

ChatGPT: 強力なモデル、注意メカニズム、強化学習の融合

この記事では、ChatGPT を強化する機械学習モデルを主に紹介します。大規模な言語モデルの紹介から始まり、GPT-3 のトレーニングを可能にする革新的な自己注意メカニズムを詳しく掘り下げ、次に、からの強化学習を詳しく掘り下げます。ヒューマンフィードバックは、ChatGPT を優れたものにする新しいテクノロジーです。
大規模言語モデル
ChatGPT は、大規模言語モデル (LLM) と呼ばれる、推論用の機械学習自然言語処理モデルの一種です。 LLM は、大量のテキスト データをダイジェストし、テキスト内の単語間の関係を推測します。過去数年間、コンピューティング能力の進歩に伴い、これらのモデルは進化を続けてきました。入力データセットとパラメータ空間のサイズが増加するにつれて、LLM の機能も増加します。
言語モデルの最も基本的なトレーニングには、一連の単語の中の単語を予測することが含まれます。最も一般的に、これは次のトークンの予測とマスキング言語モデルで観察されます。
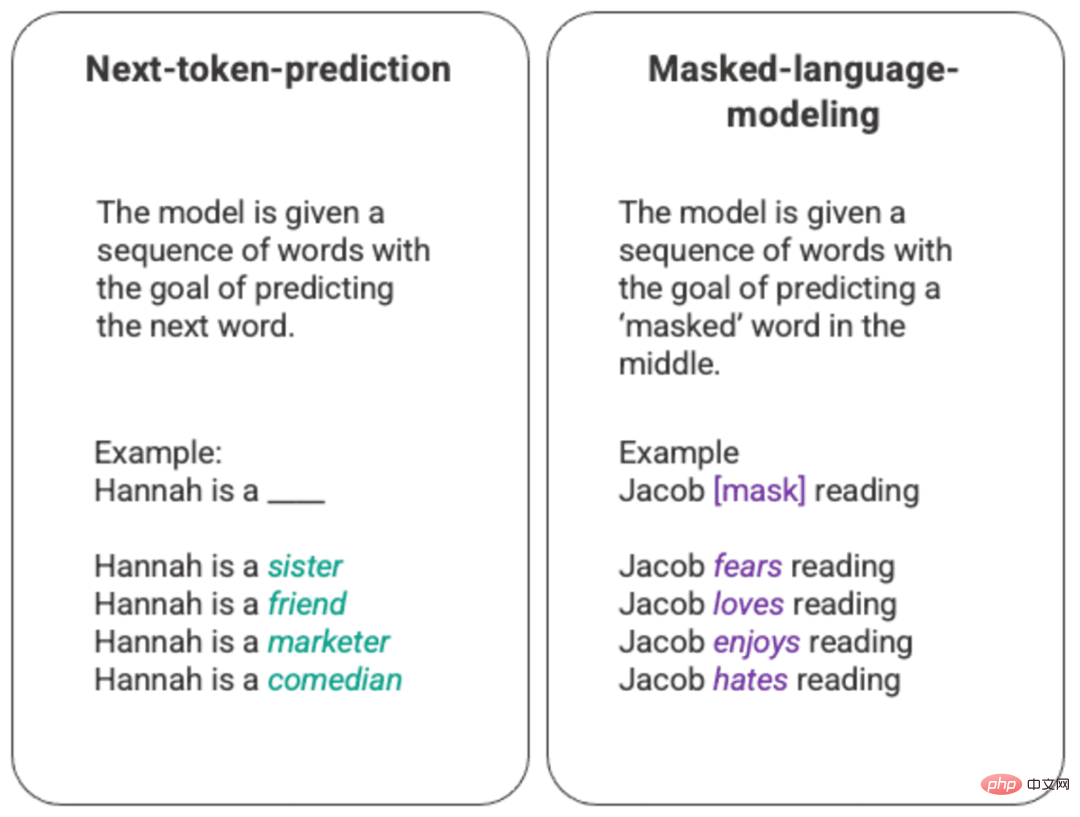
生成された次のトークン予測とマスクされた言語モデルの任意の例
この基本的なランキング手法では、通常はロングショートメモリ (LSTM) モデルを使用します。環境とコンテキストを考慮して、統計的に最も可能性の高い単語でギャップを埋めます。この逐次モデリング構造には、主に 2 つの制限があります。
- モデルは、周囲の一部の単語を他の単語よりも重視することはできません。上の例では、「読書」は最も一般的に「嫌い」と関連付けられている可能性がありますが、データベースでは「ジェイコブ」はおそらく熱心な読書家であり、モデルは「ジェイコブ」を「読む」よりも「ジェイコブ」を評価し、「愛」を選択する必要があります。 「憎しみ」をめぐって。
- 入力データは、コーパス全体としてではなく、個別かつ順次処理されます。これは、LSTM をトレーニングするとき、コンテキストのウィンドウが固定され、シーケンス内の数ステップの単一入力を超えるだけであることを意味します。これにより、単語と描画できる意味の間の関係の複雑さが制限されます。
この問題に対処するために、2017 年に Google Brain のチームはコンバーターを導入しました。 LSTM とは異なり、トランスフォーマーはすべての入力データを同時に処理できます。セルフ アテンション メカニズムを使用して、モデルは言語シーケンス内の任意の位置を基準にして、入力データのさまざまな部分にさまざまな重みを割り当てることができます。この機能により、LLM への意味の注入と、より大きなデータ セットを処理する機能の大規模な改善が可能になります。
