
 テクノロジー周辺機器
AI
Zhu Jun 氏のチームは、清華大学の Transformer に基づく初の大規模マルチモーダル拡散モデルをオープンソース化し、テキストと画像の書き換えを経て完全に完成しました。
テクノロジー周辺機器
AI
Zhu Jun 氏のチームは、清華大学の Transformer に基づく初の大規模マルチモーダル拡散モデルをオープンソース化し、テキストと画像の書き換えを経て完全に完成しました。
Zhu Jun 氏のチームは、清華大学の Transformer に基づく初の大規模マルチモーダル拡散モデルをオープンソース化し、テキストと画像の書き換えを経て完全に完成しました。

GPT-4 が今週リリースされると報告されており、マルチモダリティがそのハイライトの 1 つになるでしょう。現在の大規模言語モデルは、さまざまなモダリティを理解するための普遍的なインターフェースになりつつあり、さまざまなモダリティ情報に基づいて返信テキストを与えることができますが、大規模言語モデルによって生成されるコンテンツはテキストに限定されます。一方、現行の拡散モデルであるDALL・E 2、Imagen、Stable Diffusionなどはビジュアル制作に革命を起こしていますが、これらのモデルはテキストから画像への単一のクロスモーダル機能のみをサポートしており、まだ十分とは言えません。普遍的な生成モデルからの距離。マルチモーダル大規模モデルは、さまざまなモダリティの機能を解放し、任意のモダリティ間の変換を実現することができ、これがユニバーサル生成モデルの将来の開発方向であると考えられています。
清華大学コンピューターサイエンス学部の Zhu Jun 教授が率いる TSAIL チームは最近、論文「One Transformer fits All Distributions in Multi-Modal Diffusion at Scale」を発表しました。マルチモーダルを最初に公開した人 生成モデルに関するいくつかの探索的な作業により、任意のモード間の相互変換が可能になりました。

紙のリンク: https://ml.cs.tsinghua .edu.cn/diffusion/unidiffuser.pdf
##オープンソース コード: https://github.com/thu-ml/unidiffuser この論文は、マルチモダリティ向けに設計された確率的モデリング フレームワーク UniDiffuser を提案し、オープンソースの大規模グラフィックおよびテキスト データを使用するためにチームが提案したトランスフォーマー ベースのネットワーク アーキテクチャ U-ViT を採用します。 10 億のパラメータを持つモデルは LAION-5B でトレーニングされ、基礎となるモデルがさまざまな生成タスクを高品質で完了できるようになりました (図 1)。簡単に言うと、一方向のテキスト生成に加えて、画像生成、画像とテキストの結合生成、無条件の画像とテキスト生成、画像とテキストの書き換えなどの複数の機能も実現でき、制作効率が大幅に向上します。テキストと画像コンテンツの効率を高め、テキストとグラフィックスの生成をさらに向上させる 数式モデルの応用想像力。
この論文の筆頭著者である Bao Fan は現在博士課程の学生であり、Analytic-DPM の前の提案者であり、ICLR 2022 の優秀論文賞を受賞しました (現在は、 1 つだけ)拡散モデルにおける彼の優れた業績に対して、本土部隊が独自に完成させた賞を受賞した論文)。
さらに、Machine Heart は、TSAIL チームによって提案された DPM-Solver 高速アルゴリズムについて以前に報告しました。これは、依然として拡散モデルの最速生成アルゴリズムです。マルチモーダル大規模モデルは、チームによる長期にわたる徹底的なアルゴリズムと深い確率モデルの原理の蓄積を集中的に示したものです。この研究の共同研究者には、人民大学ヒルハウス人工知能大学院の Li Chongxuan 氏、北京知源研究所の Cao Yue 氏などが含まれます。

