

人民大学ヒルハウス人工知能大学院の Nature サブジャーナルは、マルチモーダル基本モデルを使用して一般的な人工知能に移行することを試みています

最近、中国人民大学ヒルハウス人工知能大学院の陸志烏教授、孫昊常任准教授、文吉龍学部長が、国際総合誌「Nature Communications」(英語名: Nature Communications (Nat Commun と呼ばれます) ) は、「マルチモーダル基盤モデルを介した汎用人工知能に向けて」というタイトルの研究論文を発表しました。この記事の最初の著者は、博士課程の学生である Fei Nanyi です。この研究は、一般的な人工知能に向けてマルチモーダル基本モデルを活用することを試みており、神経科学や医療などのさまざまな AI 分野に広範な影響を与えるでしょう。この記事はこの論文の解釈です。

- 論文リンク: https://www.nature.com/articles /s41467-022-30761-2
- コードリンク: https://github.com/neilfei/brivl-nmi
人工知能の基本的な目標は、知覚、記憶、推論など、人間の中核となる認知活動を模倣することです。多くの人工知能アルゴリズムやモデルがさまざまな研究分野で大きな成功を収めていますが、ほとんどの人工知能研究は、大量のラベル付きデータの取得や、大規模データのトレーニングをサポートするための不十分なコンピューティング リソースによって依然として制限されています。単一の認知能力。
これらの制限を克服し、一般的な人工知能への一歩を踏み出すために、私たちはマルチモーダル (視覚言語) 基本モデル、つまり事前トレーニング済みモデルを開発しました。さらに、モデルが強力な汎化能力を獲得するために、トレーニング データ内の画像とテキストは、画像領域と単語の厳密な一致ではなく、弱い意味相関仮説 (図 1b に示すように) に従う必要があることを提案します。 (強力な意味的相関)、強い意味的相関のため 意味的相関を仮定すると、人々が写真にキャプションを付けるときに暗示する複雑な感情や思考がモデルから失われます。
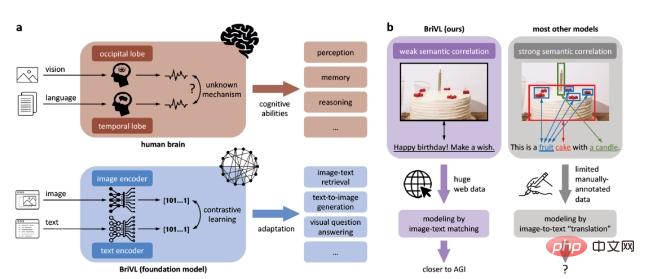