GPT とセルフアテンション
Generative Pretrained Transformer (GPT) モデルは、2018 年に OpenAI によって初めて発表され、GPT -1 と呼ばれています。 。これらのモデルは、2019 年に GPT-2、2020 年に GPT-3、そして最近では 2022 年に InstructGPT と ChatGPT と進化を続けました。人間のフィードバックをシステムに組み込む前、GPT モデルの進化における最大の進歩は、計算効率の達成によってもたらされました。これにより、GPT-3 は GPT-2 よりもはるかに多くのデータでトレーニングできるようになり、より多様な知識ベースと実行能力が得られました。より幅広いタスク。

GPT-2 (左) と GPT-3 (右) の比較。
すべての GPT モデルはトランスフォーマー構造を利用しています。これは、入力シーケンスを処理するエンコーダーと出力シーケンスを生成するデコーダーを備えていることを意味します。エンコーダーとデコーダーはどちらもマルチヘッドのセルフ アテンション メカニズムを備えており、モデルがシーケンスのさまざまな部分に異なる重み付けをして、意味とコンテキストを推測できるようになります。さらに、エンコーダーはマスクされた言語モデルを利用して単語間の関係を理解し、よりわかりやすい応答を生成します。
GPT を駆動するセルフ アテンション メカニズムは、トークン (単語、文、その他のテキスト グループであるテキストの断片) を、そのトークンの重要性を表すベクトルに変換することによって機能します。入力シーケンスです。これを行うには、このモデル:
- 1. 入力シーケンス内のトークンごとに、
query、key、およびvalueベクトルを作成します。 - 2. ステップ 1 の
queryベクトルと他のタグのkeyベクトルの間の類似性を、2 つのベクトルの内積を計算して計算します。 - 3. ステップ 2 の出力を
softmax関数に入力して、正規化された重みを生成します。 - 4. ステップ 3 で生成された重みと各トークンの
valueベクトルを乗算することにより、シーケンス内のトークンの重要性を表す最終ベクトルが生成されます。
GPT で使用される「マルチヘッド 」注意メカニズムは、自己注意の進化です。ステップ 1 ~ 4 を一度に実行する代わりに、モデルはこのメカニズムを複数回並行して繰り返し、そのたびに新しい query、key、および value を生成します。ベクトルの線形投影。このように自己注意を拡張することにより、モデルは入力データ内の部分的な意味やより複雑な関係を把握できるようになります。

