

ChatGPT と Bard は高価すぎるため、8 つの無料のオープンソースの大規模モデル ソリューションを紹介します。

1.LLaMA
LLaMA プロジェクトには、70 億から 650 億のパラメーターのサイズの基本的な言語モデルのセットが含まれています。これらのモデルは数百万のトークンでトレーニングされ、すべて公開されているデータセットでトレーニングされます。その結果、LLaMA-13B は GPT-3 (175B) を上回りましたが、LLaMA-65B は Chinchilla-70B や PaLM-540B などの最高のモデルと同様のパフォーマンスを示しました。
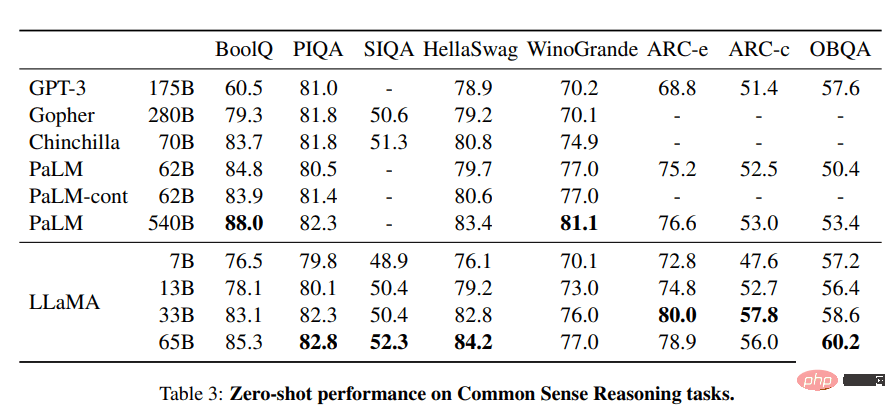
LLaMA からの画像
出典:
- 研究論文: 「LLaMA: オープンで効率的な基盤言語モデル (arxiv. org)" [https://arxiv.org/abs/2302.13971]
- GitHub: facebookresearch/llama [https://github.com/facebookresearch/llama]
- デモ: Baize Lora 7B [https://huggingface.co/spaces/project-baize/Baize-7B]
2.Alpaca
スタンフォード大学の Alpaca は、ChatGPT と競合でき、誰でも 600 ドル未満でコピーできると主張しています。 Alpaca 7B は、52K 命令フォロー デモンストレーションで LLaMA 7B モデルから微調整されています。 トレーニング コンテンツ | スタンフォード大学 CRFM の写真 リソース:- ブログ: スタンフォード大学 CRFM。 [https://crfm.stanford.edu/2023/03/13/alpaca.html]
- GitHub:tatsu-lab/stanford_alpaca [https://github.com/tatsu-lab/stanford_alpaca]
- デモ: Alpaca-LoRA (公式デモは失われています。これは Alpaca モデルのレンダリングです) [https://huggingface.co/spaces/tloen/alpaca-lora]
3.Vicuna
#Vicuna は、ShareGPT から収集されたユーザー共有会話の LLaMA モデルに基づいて微調整されています。 Vicuna-13B モデルは、OpenAI ChatGPT および Google Bard の品質の 90% 以上に達しています。また、90% の確率で LLaMA モデルと Stanford Alpaca モデルを上回りました。ビクーニャの訓練にかかる費用は約 300 ドルです。
Vicuna からの画像
出典:
- ブログ投稿: 「Vicuna: GPT-4 を印象付けるオープンソースのチャットボット」 90%* ChatGPT 品質」 [https://vicuna.lmsys.org/]
- GitHub: lm-sys/FastChat [https://github.com/lm-sys/FastChat#fine-tuning ]
- デモ: FastChat (lmsys.org) [https://chat.lmsys.org/]
4.OpenChatKit
OpenChatKit: ChatGPT に代わるオープン ソースの代替ツールであり、チャットボットを作成するための完全なツールキットです。ユーザー自身の指示調整をトレーニングするための大規模な言語モデル、微調整されたモデル、ボットの応答を更新するためのスケーラブルな検索システム、質問のボット レビューをフィルタリングするための指示が提供されます。
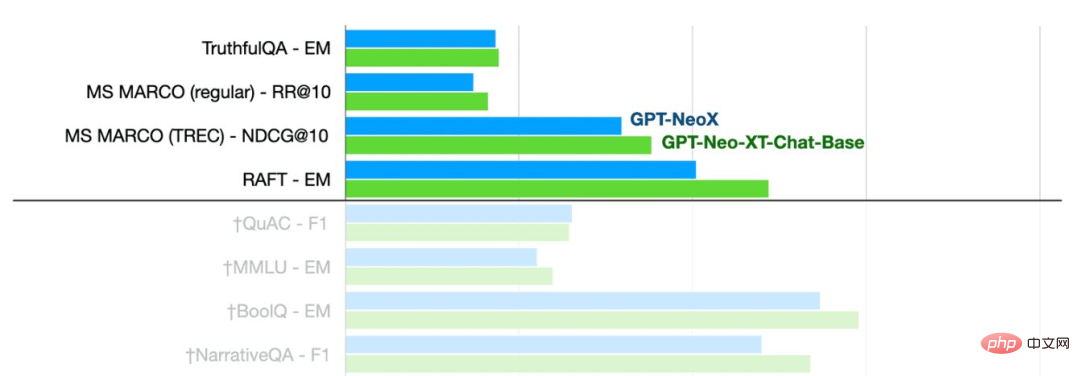
一緒に撮った写真
GPT-NeoXT-Chat-Base-20B モデルは、Basic モードの GPT-NoeX よりも優れたパフォーマンスを発揮していることがわかります。
リソース:
- ブログ投稿:「OpenChatKit の発表」—TOGETHER [https://www.together.xyz/blog/openchatkit]
- GitHub: togethercomputer /OpenChatKit [https://github.com/togethercomputer/OpenChatKit]
- デモ: OpenChatKit [https://huggingface.co/spaces/togethercomputer/OpenChatKit]
