

静的マルウェア分析を実行するには、.exe、.dll、.sys などの今日の Windows プログラムを記述する Windows PE ファイル形式を理解する必要があります。ファイルの数とデータの保存方法を定義します。 PE ファイルには、x86 命令、画像やテキストなどのデータ、およびプログラムの実行に必要なメタデータが含まれています。
PE フォーマットは元々、次の操作を実行するように設計されました。
1) プログラムをメモリにロードする方法を Windows に指示します。
PE 形式は、ファイルのどのブロックをメモリにロードするか、そしてどこにロードするかを記述します。また、プログラム コード内の Windows がプログラムの実行を開始する必要があるか、動的にリンクされたコード ライブラリをメモリにロードする必要があるかがわかります。
2) 実行中に使用できるメディア (またはリソース) を実行中のプログラムに提供します。
これらのリソースには、GUI ダイアログ ボックスやコンソールなどの文字列を含めることができます。出力文字列、画像またはビデオ。
3) デジタル コード署名などのセキュリティ データを提供する
Windows はこのセキュリティ データを使用して、コードが信頼できるソースからのものであることを確認します。
PE 形式は、図 1-1 に示す一連の構造を利用して上記の作業を実行します。
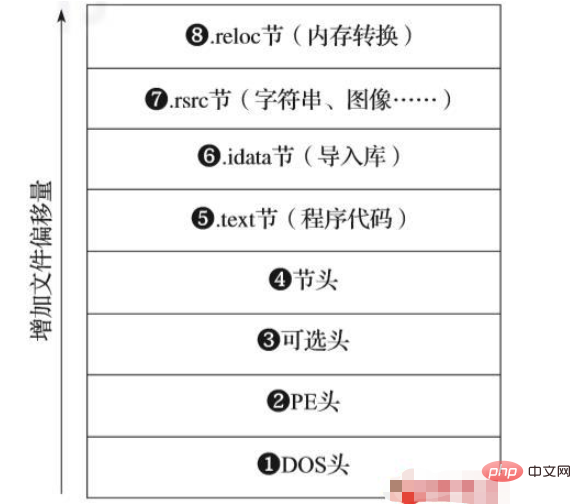
▲図 1-1 PE ファイル形式
図 1-1 に示すように、PE ファイル形式には、動作を指示するための一連のヘッダーが含まれています。システムのプログラムをメモリにロードする方法。また、実際のプログラム データを含む一連のセクションも含まれています。 Windows はこれらのセクションをメモリにロードし、メモリ内のオフセットがディスク上のセクションの位置に対応するようにします。
PE ヘッダーから始めて、このファイル構造をさらに詳しく見てみましょう。 DOS ヘッダーについては説明を省略します。DOS ヘッダーは 1980 年代の Microsoft DOS オペレーティング システムからの名残であり、互換性の理由のみで存在します。
1. PE ヘッダ
図 1-1 の下部に示すように、DOS ヘッダー ❶ の上には PE ヘッダー ❷ があり、DOS ヘッダー ❷ の一般的な属性を定義します。プログラム (バイナリ コード、画像、圧縮データ、その他のプログラム プロパティなど)。また、プログラムが 32 ビット システム用に設計されているか、64 ビット システム用に設計されているかもわかります。
PE ヘッダーは、マルウェア アナリストにとって基本的だが役立つコンテキスト情報を提供します。たとえば、ヘッダーには、マルウェア作成者がファイルをコンパイルした時刻を示すタイムスタンプ フィールドが含まれています。通常、マルウェア作成者はこのフィールドを偽の値に置き換えますが、マルウェア作成者がこのフィールドを置き換えることを忘れて、このようなことが発生する場合があります。
2. オプションのヘッダー
オプションのヘッダー ❸ は、実際には今日の PE 実行可能ファイルのいたるところにあり、その名前が示すものとはまったく逆です。これは、PE ファイル内のプログラム エントリ ポイントの場所を定義します。これは、プログラムがロードされた後に実行される最初の命令を指します。
また、PE ファイル、Windows サブシステム、ターゲット プログラム (Windows GUI や Windows コマンド ラインなど)、およびその他の高レベルの詳細をロードするときに Windows がメモリにロードするデータのサイズも定義します。プログラム。プログラムのエントリ ポイントはリバース エンジニアリングにどこからリバース エンジニアリングを開始するかを指示するため、このヘッダー情報はリバース エンジニアリングにとって非常に貴重です。
3. セクションヘッダ
セクションヘッダ❹は、PE ファイルに含まれるデータセクションを記述します。 PE ファイルのセクションは、オペレーティング システムがプログラムをロードするときにメモリにマップされるデータの一部であり、プログラムをメモリにロードする方法についての指示が含まれています。