ChatGPT から生成されたスクリーンショット。
GPT-3 は自然言語処理に大幅な進歩をもたらしましたが、ユーザーの意図に合わせる能力には限界があります。たとえば、GPT-3 は次の出力を生成する場合があります:
- は役に立ちません。これは、ユーザーからの明示的な指示に従っていないことを意味します。
- 存在しない、または不正確な事実を反映した幻覚が含まれています。
- 解釈可能性の欠如により、モデルがどのようにして特定の決定や予測に至ったのかを人間が理解することが困難になります。
- 有害または攻撃的なコンテンツ、および誤った情報を広める有害または偏ったコンテンツが含まれています。
ChatGPT には、標準 LLM に固有の問題の一部を相殺するために、革新的なトレーニング方法が導入されています。
ChatGPT
ChatGPT は、人間のフィードバックをトレーニング プロセスに組み込んでモデルを作成する新しい方法を導入する InstructGPT の派生です。ユーザーの意図とよりよく統合されます。ヒューマン フィードバックからの強化学習 (RLHF) については、openAI の 2022 年の論文「ヒューマン フィードバックによる指示に従う言語モデルのトレーニング」で詳しく説明されており、以下で簡単に説明します。
ステップ 1: 教師あり微調整 (SFT) モデル
最初の開発では、40 を使用した GPT-3 モデルの微調整が行われました。請負業者は、入力にモデルの学習対象となる既知の出力が含まれる教師ありトレーニング データセットを作成します。入力またはプロンプトは、オープン API への実際のユーザー入力から収集されます。次に、タガーはプロンプトに対して適切な応答を書き込み、各入力に対して既知の出力を作成します。次に、この新しい教師付きデータセットを使用して GPT-3 モデルを微調整し、SFT モデルとしても知られる GPT-3.5 を作成します。
プロンプト データセットの多様性を最大限に高めるために、特定のユーザー ID から取得できるプロンプトは 200 個のみであり、長い共通プレフィックスを共有するプロンプトは削除されます。最後に、個人を特定できる情報 (PII) を含むヒントはすべて削除されました。
OpenAI API からのプロンプト情報を集約した後、ラベル作成者は、ごく少数の実際のサンプル データでこれらのカテゴリを埋めるためのプロンプト情報サンプルを作成することも求められました。興味のあるカテゴリは次のとおりです:
- 一般的なヒント:ランダムな問い合わせ。
- マイナーヒント: 複数のクエリと回答のペアが含まれる手順。
