

ご覧のとおり、softmax は複数のニューロンの入力を計算します。バックプロパゲーションを導出するときは、さまざまなニューロンのパラメーターを導出することを考慮する必要があります。
2 つの状況を考えてみましょう。
導出用のパラメータが分子にある場合
導出用のパラメータが分子にある場合分母が
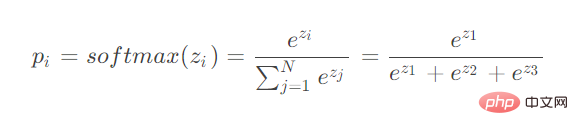
の場合 導出用パラメータが分子の場合:
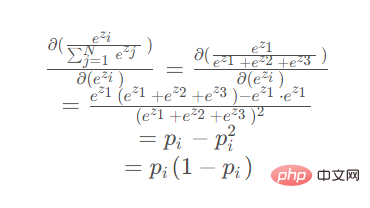
導出時 パラメータが分母にある場合 (ez2 または ez3 が対称で導出結果は同じ):
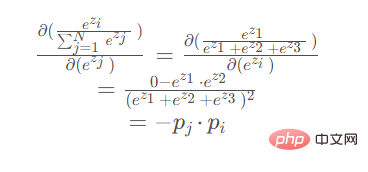
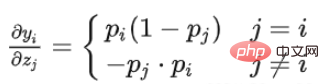
import torch
import math
def my_softmax(features):
_sum = 0
for i in features:
_sum += math.e ** i
return torch.Tensor([ math.e ** i / _sum for i in features ])
def my_softmax_grad(outputs):
n = len(outputs)
grad = []
for i in range(n):
temp = []
for j in range(n):
if i == j:
temp.append(outputs[i] * (1- outputs[i]))
else:
temp.append(-outputs[j] * outputs[i])
grad.append(torch.Tensor(temp))
return grad
if __name__ == '__main__':
features = torch.randn(10)
features.requires_grad_()
torch_softmax = torch.nn.functional.softmax
p1 = torch_softmax(features,dim=0)
p2 = my_softmax(features)
print(torch.allclose(p1,p2))
n = len(p1)
p2_grad = my_softmax_grad(p2)
for i in range(n):
p1_grad = torch.autograd.grad(p1[i],features, retain_graph=True)
print(torch.allclose(p1_grad[0], p2_grad[i]))以上がPython でソフトマックス バックプロパゲーションを実装する方法。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