効果の表示
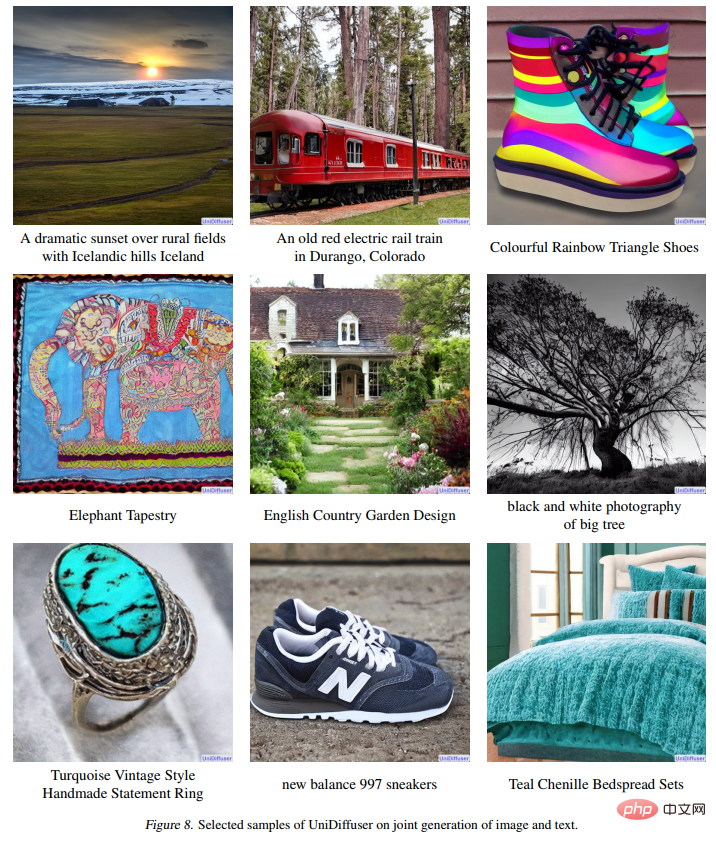
以下の図 8 は、画像とテキストを共同生成する際の UniDiffuser の効果を示しています。
以下の図 9 は、テキストから画像への UniDiffuser の効果を示しています。
次の図 10 は、画像からテキストへの UniDiffuser の効果を示しています。

#次の図11 無条件画像生成に対する UniDiffuser の効果を示します:

次の図 12 は、画像書き換えに対する UniDiffuser の効果を示しています。

次の図 15以下の図 16 に示すように、UniDiffuser がグラフィックスとテキストの 2 つのモード間を行き来できることを示しています。 UniDiffuser は 2 つの実際の画像を補間できます:
方法の概要

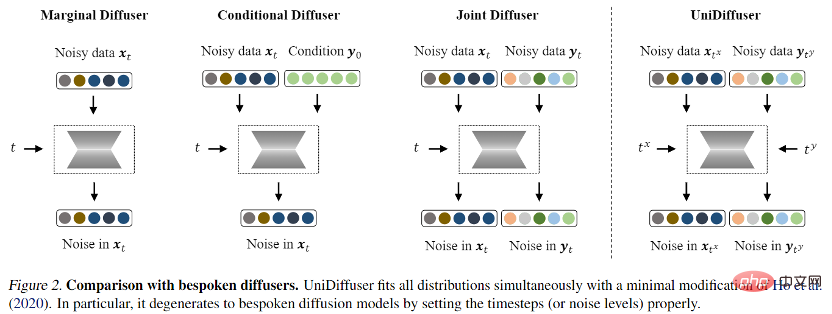
確率的モデリング フレームワーク: 画像とテキスト間のエッジ分布、条件付き分布、結合分布など、モード間のすべての分布を同時にモデル化できる確率的モデリング フレームワークを見つけることは可能ですか? 、など?
ネットワーク アーキテクチャ: さまざまな入力方式をサポートするように統合ネットワーク アーキテクチャを設計できますか?
- 確率的モデリング フレームワーク
- 確率的モデリング フレームワークとして、研究チームは UniDiffuser、A を提案しました。拡散モデルの確率モデリング フレームワーク。 UniDiffuser は、周辺分布、条件付き分布、結合分布など、マルチモーダル データのすべての分布を明示的にモデル化できます。研究チームは、異なる分布についての拡散モデル学習を 1 つの観点に統合できることを発見しました。つまり、まず 2 つのモダリティのデータに一定サイズのノイズを追加し、次に 2 つのモダリティのデータのノイズを予測します。 2 つのモーダル データのノイズの量によって、特定の分布が決まります。たとえば、テキストのノイズ サイズを 0 に設定することは、ビンセント図の条件付き分布に対応し、テキストのノイズ サイズを最大値に設定することは、無条件画像生成の分布に対応し、画像のノイズ サイズを設定し、テキストを同じ値にすると、画像とテキストの結合分散に対応します。この統一された観点によれば、UniDiffuser は元の拡散モデルのトレーニング アルゴリズムにわずかな変更を加えるだけで、上記のすべての分布を同時に学習できます。下の図に示すように、UniDiffuser はすべてのモードに同時にノイズを追加します。単一モードの代わりに、すべてのモードに対応するノイズの大きさと、すべてのモードで予測されるノイズを入力します。
# 二峰性モードを例として挙げると、最終的なトレーニング目的関数は次のとおりです。
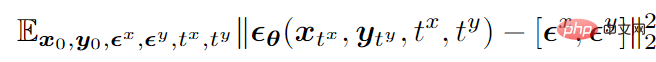


