

HuggingGPT: AI タスクのための魔法のツール

はじめに
人工汎用知能 (AGI) は、人間と同じように知的タスクを理解し、処理し、応答できる人工知能システムと考えることができます。これは、人間の脳がどのように機能するかを深く理解し、それを再現できるようにする必要がある難しい課題です。しかし、ChatGPT の出現により、そのようなシステムの開発に関して研究コミュニティから大きな関心が集まりました。 Microsoft は、HuggingGPT (Microsoft Jarvis) と呼ばれるこのような主要な AI を活用したシステムをリリースしました。
HuggingGPT の新機能とその仕組みについて詳しく説明する前に、まず ChatGPT の問題点と、複雑な AI タスクの解決に問題がある理由を理解しましょう。 ChatGPT のような大規模な言語モデルは、テキスト データの解釈と一般的なタスクの処理に優れています。しかし、彼らは特定のタスクに苦戦することが多く、ばかげた反応をすることがあります。複雑な数学問題を解いているときに、ChatGPT からの偽の応答に遭遇したことがあるかもしれません。一方で、Stable Diffusion や DALL-E などの専門家レベルの AI モデルは、それぞれの主題領域についてはより深く理解していますが、より広範囲のタスクに苦労しています。 LLM とプロフェッショナル AI モデルの間の接続を確立しない限り、困難な AI タスクを解決するために LLM の可能性を最大限に活用することはできません。これが HuggingGPT の機能であり、両方の利点を組み合わせて、より効果的で正確かつ多用途な AI システムを作成します。
HuggingGPT とは何ですか?
Microsoft が最近発行した論文によると、HuggingGPT は LLM の能力を活用し、機械学習コミュニティ (HuggingFace) のさまざまな AI モデルに接続するコントローラーとして使用し、外部ツールの使用を可能にします。生産性を向上させるために。 HuggingFace は、開発者や研究者に豊富なツールとリソースを提供する Web サイトです。プロ仕様・高精度モデルも豊富に取り揃えております。 HuggingGPT は、これらのモデルをさまざまなドメインやモードの複雑な AI タスクに適用し、印象的な結果を達成します。テキストと画像に関しては、OPenAI GPT-4 と同様のマルチモーダル機能を備えています。ただし、インターネットにも接続できるので、外部の Web リンクを提供してインターネットに関する質問をすることもできます。
モデルに画像に書かれたテキストの音声読み上げを実行させたいとします。 HuggingGPT は、最適なモデルを使用してこのタスクを連続的に実行します。まず、画像からテキストをエクスポートし、その結果を音声生成に使用します。回答の詳細は以下の画像で確認できます。ただただ素晴らしい!

ビデオ モードとオーディオ モードのマルチモーダル連携の定性分析
HuggingGPT はどのように機能しますか?
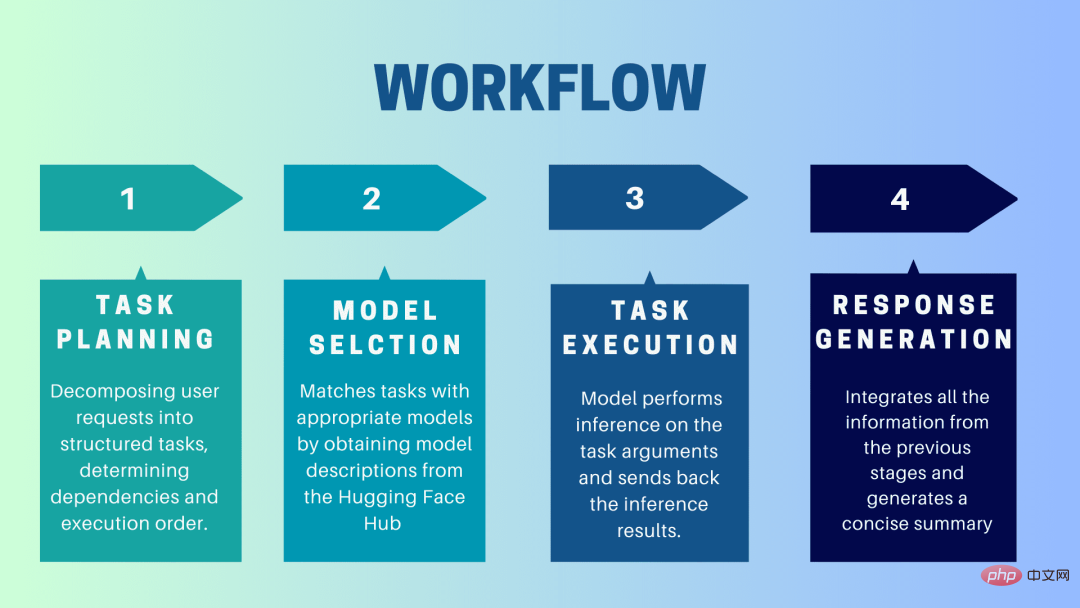
HuggingGPT は、ユーザーのリクエストをエキスパート モデルに送信するインターフェースとして LLM を使用する共同システムです。ユーザー プロンプトからモデルへの応答を受信するまでの完全なプロセスは、次の個別のステップに分けることができます:
1. タスクの計画
この段階では、HuggingGPT は ChatGPT を使用してユーザー プロンプトを理解します。 , 次に、クエリを小さな実行可能なタスクに分割します。また、これらのタスクの依存関係を特定し、タスクが実行される順序を定義します。 HuggingGPT には、タスク解析用の 4 つのスロット (タスク タイプ、タスク ID、タスク依存関係、およびタスク パラメーター) があります。 HuggingGPT とユーザー間のチャットは記録され、リソース履歴を示す画面に表示されます。
2. モデルの選択