- ユーザーベースのプロンプト: OpenAI API に要求される特定のユースケースに対応します。
応答を生成するとき、タグ付け者はユーザーの指示が何であったかを推測するために最善を尽くす必要があります。このドキュメントでは、プロンプトが情報を要求する 3 つの主な方法について説明します。
- 直接: 「...について教えてください。」
- 一言: これら 2 つのストーリーを例として、別のストーリーを書いてください。同じ話題。
- 続き: 物語の始まりを与え、物語を完成させます。
OpenAI API からのプロンプトとラベラーからの手書きのプロンプトを編集したもので、教師ありモデルで使用するための 13,000 の入出力サンプルが生成されます。
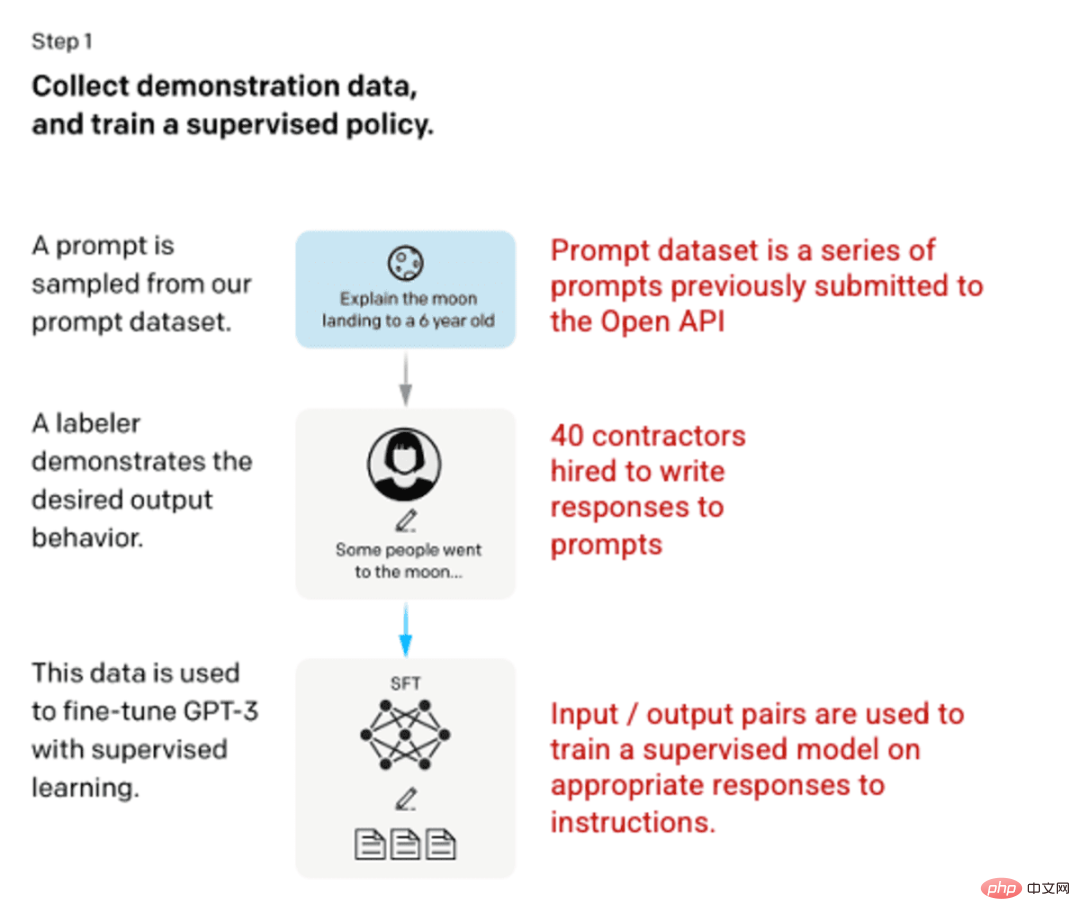
画像 (左) は、「人間のフィードバックを使用した指示に従う言語モデルのトレーニング」OpenAI et al.、2022 https://arxiv.org/pdf/2203.02155 から挿入されました。 pdf。 (右) 赤色で追加された追加のコンテキスト。
ステップ 2: 報酬モデル
ステップ 1 で SFT モデルをトレーニングした後、モデルはユーザーに対してより適切なプロンプトと一貫した応答を生成します。次の改善は、報酬モデルのトレーニングの形で行われました。モデルへの入力は一連のキューと応答であり、出力は報酬と呼ばれるスケーリングされた値です。強化学習を利用するには報酬モデルが必要です。強化学習では、モデルは報酬を最大化する出力を生成するように学習します (ステップ 3 を参照)。
報酬モデルをトレーニングするために、ラベラーは 1 つの入力プロンプトに対して 4 ~ 9 つの SFT モデル出力を提供します。被験者は、これらの出力を最良から最悪の順にランク付けして、次のような出力ランクの組み合わせを作成するように依頼されました。

応答ランクの組み合わせの例。
各組み合わせを個別のデータ ポイントとしてモデルに含めると、過剰適合 (表示されたデータの先にあるものを推測できないこと) が発生します。この問題を解決するために、ランキングの各セットをデータ ポイントの個別のバッチとして使用してモデルを構築します。
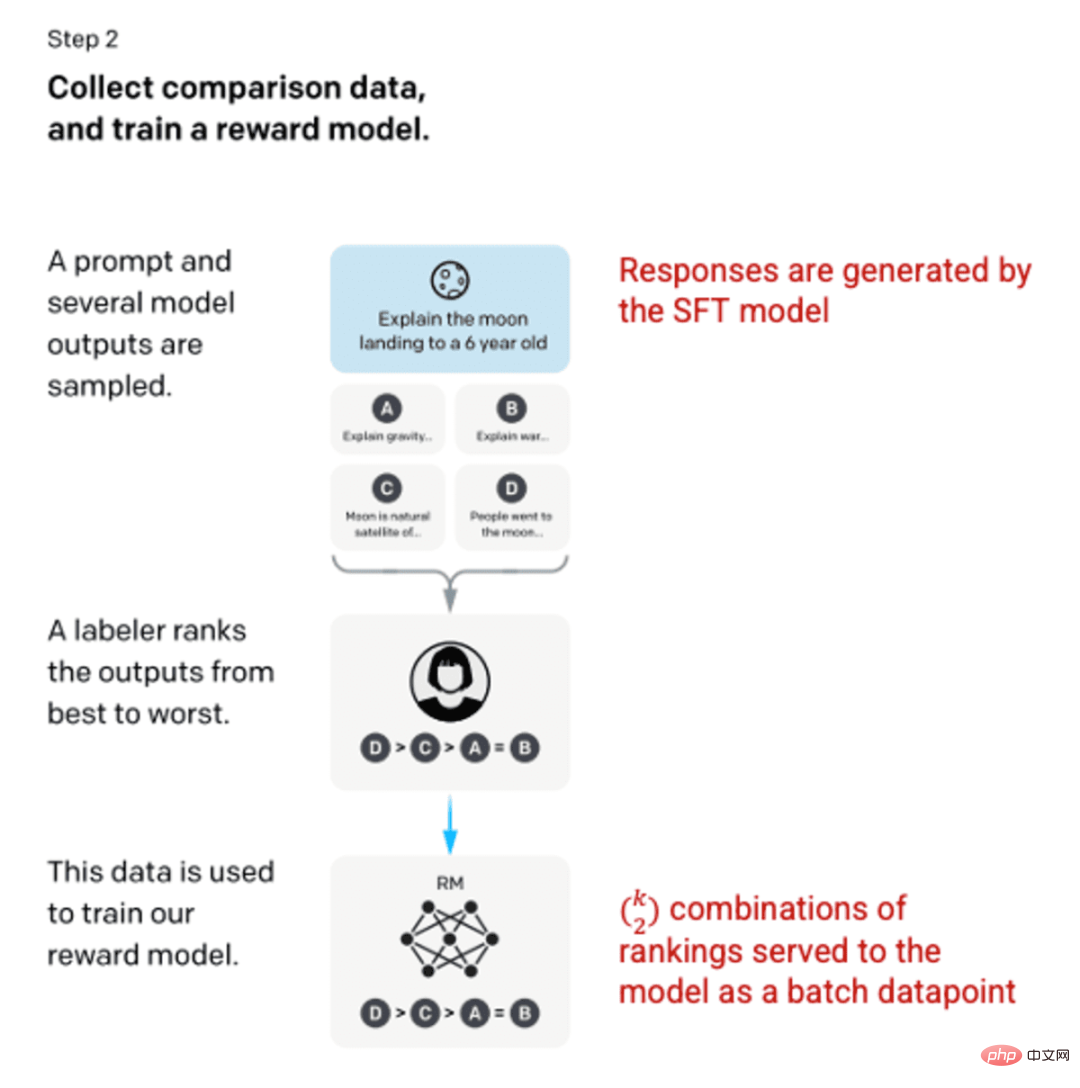
画像 (左) は、「人間のフィードバックを使用した指示に従う言語モデルのトレーニング」OpenAI et al.、2022 https://arxiv.org/pdf/2203.02155 から挿入されました。 pdf。 (右) 赤色で追加された追加のコンテキスト。