# 図 1: 弱い意味相関の仮定に基づく BriVL モデル。 a. 視覚言語情報の処理における BriVL モデルと人間の脳との比較。 b. 意味論的に弱く関連したデータのモデリングと意味論的に強く関連したデータのモデリングの比較。
インターネットからクロールした大規模な画像やテキストデータを学習させることにより、得られたマルチモーダル基本モデルは、強力な一般化能力と想像力を示します。私たちは、私たちの研究が一般的な人工知能に向けた重要な (潜在的に小さいとはいえ) 一歩を表し、神経科学や医療などのさまざまな AI 分野に広範な影響を与えると信じています。
方法大規模なマルチモーダルデータに対する自己教師ありトレーニングのための大規模マルチモーダル基本モデルを開発し、それを BriVL (Bridging-Vision) と名付けました。 -と言語)。
まず、弱セマンティック相関データセット (WSCD) と呼ばれる、インターネットから構築された大規模なマルチソースのグラフィックおよびテキスト データセットを使用します。 WSCD は、ニュース、百科事典、ソーシャル メディアなど、ウェブ上の複数のソースから中国語の画像とテキストのペアを収集します。自然なデータ分布を維持するために、元のデータを編集または変更することなく、WSCD 内のポルノおよび機密データのみをフィルタリングして除外しました。全体として、WSCD にはスポーツ、日常生活、映画などの多くのトピックをカバーする約 6 億 5,000 万の絵とテキストのペアが含まれています。
第二に、ネットワーク アーキテクチャに関しては、画像とテキストの間には必ずしも地域の詳細な単語一致が存在しないため、時間のかかるオブジェクト検出器を破棄し、シンプルなダブル タワー アーキテクチャを採用します。したがって、2 つの独立したエンコーダを介して画像とテキスト入力をエンコードできます (図 2)。ツインタワー構造には、クエリを実行する前に候補セットの特徴を計算してインデックスを付けることができ、現実世界のアプリケーションのリアルタイム要件を満たすことができるため、推論プロセスにおいて明らかな効率上の利点があります。第三に、大規模分散トレーニング技術と自己教師あり学習の開発により、大量のラベルなしマルチモーダルデータを使用してモデルをトレーニングすることが可能になりました。
具体的には、画像とテキストのペアの弱い相関をモデル化し、統一された意味空間を学習するために、シングルモーダル対比学習法 MoCo に基づいたクロスモーダル対比学習アルゴリズムを設計しました。図 2 に示すように、BriVL モデルはモメンタム メカニズムを使用して、さまざまなトレーニング バッチでネガティブ サンプル キューを動的に維持します。このようにして、GPU メモリの使用量を削減する (つまり GPU リソースの節約) ために比較的小さなバッチ サイズを使用しながら、比較的多数の負のサンプル (対比学習に不可欠) を得ることができます。
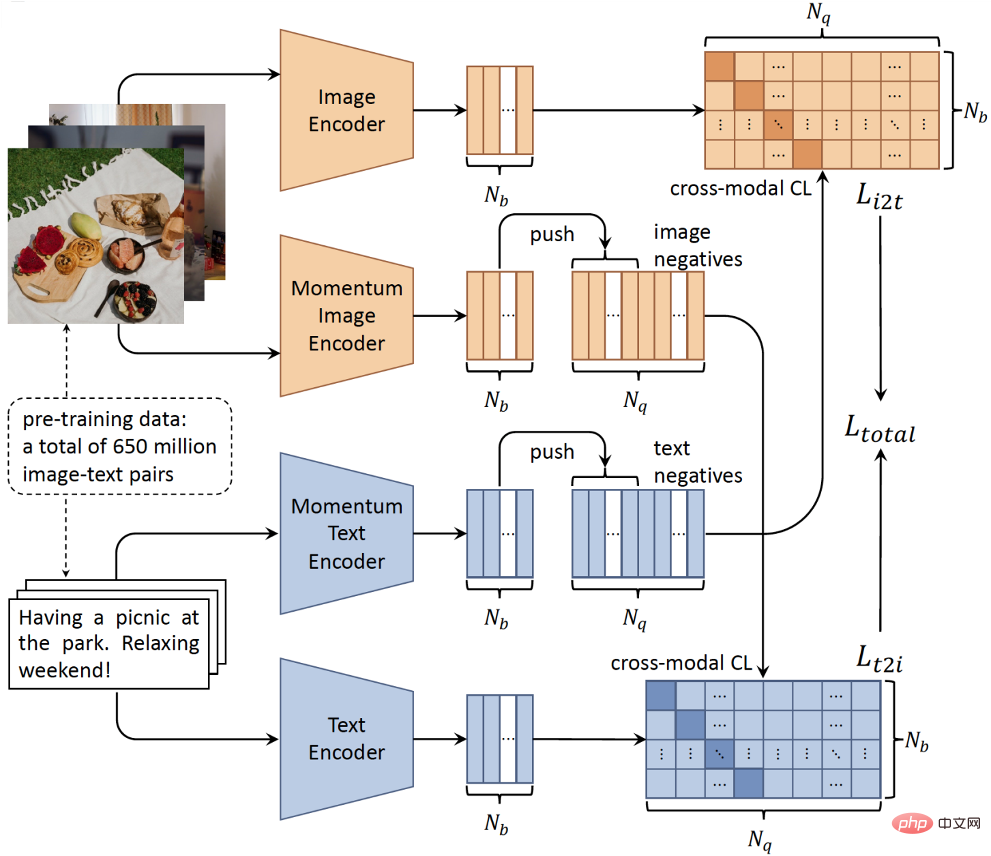
図 2: 大規模なマルチモーダル事前トレーニング用の BriVL モデルの概略図。
主な結果
ニューラル ネットワークの可視化
単語や説明文を聞くと、何かが頭に浮かびます。 BriVL の場合、相関の弱い画像とテキストの多数のペアで事前トレーニングされた後、テキストが与えられたときに何を想像するかについて非常に興味があります。
具体的には、まずテキストを入力し、BriVL のテキスト エンコーダーを通じてそのテキスト埋め込みを取得します。次に、ノイズのある画像をランダムに初期化し、画像エンコーダーを通じてその特徴を埋め込みます。入力画像はランダムに初期化されるため、その特徴は入力テキストの特徴と一致しない必要があります。したがって、2 つの特徴埋め込みを一致させるという目標を定義し、バックプロパゲーションを介して入力画像を更新します。結果の画像は、BriVL が入力テキストをどのように想像したかを明確に示しています。ここでは追加のモジュールやデータを使用せず、事前トレーニングされた BriVL も視覚化プロセス全体を通じてフリーズされます。
最初に、いくつかの高レベルの意味概念を想像する BriVL の機能を紹介します (図 3)。ご覧のとおり、これらの概念は非常に抽象的ですが、視覚化ではその具体的な形式を示すことができます (例: 「自然」: 草のような植物、「時間」: 時計、「科学」: メガネと三角錐を付けた顔)フラスコ; 「ドリームランド」: 雲、ドアへの橋、そして夢のような雰囲気)。抽象的な概念を一連の具体的なオブジェクトに一般化するこの機能は、意味的に関連性の低いデータのみを使用したマルチモーダル事前トレーニングの有効性を示しています。

