

YOLOv6 の高速かつ正確なターゲット検出フレームワークがオープンソース化されました

著者: Chu Yi、Kai Heng など
最近、Meituan のビジュアル インテリジェンス部門は、検出精度と推論効率を同時に重視できる産業アプリケーション専用のターゲット検出フレームワーク YOLOv6 を開発しました。時間。研究開発プロセス中、ビジュアル インテリジェンス部門は、学界や産業界からの最先端の開発や科学研究の結果を活用しながら、探索と最適化を続けました。信頼できるターゲット検出データセットである COCO での実験結果では、YOLOv6 が検出精度と速度の点で同規模の他のアルゴリズムを上回っていることが示されており、さまざまな異なるプラットフォームの展開もサポートしており、プロジェクト展開時の適応作業が大幅に簡素化されています。 。これはオープンソースであり、より多くの学生を支援することを期待しています。
1. 概要
YOLOv6 は、Meituan のビジュアル インテリジェンス部門によって開発されたターゲット検出フレームワークであり、産業用アプリケーションに特化しています。このフレームワークは、検出精度と推論効率の両方に重点を置いており、業界で一般的に使用されているサイズ モデルの中で、YOLOv6-nano の精度は COCO で最大 35.0% AP、推論速度は です。 T4。1242 FPS; YOLOv6-s は、COCO で 43.1% AP の精度、T4 で 520 FPS の推論速度を達成できます。デプロイメントに関して、YOLOv6 は、GPU (TensorRT)、CPU (OPENVINO)、ARM (MNN、TNN、NCNN) などのさまざまなプラットフォームのデプロイメントをサポートします。これにより、プロジェクト展開時の適応作業が大幅に簡素化されます。現在、プロジェクトは Github、ポータル: YOLOv6 にオープンソース化されています。困っている友達は、Star にアクセスして収集し、いつでもアクセスしてください。
YOLOv5 や YOLOX をはるかに超える精度と速度を実現した新しいフレームワーク
オブジェクト検出は、コンピュータ ビジョン分野の基礎技術として、広く利用されています。中でも YOLO シリーズ アルゴリズムは、総合的なパフォーマンスが優れているため、ほとんどの産業アプリケーションで徐々に推奨されるフレームワークになりました。これまで、業界は多くの YOLO 検出フレームワークを導き出してきました。その中には、YOLOv5[1]、YOLOX[2]、PP-YOLOE[3] があります。最も代表的なパフォーマンスですが、実際に使用してみると、上記のフレームワークには速度と精度の点でまだ改善の余地があることがわかりました。これに基づいて、業界の既存の先進技術を研究および活用することにより、新しいターゲット検出フレームワーク YOLOv6 を開発しました。このフレームワークは、モデルのトレーニング、推論、マルチプラットフォーム展開などの産業アプリケーション要件の完全なチェーンをサポートし、ネットワーク構造やトレーニング戦略などのアルゴリズム レベルで多くの改善と最適化を行っています。COCO データ セットでは、YOLOv6同じサイズの他のアルゴリズムを上回る、関連する結果を以下の図 1 に示します。 1 YOLOv6 モデルの各サイズと他モデルのパフォーマンスの比較