ステップ 3: 強化学習モデル
最終段階では、モデルにランダムなプロンプトが表示され、応答が返されます。応答は、ステップ 2 でモデルによって学習された「ポリシー」を使用して生成されます。ポリシーは、マシンが目標を達成するために使用する方法を学習した戦略を表します (この場合は報酬を最大化します)。ステップ 2 で開発された報酬モデルに基づいて、キューと応答のペアに対してスケーリングされた報酬値が決定されます。その後、報酬は戦略を開発するためにモデルにフィードバックされます。
2017 年に Schulman らは、応答が生成されるたびにモデルのポリシーを更新する手法である Proximal Policy Optimization (PPO) を導入しました。 PPO は、SFT モデルにカルバック・ライブラー (KL) ペナルティを組み込みます。 KL ダイバージェンスは 2 つの分布関数の類似性を測定し、極端な距離にペナルティを課します。この場合、KL ペナルティを使用すると、ステップ 1 でトレーニングされた SFT モデルの出力からの応答の距離を縮め、報酬モデルが過剰に最適化されて人間の意図のデータセットから大きく逸脱することを回避できます。
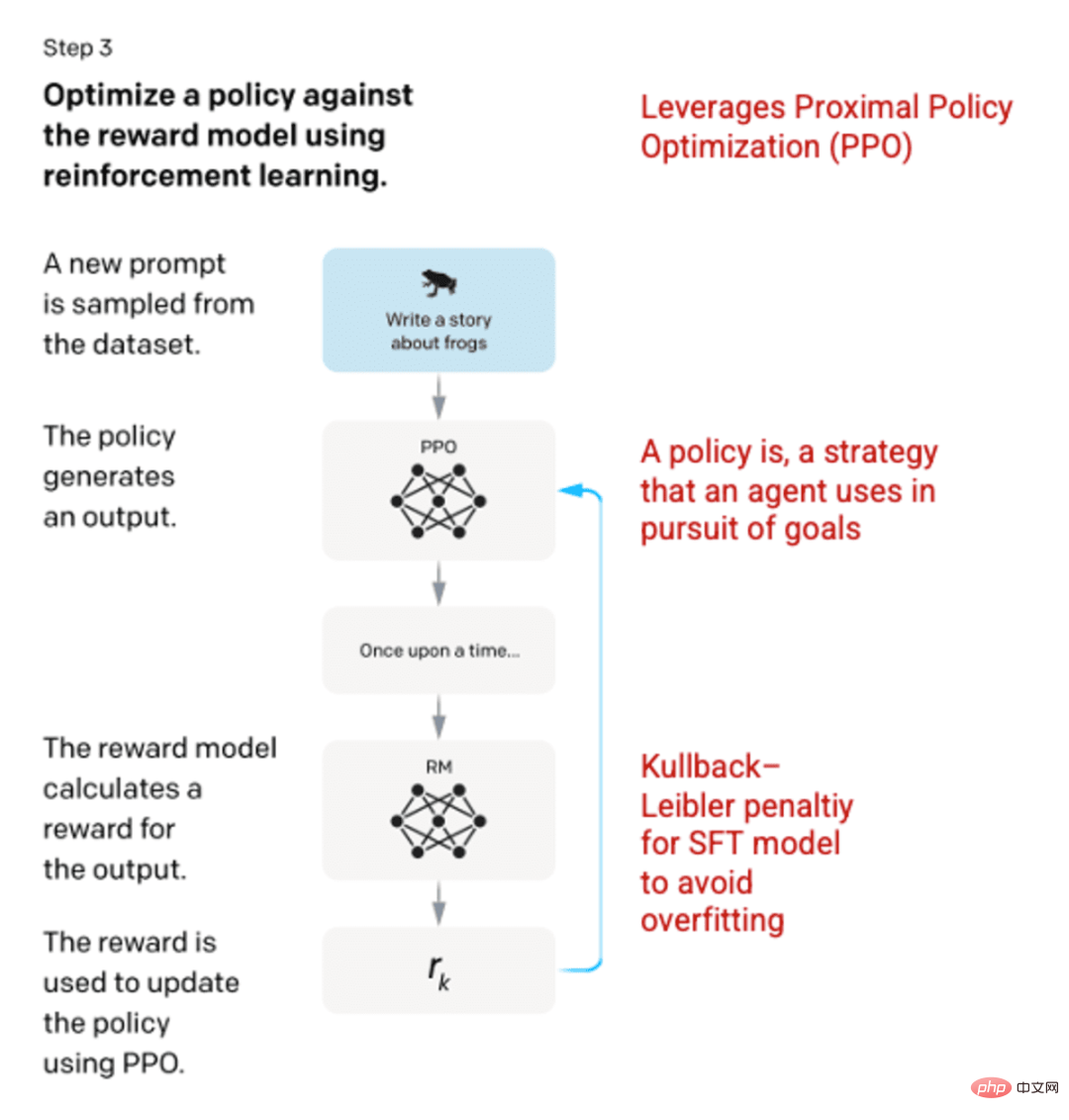
画像 (左) は、「人間のフィードバックを使用した指示に従う言語モデルのトレーニング」OpenAI et al.、2022 https://arxiv.org/pdf/2203.02155 から挿入されました。 pdf。 (右) 赤色で追加された追加のコンテキスト。
プロセスのステップ 2 と 3 は何度も繰り返すことができますが、実際にはまだ広く行われていません。

ChatGPT から生成されたスクリーンショット。
モデルの評価
モデルの評価は、トレーニング中にモデルがまだ見なかったテスト セットを予約することによって実行されます。テスト セットでは、モデルのパフォーマンスが以前の GPT-3 よりも優れているかどうかを判断するために一連の評価が実行されます。
有用性: ユーザーの指示を推論して従うモデルの機能。ラベラーは、85±3% の確率で InstructGPT の出力を GPT-3 に優先しました。
本物性: モデルが幻覚を見る傾向。 TruthfulQA データセットを使用して評価すると、PPO モデルは真実性と有益性の両方がわずかに増加した出力を生成します。
無害性: 不適切、軽蔑的、中傷的なコンテンツを回避するモデルの能力。無害性は、RealToxicityPrompts データセットを使用してテストされます。試験は 3 つの条件で実施されました。
