする脳のような特性評価ツールとして、研究者がより脳に似たコンピューティング モデルを設計する動機になります。神経情報のエンコードとデコードは、ブレインコンピューターインターフェースの分野の中核課題であり、人間の脳の複雑な機能の背後にある原理を探求し、脳のような知能の発達を促進する効果的な方法でもあります。 Institute of Automation のニューラル コンピューティングおよびブレイン コンピューター インタラクション研究チームは、この分野で長年取り組んできており、一連の研究成果を発表しており、それらは TPAMI 2023、TMI2023、TNNLS 2022/2019、TMM 2021、 Info. Fusion 2021、AAAI 2020などこの予備研究は MIT Technology Review の見出しで報道され、ICME 2019 Best Paper 次点賞を受賞しました。
この研究は、科学技術イノベーション 2030 - 「新世代の人工知能」主要プロジェクト、国家財団プロジェクト、自動化研究所 2035 プロジェクト、および中国人工知能の支援を受けました。 Intelligence Society-Huawei MindSpore Academic Award Fund およびペデスタルおよびその他のプロジェクトに対するインテリジェンス サポート。
著者について
筆頭著者: Du Changde、中国科学院オートメーション研究所特別研究助手、脳認知と人工知能の研究に従事、視覚的な神経情報において彼は、TPAMI/TNNLS/AAAI/KDD/ACMMM などを含む、エンコードとデコード、マルチモーダル ニューラル コンピューティングなどに関する 40 以上の論文を発表しています。彼は、2019 IEEE ICME Best Paper Run-up Award と 2021 Top 100 Chinese AI Rising Stars を受賞しています。彼は科学技術省、国立科学技術財団、中国科学院で数々の科学研究任務を次々と引き受け、その研究結果は MIT Technology Review の見出しで報告されました。##個人ホームページ: https://changdedu.github.io/

担当著者: 何恵光、中国科学院オートメーション研究所研究員、博士指導教員、中国科学院大学助教授、上海科学技術大学特別教授、青少年促進協会優秀会員中国科学院の博士号を取得し、中華人民共和国建国70周年記念メダルを受賞した。彼は、7 つの国家自然基金プロジェクト (主要基金および国際協力プロジェクトを含む)、2 863 プロジェクト、および国家重点研究計画プロジェクトを次々と実施してきました。彼は、第二級国家科学技術進歩賞を2回(それぞれ第2位と第3位)、北京科学技術進歩賞を2回、教育省第一級科学技術進歩賞、第一回優秀博士論文賞を受賞している。中国科学院、北京科学技術新星、中国科学院「陸家西若手才能賞」、福建省「閩江学者」主席教授。研究分野は人工知能、ブレイン・コンピュータ・インターフェース、医用画像解析など。過去 5 年間で、IEEE TPAMI/TNNLS や ICML などのジャーナルや会議に 80 以上の論文を発表しました。彼は、IEEEE TCDS、Journal of Automation、およびその他のジャーナルの編集委員、CCF の著名なメンバー、および CSIG の著名なメンバーです。
#
以上がInstitute of Automationが開発した非侵襲的なマルチモーダル学習モデルは、脳信号のデコードと意味解析を実現しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7486
7486
 15
1377
52
77
11
19
38
15
1377
52
77
11
19
38

 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI は確かに数学を変えつつあります。最近、この問題に細心の注意を払っている陶哲軒氏が『米国数学協会会報』(米国数学協会会報)の最新号を送ってくれた。 「機械は数学を変えるのか?」というテーマを中心に、多くの数学者が意見を述べ、そのプロセス全体は火花に満ち、ハードコアで刺激的でした。著者には、フィールズ賞受賞者のアクシャイ・ベンカテシュ氏、中国の数学者鄭楽軍氏、ニューヨーク大学のコンピューター科学者アーネスト・デイビス氏、その他業界で著名な学者を含む強力な顔ぶれが揃っている。 AI の世界は劇的に変化しています。これらの記事の多くは 1 年前に投稿されたものです。
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google が推進する JAX のパフォーマンスは、最近のベンチマーク テストで Pytorch や TensorFlow のパフォーマンスを上回り、7 つの指標で 1 位にランクされました。また、テストは最高の JAX パフォーマンスを備えた TPU では行われませんでした。ただし、開発者の間では、依然として Tensorflow よりも Pytorch の方が人気があります。しかし、将来的には、おそらくより大規模なモデルが JAX プラットフォームに基づいてトレーニングされ、実行されるようになるでしょう。モデル 最近、Keras チームは、ネイティブ PyTorch 実装を使用して 3 つのバックエンド (TensorFlow、JAX、PyTorch) をベンチマークし、TensorFlow を使用して Keras2 をベンチマークしました。まず、主流のセットを選択します
 時系列予測 NLP 大規模モデルの新機能: 時系列予測の暗黙的なプロンプトを自動的に生成
Mar 18, 2024 am 09:20 AM
時系列予測 NLP 大規模モデルの新機能: 時系列予測の暗黙的なプロンプトを自動的に生成
Mar 18, 2024 am 09:20 AM
今日は、時系列予測のパフォーマンスを向上させるために、時系列データを潜在空間上の大規模な自然言語処理 (NLP) モデルと整合させる方法を提案するコネチカット大学の最近の研究成果を紹介したいと思います。この方法の鍵は、潜在的な空間ヒント (プロンプト) を使用して時系列予測の精度を高めることです。論文タイトル: S2IP-LLM: SemanticSpaceInformedPromptLearningwithLLMforTimeSeriesForecasting ダウンロードアドレス: https://arxiv.org/pdf/2403.05798v1.pdf 1. 大きな問題の背景モデル
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
