

ChatGPT トピック 1 つの GPT ファミリーの進化の歴史

タイムライン
2018年6月
OpenAIは、1億1,000万のパラメーターを備えたGPT-1モデルをリリースしました。
2018年11月
OpenAIは15億個のパラメーターを備えたGPT-2モデルをリリースしましたが、悪用の懸念から、モデルのすべてのコードとデータは公開されていません。
2019年2月
OpenAIはGPT-2モデルの一部のコードとデータを公開しましたが、アクセスは依然として制限されています。
2019 年 6 月 10 日
OpenAI は、1,750 億のパラメーターを備えた GPT-3 モデルをリリースし、一部のパートナーにアクセスを提供しました。
2019年9月
OpenAIはGPT-2のすべてのコードとデータを公開し、より大きなバージョンをリリースしました。
2020 年 5 月に
#OpenAI は、1,750 億のパラメーターを持ち、これまでで最大の自然言語処理モデルである GPT-3 モデルのベータ版のリリースを発表しました。 2022 年 3 月OpenAI は、命令チューニングを使用して InstructGPT をリリースしました2022 年 11 月 30 日OpenAI は、大規模言語の GPT-3.5 シリーズに合格しました。新しい会話型 AI モデル ChatGPT がモデルの微調整を経て正式リリースされました。 2022 年 12 月 15 日ChatGPT の最初のアップデート。全体的なパフォーマンスが向上し、履歴の会話記録を保存および表示する新機能が追加されます。 2023年1月9日ChatGPTが2回目のアップデートを行い、回答の信頼性が向上し、新たに「生成停止」機能が追加されました。 2023年1月21日OpenAIは、一部のユーザーに限定されたChatGPT Professionalの有料版をリリースしました。 2023 年 1 月 30 日ChatGPT の 3 回目のアップデートでは、回答の信頼性が向上するだけでなく、数学的スキルも向上します。 2023年2月2日OpenAIはChatGPT有料版のサブスクリプションサービスを正式に開始し、新バージョンは無料版よりも応答が速く、動作が安定しています。 2023 年 3 月 15 日OpenAI は、テキストを読み取るだけでなく、画像を認識してテキスト結果を生成できる大規模マルチモーダル モデル GPT-4 を衝撃的に発表しました。接続された ChatGPT は Plus ユーザーに公開されています。 GPT-1: 一方向 Transformer に基づく事前トレーニング済みモデル GPT が登場する前は、NLP モデルは主に大量の注釈付きデータに基づいてトレーニングされていました。特定のタスク用。これにより、いくつかの制限が発生します: 大規模で高品質のアノテーション データを取得するのは容易ではありません; モデルは受けたトレーニングに限定されており、一般化能力が不十分です; 実行できません すぐに使用できるタスクは、モデルの実際の適用を制限します。 これらの問題を克服するために、OpenAI は大規模モデルを事前トレーニングする道を歩み始めました。 GPT-1 は、2018 年に OpenAI によってリリースされた最初の事前トレーニング済みモデルです。一方向の Transformer モデルを採用し、トレーニングに 40 GB 以上のテキスト データを使用します。 GPT-1 の主な機能は、生成的な事前トレーニング (教師なし) と識別タスクの微調整 (教師あり) です。まず、教師なし学習の事前トレーニングを使用し、8 つの GPU で 1 か月間かけて大量のラベルなしデータから AI システムの言語機能を強化し、大量の知識を取得しました。 NLP タスクのシステム パフォーマンスを向上させるために統合されました。 GPT-1 はテキストの生成とタスクの理解において優れたパフォーマンスを示し、当時最も先進的な自然言語処理モデルの 1 つとなりました。 GPT-2: マルチタスク事前トレーニング モデル シングルタスク モデルには一般化が欠けており、マルチタスクの学習には多数の効果的なトレーニング ペアが必要であるため、 , GPT-2はGPT-1をベースに拡張・最適化されており、教師あり学習が削除され教師なし学習のみが残されています。 GPT-2 は、より大きなテキスト データとより強力なコンピューティング リソースをトレーニングに使用し、パラメータ サイズは 1 億 5,000 万に達し、GPT-1 の 1 億 1,000 万のパラメータをはるかに上回ります。 GPT-2 では、学習に大規模なデータ セットと大規模なモデルを使用することに加えて、新しくてより困難なタスクであるゼロショット学習 (ゼロショット) も提案しています。これは、事前トレーニングされたモデルを多くの下流タスクに直接適用することです。 GPT-2 は、テキスト生成、テキスト分類、言語理解などを含む複数の自然言語処理タスクで優れたパフォーマンスを実証しています。