- モデル カード: togethercomputer/ GPT-NeoXT-Chat-Base-20B [https://huggingface.co/togethercomputer/GPT-NeoXT-Chat-Base-20B]
#5.GPT4ALL
GPT4ALL はコミュニティ主導のプロジェクトであり、コード、ストーリー、説明、複数回の対話を含む補助インタラクションの大規模なコーパスでトレーニングされています。チームは、オープンソースを促進するために、データセット、モデルの重み、データ管理プロセス、トレーニング コードを提供しました。さらに、ラップトップで実行できるモデルの量子化 4 ビット バージョンもリリースしました。 Python クライアントを使用してモデル推論を実行することもできます。
GPT4ALL の写真
リソース:
- 技術レポート: GPT4All [https://s3.amazonaws.com/static.nomic.ai/gpt4all/2023_GPT4All_Technical_Report.pdf]
- GitHub: nomic-ai/gpt4al [https:/ /github.com/nomic-ai/gpt4all]
- デモ: GPT4All (非公式)。 [https://huggingface.co/spaces/rishiraj/GPT4All]
- モデルカード: nomic-ai/gpt4all-lora · ハグフェイス [https://huggingface.co/nomic-ai/gpt4all-lora] ]
6.Raven RWKV
Raven RWKV 7B は、RWKV 言語モデルによって駆動されるオープンソースのチャット ロボットです。結果は ChatGPT と同様です。このモデルは RNN を使用しており、品質とスケーラビリティの点でトランスに匹敵すると同時に、より高速で VRAM を節約できます。 Raven は、Stanford Alpaca、code-alpaca、その他のデータセットに基づいて微調整されています。
Raven RWKV 7Bからの画像
出典:
- GitHub: BlinkDL/ChatRWKV [https://github.com] /BlinkDL/ChatRWKV]
- デモ: Raven RWKV 7B [https://huggingface.co/spaces/BlinkDL/Raven-RWKV-7B]
- モデル カード: BlinkDL/rwkv-4-レイブン [https://huggingface.co/BlinkDL/rwkv-4-raven]
7.OPT
OPT: Open Pre-trained Transformer 言語モデルは、ChatGPT ほど強力ではありませんが、ゼロショット学習および少数ショット学習とステレオタイプ バイアス分析において優れた機能を示します。より良い結果を得るために、Alpa、Colossal-AI、CTranslate2、FasterTransformer と統合することもできます。 注: このリストに載っている理由は、テキスト生成カテゴリで月間 624,710 ダウンロードされているため、その人気が理由です。
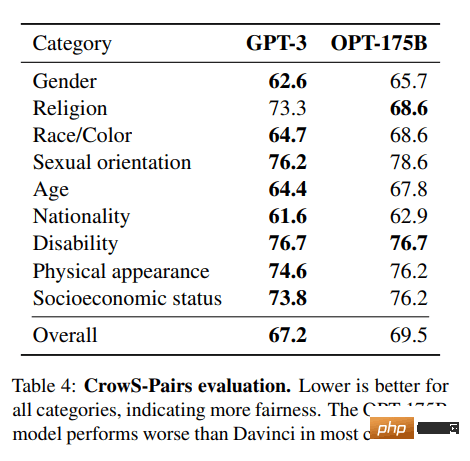
(arxiv.org) からの画像
出典:
- 研究論文: 「OPT: Open Pre-trained Transformer」言語モデル (arxiv.org)」 [https://arxiv.org/abs/2205.01068]
- GitHub: facebookresearch/metaseq [https://github.com/facebookresearch/metaseq] # #デモ: LLM 用のウォーターマーク [https://huggingface.co/spaces/tomg-group-umd/lm-watermarking]
- モデル カード: facebook/opt-1.3b [https://huggingface. co/facebook/opt-1.3b]
##8.Flan-T5-XXLFlan-T5-XXL T5 モデル命令の形で表現されたデータセットに基づいて微調整されます。命令の微調整により、PaLM、T5、U-PaLM などのさまざまなモデル クラスのパフォーマンスが大幅に向上しました。 Flan-T5-XXL モデルは、1,000 を超える追加タスクで微調整され、より多くの言語をカバーします。
 Flan-T5-XXL
Flan-T5-XXL
からの画像出典:
研究論文: 「スケーリング命令 - 微調整された言語モデル」 [https://arxiv.org/pdf/2210.11416.pdf]- GitHub: google-research/t5x [https://github.com/google-research/t5x]