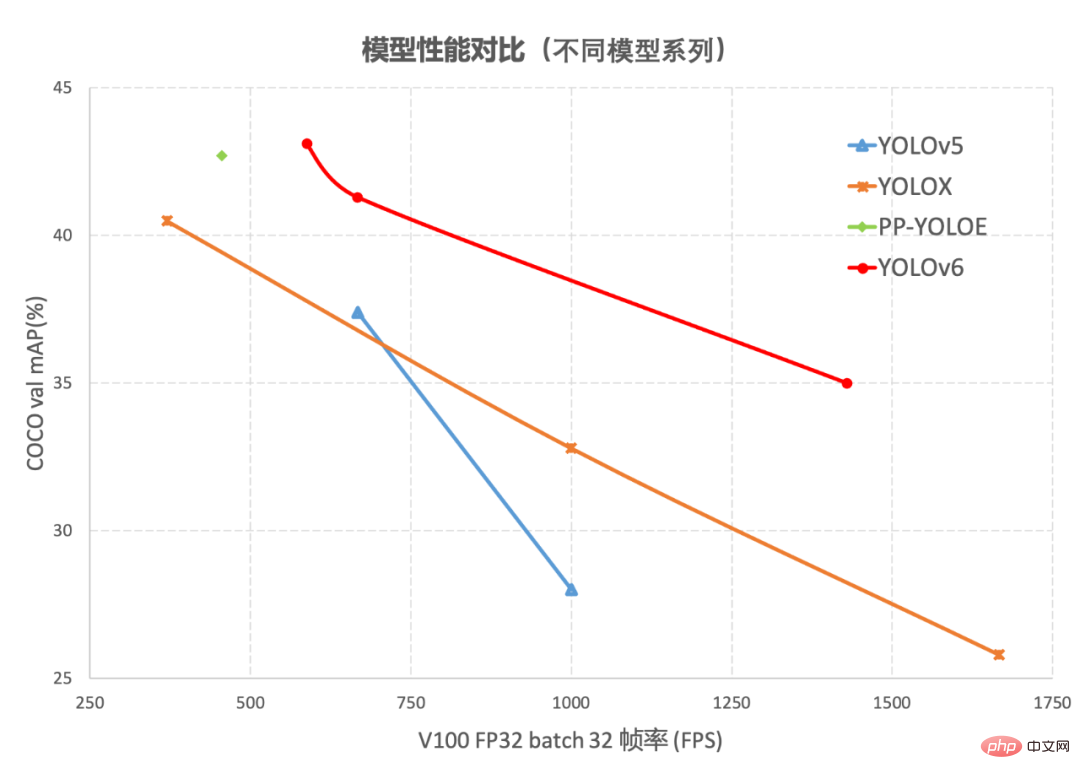
図 1-2 YOLOv6 と他のモデルのパフォーマンス比較異なる解像度の他のモデル
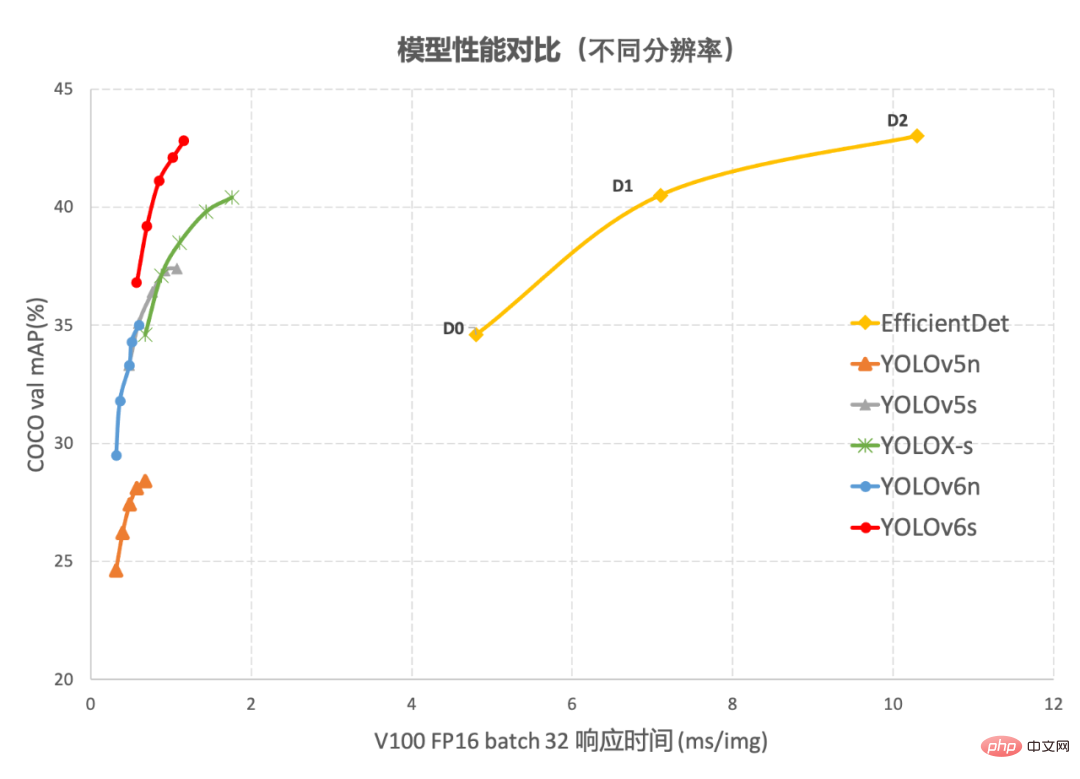 図 1-1
図 1-1
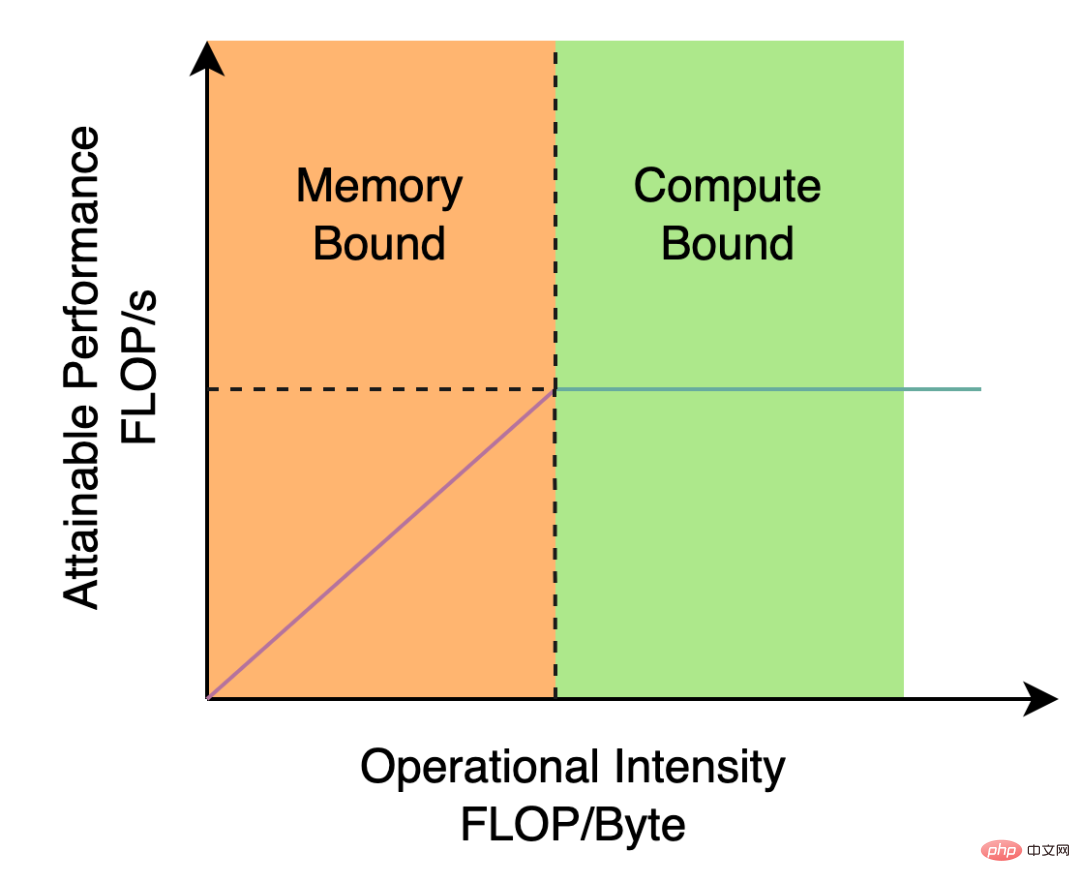
は、異なるサイズのネットワークにおける各検出アルゴリズムのパフォーマンスの比較を示しています。曲線上の点は、それぞれ検出アルゴリズムのパフォーマンスを表しています異なるサイズのネットワーク (s /tiny/nano) モデルのパフォーマンスでは、図からわかるように、YOLOv6 は精度と速度の点で同じサイズの他の YOLO シリーズ アルゴリズムを上回っています。 。 図 1-2 は、入力解像度が変化したときの各検出ネットワーク モデルのパフォーマンスの比較を示しています。曲線上の点は左から右に、画像解像度が順次増加するときを表します (384/448/512/576 / 640) このモデルのパフォーマンスは、図からわかるように、さまざまな解像度の下でも YOLOv6 が大きなパフォーマンス上の利点を維持しています。 2. YOLOv6 の主要テクノロジーの紹介YOLOv6 では、主に背骨、首、頭、トレーニング戦略において多くの改善が加えられています: YOLOv5/YOLOX で使用されるバックボーンとネックは両方とも CSPNet に基づいて構築されています[5] 、マルチブランチ アプローチと残差構造を使用します。 GPU などのハードウェアの場合、この構造によりレイテンシがある程度増加し、メモリ帯域幅の使用率が低下します。以下の図 2 は、コンピュータ アーキテクチャの分野におけるルーフライン モデル #[8] の紹介であり、ハードウェアのコンピューティング能力とメモリ帯域幅の関係を示しています。 図2 ルーフラインモデル紹介図 そこで、ハードウェアを意識したニューラル ネットワーク設計、バックボーンとネックが再設計され、最適化されました。この考え方は、ハードウェアの特性と推論フレームワーク/コンパイルフレームワークの特性を踏まえ、ハードウェアとコンパイルしやすい構造を設計原則とし、ハードウェアの計算能力、メモリ帯域幅などを総合的に考慮してネットワークを構築します。 、コンパイル最適化特性、ネットワーク表現機能などを確認し、高速で良好なネットワーク構造を取得します。上記の 2 つの再設計された検出コンポーネントについて、YOLOv6 ではそれぞれ EfficientRep Backbone と Rep-PAN Neck と呼びます。