

迷路を歩くネズミから人間を倒すAlphaGoまで、強化学習の発展

強化学習のことになると、多くの研究者のアドレナリンが制御不能に急増します。ゲーム AI システム、現代のロボット、チップ設計システム、その他のアプリケーションにおいて非常に重要な役割を果たします。
強化学習アルゴリズムにはさまざまな種類がありますが、主に「モデルベース」と「モデルフリー」の 2 つのカテゴリに分類されます。
TechTalks との対談の中で、神経科学者であり『知能の誕生』の著者である Daeyel Lee 氏が、人間と動物、人工知能と自然知能における強化学習のさまざまなモデル、および将来の研究の方向性について語ります。

モデルフリー強化学習
19世紀後半、心理学者エドワード・ソーンダイクによって提案された「効果の法則」がモデルの基礎となりました。無料の強化学習。ソーンダイク氏は、特定の状況でプラスの影響を与える行動は、その状況で再び起こる可能性が高く、マイナスの影響を与える行動は再び起こる可能性が低いと提案しました。
ソーンダイクは、実験でこの「効果の法則」を調査しました。彼は猫を迷路の箱に入れ、猫が箱から逃げるのにかかる時間を測定しました。逃げるために、猫はロープやレバーなどの一連の道具を操作しなければなりません。ソーンダイク氏は、猫がパズル箱と触れ合ううちに、脱出に役立つ行動を学習したことを観察した。時間が経つにつれて、猫はますます速く箱から逃げます。ソーンダイク氏は、猫は自分の行動が与える報酬と罰から学ぶことができると結論づけた。 「効果の法則」は後に行動主義への道を開きました。行動主義は、人間や動物の行動を刺激と反応の観点から説明しようとする心理学の分野です。 「効果の法則」は、モデルフリーの強化学習の基礎でもあります。モデルフリーの強化学習では、エージェントは世界を認識し、報酬を測定しながらアクションを実行します。
モデルフリーの強化学習では、直接的な知識や世界モデルは存在しません。 RL エージェントは、試行錯誤を通じて各アクションの結果を直接経験する必要があります。
モデルベースの強化学習
ソーンダイクの「効果の法則」は 1930 年代まで人気がありました。当時のもう一人の心理学者エドワード・トールマンは、ネズミがどのようにして迷路を素早く移動できるようになったのかを調査する中で、重要な洞察を発見した。トールマンは実験中に、動物は強化なしでも環境について学習できることに気づきました。
たとえば、迷路の中でマウスを放すと、マウスはトンネル内を自由に探索し、徐々に環境の構造を理解します。その後、ラットを同じ環境に戻し、餌を探す、出口を見つけるなどの強化信号を与えると、迷路を探索しなかった動物よりも早くゴールに到達することができます。トールマンはこれを「潜在学習」と呼び、これがモデルベースの強化学習の基礎となります。 「潜在学習」により、動物と人間は自分たちの世界を精神的に表現し、頭の中で仮説的なシナリオをシミュレートし、結果を予測することができます。
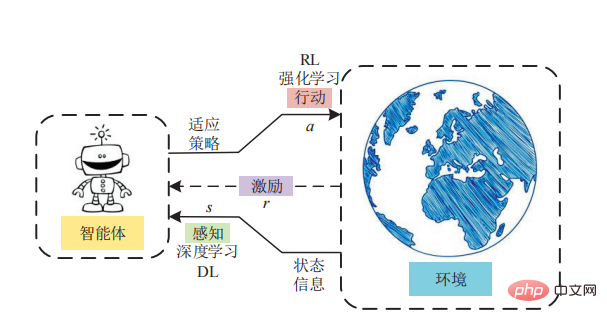
# モデルベースの強化学習の利点は、エージェントが環境内で試行錯誤を行う必要がなくなることです。モデルベースの強化学習は、チェスや囲碁などのボード ゲームをマスターできる人工知能システムの開発に特に成功していることを強調する価値があります。これはおそらく、これらのゲームの環境が決定論的であるためと考えられます。