図 3: BriVL モデルによる抽象概念の想像。
図 4 は、BriVL の文章に対する想像力を示しています。 BriVL の「雲の向こうに日差しがある」という想像は、文字通り雲の向こうに日差しがあるだけでなく、海上の危険な状況(左側に船のような物体や波がある)を示しているようにも見え、その暗黙の意味を表現しています。文 。ビジュアライゼーション「夏の花として咲く」では、花の群れが見られます。次の 2 つのシナリオのより複雑なテキスト入力は、両方とも古代中国の詩からのものであり、その構文はトレーニング セット内の大部分のテキストとは完全に異なります。 BriVLでもよく理解できるようで、「竹の外に桃の花が三、二枝」では竹とピンクの花があることがわかり、「太陽は山の向こうにあり、黄河は山に流れ込んでいる」ということが分かります。山の木々が夕日を隠し、目の前の川には小さな船が見えます。全体として、BriVL は、複雑な文によって促された場合でも、高い想像力を維持していることがわかりました。


図 4: BriVL モデルによる中国語の文の想像。
図 5 では、BriVL のニューラル ネットワークの視覚化にいくつかの同様のテキストが使用されています。 「森のある山」の場合は、画像内の緑の領域が増えます。「石のある山」の場合、画像内の岩が増えます。「雪のある山」の場合、中央の木の周りの地面は白または青です。「山」の場合「滝」では、青い水が流れ落ちるのが見え、水蒸気も見えます。これらの視覚化は、BriVL が山の修飾子を正確に理解し、想像できることを示しています。

図 5: BriVL モデルの「…のある山」の想像。
#テキスト生成図ニューラル ネットワークの視覚化は非常に簡単ですが、解釈が難しい場合があります。そこで私たちは、BriVL の想像上のコンテンツを人間がよりよく理解できるように、代替の視覚化/解釈可能アプローチを開発しました。具体的には、ImageNet データセットで事前トレーニングされた VQGAN はリアルな画像の生成に非常に優れているため、VQGAN を利用して BriVL の指導の下で画像を生成します。まずトークンシーケンスをランダムに取得し、事前トレーニングされた VQGAN から生成された画像を取得します。次に、生成された画像を BriVL の画像エンコーダに送り、テキストの一部をテキスト エンコーダに送ります。最後に、画像とテキストの埋め込み間のマッチングのターゲットを定義し、バックプロパゲーションによって初期トークン シーケンスを更新します。ニューラル ネットワークの視覚化と同様に、VQGAN と BriVL は両方とも生成プロセス中にフリーズされます。比較のために、BriVL の代わりに OpenAI の CLIP モデルによって生成された画像も示します。
最初に 4 つのテキスト入力を選択し、CLIP と BriVL のテキスト生成グラフの結果をそれぞれ図 6 と図 7 に示しました。 CLIP と BriVL はどちらもテキストをよく理解しますが、2 つの大きな違いもあります。まず、CLIP で生成された画像には漫画風の要素が表示されますが、BriVL で生成された画像はより現実的で自然です。第 2 に、CLIP は単純に要素をまとめて配置する傾向があるのに対し、BriVL はよりグローバルに統一された画像を生成します。最初の違いは、CLIP と BriVL で使用されるトレーニング データが異なるためである可能性があります。トレーニング データ内の画像はインターネットから収集されたもの (ほとんどが実際の写真) ですが、CLIP のトレーニング データには一定数の漫画画像が含まれている場合があります。 2 番目の違いは、CLIP が強い意味的相関関係を持つ画像とテキストのペアを (単語フィルタリングを通じて) 使用するのに対し、私たちは相関関係の弱いデータを使用するという事実によるものと考えられます。これは、マルチモーダル事前トレーニング中、CLIP は特定のオブジェクトと単語/フレーズ間の対応関係を学習する可能性が高いのに対し、BriVL は指定されたテキストを含む各画像を全体として理解しようとすることを意味します。