 ## は、2 つのモードで同時にノイズを予測するノイズ予測ネットワークです。
## は、2 つのモードで同時にノイズを予測するノイズ予測ネットワークです。
トレーニング後、UniDiffuser は 2 つのモダリティに適切な時間をノイズ予測ネットワークに設定することで、無条件、条件付き、および共同生成を実現できます。たとえば、テキストの時間を 0 に設定すると、テキストから画像への生成が実現できます。テキストの時間を最大値に設定すると、無条件の画像生成が実現できます。画像とテキストの時間を同じ値に設定すると、画像とテキストの共同生成。
UniDiffuser のトレーニング アルゴリズムとサンプリング アルゴリズムを以下に示しますが、これらのアルゴリズムは元の拡散モデルと比較してわずかな変更しか加えておらず、実装が簡単であることがわかります。

さらに、UniDiffuser は条件付き分布と無条件分布の両方をモデル化するため、UniDiffuser は分類子を使用しないガイダンスを自然にサポートします。以下の図 3 は、さまざまなガイダンス スケールにおける UniDiffuser の条件付き生成と共同生成の効果を示しています。

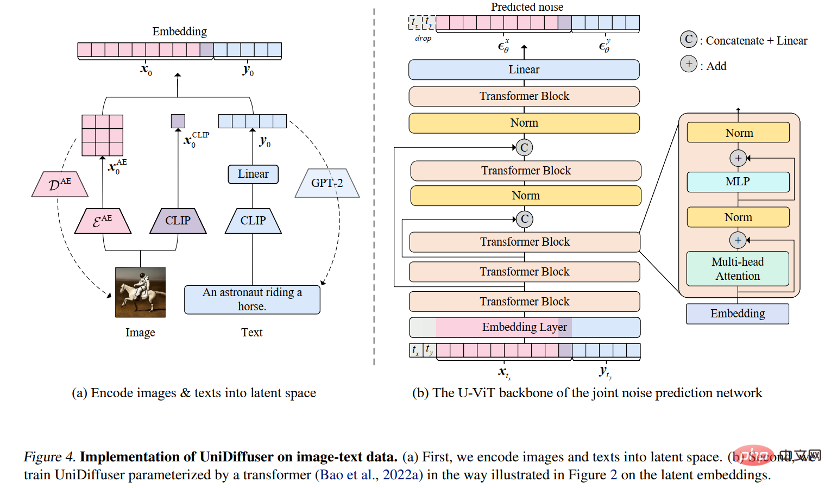
ネットワーク アーキテクチャ
#ネットワーク アーキテクチャを考慮して、研究チームは、変圧器ベースのアーキテクチャを使用してノイズ予測ネットワークをパラメータ化することを提案しました。具体的には、研究チームは最近提案された U-ViT アーキテクチャを採用しました。 U-ViT はすべての入力をトークンとして扱い、トランス ブロック間に U 字型の接続を追加します。研究チームはまた、安定拡散戦略を採用して、さまざまなモダリティのデータを潜在空間に変換し、拡散モデルをモデル化しました。 U-ViT アーキテクチャもこの研究チームから提供され、https://github.com/baofff/U-ViT でオープンソース化されていることは注目に値します。