ユーザー環境と利用可能なモデルに基づいて、HuggingGPT はコンテキストに応じたタスク モデル割り当てメカニズムを使用して、特定のタスクに最も適切なモデルを選択します。このメカニズムによれば、モデルの選択は多肢選択の質問とみなされ、最初にタスクのタイプに基づいてモデルがフィルタリングされます。その後、モデルの品質の信頼できる尺度と考えられるダウンロード数に基づいてモデルがランク付けされました。このランキングに基づいて、Top-K モデルが選択されます。ここでの K は、モデルの数を反映する単なる定数です。たとえば、3 に設定すると、ダウンロード数が最も多い 3 つのモデルが選択されます。
3.タスクの実行
ここでは、タスクが特定のモデルに割り当てられ、モデルが推論を実行して結果を返します。このプロセスをより効率的にするために、HuggingGPT は、同じリソースを必要としない限り、異なるモデルを同時に実行できます。たとえば、猫と犬の写真を生成するように指示された場合、さまざまなモデルを並行して実行してこのタスクを実行できます。ただし、モデルが同じリソースを必要とする場合があるため、HuggingGPT はリソースを追跡するために
4. 応答の生成
最後のステップは、ユーザーへの応答を生成することです。まず、前の段階でのすべての情報と推論結果が統合されます。情報は構造化された形式で表示されます。たとえば、プロンプトが画像内のライオンの数を検出することである場合、検出確率を使用して適切な境界ボックスを描画します。 LLM (ChatGPT) はこの形式を取得し、人間に優しい言語でレンダリングします。
HuggingGPT のセットアップ
HuggingGPT は、自然言語テキストを生成できるディープ ニューラル ネットワーク モデルである、Hugging Face の最先端の GPT-3.5 アーキテクチャに基づいて構築されています。ローカル マシンでセットアップする手順は次のとおりです。
システム要件
デフォルト構成では、Ubuntu 16.04 LTS、少なくとも 24 GB の VRAM、少なくとも 12 GB (最小)、 16GB (標準) または 80GB (フル) RAM、および少なくとも 284GB のディスク容量。さらに、damo-vilab/text-to-video-ms-1.7b には 42 GB、ControlNet には 126 GB、stable-diffusion-v1-5 には 66 GB、その他のリソースには 50 GB のスペースが必要です。 「ライト」構成の場合、Ubuntu 16.04 LTS のみが必要です。
開始手順
まず、server/configs/config.default.yaml ファイル内の OpenAI キーとハグフェイス トークンを実際のキーに置き換えます。または、環境変数 OPENAI_API_KEY と HUGGGINGFACE_ACCESS_TOKEN にそれぞれ設定することもできます。
次のコマンドを実行します。
サーバーの場合:
- Python 環境をセットアップしてインストールします。必要な依存関係。
<code># 设置环境cd serverconda create -n jarvis pythnotallow=3.8conda activate jarvisconda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidiapip install -r requirements.txt</code>
- 必要なモデルをダウンロードします。
<code># 下载模型。确保`git-lfs`已经安装。cd modelsbash download.sh # required when `inference_mode` is `local` or `hybrid`.</code>
- 実行中のサーバー
<code># 运行服务器cd ..python models_server.py --config configs/config.default.yaml # required when `inference_mode` is `local` or `hybrid`python awesome_chat.py --config configs/config.default.yaml --mode server # for text-davinci-003</code>
これで、HTTP リクエストを Web API エンドポイントに送信して、Jarvis のサービスにアクセスできるようになります。リクエストを
- /hugginggpt エンドポイントに送信し、POST メソッドを使用して完全なサービスにアクセスします。
