

Javaで1億の乱数をソートするにはどうすればよいですか?

1. 直接挿入ソート
1. 図解による挿入ソート
アイデア: 文字通り、挿入とは要素をセット内の特定の要素に入れることです。シーケンスを 2 つの部分に分割する必要があります。1 つの部分は順序付きセットで、もう 1 つの部分は並べ替えられるセットです。
図:
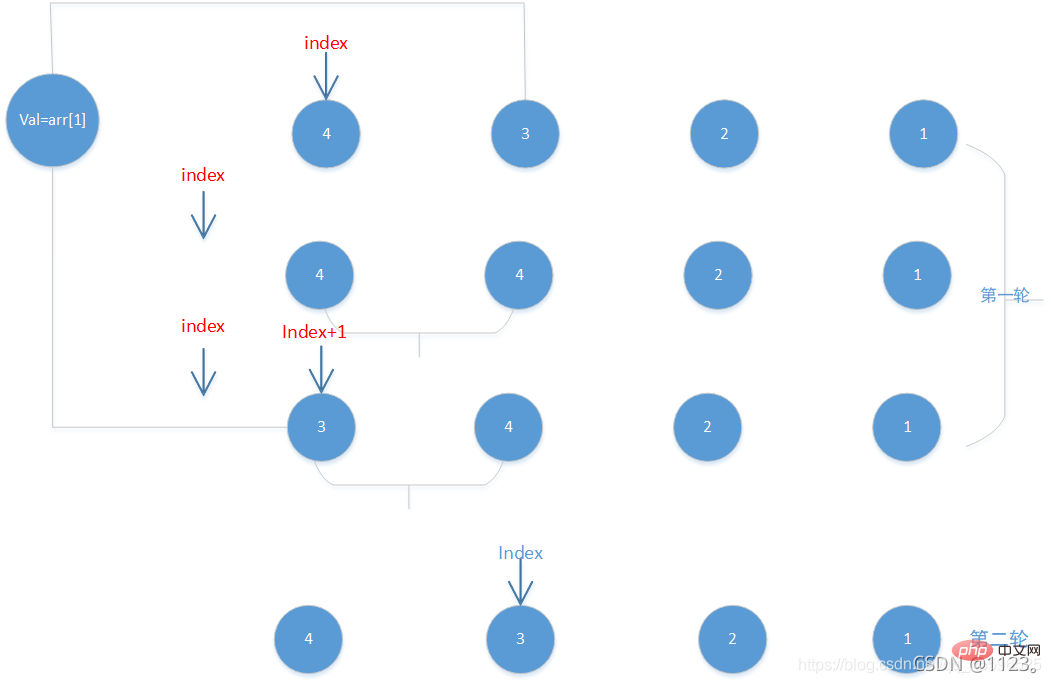
は 2 番目の要素 (3) から開始する必要があります。後続の操作で 3 を上書きしないようにするには、保存する一時変数 3。つまり、上記の
val=arr[1]、配列を操作しているため、注文された
カーソル
が境界を越えず、挿入される値がカーソルで示された位置より小さい場合(上図の #4) 、要素 4 を後方に移動し、カーソルを前方に移動し、カーソルが交差するまでセット内の他の要素が挿入される要素より小さいかどうかを確認し続けます。境界。ループが終了します。次の比較ラウンドが始まります。2. コードの実装
public static void insertSort(int[]arr){
for(int i = 1 ; i < arr.length; i++){
int val = arr[i];
int valIndex = i - 1; //游标
while(valIndex >= 0 && val < arr[valIndex]){ //插入的值比游标指示的值小
arr[valIndex + 1] = arr[valIndex];
valIndex--; //游标前移
}
arr[valIndex+1] = val;
}
}
12345678910113. パフォーマンス テストと時間と空間の複雑さ
実際の実行800,000 件のデータには 1 分 4 秒かかります (正確な値ではなく、各マシンが異なる可能性があります)
ソート レコードとキーワードが少ない場合は、直接挿入の方が効率的です。高い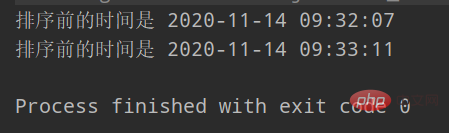
キーワード比較の数: KCN=(n^2)/2 キーワードの総数移動数:
RMN= (n^2)/2したがって、時間計算量は約 O(N^2)
2. ヒルソート (交換方法)1. アイデアの図解
public static void shellSort(int[] arr){ //交换法
int tmp = 0;
for(int gap = arr.length / 2 ; gap > 0 ; gap /= 2){
for(int i = gap ; i < arr.length ; i++){ //先遍历所有数组