これらの主な貢献は次のとおりです: RepVGG[4] スタイル構造はトレーニング中はマルチブランチ トポロジであり、実際のデプロイメント中に単一の 3x3 に等価に融合できます。畳み込みの構造 (融合プロセスは以下の図 3 に示されています)。融合された 3x3 畳み込み構造により、計算集約型のハードウェア (GPU など) の計算能力を効果的に利用でき、GPU/CPU 上の高度に最適化された NVIDIA cuDNN および Intel MKL コンパイル フレームワークの助けも得られます。得られる。 。 実験の結果、上記の戦略により、YOLOv6 はハードウェア遅延を削減し、アルゴリズムの精度を大幅に向上させ、検出ネットワークをより高速かつ強力にすることがわかりました。ナノサイズモデルを例にとると、YOLOv5-nano で使用されるネットワーク構造と比較して、この方法では速度が 21% 向上し、精度が 3.6% AP 向上します。 図 3 Rep オペレーターの融合プロセス[4] EfficientRep Backbone: バックボーンの設計に関しては、上記の Rep オペレーターに基づいて効率的なバックボーンを設計しました。 YOLOv5 で使用される CSP-Backbone と比較して、この Backbone はハードウェア (GPU など) の計算能力を効率的に利用でき、強力な表現能力も備えています。 下の図 4 は EfficientRep Backbone の具体的な設計構造図で、Backbone の stride=2 の通常の Conv 層を stride=2 の RepConv 層に置き換えています。同時に、元の CSP ブロックは RepBlock に再設計され、RepBlock の最初の RepConv が変換され、チャネルの次元が調整されます。さらに、元の SPPF をより効率的な SimSPPF に最適化します。 図 4 EfficientRep バックボーン構造図 Rep-PAN:ネック設計に関しては、ハードウェアでの推論をより効率的にし、精度と速度のより良いバランスを達成するために、ハードウェアを意識したニューラル ネットワーク設計のアイデアに基づいて、YOLOv6 のより効果的な機能融合ネットワーク構造を設計しました。 Rep-PAN は PAN[6] トポロジに基づいており、RepBlock を使用して YOLOv5 で使用されている CSP-Block を置き換え、同時にネック全体のオペレーターを調整します。その目的は、ハードウェア上で効率的な推論を実現しながら、優れたマルチスケール機能融合機能を維持することです (Rep-PAN 構造図は以下の図 5 に示されています)。 図 5 Rep-PAN 構造図 YOLOv6 では、分離型検出ヘッド (Decoupled Head) 構造を採用し、設計を合理化しています。オリジナルの YOLOv5 の検出ヘッドは分類ブランチと回帰ブランチをマージして共有することによって実装されていますが、YOLOX の検出ヘッドは分類ブランチと回帰ブランチを分離し、さらに 2 つの 3x3 畳み込み層を追加しています。