言い換えると、セクションはディスク上のバイトのシーケンスであり、メモリ内で連続したバイトの文字列になるか、読み込みプロセスの一部についてオペレーティング システムに通知します。
セクション ヘッダーは、プログラムの実行時に読み取り可能、書き込み可能、または実行可能であるかどうかなど、セクションにどのようなアクセス許可を付与する必要があるかを Windows に指示します。たとえば、x86 コードを含む .text セクションは、実行中にプログラム コードが誤って変更されるのを防ぐために、読み取り可能および実行可能であるが書き込み可能ではないとマークされることがよくあります。
図 1-1 は、.text や .rsrc などの多くのセクションを示しています。 PE ファイルが実行されると、それらはメモリにマップされます。 .reloc セクションなどの他の特別なセクションはメモリにマップされないため、これらのセクションについても説明します。図 1-1 に示すセクションを見てみましょう。
1).text セクション
すべての PE プログラムには、セクション ヘッダーで実行可能としてマークされた x86 コードのセクションが少なくとも 1 つ含まれており、これらのセクションにはほとんどの場合 .text という名前が付けられます❺ 。
2).idata セクション
.idata セクション ❻ (インポート セクションとも呼ばれる) には、ダイナミック リンク ライブラリをリストするインポート アドレス テーブル (IAT) が含まれています。とその機能。 IAT は、プログラムが呼び出すライブラリを示すため、PE バイナリの初期分析中に確認する必要がある最も重要な PE 構造の 1 つですが、これらの呼び出しによってマルウェアの高度な機能が明らかになる可能性があります。
3) データ セクション
PE ファイル構造のデータ セクションには、.rsrc、.data、および .rdata セクションを含めることができます。これらのセクションには、プログラム 画像、ボタンアイコン、音声、その他のメディアなどたとえば、図 1-1 の .rsrc セクションには、プログラムがテキストを文字列として表示するために使用する印刷可能な文字列が含まれています。
.rsrc (リソース) セクションの情報は、マルウェア アナリストにとって非常に重要です。PE ファイル内の印刷可能な文字列、グラフィック イメージ、その他の資産を調べることで、ファイルの機能に関する重要な手がかりを得ることができるからです。
セクション 03 では、icoutils ツールキット (icotool および wrestool を含む) を使用して、マルウェア バイナリのリソース セクションからグラフィック イメージを抽出する方法を学びます。次に、セクション 04 では、マルウェア リソース セクションから印刷可能な文字列を抽出する方法を学びます。
4).reloc セクション
PE バイナリのコードは位置に依存しません。つまり、予期されるメモリ位置から新しいメモリに移動されると、場所が異なると、正しく実行されません。 .reloc❽ は、コードを壊さずに移動できるようにすることで、この問題を解決します。
PE ファイルのコードが移動された場合、コードが引き続き正しく実行できるように、ファイルのコード内でメモリ アドレス変換を実行するように Windows オペレーティング システムに指示します。これらの変換には通常、メモリ アドレスへのオフセットの加算または減算が含まれます。
Ero Carerra によって作成および保守されている Python モジュール pefile は、PE ファイルを解析するための業界標準のマルウェア分析ライブラリになりました。このセクションでは、pefile を使用して ircbot.exe を解析する方法を説明します。コード リスト 1-1 では、ircbot.exe が現在の作業ディレクトリにすでに存在していることを前提としています。
次のコマンドを入力して pefile ライブラリをインストールし、Python にインポートできるようにします:
$ pip install pefile
次に、リスト 1-1 のコマンドを使用して Python を起動し、pefile モジュールをインポートし、次に、pefile を使用して PE ファイル ircbot.exe を開いて解析します。