- 指示は敬意を持って対応します。その結果、有害な反応が大幅に減少します。
- 指示は、尊重に関する設定なしで反応を提供します: 有害性に目立った変化はありません。
- ガイダンスは有害な反応をもたらす: 反応は実際には GPT-3 モデルよりもはるかに有害です。
ChatGPT と InstructGPT の作成に使用されるメソッドの詳細については、OpenAI によって公開された元の論文「人間のフィードバックによる指示に従う言語モデルのトレーニング」 (2022 https://) をお読みください。 arxiv .org/pdf/2203.02155.pdf。
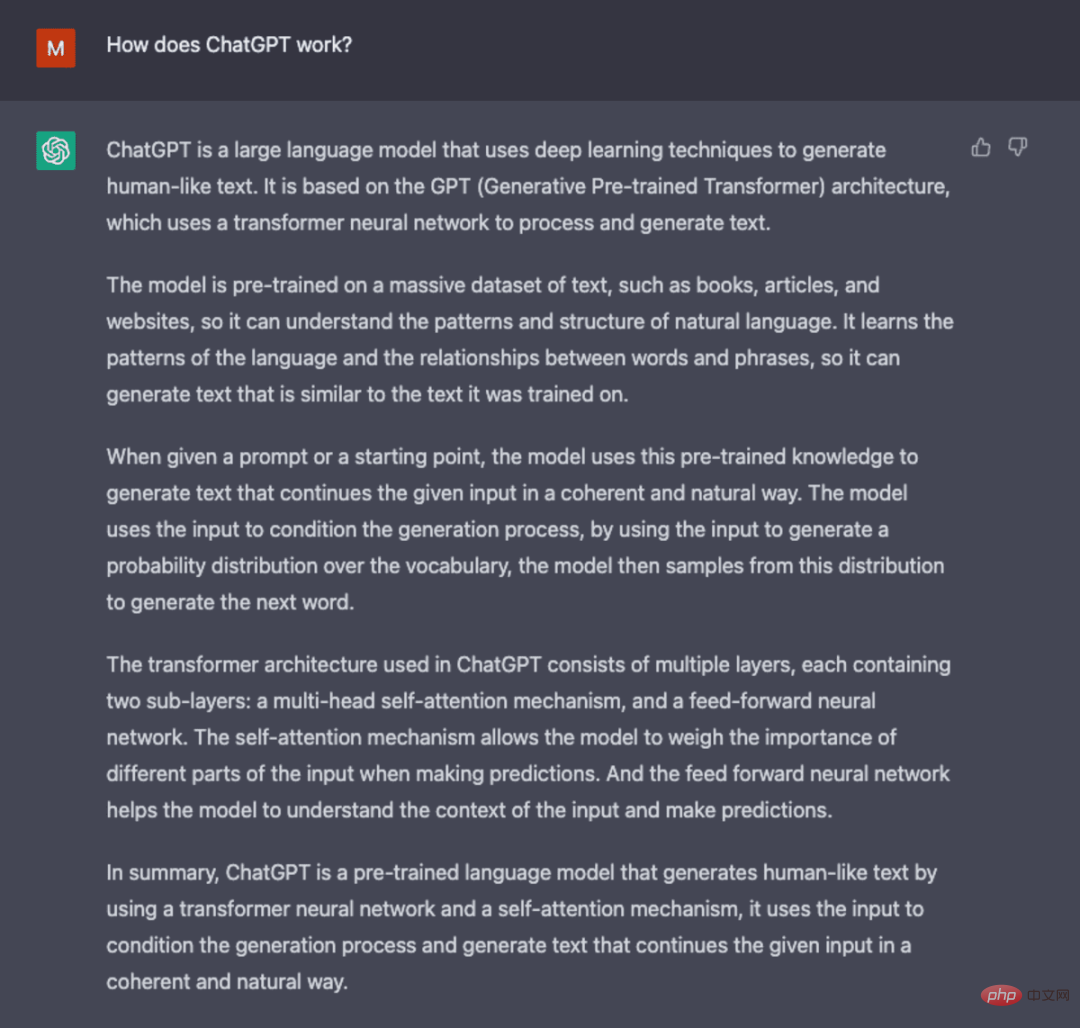
ChatGPT から生成されたスクリーンショット。
以上がChatGPT: 強力なモデル、注意メカニズム、強化学習の融合の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7480
7480
 15
1377
52
77
11
19
33
15
1377
52
77
11
19
33

 ChatGPT では、無料ユーザーが 1 日あたりの制限付きで DALL-E 3 を使用して画像を生成できるようになりました
Aug 09, 2024 pm 09:37 PM
ChatGPT では、無料ユーザーが 1 日あたりの制限付きで DALL-E 3 を使用して画像を生成できるようになりました
Aug 09, 2024 pm 09:37 PM
DALL-E 3は、前モデルより大幅に改良されたモデルとして2023年9月に正式導入されました。これは、複雑な詳細を含む画像を作成できる、これまでで最高の AI 画像ジェネレーターの 1 つと考えられています。ただし、発売当初は対象外でした
 この記事では、SHAP: 機械学習のモデルの説明について説明します。
Jun 01, 2024 am 10:58 AM
この記事では、SHAP: 機械学習のモデルの説明について説明します。
Jun 01, 2024 am 10:58 AM
機械学習とデータ サイエンスの分野では、モデルの解釈可能性が常に研究者や実務家に焦点を当ててきました。深層学習やアンサンブル手法などの複雑なモデルが広く適用されるようになったことで、モデルの意思決定プロセスを理解することが特に重要になってきました。 Explainable AI|XAI は、モデルの透明性を高めることで、機械学習モデルに対する信頼と自信を構築するのに役立ちます。モデルの透明性の向上は、複数の複雑なモデルの普及や、モデルを説明するための意思決定プロセスなどの方法によって実現できます。これらの方法には、特徴重要度分析、モデル予測間隔推定、ローカル解釈可能性アルゴリズムなどが含まれます。特徴重要度分析では、入力特徴に対するモデルの影響度を評価することで、モデルの意思決定プロセスを説明できます。モデルの予測間隔の推定