検出精度は向上していますが、ネットワーク遅延はある程度増加します。 したがって、関連する演算子の表現能力とハードウェアの計算オーバーヘッドとのバランスを考慮してデカップリング ヘッドの設計を合理化し、ハイブリッドを使用して再設計しました。チャネル戦略 より効率的なデカップリング ヘッド構造が開発され、精度を維持しながら遅延が削減され、デカップリング ヘッドの 3x3 畳み込みによって生じる追加の遅延オーバーヘッドが軽減されます。ナノサイズのモデルでアブレーション実験を実施し、同じチャネル数のデカップリングヘッド構造を比較することにより、精度が 0.2% AP 向上し、速度が 6.8% 向上しました。 2.3 より効果的なトレーニング戦略 アンカーフリーアンカーフリーパラダイム YOLOv6 は、より簡潔なアンカーフリー検出方法を採用しています。アンカーベースの検出器は、トレーニング前にクラスター分析を実行して最適なアンカー セットを決定する必要があるため、検出器の複雑さがある程度増加します。同時に、一部のエッジエンド アプリケーションでは、多数の検出結果が発生します。ハードウェアステップ間で転送する必要がある場合も、追加の遅延が発生します。アンカーフリーアンカーフリーパラダイムは、その強力な一般化能力とより単純なデコードロジックにより、近年広く使用されています。アンカーフリーに関する実験的研究の結果、アンカーベースの検出器の複雑さによって生じる追加の遅延と比較して、アンカーフリー検出器では速度が 51% 向上していることがわかりました。 SimOTA ラベル割り当て戦略 より高品質の陽性サンプルを取得するために、YOLOv6 は SimOTA 近年、動的ラベル割り当てに基づいた手法が多数登場しており、このような手法では、トレーニング プロセス中にネットワーク出力に基づいて陽性サンプルが割り当てられ、より高品質な陽性サンプルが生成されます。 、ひいてはネットワークの前向き最適化を促進します。たとえば、OTA[7] [4] アルゴリズムは Top-K 近似戦略を使用してサンプルの最適一致を取得するため、トレーニングが大幅に高速化されます。したがって、YOLOv6 は SimOTA 動的割り当て戦略を採用し、それをアンカーフリー パラダイムと組み合わせて、ナノサイズ モデルで平均検出精度を 1.3% AP 向上させます。 SIoU バウンディング ボックス回帰損失 回帰精度をさらに向上させるために、YOLOv6 は SIoU を採用しています。 [9 ] 近年、一般的に使用されるバウンディングボックス回帰損失には、IoU、GIoU、CIoU、DIoU損失などが含まれます。これらの損失関数は、予測フレームとターゲットフレームの間の重なりの程度、中心点などの要素を考慮します。 2 つの間のギャップを測定し、それによってネットワークが損失を最小限に抑えて回帰精度を向上させるように誘導しますが、これらの方法では、予測ボックスとターゲット ボックスの間の方向の一致は考慮されていません。 