for(int j = i - gap ; j >= 0 ; j -= gap){//开启插入排序
if(arr[ j ] > arr[ gap + j ]){ //可以根据升降序修改大于或小于
tmp = arr[gap + j];
arr[j+gap] = arr[j];
arr[j] = tmp;
}
}
}
System.out.println(gap);
System.out.println(Arrays.toString(arr));
}
}
12345678910111213141516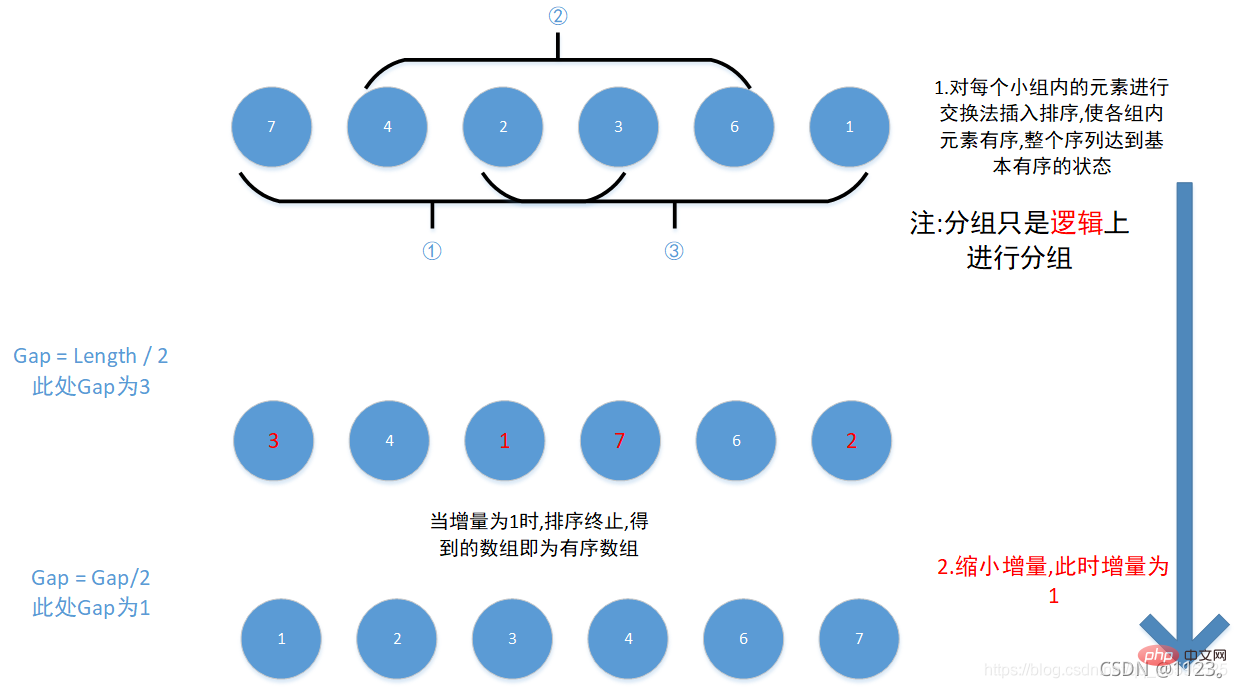 ここが最も理解しにくいことですj = i - gap
ここが最も理解しにくいことですj = i - gap、グループ内の最初の要素を表します。つまり、
j=0,最初の要素がグループ内の値が 2 番目の要素より大きい場合 (論理分類により、2 番目の要素のインデックスは最初の要素のすべての値の増分ギャップ である必要があります)、2 つを交換します。それ以外の場合は
、比較を続けるか、ループから抜け出します。 この方法ですべてのグループを走査した後、増分を減らします (つまり、gap/=2) )、増分ギャップが 1 になるまで上記の手順を続行します。値が 1 になると、シーケンスのソートは終了します。
3. 時間計算量ヒル ソートの時間計算量は、
の値は明確な値ではなく、これは議論する必要がある4番目の点でもあります
4。増分シーケンスの選択について上記の並べ替えを行う場合
増分リダクション選択されたモデルは
gap/=2 です。これは最適な選択ではありません。増分の選択は数学界の未解決の問題です。 しかし、それは決定することができます。はい、n->無限大の場合、時間計算量は次のように削減できることが多数の実験によって証明されています:
##次のポイント
では、いくつかの実験も行っていますが、一定の規模 (800w ~ 100w など) 内の計算では確実に効果が得られます。 100 万)、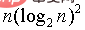 ヒル ソートの速度はヒープ ソートの速度をはるかに上回ります
ヒル ソートの速度はヒープ ソートの速度をはるかに上回ります
3. ヒル ソート (シフト法) Exchange メソッドは、shift メソッドよりもはるかに遅いため、shift メソッド
を使用し、shift メソッドは、exchange メソッド1 よりも挿入ソートに「似ています」。アイデアは、実際には上記の 2 つの並べ替え方法です。grouping