 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 説明可能な AI: 複雑な AI/ML モデルの説明
Jun 03, 2024 pm 10:08 PM
説明可能な AI: 複雑な AI/ML モデルの説明
Jun 03, 2024 pm 10:08 PM
翻訳者 | Li Rui によるレビュー | 今日、人工知能 (AI) および機械学習 (ML) モデルはますます複雑になっており、これらのモデルによって生成される出力はブラックボックスになっており、関係者に説明することができません。 Explainable AI (XAI) は、利害関係者がこれらのモデルがどのように機能するかを理解できるようにし、これらのモデルが実際に意思決定を行う方法を確実に理解できるようにし、AI システムの透明性、信頼性、およびこの問題を解決するための説明責任を確保することで、この問題を解決することを目指しています。この記事では、さまざまな説明可能な人工知能 (XAI) 手法を検討して、その基礎となる原理を説明します。説明可能な AI が重要であるいくつかの理由 信頼と透明性: AI システムが広く受け入れられ、信頼されるためには、ユーザーは意思決定がどのように行われるかを理解する必要があります
 あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
機械学習は人工知能の重要な分野であり、明示的にプログラムしなくてもコンピューターにデータから学習して能力を向上させる機能を提供します。機械学習は、画像認識や自然言語処理から、レコメンデーションシステムや不正行為検出に至るまで、さまざまな分野で幅広く応用されており、私たちの生活様式を変えつつあります。機械学習の分野にはさまざまな手法や理論があり、その中で最も影響力のある 5 つの手法は「機械学習の 5 つの流派」と呼ばれています。 5 つの主要な学派は、象徴学派、コネクショニスト学派、進化学派、ベイジアン学派、およびアナロジー学派です。 1. 象徴主義は、象徴主義とも呼ばれ、論理的推論と知識の表現のためのシンボルの使用を強調します。この学派は、学習は既存の既存の要素を介した逆演繹のプロセスであると信じています。
 フラッシュ アテンションは安定していますか?メタとハーバードは、モデルの重みの偏差が桁違いに変動していることを発見しました