- /tasks エンドポイントでは、POST メソッドを使用してフェーズ 1 の中間結果にアクセスします。
- /results エンドポイントでは、POST メソッドを使用してステージ 1 ~ 3 の中間結果にアクセスします。
これらのリクエストは JSON 形式である必要があり、ユーザーに代わって入力された情報のリストが含まれている必要があります。
Web の場合:
- アプリケーション awesome_chat.py をサーバー モードで起動した後、コンピューターにノード js と npm をインストールします。
- Web ディレクトリに移動し、次の依存関係をインストールします。
<code>cd webnpm installnpm run dev</code>
- http://{LAN_IP_of_the_server}:{port}/ を web/src/config/ に設定します。別のマシンで Web クライアントを実行している場合の、index.ts の HUGGGINGGPT_BASE_URL。
- ビデオ生成機能を使用したい場合は、H.264 を使用して ffmpeg を手動でコンパイルしてください。
<code># 可选:安装 ffmpeg# 这个命令需要在没有错误的情况下执行。LD_LIBRARY_PATH=/usr/local/lib /usr/local/bin/ffmpeg -i input.mp4 -vcodec libx264 output.mp4</code>
- 設定アイコンをダブルクリックして、ChatGPT に戻ります。
CLI の場合:
CLI を使用した Jarvis のセットアップは非常に簡単です。以下のコマンドを実行するだけです:
<code>cd serverpython awesome_chat.py --config configs/config.default.yaml --mode cli</code>
Gradio の場合:
Gradio デモも Hugging Face Space でホストされています。 OPENAI_API_KEY と HUGGGINGFACE_ACCESS_TOKEN を入力した後、実験できます。
ローカルで実行するには:
- 必要な依存関係をインストールし、Hugging Face Space からプロジェクト リポジトリを複製し、プロジェクト ディレクトリに移動します。
- 次のコマンドを使用します。モデルサーバーを起動してから Gradio デモを開始するには:
<code>python models_server.py --config configs/config.gradio.yamlpython run_gradio_demo.py --config configs/config.gradio.yaml</code>
- ブラウザで http://localhost:7860 経由でデモにアクセスし、さまざまな入力を入力してテストします
- オプションとして、次のコマンドを実行してデモを Docker イメージとして実行することもできます:
<code>docker run -it -p 7860:7860 --platform=linux/amd64 registry.hf.space/microsoft-hugginggpt:latest python app.py</code>
注: 質問がある場合は、公式 Github リポジトリ (https: //github.com/microsoft/JARVIS)。
最終感想
HuggingGPT には、ここで強調する必要がある特定の制限もあります。たとえば、システムの効率が大きなボトルネックとなっており、HuggingGPT では前述のすべての段階で LLM との複数の対話が必要になります。これらの対話により、ユーザー エクスペリエンスが低下し、遅延が増加する可能性があります。同様に、コンテキストの最大長は、許可されるトークンの数によって制限されます。もう 1 つの問題は、システムの信頼性です。LLM がプロンプトを誤って解釈し、間違ったタスク シーケンスを生成する可能性があり、それがプロセス全体に影響を及ぼします。それにもかかわらず、複雑な AI タスクを解決する大きな可能性を秘めており、AGI にとって良い進歩となります。この研究がAIの未来をどのような方向に導くのか、楽しみにしましょう!