とinsertion
の利点を組み合わせると、非常に効率的です。のアイデアを具体化しています。 分割統治、比較的大きなシーケンスをいくつかの小さなシーケンスに分割する
2. コードの実装
public static void shellSort02(int[] arr){ //移位法
for(int gap = arr.length/2 ; gap > 0 ; gap /= 2){ //分组
for(int i = gap ; i < arr.length ; i++){ //遍历
int valIndex = i;
int val = arr[valIndex];
if(val < arr[valIndex-gap]){ //插入的值小于组内另一个值
while(valIndex - gap >=0 && val < arr[valIndex-gap]){ //开始插排
// 插入
arr[valIndex] = arr[valIndex-gap];
valIndex -= gap; //让valIndex = valIndex-gap (游标前移)
}
}
arr[valIndex] = val;
}
}
}
12345678910111213141516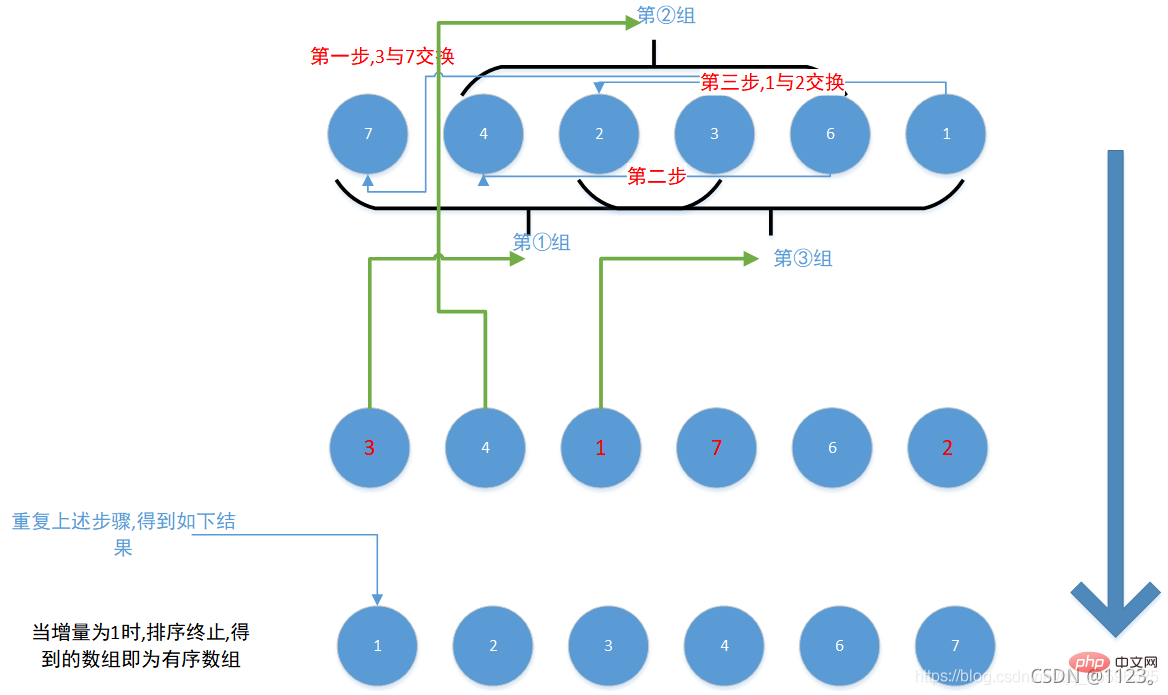 3. 実験的結果############ ############
3. 実験的結果############ ############以上がJavaで1億の乱数をソートするにはどうすればよいですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7640
7640
 15
1391
52
90
11
32
150
15
1391
52
90
11
32
150


 ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
Java の Weka へのガイド。ここでは、weka java の概要、使い方、プラットフォームの種類、利点について例を交えて説明します。

 Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
この記事では、Java Spring の面接で最もよく聞かれる質問とその詳細な回答をまとめました。面接を突破できるように。
 Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8は、Stream APIを導入し、データ収集を処理する強力で表現力のある方法を提供します。ただし、ストリームを使用する際の一般的な質問は次のとおりです。 従来のループにより、早期の中断やリターンが可能になりますが、StreamのForeachメソッドはこの方法を直接サポートしていません。この記事では、理由を説明し、ストリーム処理システムに早期終了を実装するための代替方法を調査します。 さらに読み取り:JavaストリームAPIの改善 ストリームを理解してください Foreachメソッドは、ストリーム内の各要素で1つの操作を実行する端末操作です。その設計意図はです
 Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプに関するガイド。ここでは、Java でタイムスタンプを日付に変換する方法とその概要について、例とともに説明します。
 カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルは3次元の幾何学的図形で、両端にシリンダーと半球で構成されています。カプセルの体積は、シリンダーの体積と両端に半球の体積を追加することで計算できます。このチュートリアルでは、さまざまな方法を使用して、Javaの特定のカプセルの体積を計算する方法について説明します。 カプセルボリュームフォーミュラ カプセルボリュームの式は次のとおりです。 カプセル体積=円筒形の体積2つの半球体積 で、 R:半球の半径。 H:シリンダーの高さ(半球を除く)。 例1 入力 RADIUS = 5ユニット 高さ= 10単位 出力 ボリューム= 1570.8立方ユニット 説明する 式を使用してボリュームを計算します。 ボリューム=π×R2×H(4
 未来を創る: まったくの初心者のための Java プログラミング
Oct 13, 2024 pm 01:32 PM
未来を創る: まったくの初心者のための Java プログラミング
Oct 13, 2024 pm 01:32 PM
Java は、初心者と経験豊富な開発者の両方が学習できる人気のあるプログラミング言語です。このチュートリアルは基本的な概念から始まり、高度なトピックに進みます。 Java Development Kit をインストールしたら、簡単な「Hello, World!」プログラムを作成してプログラミングを練習できます。コードを理解したら、コマンド プロンプトを使用してプログラムをコンパイルして実行すると、コンソールに「Hello, World!」と出力されます。 Java の学習はプログラミングの旅の始まりであり、習熟が深まるにつれて、より複雑なアプリケーションを作成できるようになります。