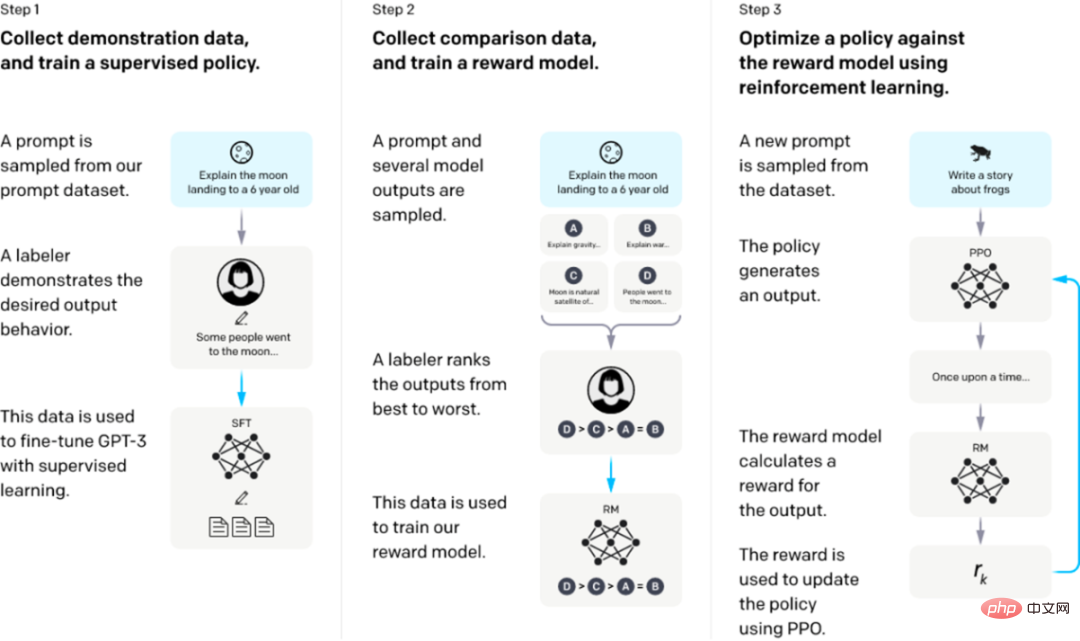
ステップ 1: 教師あり SFT の微調整: デモ データを収集し、教師ありポリシーをトレーニングします。私たちのタガーは、入力プロンプト配布での望ましい動作のデモンストレーションを提供します。次に、教師あり学習を使用して、これらのデータに基づいて事前トレーニングされた GPT-3 モデルを微調整します。
ステップ 2: 報酬モデルのトレーニング。比較データを収集し、報酬モデルをトレーニングします。私たちは、ラベラーが特定の入力に対してどの出力を好むかを示す、モデル出力間の比較のデータセットを収集しました。次に、人間が好む出力を予測するために報酬モデルをトレーニングします。
ステップ 3: 報酬モデルでの近接ポリシー最適化 (PPO) による強化学習: RM の出力をスカラー報酬として使用します。 PPO アルゴリズムを使用して監視戦略を微調整し、この報酬を最適化します。
ステップ 2 と 3 は継続的に繰り返すことができ、現在の最適な戦略に関してさらに多くの比較データが収集され、それを使用して新しい RM をトレーニングし、次に新しい戦略をトレーニングします。
最初の 2 つのステップのプロンプトは、OpenAI のオンライン API 上のユーザー使用状況データから取得され、雇用されたアノテーターによって手書きされます。最後のステップはすべて API データからサンプリングされます。InstructGPT の特定のデータ:
1. SFT データ セット
SFT データ セットは、最初のトレーニングに使用されます。ステップ 教師ありモデルは、収集された新しいデータを使用して、GPT-3 のトレーニング方法に従って GPT-3 を微調整します。 GPT-3 はプロンプト学習に基づく生成モデルであるため、SFT データセットもプロンプトと応答のペアで構成されるサンプルです。 SFT データの一部は OpenAI の PlayGround ユーザーから提供され、もう 1 つの部分は OpenAI が雇用する 40 人のラベラーから提供されます。そして彼らはラベラーを訓練しました。このデータセットでは、アノテーターの仕事は、内容に基づいて指示自体を記述することです。
2. RM データ セット
RM データ セットは、ステップ 2 で報酬モデルをトレーニングするために使用されます。 GPT/ChatGPTを指導します。この報酬目標は微分可能である必要はありませんが、モデルが生成する必要があるものとできるだけ包括的かつ現実的に一致している必要があります。もちろん、この報酬は手動のアノテーションによって提供することもできますし、人為的なペアリングを通じて、バイアスを含む生成されたコンテンツに低いスコアを与え、人間が好まないコンテンツを生成しないようにモデルを促すことができます。 InstructGPT/ChatGPT のアプローチは、最初にモデルに候補テキストのバッチを生成させ、次にラベラーを使用して、生成されたデータの品質に従って生成されたコンテンツを並べ替えることです。
3. PPO データ セット
InstructGPT の PPO データには注釈が付けられておらず、GPT-3 API ユーザーから取得されます。さまざまなユーザーによって提供される生成タスクにはさまざまな種類があり、その割合が最も高いのは生成タスク (45.6%)、QA (12.4%)、ブレインストーミング (11.2%)、対話 (8.4%) などです。
#付録:
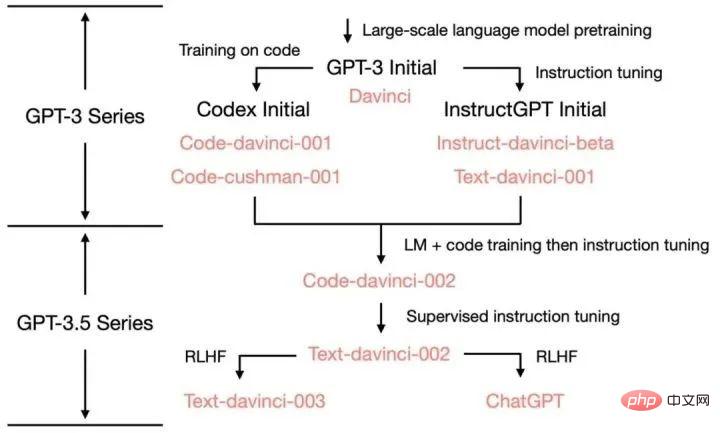
ChatGPT のさまざまな機能のソース:

以上がChatGPT トピック 1 つの GPT ファミリーの進化の歴史の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7456