以上がHuggingGPT: AI タスクのための魔法のツールの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7554
7554
 15
1382
52
83
11
24
96
15
1382
52
83
11
24
96

 Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centos Shutdownコマンドはシャットダウンし、構文はシャットダウン[オプション]時間[情報]です。オプションは次のとおりです。-hシステムをすぐに停止します。 -pシャットダウン後に電源をオフにします。 -r再起動; -t待機時間。時間は、即時(現在)、数分(分)、または特定の時間(HH:mm)として指定できます。追加の情報をシステムメッセージに表示できます。
 Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosシステムの下でのGitlabのバックアップと回復ポリシーデータセキュリティと回復可能性を確保するために、Gitlab on Centosはさまざまなバックアップ方法を提供します。この記事では、いくつかの一般的なバックアップ方法、構成パラメーター、リカバリプロセスを詳細に紹介し、完全なGitLabバックアップと回復戦略を確立するのに役立ちます。 1.手動バックアップGitlab-RakeGitlabを使用:バックアップ:コマンドを作成して、マニュアルバックアップを実行します。このコマンドは、gitlabリポジトリ、データベース、ユーザー、ユーザーグループ、キー、アクセスなどのキー情報をバックアップします。デフォルトのバックアップファイルは、/var/opt/gitlab/backupsディレクトリに保存されます。 /etc /gitlabを変更できます
 CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CENTOSシステムでHDFS構成をチェックするための完全なガイドこの記事では、CENTOSシステム上のHDFSの構成と実行ステータスを効果的に確認する方法をガイドします。次の手順は、HDFSのセットアップと操作を完全に理解するのに役立ちます。 Hadoop環境変数を確認します。最初に、Hadoop環境変数が正しく設定されていることを確認してください。端末では、次のコマンドを実行して、Hadoopが正しくインストールおよび構成されていることを確認します。HDFS構成をチェックするHDFSファイル:HDFSのコア構成ファイルは/etc/hadoop/conf/ディレクトリにあります。使用
 CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
Pytorch GPUアクセラレーションを有効にすることで、CentOSシステムでは、PytorchのCUDA、CUDNN、およびGPUバージョンのインストールが必要です。次の手順では、プロセスをガイドします。CUDAおよびCUDNNのインストールでは、CUDAバージョンの互換性が決定されます。NVIDIA-SMIコマンドを使用して、NVIDIAグラフィックスカードでサポートされているCUDAバージョンを表示します。たとえば、MX450グラフィックカードはCUDA11.1以上をサポートする場合があります。 cudatoolkitのダウンロードとインストール:nvidiacudatoolkitの公式Webサイトにアクセスし、グラフィックカードでサポートされている最高のCUDAバージョンに従って、対応するバージョンをダウンロードしてインストールします。 cudnnライブラリをインストールする:
 Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
CentOSにMySQLをインストールするには、次の手順が含まれます。適切なMySQL Yumソースの追加。 yumを実行して、mysql-serverコマンドをインストールして、mysqlサーバーをインストールします。ルートユーザーパスワードの設定など、MySQL_SECURE_INSTALLATIONコマンドを使用して、セキュリティ設定を作成します。必要に応じてMySQL構成ファイルをカスタマイズします。 MySQLパラメーターを調整し、パフォーマンスのためにデータベースを最適化します。
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
DockerはLinuxカーネル機能を使用して、効率的で孤立したアプリケーションランニング環境を提供します。その作業原則は次のとおりです。1。ミラーは、アプリケーションを実行するために必要なすべてを含む読み取り専用テンプレートとして使用されます。 2。ユニオンファイルシステム(UnionFS)は、違いを保存するだけで、スペースを節約し、高速化する複数のファイルシステムをスタックします。 3.デーモンはミラーとコンテナを管理し、クライアントはそれらをインタラクションに使用します。 4。名前空間とcgroupsは、コンテナの分離とリソースの制限を実装します。 5.複数のネットワークモードは、コンテナの相互接続をサポートします。これらのコア概念を理解することによってのみ、Dockerをよりよく利用できます。
 Centos8はsshを再起動します
Apr 14, 2025 pm 09:00 PM
Centos8はsshを再起動します
Apr 14, 2025 pm 09:00 PM
SSHサービスを再起動するコマンドは次のとおりです。SystemCTL再起動SSHD。詳細な手順:1。端子にアクセスし、サーバーに接続します。 2。コマンドを入力します:SystemCtl RestArt SSHD; 3.サービスステータスの確認:SystemCTLステータスSSHD。
 Centosでgitlabログを表示する方法
Apr 14, 2025 pm 06:18 PM
Centosでgitlabログを表示する方法
Apr 14, 2025 pm 06:18 PM
CENTOSシステムでGitLabログを表示するための完全なガイドこの記事では、メインログ、例外ログ、その他の関連ログなど、CentosシステムでさまざまなGitLabログを表示する方法をガイドします。ログファイルパスは、gitlabバージョンとインストール方法によって異なる場合があることに注意してください。次のパスが存在しない場合は、gitlabインストールディレクトリと構成ファイルを確認してください。 1.メインGitLabログの表示