- デモ: Chat Llm ストリーミング [https://huggingface.co/spaces/olivierdehaene/chat-llm-streaming]
- モデル カード: google/flan-t5-xxl [https://huggingface.co/google /flan-t5-xxl?text=Q: ( False or not False or False ) は? A: ステップごとに考えてみましょう]
概要##オープンソースの大規模モデルの中から選択できるものは数多くあります。この記事では、最も人気のある 8 つの大規模モデルについて説明します。
以上がChatGPT と Bard は高価すぎるため、8 つの無料のオープンソースの大規模モデル ソリューションを紹介します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7563
7563
 15
1385
52
84
11
28
99
15
1385
52
84
11
28
99

 オープンソースのフリーテキスト注釈ツールのおすすめ 10 選
Mar 26, 2024 pm 08:20 PM
オープンソースのフリーテキスト注釈ツールのおすすめ 10 選
Mar 26, 2024 pm 08:20 PM
テキスト注釈は、テキスト内の特定のコンテンツにラベルまたはタグを対応させる作業です。その主な目的は、特に人工知能の分野で、より深い分析と処理のためにテキストに追加情報を提供することです。テキスト注釈は、人工知能アプリケーションの教師あり機械学習タスクにとって非常に重要です。これは、自然言語テキスト情報をより正確に理解し、テキスト分類、感情分析、言語翻訳などのタスクのパフォーマンスを向上させるために AI モデルをトレーニングするために使用されます。テキスト アノテーションを通じて、AI モデルにテキスト内のエンティティを認識し、コンテキストを理解し、新しい同様のデータが出現したときに正確な予測を行うように教えることができます。この記事では主に、より優れたオープンソースのテキスト注釈ツールをいくつか推奨します。 1.LabelStudiohttps://github.com/Hu
 ChatGPT では、無料ユーザーが 1 日あたりの制限付きで DALL-E 3 を使用して画像を生成できるようになりました
Aug 09, 2024 pm 09:37 PM
ChatGPT では、無料ユーザーが 1 日あたりの制限付きで DALL-E 3 を使用して画像を生成できるようになりました
Aug 09, 2024 pm 09:37 PM
DALL-E 3は、前モデルより大幅に改良されたモデルとして2023年9月に正式導入されました。これは、複雑な詳細を含む画像を作成できる、これまでで最高の AI 画像ジェネレーターの 1 つと考えられています。ただし、発売当初は対象外でした
 オープンソースの無料画像注釈ツールおすすめ 15 選
Mar 28, 2024 pm 01:21 PM
オープンソースの無料画像注釈ツールおすすめ 15 選
Mar 28, 2024 pm 01:21 PM
画像の注釈は、ラベルまたは説明情報を画像に関連付けて、画像の内容に深い意味と説明を与えるプロセスです。このプロセスは機械学習にとって重要であり、画像内の個々の要素をより正確に識別するために視覚モデルをトレーニングするのに役立ちます。画像に注釈を追加することで、コンピュータは画像の背後にあるセマンティクスとコンテキストを理解できるため、画像の内容を理解して分析する能力が向上します。画像アノテーションは、コンピュータ ビジョン、自然言語処理、グラフ ビジョン モデルなどの多くの分野をカバーする幅広い用途があり、車両が道路上の障害物を識別するのを支援したり、障害物の検出を支援したりするなど、幅広い用途があります。医用画像認識による病気の診断。この記事では主に、より優れたオープンソースおよび無料の画像注釈ツールをいくつか推奨します。 1.マケセンス
 推奨: 優れた JS オープンソースの顔検出および認識プロジェクト
Apr 03, 2024 am 11:55 AM
推奨: 優れた JS オープンソースの顔検出および認識プロジェクト
Apr 03, 2024 am 11:55 AM