図 6: CLIP (ResNet-50x4 使用) は VQGAN を使用してテキスト生成グラフの例を実現します。


# 図 7: BriVL の例グラフを生成するための VQGAN 実装。
また、複数の連続する文に基づいて一連の画像を生成するという、より困難なタスクも検討しました。図 8 に示すように、各画像は独立して生成されていますが、4 つの画像が視覚的に一貫しており、同じスタイルであることがわかります。これは、BriVL モデルのもう 1 つの利点を示しています。画像内の環境と背景は、関連するテキストで明示的に言及するのが難しいにもかかわらず、大規模なマルチモーダル事前トレーニングでは無視されません。

図 8: VQGAN を使用して一連の一貫したコンテンツを生成する BriVL の例。
図 9 では、現実には存在しない概念/シナリオ (例: "サイバーパンクシティ」と「雲の上の城」)。これは、BriVL の優れたパフォーマンスが事前トレーニング データへの過剰適合から得られるものではないことを証明します。なぜなら、ここで入力された概念/シナリオは現実には存在すらしないからです (もちろん、事前トレーニング データセットには存在しない可能性が最も高いです)。 )。さらに、これらの生成された例は、意味的に関連性の低いデータで BriVL を事前トレーニングすることの利点を再確認します (きめ細かい地域単語のアライメントは BriVL の想像力を損なうため)。

図 9: BriVL テキスト生成グラフの結果の詳細、概念/シナリオは次のとおりです。現実にはあまり見られないか、存在すらしません。
さらに、リモート センシング画像のゼロサンプル分類、中国ニュースのゼロサンプル分類、視覚的な質疑応答など、複数の下流タスクにも BriVL を適用しました。詳細については、論文の原文を参照してください。
結論と考察私たちは、意味的に関連性の低い 6 億 5,000 万の画像とテキストを操作する、BriVL と呼ばれる大規模なマルチモーダル基本モデルを開発しました。ニューラル ネットワークの視覚化とテキスト生成のグラフを通じて、位置合わせされた画像とテキストの埋め込み空間を直感的に示します。さらに、他の下流タスクの実験でも、BriVL のクロスドメイン学習/転送機能と、シングルモーダル学習に対するマルチモーダル学習の利点が示されています。特に、BriVL は想像力と推論力をある程度獲得しているようであることがわかりました。これらの利点は主に、BriVL に従う弱いセマンティック相関の仮定から来ると考えられます。つまり、相関の弱い画像とテキストのペアで人間の複雑な感情や思考をマイニングすることにより、BriVL の認知力が向上します。
一般的な人工知能に向けて私たちが講じるこの一歩は、人工知能そのものの分野だけでなく、AI のすべての分野に広範な影響を与えると信じています。人工知能研究の場合、GPU リソースを節約するマルチモーダル事前トレーニング フレームワークに基づいて、研究者は BriVL をより大きな規模とより多くのモダリティに簡単に拡張して、より一般的なベース モデルを取得できます。大規模なマルチモーダル ベース モデルの助けを借りて、研究者が新しいタスク (特に十分なヒューマン アノテーション サンプルがないタスク) を探索することも容易になります。 AI の分野では、基本モデルはその強力な一般化機能により、特定の作業環境に迅速に適応できます。たとえば、ヘルスケアの分野では、マルチモーダル基本モデルは症例のマルチモーダルデータを最大限に活用して診断の精度を向上させることができ、神経科学の分野では、マルチモーダル基本モデルは、神経科学のメカニズムでマルチモーダル情報がどのように機能するかを解明するのにも役立つ可能性があります。人工ニューラルネットワークは、人間の脳の実際のニューラルシステムよりも研究が容易であるため、人間の脳における融合。
これにもかかわらず、マルチモーダル基本モデルは依然としていくつかのリスクと課題に直面しています。基本モデルは特定の事柄についての偏見や固定観念を学習する可能性があるため、これらの問題はモデルのトレーニング前に慎重に対処し、下流のアプリケーションで監視して対処する必要があります。また、基本モデルが機能を強化するにつれて、社会に悪影響を及ぼさないように、悪意を持った人々によって悪用されることにも注意する必要があります。さらに、基本モデルに関する今後の研究には、より深いモデル解釈ツールを開発する方法、より多くのモダリティを備えた事前トレーニング データセットを構築する方法、および基本モデルを変換するためのより効果的な微調整テクニックを使用する方法など、いくつかの課題もあります。モデル。さまざまな下流タスクに適用されます。
この論文の著者: Fei Nanyi、Lu Zhiwu、Gao Yizhao、Yang Guoxing、Huo Yuqi、Wen Jingyuan、Lu Haoyu、Song Ruihua、Gao Xin、Xiang Tao、Sunハオ、ウェン・ジロン ; 共同執筆者は、中国人民大学ヒルハウス人工知能大学院のLu Zhiwu教授、Sun Hao常任准教授、Wen Jiron教授です。論文は国際総合誌「Nature Communications」(英語名:Nature Communications、略称:Nat Commun)に掲載された。この論文はFei Nanyiによって通訳されました。
###以上が人民大学ヒルハウス人工知能大学院の Nature サブジャーナルは、マルチモーダル基本モデルを使用して一般的な人工知能に移行することを試みていますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック



 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI は確かに数学を変えつつあります。最近、この問題に細心の注意を払っている陶哲軒氏が『米国数学協会会報』(米国数学協会会報)の最新号を送ってくれた。 「機械は数学を変えるのか?」というテーマを中心に、多くの数学者が意見を述べ、そのプロセス全体は火花に満ち、ハードコアで刺激的でした。著者には、フィールズ賞受賞者のアクシャイ・ベンカテシュ氏、中国の数学者鄭楽軍氏、ニューヨーク大学のコンピューター科学者アーネスト・デイビス氏、その他業界で著名な学者を含む強力な顔ぶれが揃っている。 AI の世界は劇的に変化しています。これらの記事の多くは 1 年前に投稿されたものです。
 Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google が推進する JAX のパフォーマンスは、最近のベンチマーク テストで Pytorch や TensorFlow のパフォーマンスを上回り、7 つの指標で 1 位にランクされました。また、テストは最高の JAX パフォーマンスを備えた TPU では行われませんでした。ただし、開発者の間では、依然として Tensorflow よりも Pytorch の方が人気があります。しかし、将来的には、おそらくより大規模なモデルが JAX プラットフォームに基づいてトレーニングされ、実行されるようになるでしょう。モデル 最近、Keras チームは、ネイティブ PyTorch 実装を使用して 3 つのバックエンド (TensorFlow、JAX、PyTorch) をベンチマークし、TensorFlow を使用して Keras2 をベンチマークしました。まず、主流のセットを選択します
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
 Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
FP8 以下の浮動小数点数値化精度は、もはや H100 の「特許」ではありません。 Lao Huang は誰もが INT8/INT4 を使用できるようにしたいと考え、Microsoft DeepSpeed チームは NVIDIA からの公式サポートなしで A100 上で FP6 の実行を開始しました。テスト結果は、A100 での新しい方式 TC-FPx の FP6 量子化が INT4 に近いか、場合によってはそれよりも高速であり、後者よりも精度が高いことを示しています。これに加えて、エンドツーエンドの大規模モデルのサポートもあり、オープンソース化され、DeepSpeed などの深層学習推論フレームワークに統合されています。この結果は、大規模モデルの高速化にも即座に影響します。このフレームワークでは、シングル カードを使用して Llama を実行すると、スループットはデュアル カードのスループットの 2.65 倍になります。 1つ