SIoU 損失関数は、必要な回帰間にベクトル角を導入することで距離損失を再定義し、回帰の自由度を効果的に低減し、ネットワークの収束を加速し、回帰精度をさらに向上させます。 YOLOv6s での実験に SIoU 損失を使用すると、CIoU 損失と比較して、平均検出精度が 0.3% AP 向上しました。 上記の最適化戦略と改善により、YOLOv6 はさまざまなサイズの複数のモデルで優れたパフォーマンスを達成しました。以下の表 1 は、YOLOv6-nano のアブレーション実験結果を示しており、実験結果から、当社が独自に設計した検出ネットワークにより、精度と速度の両方で大きな向上がもたらされたことがわかります。 表 1 YOLOv6 ナノ アブレーション実験結果以下の表 2 は、現在主流の他の YOLO シリーズ アルゴリズムと比較した YOLOv6 の実験結果を示しています。表から次のことがわかります。 #表 2 さまざまなサイズの YOLOv6 モデルと他のモデルのパフォーマンスの比較 この記事では、ターゲット検出フレームワークにおける Meituan Visual Intelligence 部門の最適化と実践経験を紹介します。 , 私たちは、YOLO シリーズ フレームワークのトレーニング戦略、バックボーン ネットワーク、マルチスケール特徴融合、検出ヘッドなどを考えて最適化し、新しい検出フレームワーク YOLOv6 を設計しました。当初の目的は、実際に発生した問題を解決することにありました。産業用アプリケーションの実装に関する質問です。 YOLOv6 フレームワークを構築する際、ハードウェアを意識したニューラル ネットワーク設計アイデアに基づいて、自社開発の EfficientRep Backbone、Rep-Neck、Efficient Decoupled Head などのいくつかの新しい手法を検討し、最適化しました。また、アンカーフリー、SimOTA、SIoU 回帰損失など、学界や産業界での最先端の開発や成果も活用しています。 COCO データセットの実験結果は、YOLOv6 が検出精度と速度の点で最高であることを示しています。 # 今後も、YOLOv6 エコシステムの構築と改善を続けていきます。主な作業には次の側面が含まれます。 YOLOv6 モデルの全範囲に対応し、引き続き検出パフォーマンスを向上させます。
2.1 ハードウェアに優しいバックボーン ネットワーク設計
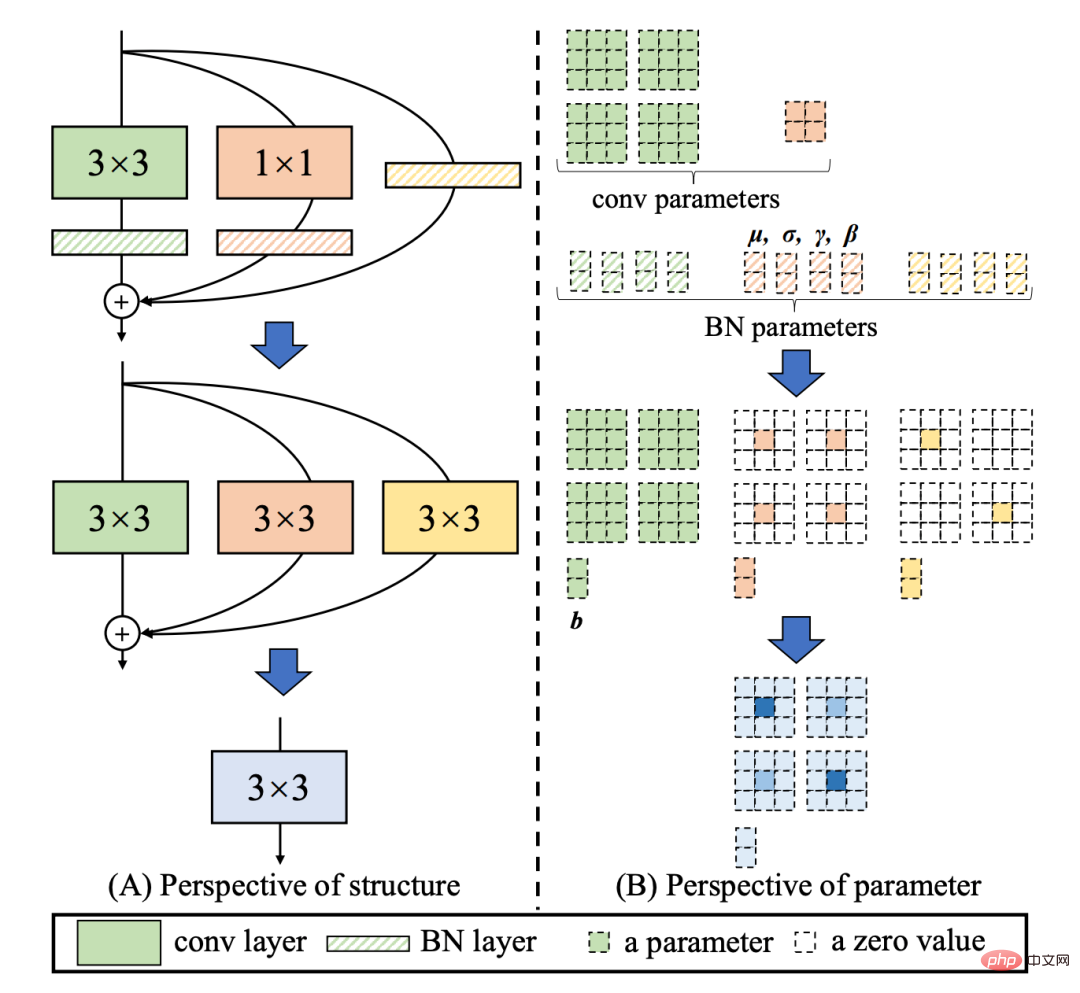
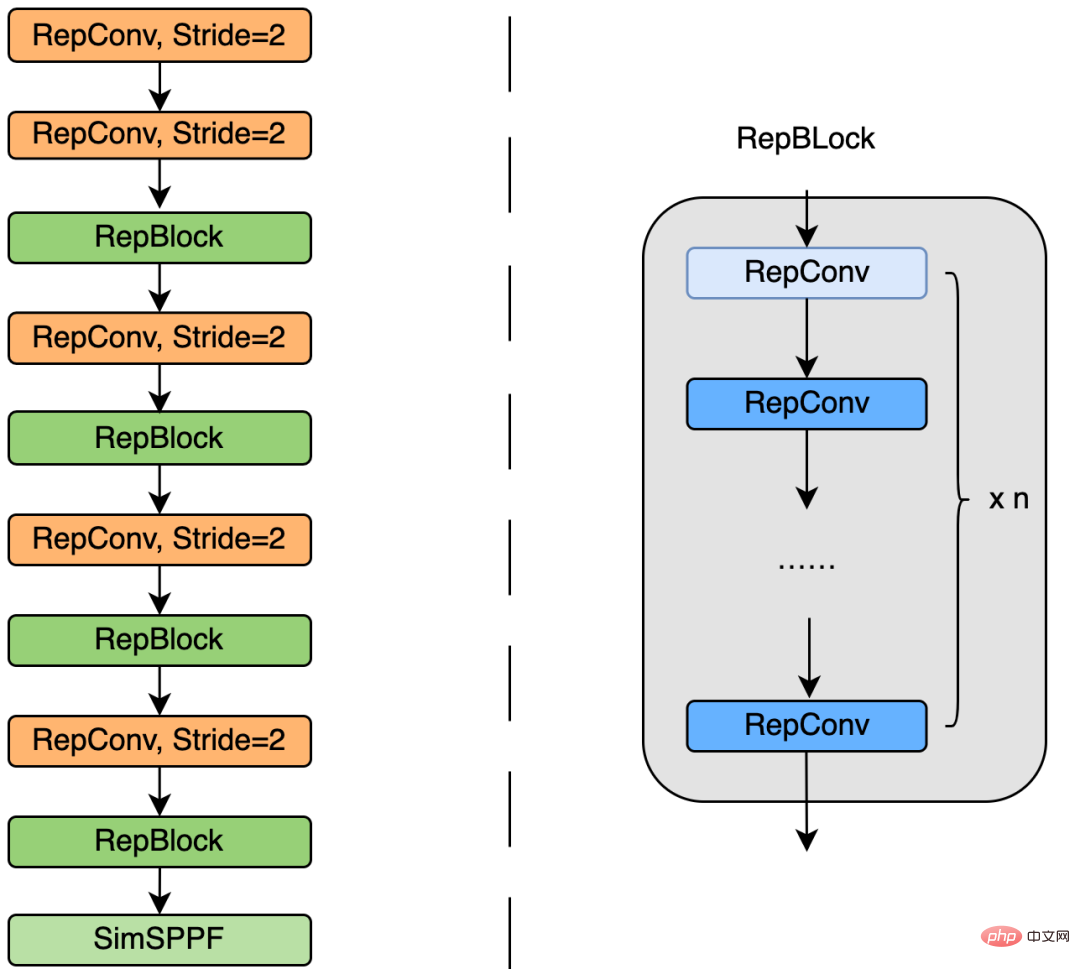
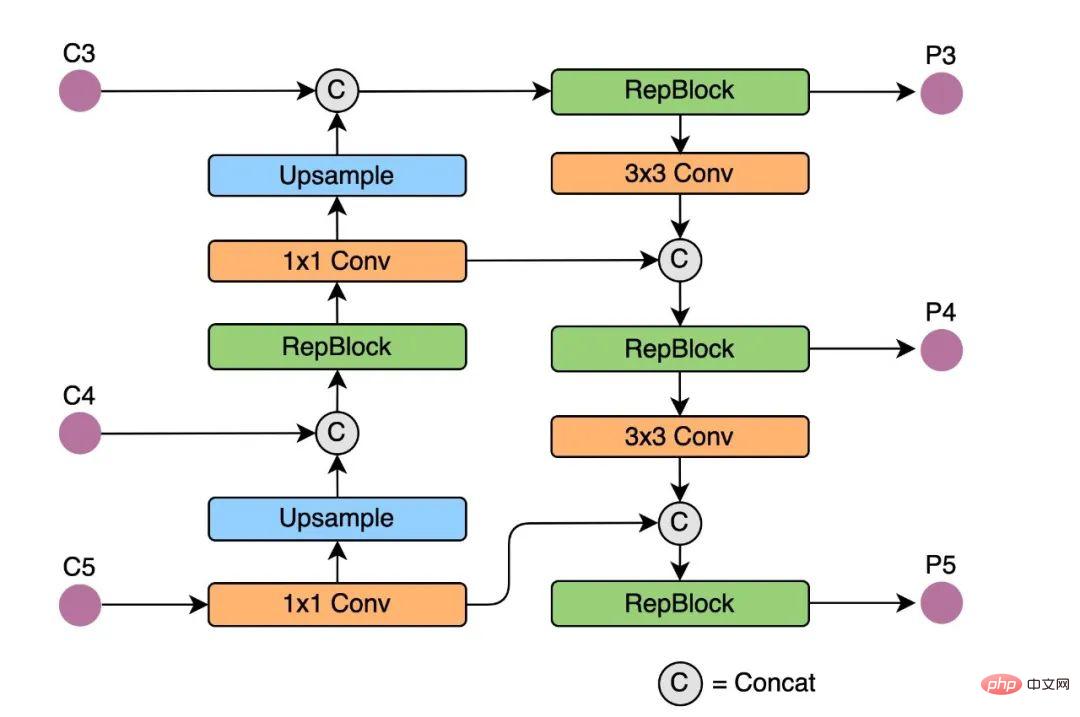
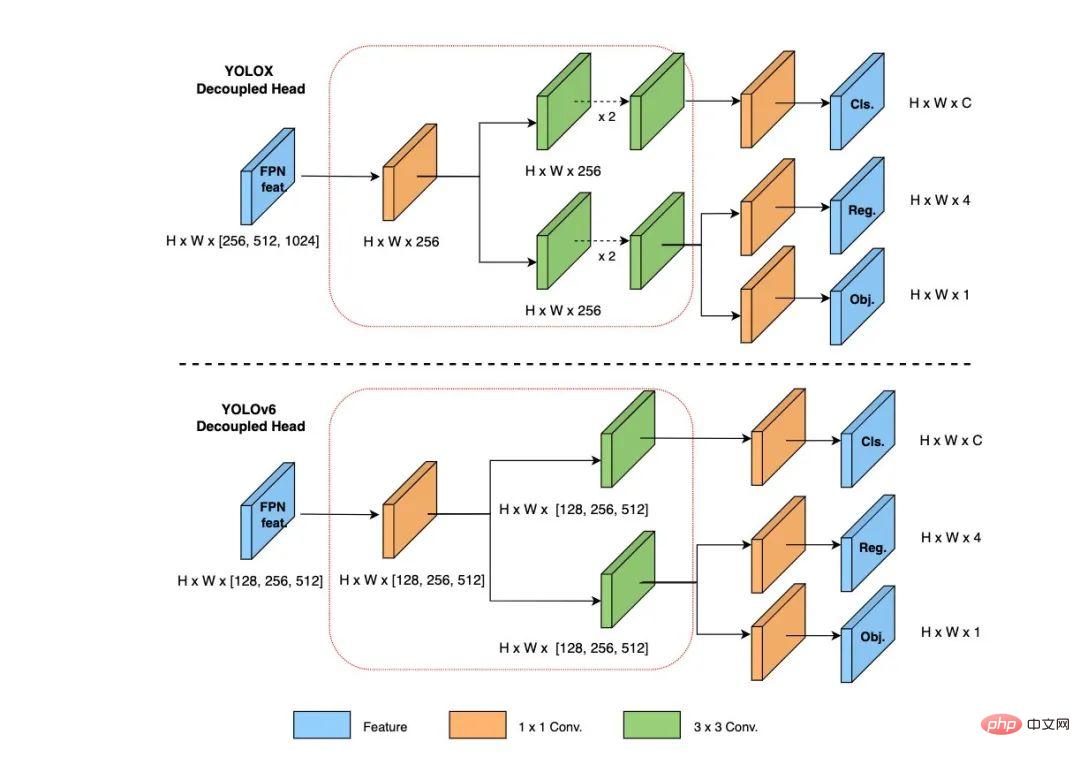
#検出精度をさらに向上させるために、私たちは学界や産業界の他の検出フレームワークからの高度な研究の進歩を活用しています:アンカーフリーアンカーフリーパラダイム、SimOTAラベル割り当て戦略、SIoUバウンディングボックス回帰損失。
3. 実験結果