7456
 15
1375
52
77
11
14
9
15
1375
52
77
11
14
9

 ChatGPT では、無料ユーザーが 1 日あたりの制限付きで DALL-E 3 を使用して画像を生成できるようになりました
Aug 09, 2024 pm 09:37 PM
ChatGPT では、無料ユーザーが 1 日あたりの制限付きで DALL-E 3 を使用して画像を生成できるようになりました
Aug 09, 2024 pm 09:37 PM
DALL-E 3は、前モデルより大幅に改良されたモデルとして2023年9月に正式導入されました。これは、複雑な詳細を含む画像を作成できる、これまでで最高の AI 画像ジェネレーターの 1 つと考えられています。ただし、発売当初は対象外でした
 YOLOは不滅です! YOLOv9 がリリースされました: パフォーマンスとスピード SOTA~
Feb 26, 2024 am 11:31 AM
YOLOは不滅です! YOLOv9 がリリースされました: パフォーマンスとスピード SOTA~
Feb 26, 2024 am 11:31 AM
現在の深層学習手法は、モデルの予測結果が実際の状況に最も近くなるように、最適な目的関数を設計することに重点を置いています。同時に、予測に十分な情報を取得するには、適切なアーキテクチャを設計する必要があります。既存の方法は、入力データがレイヤーごとの特徴抽出と空間変換を受けると、大量の情報が失われるという事実を無視しています。この記事では、ディープネットワークを介してデータを送信する際の重要な問題、つまり情報のボトルネックと可逆機能について詳しく説明します。これに基づいて、深層ネットワークが複数の目的を達成するために必要なさまざまな変化に対処するために、プログラマブル勾配情報 (PGI) の概念が提案されています。 PGI は、目的関数を計算するためのターゲット タスクに完全な入力情報を提供することで、ネットワークの重みを更新するための信頼できる勾配情報を取得できます。さらに、新しい軽量ネットワーク フレームワークが設計されています。
 ChatGPT と Python の完璧な組み合わせ: インテリジェントな顧客サービス チャットボットの作成
Oct 27, 2023 pm 06:00 PM
ChatGPT と Python の完璧な組み合わせ: インテリジェントな顧客サービス チャットボットの作成
Oct 27, 2023 pm 06:00 PM
ChatGPT と Python の完璧な組み合わせ: インテリジェント カスタマー サービス チャットボットの作成 はじめに: 今日の情報化時代において、インテリジェント カスタマー サービス システムは企業と顧客の間の重要なコミュニケーション ツールとなっています。より良い顧客サービス体験を提供するために、多くの企業が顧客相談や質問応答などのタスクを完了するためにチャットボットに注目し始めています。この記事では、OpenAI の強力なモデル ChatGPT と Python 言語を使用して、インテリジェントな顧客サービス チャットボットを作成し、顧客サービスを向上させる方法を紹介します。
 携帯電話にchatgptをインストールする方法
Mar 05, 2024 pm 02:31 PM
携帯電話にchatgptをインストールする方法
Mar 05, 2024 pm 02:31 PM
インストール手順: 1. ChatGTP ソフトウェアを ChatGTP 公式 Web サイトまたはモバイル ストアからダウンロードします; 2. それを開いた後、設定インターフェイスで言語を中国語を選択します; 3. ゲーム インターフェイスでヒューマン マシン ゲームを選択し、中国スペクトル; 4 . 起動後、チャット ウィンドウにコマンドを入力してソフトウェアを操作します。
 Win10 パーティション形式の深い理解: GPT と MBR の比較
Dec 22, 2023 am 11:58 AM
Win10 パーティション形式の深い理解: GPT と MBR の比較
Dec 22, 2023 am 11:58 AM
