import multiprocessing
def producer(numbers, q):
for x in numbers:
if x % 2 == 0:
if q.full():
print("queue is full")
break
q.put(x)
print(f"put {x} in queue by producer")
return None
def consumer(q):
while not q.empty():
print(f"take data {q.get()} from queue by consumer")
return None
if __name__ == "__main__":
# 设置1个queue对象,最大长度为5
qu = multiprocessing.Queue(maxsize=5,)
# 创建producer子进程,把queue做为其中1个参数传给它,该进程负责写
p5 = multiprocessing.Process(
name="producer-1",
target=producer,
args=([random.randint(1, 100) for i in range(0, 10)], qu)
)
p5.start()
p5.join()
#创建consumer子进程,把queue做为1个参数传给它,该进程中队列中读
p6 = multiprocessing.Process(
name="consumer-1",
target=consumer,
args=(qu,)
)
p6.start()
p6.join()
print(qu.qsize())
>>> from multiprocessing import shared_memory
>>> shm_a = shared_memory.SharedMemory(create=True, size=10)
>>> type(shm_a.buf)
<class 'memoryview'>
>>> buffer = shm_a.buf
>>> len(buffer)
10
>>> buffer[:4] = bytearray([22, 33, 44, 55]) # Modify multiple at once
>>> buffer[4] = 100 # Modify single byte at a time
>>> # Attach to an existing shared memory block
>>> shm_b = shared_memory.SharedMemory(shm_a.name)
>>> import array
>>> array.array('b', shm_b.buf[:5]) # Copy the data into a new array.array
array('b', [22, 33, 44, 55, 100])
>>> shm_b.buf[:5] = b'howdy' # Modify via shm_b using bytes
>>> bytes(shm_a.buf[:5]) # Access via shm_a
b'howdy'
>>> shm_b.close() # Close each SharedMemory instance
>>> shm_a.close()
>>> shm_a.unlink() # Call unlink only once to release the shared memory
>>> with SharedMemoryManager() as smm:
... sl = smm.ShareableList(range(2000))
... # Divide the work among two processes, storing partial results in sl
... p1 = Process(target=do_work, args=(sl, 0, 1000))
... p2 = Process(target=do_work, args=(sl, 1000, 2000))
... p1.start()
... p2.start() # A multiprocessing.Pool might be more efficient
... p1.join()
... p2.join() # Wait for all work to complete in both processes
... total_result = sum(sl) # Consolidate the partial results now in sl
from multiprocessing.managers import BaseManager
class MathsClass:
def add(self, x, y):
return x + y
def mul(self, x, y):
return x * y
class MyManager(BaseManager):
pass
MyManager.register('Maths', MathsClass)
if __name__ == '__main__':
with MyManager() as manager:
maths = manager.Maths()
print(maths.add(4, 3)) # prints 7
print(maths.mul(7, 8))
ログイン後にコピー
以上がマルチプロセッシングを使用して Python でプロセス間通信を実装するにはどうすればよいですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
VSコードはWindows 8で実行できますが、エクスペリエンスは大きくない場合があります。まず、システムが最新のパッチに更新されていることを確認してから、システムアーキテクチャに一致するVSコードインストールパッケージをダウンロードして、プロンプトとしてインストールします。インストール後、一部の拡張機能はWindows 8と互換性があり、代替拡張機能を探すか、仮想マシンで新しいWindowsシステムを使用する必要があることに注意してください。必要な拡張機能をインストールして、適切に動作するかどうかを確認します。 Windows 8ではVSコードは実行可能ですが、開発エクスペリエンスとセキュリティを向上させるために、新しいWindowsシステムにアップグレードすることをお勧めします。



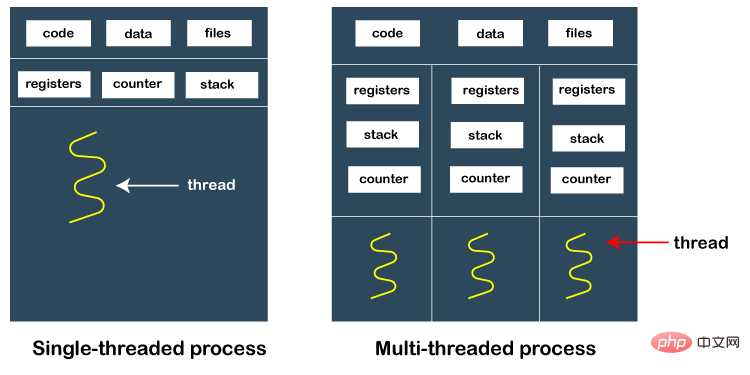 実際のプロジェクト要件では、集中的な計算やリアルタイム タスクが頻繁に発生し、場合によっては、プロセス間で大量のデータ (画像、大容量データなど) を転送する必要があります。オブジェクトなど
実際のプロジェクト要件では、集中的な計算やリアルタイム タスクが頻繁に発生し、場合によっては、プロセス間で大量のデータ (画像、大容量データなど) を転送する必要があります。オブジェクトなど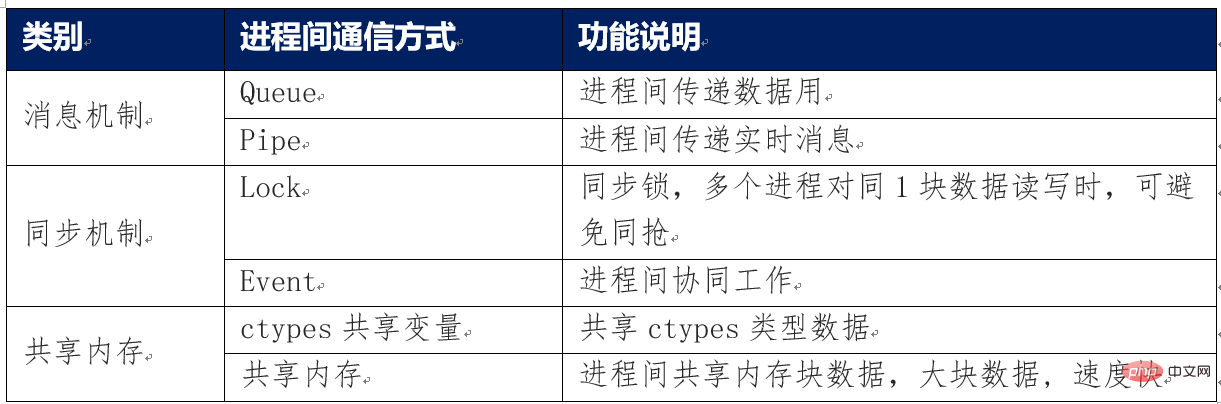 プロセス間通信のメモリ安全性について
プロセス間通信のメモリ安全性について