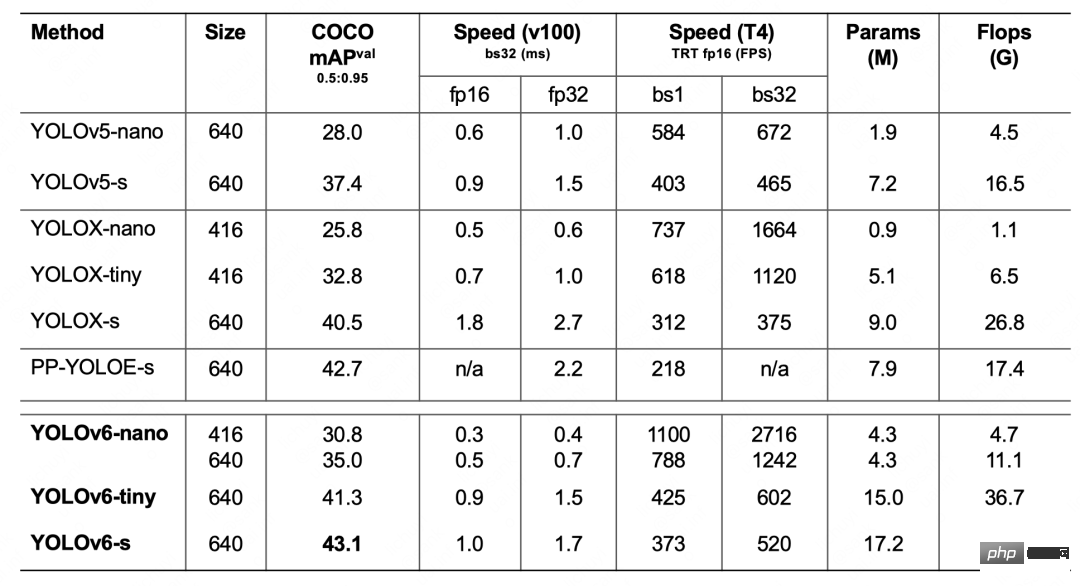
4. 概要と展望
さまざまなハードウェア プラットフォームでハードウェアに適したモデルを設計します。
以上がYOLOv6 の高速かつ正確なターゲット検出フレームワークがオープンソース化されましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7467
7467
 15
1376
52
77
11
18
19
15
1376
52
77
11
18
19

 オープンソースのフリーテキスト注釈ツールのおすすめ 10 選
Mar 26, 2024 pm 08:20 PM
オープンソースのフリーテキスト注釈ツールのおすすめ 10 選
Mar 26, 2024 pm 08:20 PM
テキスト注釈は、テキスト内の特定のコンテンツにラベルまたはタグを対応させる作業です。その主な目的は、特に人工知能の分野で、より深い分析と処理のためにテキストに追加情報を提供することです。テキスト注釈は、人工知能アプリケーションの教師あり機械学習タスクにとって非常に重要です。これは、自然言語テキスト情報をより正確に理解し、テキスト分類、感情分析、言語翻訳などのタスクのパフォーマンスを向上させるために AI モデルをトレーニングするために使用されます。テキスト アノテーションを通じて、AI モデルにテキスト内のエンティティを認識し、コンテキストを理解し、新しい同様のデータが出現したときに正確な予測を行うように教えることができます。この記事では主に、より優れたオープンソースのテキスト注釈ツールをいくつか推奨します。 1.LabelStudiohttps://github.com/Hu
 オープンソースの無料画像注釈ツールおすすめ 15 選
Mar 28, 2024 pm 01:21 PM
オープンソースの無料画像注釈ツールおすすめ 15 選
Mar 28, 2024 pm 01:21 PM
画像の注釈は、ラベルまたは説明情報を画像に関連付けて、画像の内容に深い意味と説明を与えるプロセスです。このプロセスは機械学習にとって重要であり、画像内の個々の要素をより正確に識別するために視覚モデルをトレーニングするのに役立ちます。画像に注釈を追加することで、コンピュータは画像の背後にあるセマンティクスとコンテキストを理解できるため、画像の内容を理解して分析する能力が向上します。画像アノテーションは、コンピュータ ビジョン、自然言語処理、グラフ ビジョン モデルなどの多くの分野をカバーする幅広い用途があり、車両が道路上の障害物を識別するのを支援したり、障害物の検出を支援したりするなど、幅広い用途があります。医用画像認識による病気の診断。この記事では主に、より優れたオープンソースおよび無料の画像注釈ツールをいくつか推奨します。 1.マケセンス
 Meituanの持ち帰りカウンターの入手方法
Apr 08, 2024 pm 03:41 PM
Meituanの持ち帰りカウンターの入手方法
Apr 08, 2024 pm 03:41 PM