独自のシステムをパーティション分割する場合、ユーザーが使用するハードドライブが異なるため、多くのユーザーは win10 パーティション形式が gpt か mbr のどちらであるかを知りません。このため、これらの違いを理解するのに役立つ詳細な紹介を提供しました。二。 Win10 パーティション形式 gpt または mbr: 回答: 3 TB を超えるハード ドライブを使用している場合は、gpt を使用できます。 gpt は mbr よりも高度ですが、互換性の点では mbr の方がまだ優れています。もちろん、ユーザーの好みに応じて選択することもできます。 gpt と mbr の違い: 1. サポートされるパーティションの数: 1. MBR は最大 4 つのプライマリ パーティションをサポートします。 2. GPT はパーティションの数によって制限されません。 2. サポートされるハードドライブのサイズ: 1. MBR は最大 2TB までのみサポートします
 win7 のハードディスク形式として MBR または GPT を選択する必要がありますか?
Jan 03, 2024 pm 08:09 PM
win7 のハードディスク形式として MBR または GPT を選択する必要がありますか?
Jan 03, 2024 pm 08:09 PM
win7 オペレーティング システムを使用している場合、システムを再インストールしてハードディスクをパーティション分割する必要がある状況に遭遇することがあります。 win7 のハードディスク フォーマットに mbr と gpt のどちらが必要かという問題については、編集者は依然として独自のシステムとハードウェア構成の詳細に基づいて選択する必要があると考えています。互換性の観点から、mbr 形式を選択するのが最善です。詳細については、エディターがどのように実行したかを見てみましょう~ Win7 ハードディスク フォーマットには mbr または gpt1 が必要です。システムが Win7 でインストールされている場合は、互換性の良い MBR を使用することをお勧めします。 2. 3T を超える場合、または win8 をインストールする場合は、GPT を使用できます。 3. 確かに GPT は MBR よりも高度ですが、互換性の点では MBR は間違いなく無敵です。 GPT および MBR 領域
 1.3ミリ秒には1.3ミリ秒かかります。清華社の最新オープンソース モバイル ニューラル ネットワーク アーキテクチャ RepViT
Mar 11, 2024 pm 12:07 PM
1.3ミリ秒には1.3ミリ秒かかります。清華社の最新オープンソース モバイル ニューラル ネットワーク アーキテクチャ RepViT
Mar 11, 2024 pm 12:07 PM
論文のアドレス: https://arxiv.org/abs/2307.09283 コードのアドレス: https://github.com/THU-MIG/RepViTRepViT は、モバイル ViT アーキテクチャで優れたパフォーマンスを発揮し、大きな利点を示します。次に、この研究の貢献を検討します。記事では、主にモデルがグローバル表現を学習できるようにするマルチヘッド セルフ アテンション モジュール (MSHA) のおかげで、軽量 ViT は一般的に視覚タスクにおいて軽量 CNN よりも優れたパフォーマンスを発揮すると述べられています。ただし、軽量 ViT と軽量 CNN のアーキテクチャの違いは十分に研究されていません。この研究では、著者らは軽量の ViT を効果的なシステムに統合しました。
 Kubernetes デバッグ用の最終兵器: K8sGPT
Feb 26, 2024 am 11:40 AM
Kubernetes デバッグ用の最終兵器: K8sGPT
Feb 26, 2024 am 11:40 AM
人工知能と機械学習テクノロジーが発展し続ける中、企業や組織はこれらのテクノロジーを活用して競争力を強化するための革新的な戦略を積極的に模索し始めています。 K8sGPT[2] は、この分野で最も強力なツールの 1 つであり、k8s オーケストレーションの利点と GPT モデルの優れた自然言語処理機能を組み合わせた k8s ベースの GPT モデルです。 K8sGPT とは何ですか? まず例を見てみましょう: K8sGPT 公式 Web サイトによると: K8sgpt は、Kubernetes クラスターの問題をスキャン、診断、分類するために設計されたツールであり、SRE の経験を分析エンジンに統合して、最も関連性の高い情報を提供します。人工知能技術の応用を通じて、K8sgpt はコンテンツを充実させ続け、ユーザーがより迅速かつ正確に理解できるように支援します。