コード リスト 1-1 pefile モジュールをロードし、PE ファイル (ircbot.exe) を解析します
$ python >>> import pefile >>> pe = pefile.PE("ircbot.exe")この例では、PE モジュールによって実装されるコア クラスである pefile.PE を変更します。 PE ファイルを解析して、そのプロパティを表示できるようにします。 PE コンストラクターを呼び出すことで、指定された PE ファイル (この場合は ircbot.exe) をロードして解析します。このファイルをロードして解析したので、リスト 1-2 のコードを実行して、ircbot.exe の pe フィールドから情報を抽出します。
コード リスト 1-2 PE ファイルのさまざまなセクションをループし、それらに関する情報を出力します
#基于 Ero Carrera的示例代码(pefile库的作者) for section in pe.sections: print(section.Name, hex(section.VirtualAddress), hex(section.Misc_VirtualSize), section.SizeOfRawData)
コード リスト 1-3 は、印刷出力の内容を示しています。
コード リスト 1-3 Python の pefile モジュールを使用して ircbot.exe からセクション データを抽出します
PE からセクション データを抽出しますファイル 5 データは、.text、.rdata、.data、.idata、.reloc の 3 つの異なるセクションから抽出されます。出力は 5 つのタプルの形式で提供され、PE セクションごとに 1 つの要素が抽出されます。各行の最初のエントリは PE セクションを識別します。 (一連の \\x00 null バイトは無視してかまいません。これらは単なる C スタイルの空の文字列終端文字です。) 残りのフィールドは、各セクションがメモリにロードされると、そのメモリ使用量がどのくらいになるか、メモリ内のどこにあるかを示します。ロードされると見つかります。
たとえば、0x1000❶ は、これらのセクションをロードするためのベース仮想メモリ アドレスであり、セクションのベース メモリ アドレスとみなすこともできます。仮想サイズ フィールドの 0x32830❷ は、セクションのロード後に必要なメモリ サイズを指定します。 3 番目のフィールドの 207360❸ は、このセクションがこのメモリ ブロック内で占めるデータ量を示します。
pefile を使用してプログラムのセクションを解析するだけでなく、バイナリがロードする DLL ファイルと、それらの DLL ファイル内で要求される関数呼び出しをリストするためにも使用できます。これは、PE ファイルの IAT をミラーリング (ダンプ) することで実現できます。コード リスト 1-4 は、pefile を使用して ircbot.exe の IAT をミラーリングする方法を示しています。
コード リスト 1-4 ircbot.exe からインポート情報を抽出します
$ python pe = pefile.PE("ircbot.exe") for entry in pe.DIRECTORY_ENTRY_IMPORT: print entry.dll for function in entry.imports: print '\t', function.nameコード リスト 1-4 は次の結果を生成します。出力をリスト 1-5 に示します (簡潔にするために出力は省略されています)。
#コード リスト 1-5 ircbot.exe の IAT テーブルの内容。このマルウェアによって使用されるライブラリ関数が示されています。
你还可以在恶意软件中找到攻击者自己感兴趣程序中的图像,例如攻击者为远程控制受感染机器而运行的网络攻击工具和程序。
回到我们的样本图像分析,你可以在本文的数据目录中找到名为fakepdfmalware.exe的这个恶意软件样本。这个样本使用Adobe Acrobat图标诱骗用户认为它是一个Adobe Acrobat文档,而实际上它是一个恶意的PE可执行文件。