1. 配達員が食事をキャビネットに入れると、テキスト メッセージ、電話、または Meituan メッセージを通じて、顧客に食事を受け取るように通知します。 2. 顧客は WeChat または Meituan APP を通じて食品キャビネットの QR コードをスキャンして、スマート食品キャビネット アプレットに入ることができます。 3. ピックアップコードを入力するか、「ワンクリックキャビネットオープン」機能を使用して、簡単にキャビネットのドアを開けてテイクアウトを取り出すことができます。
 美団の支払いパスワードを忘れた場合の回復方法_美団の支払いパスワードを忘れた場合の回復方法
Mar 28, 2024 pm 03:29 PM
美団の支払いパスワードを忘れた場合の回復方法_美団の支払いパスワードを忘れた場合の回復方法
Mar 28, 2024 pm 03:29 PM
1. まず、Meituan ソフトウェアに入り、[マイ メニュー] ページで [設定] を見つけ、クリックして [設定] に入ります。 2. 次に、設定ページで支払い設定を見つけ、クリックして支払い設定を入力します。 3. 支払いセンターに入り、支払いパスワード設定を見つけて、クリックして支払いパスワード設定を入力します。 4. 支払いパスワード設定ページで、支払いパスワードの取得を見つけ、クリックしてページ オプションを入力します。 5. 取得したい支払いパスワード情報を入力し、「確認」をクリックすると、パスワードを通過すると支払いパスワードを取得できます。
 推奨: 優れた JS オープンソースの顔検出および認識プロジェクト
Apr 03, 2024 am 11:55 AM
推奨: 優れた JS オープンソースの顔検出および認識プロジェクト
Apr 03, 2024 am 11:55 AM
顔の検出および認識テクノロジーは、すでに比較的成熟しており、広く使用されているテクノロジーです。現在、最も広く使用されているインターネット アプリケーション言語は JS ですが、Web フロントエンドでの顔検出と認識の実装には、バックエンドの顔認識と比較して利点と欠点があります。利点としては、ネットワーク インタラクションの削減とリアルタイム認識により、ユーザーの待ち時間が大幅に短縮され、ユーザー エクスペリエンスが向上することが挙げられます。欠点としては、モデル サイズによって制限されるため、精度も制限されることが挙げられます。 js を使用して Web 上に顔検出を実装するにはどうすればよいですか? Web 上で顔認識を実装するには、JavaScript、HTML、CSS、WebRTC など、関連するプログラミング言語とテクノロジに精通している必要があります。同時に、関連するコンピューター ビジョンと人工知能テクノロジーを習得する必要もあります。 Web 側の設計により、次の点に注意してください。
 Meituan の住所はどこで変更できますか? Meituanのアドレス変更チュートリアル!
Mar 15, 2024 pm 04:07 PM
Meituan の住所はどこで変更できますか? Meituanのアドレス変更チュートリアル!