顔の検出および認識テクノロジーは、すでに比較的成熟しており、広く使用されているテクノロジーです。現在、最も広く使用されているインターネット アプリケーション言語は JS ですが、Web フロントエンドでの顔検出と認識の実装には、バックエンドの顔認識と比較して利点と欠点があります。利点としては、ネットワーク インタラクションの削減とリアルタイム認識により、ユーザーの待ち時間が大幅に短縮され、ユーザー エクスペリエンスが向上することが挙げられます。欠点としては、モデル サイズによって制限されるため、精度も制限されることが挙げられます。 js を使用して Web 上に顔検出を実装するにはどうすればよいですか? Web 上で顔認識を実装するには、JavaScript、HTML、CSS、WebRTC など、関連するプログラミング言語とテクノロジに精通している必要があります。同時に、関連するコンピューター ビジョンと人工知能テクノロジーを習得する必要もあります。 Web 側の設計により、次の点に注意してください。
 携帯電話にchatgptをインストールする方法
Mar 05, 2024 pm 02:31 PM
携帯電話にchatgptをインストールする方法
Mar 05, 2024 pm 02:31 PM
インストール手順: 1. ChatGTP ソフトウェアを ChatGTP 公式 Web サイトまたはモバイル ストアからダウンロードします; 2. それを開いた後、設定インターフェイスで言語を中国語を選択します; 3. ゲーム インターフェイスでヒューマン マシン ゲームを選択し、中国スペクトル; 4 . 起動後、チャット ウィンドウにコマンドを入力してソフトウェアを操作します。
 Alibaba 7B マルチモーダル文書理解の大規模モデルが新しい SOTA を獲得
Apr 02, 2024 am 11:31 AM
Alibaba 7B マルチモーダル文書理解の大規模モデルが新しい SOTA を獲得
Apr 02, 2024 am 11:31 AM
マルチモーダル文書理解機能のための新しい SOTA!アリババの mPLUG チームは、最新のオープンソース作品 mPLUG-DocOwl1.5 をリリースしました。これは、高解像度の画像テキスト認識、一般的な文書構造の理解、指示の遵守、外部知識の導入という 4 つの主要な課題に対処するための一連のソリューションを提案しています。さっそく、その効果を見てみましょう。複雑な構造のグラフをワンクリックで認識しMarkdown形式に変換:さまざまなスタイルのグラフが利用可能:より詳細な文字認識や位置決めも簡単に対応:文書理解の詳しい説明も可能:ご存知「文書理解」 「」は現在、大規模な言語モデルの実装にとって重要なシナリオです。市場には文書の読み取りを支援する多くの製品が存在します。その中には、主にテキスト認識に OCR システムを使用し、テキスト処理に LLM と連携する製品もあります。
 リリースされたばかりの!ワンクリックでアニメ風の画像を生成するオープンソース モデル
Apr 08, 2024 pm 06:01 PM
リリースされたばかりの!ワンクリックでアニメ風の画像を生成するオープンソース モデル
Apr 08, 2024 pm 06:01 PM
最新の AIGC オープンソース プロジェクト、AnimagineXL3.1 をご紹介します。このプロジェクトは、アニメをテーマにしたテキストから画像へのモデルの最新版であり、より最適化された強力なアニメ画像生成エクスペリエンスをユーザーに提供することを目的としています。 AnimagineXL3.1 では、開発チームは、モデルのパフォーマンスと機能が新たな高みに達することを保証するために、いくつかの重要な側面の最適化に重点を置きました。まず、トレーニング データを拡張して、以前のバージョンのゲーム キャラクター データだけでなく、他の多くの有名なアニメ シリーズのデータもトレーニング セットに含めました。この動きによりモデルの知識ベースが充実し、さまざまなアニメのスタイルやキャラクターをより完全に理解できるようになります。 AnimagineXL3.1 では、特別なタグと美学の新しいセットが導入されています
 Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
FP8 以下の浮動小数点数値化精度は、もはや H100 の「特許」ではありません。 Lao Huang は誰もが INT8/INT4 を使用できるようにしたいと考え、Microsoft DeepSpeed チームは NVIDIA からの公式サポートなしで A100 上で FP6 の実行を開始しました。テスト結果は、A100 での新しい方式 TC-FPx の FP6 量子化が INT4 に近いか、場合によってはそれよりも高速であり、後者よりも精度が高いことを示しています。これに加えて、エンドツーエンドの大規模モデルのサポートもあり、オープンソース化され、DeepSpeed などの深層学習推論フレームワークに統合されています。この結果は、大規模モデルの高速化にも即座に影響します。このフレームワークでは、シングル カードを使用して Llama を実行すると、スループットはデュアル カードのスループットの 2.65 倍になります。 1つ