在我们使用Linux命令行工具wrestool从二进制文件fakepdfmalware.exe中提取图像之前,我们首先需要创建一个目录来保存我们将提取的图像。代码清单1-6显示了如何完成所有这些操作。
代码清单1-6 从恶意软件样本中提取图像的Shell命令
$ mkdir images $ wrestool -x fakepdfmalware.exe -output=images $ icotool -x -o images images/*.ico
我们首先使用mkdir images创建一个目录来保存提取的图像。接下来,我们使用wrestool从fakepdfmalware.exe中提取图像资源(-x)到/images目录,然后使用icotool提取(-x)并将Adobe中.ico图标格式中的所有资源转换(-o)为.png图形,以便我们可以使用标准的图像浏览工具查看们。
如果你的系统上没有安装wrestool,你可以从这里下载:
http://www.nongnu.org/icoutils/
一旦你使用wrestool将目标可执行文件中的图像转换为PNG格式,你就可以在你喜欢的图像浏览工具中打开它们,并以各种分辨率查看Adobe Acrobat图标。
正如我在这里给出的例子所示,从PE文件中提取图像和图标相对简单,可以快速显示与恶意软件二进制文件相关的有趣且又有用的信息。同样地,我们可以轻松地从恶意软件中提取可打印字符串来获取更多信息,我们接下来会做这项工作。
字符串是程序二进制文件中可打印字符的序列。恶意软件分析师通常依赖恶意样本中的字符串来快速了解其中可能发生的情况。这些字符串通常包含下载网页和文件的HTTP和FTP命令,用于告诉你恶意软件连接到的地址的IP地址和主机名等类似信息。
有时,即使用于编写字符串的语言也有可能暗示恶意软件二进制文件的来源国,尽管这可能是伪造的。你甚至可以在一个字符串中找到一些文本,它们用网络用语解释了恶意二进制文件的用途。
字符串还可以显示有关二进制文件的更多技术信息。例如,你可能会发现有关用于创建二进制文件的编译器、编写二进制文件所使用的编程语言、嵌入式脚本或HTML等信息。
虽然恶意软件作者可以对所有这些痕迹进行混淆、加密和压缩等处理,但是即便是高水平的恶意软件作者也经常会暴露并留下一些痕迹,因此在分析恶意软件时,对镜像的字符串进行细致检查显得尤为重要。
1. 使用字符串程序
查看文件中所有字符串的标准方法是使用命令行工具strings,按照以下语法进行使用:
$ strings filepath | less
该命令将文件中的所有字符串逐行打印到终端上。在末尾添加 | less可以防止字符串在终端上跨屏显示。默认情况下,strings命令查找所有最小长度为4字节的可打印字符串,但是你可以设置不同的最小长度并更改“命令手册”中所列各种其他参数。
我建议只使用默认的最小字符串长度4,但是你可以使用-n选项更改最小字符串长度。例如,“string -n 10 filepath”只提取最小长度为10字节的字符串。
2. 分析镜像字符串
现在我们镜像了一个恶意软件程序的可打印字符串,但是挑战在于要理解这些字符串的含义。例如,假设我们将ircbot.exe中的字符串镜像到ircbotstring.txt文件中,这在本文前面的内容中,我们使用pefile库已经进行了探讨,如下所示:
$ strings ircbot.exe > ircbotstring.txt
ircbotstring.txt的内容包含数千行文本,但其中一些行应该突出显示出来。例如,代码清单1-7显示了从字符串镜像中提取出来的一串以单词DOWNLOAD开头的行。
代码清单1-7 显示恶意软件可以将攻击者指定的文件下载到目标计算机的字符串输出
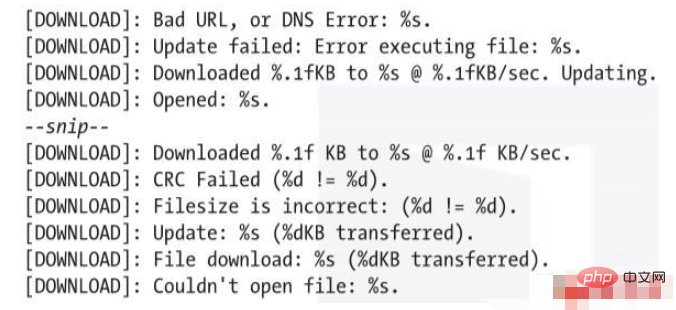
这些行表示ircbot.exe将尝试把攻击者指定的文件下载到目标计算机上。
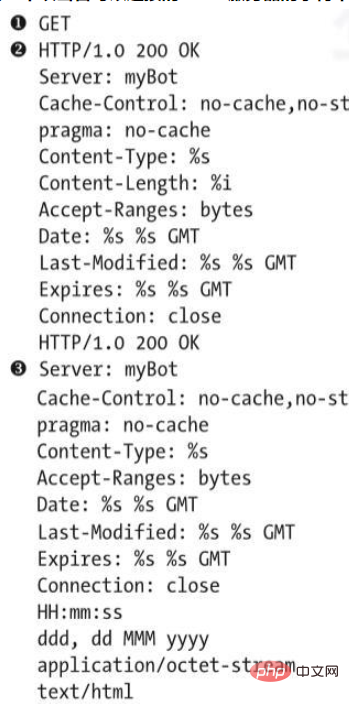
我们来尝试分析另一个。代码清单1-8所示的字符串镜像表明ircbot.exe可以起到Web服务器的作用,在目标机器上侦听来自攻击者的连接。
#コード リスト 1-8 マルウェアに攻撃者が接続できる HTTP サーバーがあることを示す文字列出力
以上がPython がマルウェアを識別する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