Mar 15, 2024 pm 04:07 PM
1. Meituan の住所はどこで変更できますか? Meituanのアドレス変更チュートリアル!方法(1) 1. Meituan My Pageに入り、「設定」をクリックします。 2. 個人情報を選択します。 3. 配送先住所を再度クリックします。 4. 最後に、変更したいアドレスを選択し、アドレスの右側にあるペンアイコンをクリックして変更します。方法 (2) 1. Meituan アプリのホームページで [テイクアウト] をクリックし、入力後 [その他の機能] をクリックします。 2. [その他] インターフェイスで、[アドレスの管理] をクリックします。 3. [配送先住所] インターフェイスで、[編集] を選択します。 4. 必要に応じて 1 つずつ変更し、最後にクリックしてアドレスを保存します。
 Meituanのレビューを削除する方法 レビューを削除する方法
Mar 12, 2024 pm 07:31 PM
Meituanのレビューを削除する方法 レビューを削除する方法
Mar 12, 2024 pm 07:31 PM
このプラットフォームを利用すると、食や消費に関するさまざまな側面のレビューも表示されます。操作方法も非常に簡単なものもあります。消費するときに、そのレビューを見ることができるはずです。いくつかの機能オプションは評価できます。ただし、ストアによっては間違った評価を自分で削除しなければならない場合もありますが、ユーザーはその評価の仕方がわからないので、今日は編集者が上記の機能のいくつかを詳しく説明しましょう。何かアイデアがありましたら、今日編集者が削除方法を詳しく説明しますので、興味のある方は今すぐ編集者と一緒に見てください。皆さんもきっと何かを知っているはずです、お見逃しなくそれ。消去
 Alibaba 7B マルチモーダル文書理解の大規模モデルが新しい SOTA を獲得
Apr 02, 2024 am 11:31 AM
Alibaba 7B マルチモーダル文書理解の大規模モデルが新しい SOTA を獲得
Apr 02, 2024 am 11:31 AM
マルチモーダル文書理解機能のための新しい SOTA!アリババの mPLUG チームは、最新のオープンソース作品 mPLUG-DocOwl1.5 をリリースしました。これは、高解像度の画像テキスト認識、一般的な文書構造の理解、指示の遵守、外部知識の導入という 4 つの主要な課題に対処するための一連のソリューションを提案しています。さっそく、その効果を見てみましょう。複雑な構造のグラフをワンクリックで認識しMarkdown形式に変換:さまざまなスタイルのグラフが利用可能:より詳細な文字認識や位置決めも簡単に対応:文書理解の詳しい説明も可能:ご存知「文書理解」 「」は現在、大規模な言語モデルの実装にとって重要なシナリオです。市場には文書の読み取りを支援する多くの製品が存在します。その中には、主にテキスト認識に OCR システムを使用し、テキスト処理に LLM と連携する製品もあります。