実験結果
UniDiffuser はまず Versatile Diffusion と比較されました。 Versatile Diffusion は、マルチタスク フレームワークに基づいた過去のマルチモーダル普及モデルです。まず、UniDiffuser と Versatile Diffusion をテキストから画像への効果について比較しました。以下の図 5 に示すように、UniDiffuser は、さまざまな分類子を使用しないガイダンス スケールの下で、CLIP スコアと FID メトリクスの両方において Versatile Diffusion よりも優れています。
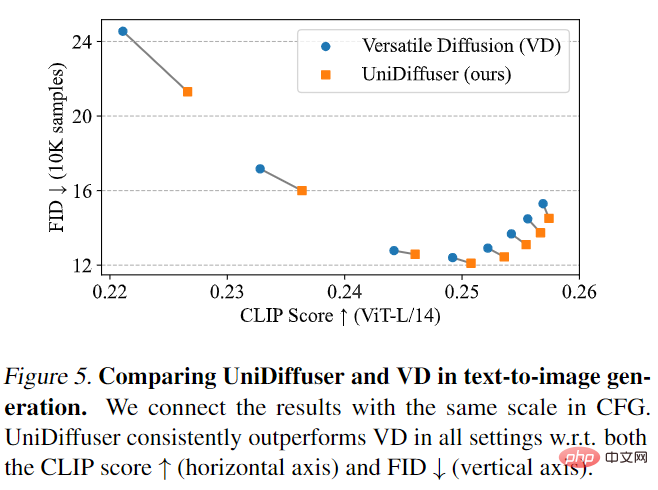
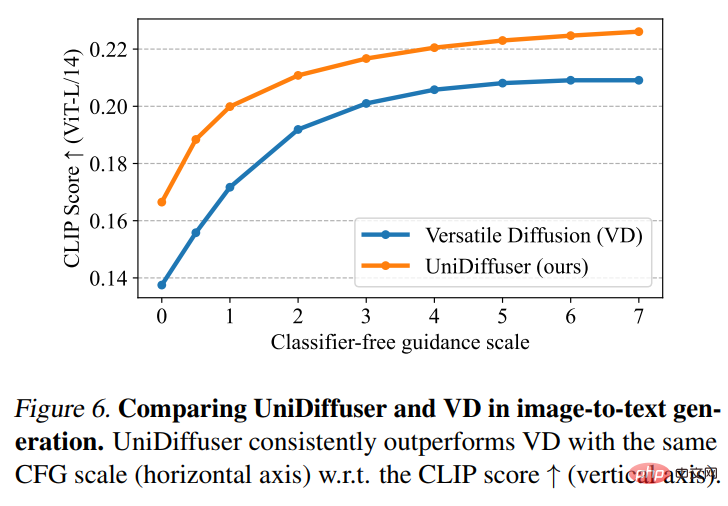
次に、UniDiffuser と Versatile Diffusion が画像とテキストの比較を実行しました。以下の図 6 に示すように、UniDiffuser は画像からテキストへのクリップ スコアが優れています。
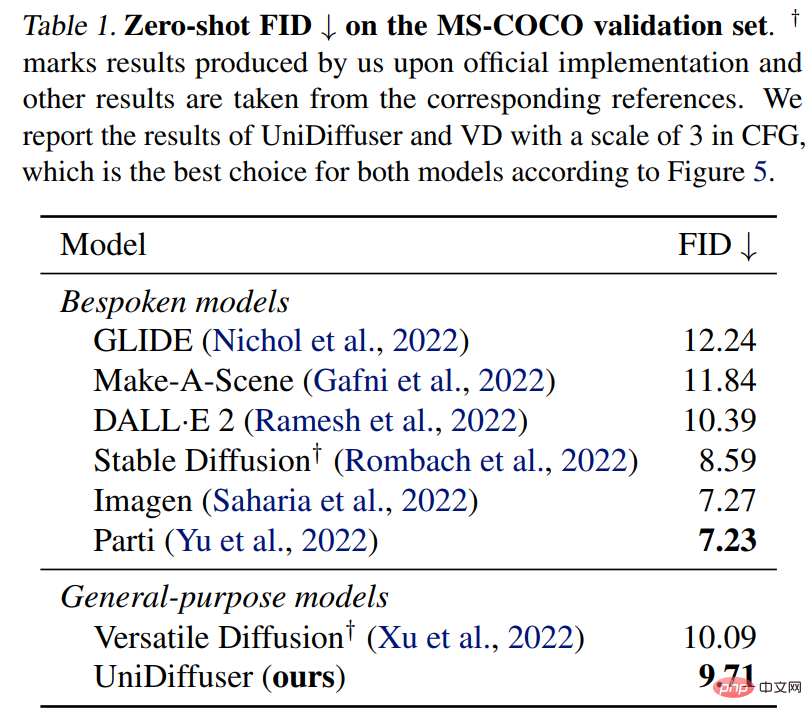
UniDiffuser は、MS-COCO 上で専用のテキストからグラフへのモデルとのゼロショット FID 比較も実行します。以下の表 1 に示すように、UniDiffuser は専用のテキストからグラフへのモデルと同等の結果を達成できます。
以上がZhu Jun 氏のチームは、清華大学の Transformer に基づく初の大規模マルチモーダル拡散モデルをオープンソース化し、テキストと画像の書き換えを経て完全に完成しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7488
7488
 15
1377
52
77
11
19
39
15
1377
52
77
11
19
39

 OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
Jun 13, 2024 pm 01:59 PM
OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
Jun 13, 2024 pm 01:59 PM
ソフトウェア テクノロジの最前線に立つ UIUC Zhang Lingming のグループは、BigCode 組織の研究者とともに、最近 StarCoder2-15B-Instruct 大規模コード モデルを発表しました。この革新的な成果により、コード生成タスクにおいて大きな進歩が達成され、CodeLlama-70B-Instruct を上回り、コード生成パフォーマンス リストのトップに到達しました。 StarCoder2-15B-Instruct のユニークな特徴は、その純粋な自己調整戦略であり、トレーニング プロセス全体がオープンで透過的で、完全に自律的で制御可能です。このモデルは、高価な手動アノテーションに頼ることなく、StarCoder-15B 基本モデルの微調整に応じて、StarCoder2-15B を介して数千の命令を生成します。
 Yolov10: 詳細な説明、展開、アプリケーションがすべて 1 か所にまとめられています。
Jun 07, 2024 pm 12:05 PM
Yolov10: 詳細な説明、展開、アプリケーションがすべて 1 か所にまとめられています。
Jun 07, 2024 pm 12:05 PM
1. はじめに ここ数年、YOLO は、計算コストと検出パフォーマンスの効果的なバランスにより、リアルタイム物体検出の分野で主流のパラダイムとなっています。研究者たちは、YOLO のアーキテクチャ設計、最適化目標、データ拡張戦略などを調査し、大きな進歩を遂げました。同時に、後処理に非最大抑制 (NMS) に依存すると、YOLO のエンドツーエンドの展開が妨げられ、推論レイテンシに悪影響を及ぼします。 YOLO では、さまざまなコンポーネントの設計に包括的かつ徹底的な検査が欠けており、その結果、大幅な計算冗長性が生じ、モデルの機能が制限されます。効率は最適ではありませんが、パフォーマンス向上の可能性は比較的大きくなります。この作業の目標は、後処理とモデル アーキテクチャの両方から YOLO のパフォーマンス効率の境界をさらに改善することです。この目的を達成するために
 清華大学が引き継ぎ、YOLOv10 が登場しました。パフォーマンスが大幅に向上し、GitHub のホット リストに掲載されました。
Jun 06, 2024 pm 12:20 PM
清華大学が引き継ぎ、YOLOv10 が登場しました。パフォーマンスが大幅に向上し、GitHub のホット リストに掲載されました。
Jun 06, 2024 pm 12:20 PM
ターゲット検出システムのベンチマークである YOLO シリーズが再び大幅にアップグレードされました。今年 2 月の YOLOv9 のリリース以来、YOLO (YouOnlyLookOnce) シリーズのバトンは清華大学の研究者の手に渡されました。先週末、YOLOv10 のリリースのニュースが AI コミュニティの注目を集めました。これは、コンピュータ ビジョンの分野における画期的なフレームワークと考えられており、リアルタイムのエンドツーエンドの物体検出機能で知られており、効率と精度を組み合わせた強力なソリューションを提供することで YOLO シリーズの伝統を継承しています。論文アドレス: https://arxiv.org/pdf/2405.14458 プロジェクトアドレス: https://github.com/THU-MIG/yo
 Google Gemini 1.5 テクニカル レポート: 数学オリンピックの問題を簡単に証明、Flash バージョンは GPT-4 Turbo より 5 倍高速
Jun 13, 2024 pm 01:52 PM
Google Gemini 1.5 テクニカル レポート: 数学オリンピックの問題を簡単に証明、Flash バージョンは GPT-4 Turbo より 5 倍高速
Jun 13, 2024 pm 01:52 PM