May 30, 2024 pm 01:24 PM
フラッシュ アテンションは安定していますか?メタとハーバードは、モデルの重みの偏差が桁違いに変動していることを発見しました
May 30, 2024 pm 01:24 PM
MetaFAIR はハーバード大学と協力して、大規模な機械学習の実行時に生成されるデータの偏りを最適化するための新しい研究フレームワークを提供しました。大規模な言語モデルのトレーニングには数か月かかることが多く、数百、さらには数千の GPU を使用することが知られています。 LLaMA270B モデルを例にとると、そのトレーニングには合計 1,720,320 GPU 時間が必要です。大規模なモデルのトレーニングには、これらのワークロードの規模と複雑さにより、特有のシステム上の課題が生じます。最近、多くの機関が、SOTA 生成 AI モデルをトレーニングする際のトレーニング プロセスの不安定性を報告しています。これらは通常、損失スパイクの形で現れます。たとえば、Google の PaLM モデルでは、トレーニング プロセス中に最大 20 回の損失スパイクが発生しました。数値的なバイアスがこのトレーニングの不正確さの根本原因です。
 C++ の機械学習: C++ で一般的な機械学習アルゴリズムを実装するためのガイド
Jun 03, 2024 pm 07:33 PM
C++ の機械学習: C++ で一般的な機械学習アルゴリズムを実装するためのガイド
Jun 03, 2024 pm 07:33 PM
C++ では、機械学習アルゴリズムの実装には以下が含まれます。 線形回帰: 連続変数を予測するために使用されるステップには、データの読み込み、重みとバイアスの計算、パラメーターと予測の更新が含まれます。ロジスティック回帰: 離散変数の予測に使用されます。このプロセスは線形回帰に似ていますが、予測にシグモイド関数を使用します。サポート ベクター マシン: サポート ベクターの計算とラベルの予測を含む強力な分類および回帰アルゴリズム。
 SearchGPT: Open AI が独自の AI 検索エンジンで Google に対抗
Jul 30, 2024 am 09:58 AM
SearchGPT: Open AI が独自の AI 検索エンジンで Google に対抗
Jul 30, 2024 am 09:58 AM
オープン AI がついに検索に進出します。サンフランシスコの同社は最近、検索機能を備えた新しい AI ツールを発表した。今年 2 月に The Information によって初めて報告されたこの新しいツールは、まさに SearchGPT と呼ばれ、次のような機能を備えています。