今年 2 月、Google はマルチモーダル大型モデル Gemini 1.5 を発表しました。これは、エンジニアリングとインフラストラクチャの最適化、MoE アーキテクチャ、その他の戦略を通じてパフォーマンスと速度を大幅に向上させました。より長いコンテキスト、より強力な推論機能、およびクロスモーダル コンテンツのより適切な処理が可能になります。今週金曜日、Google DeepMind は Gemini 1.5 の技術レポートを正式にリリースしました。このレポートには Flash バージョンとその他の最近のアップグレードが含まれています。このドキュメントは 153 ページあります。技術レポートのリンク: https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf このレポートでは、Google が Gemini1 を紹介しています。
 Java フレームワークの商用サポートの費用対効果を評価する方法
Jun 05, 2024 pm 05:25 PM
Java フレームワークの商用サポートの費用対効果を評価する方法
Jun 05, 2024 pm 05:25 PM
Java フレームワークの商用サポートのコスト/パフォーマンスを評価するには、次の手順が必要です。 必要な保証レベルとサービス レベル アグリーメント (SLA) 保証を決定します。研究サポートチームの経験と専門知識。アップグレード、トラブルシューティング、パフォーマンスの最適化などの追加サービスを検討してください。ビジネス サポートのコストと、リスクの軽減と効率の向上を比較検討します。
 レビュー!自動運転推進におけるベーシックモデルの重要な役割を総まとめ
Jun 11, 2024 pm 05:29 PM
レビュー!自動運転推進におけるベーシックモデルの重要な役割を総まとめ
Jun 11, 2024 pm 05:29 PM
上記および著者の個人的な理解: 最近、ディープラーニング技術の発展と進歩により、大規模な基盤モデル (Foundation Model) が自然言語処理とコンピューター ビジョンの分野で大きな成果を上げています。自動運転における基本モデルの応用にも大きな発展の可能性があり、シナリオの理解と推論を向上させることができます。豊富な言語と視覚データの事前トレーニングを通じて、基本モデルは自動運転シナリオのさまざまな要素を理解して解釈し、推論を実行して、運転の意思決定と計画のための言語とアクションのコマンドを提供します。基本モデルは、運転シナリオを理解してデータを拡張することで、日常的な運転やデータ収集では遭遇する可能性が低い、ロングテール分布におけるまれな実現可能な機能を提供できます。
 PHP フレームワークの学習曲線は他の言語フレームワークと比較してどうですか?
Jun 06, 2024 pm 12:41 PM
PHP フレームワークの学習曲線は他の言語フレームワークと比較してどうですか?
Jun 06, 2024 pm 12:41 PM
PHP フレームワークの学習曲線は、言語熟練度、フレームワークの複雑さ、ドキュメントの品質、コミュニティのサポートによって異なります。 PHP フレームワークの学習曲線は、Python フレームワークと比較すると高く、Ruby フレームワークと比較すると低くなります。 Java フレームワークと比較すると、PHP フレームワークの学習曲線は中程度ですが、開始までの時間は短くなります。
 PHP フレームワークの軽量オプションはアプリケーションのパフォーマンスにどのような影響を与えますか?
Jun 06, 2024 am 10:53 AM
PHP フレームワークの軽量オプションはアプリケーションのパフォーマンスにどのような影響を与えますか?
Jun 06, 2024 am 10:53 AM
軽量の PHP フレームワークは、サイズが小さくリソース消費が少ないため、アプリケーションのパフォーマンスが向上します。その特徴には、小型、高速起動、低メモリ使用量、改善された応答速度とスループット、および削減されたリソース消費が含まれます。 実際のケース: SlimFramework は、わずか 500 KB、高い応答性と高スループットの REST API を作成します。