モデルベース VS モデルフリー
一般に、モデルベースの強化学習は非常に時間がかかります。致命的な危険が発生する可能性があります。 「計算的には、モデルベースの強化学習ははるかに複雑です。まずモデルを取得し、精神的なシミュレーションを実行する必要があります。次に、神経プロセスの軌道を見つけて、アクションを実行する必要があります。しかし、モデルベースの強化学習は、必ずしもモデルフリー RL よりも複雑であるとは限りません。」 環境が非常に複雑な場合、比較的単純なモデル (すぐに取得できる) でモデル化できれば、シミュレーションははるかに単純になります。そして費用対効果が高い。
複数の学習モード
実際には、モデルベースの強化学習もモデルフリーの強化学習も完璧な解決策ではありません。強化学習システムが複雑な問題を解決しているところを見ると、モデルベースとモデルフリーの両方の強化学習が使用されている可能性が高く、場合によってはさらに多くの形式の学習が使用されている可能性があります。神経科学の研究によると、人間も動物も複数の学習方法があり、脳は常にこれらのモードを常に切り替えていることがわかっています。近年、複数の強化学習モデルを組み合わせた人工知能システムの構築への関心が高まっています。カリフォルニア大学サンディエゴ校の科学者による最近の研究では、モデルフリー強化学習とモデルベース強化学習を組み合わせることで、制御タスクにおいて優れたパフォーマンスを達成できることが示されています。 「AlphaGoのような複雑なアルゴリズムを見ると、モデルフリーRL要素とモデルベースRL要素の両方があります。ボード構成に基づいて状態値を学習します。基本的にはモデルフリーRLですが、ただし、モデルベースの前方探索も実行されます。」
重要な成果にもかかわらず、強化学習の進歩は依然として遅いです。 RL モデルが複雑で予測不可能な環境に直面すると、パフォーマンスが低下し始めます。
リー氏は次のように述べています:「私たちの脳は、多くの異なる状況に対処するために進化した学習アルゴリズムの複雑な世界だと思います。」
これらの学習モード間を常に移動するだけでなく、切り替えを超えて、また、意思決定に積極的に関与していない場合でも、脳は常にそれらを維持し、更新することができます。
心理学者のダニエル・カーネマン氏は、「さまざまな学習モジュールを維持し、それらを同時に更新することで、人工知能システムの効率と精度を向上させることができます。」
また、別の側面を理解する必要もあります。 AI システムに適切な帰納的バイアスを適用して、費用対効果の高い方法で正しいことを確実に学習できるようにします。何十億年にもわたる進化により、人間と動物には、できるだけ少ないデータを使用しながら効果的に学習するために必要な帰納的バイアスが与えられました。帰納的バイアスは、実生活で観察された現象からルールを要約し、モデルに特定の制約を課すものとして理解できます。これはモデル選択の役割を果たすことができます。つまり、実際のルールとより一致するモデルをモデルから選択します。仮説空間。 「私たちが環境から得られる情報はほとんどありません。その情報を使って一般化する必要があります。その理由は、脳には帰納的なバイアスがあり、少数の例から一般化しようとするバイアスがあるためです。それは、 「進化の産物です。」 「ますます多くの神経科学者がこれに興味を持っています。」 しかし、帰納的バイアスは物体認識タスクでは理解しやすいですが、社会的関係の構築などの抽象的な問題ではわかりにくくなります。今後も、知るべきことはたくさんあります~~~
参考資料:
https://thenextweb.com/news/everything-you-need-to-モデルフリーおよびモデルベースの強化学習について知る
以上が迷路を歩くネズミから人間を倒すAlphaGoまで、強化学習の発展の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7733
7733
 15
1643
14
1397
52
1290
25
1233
29
15
1643
14
1397
52
1290
25
1233
29

 WorldCoin(WLD)価格予測2025-2031:WLDは2031年までに4ドルに達しますか?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)価格予測2025-2031:WLDは2031年までに4ドルに達しますか?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)は、独自の生体認証とプライバシー保護メカニズムを備えた暗号通貨市場で際立っており、多くの投資家の注目を集めています。 WLDは、特にOpenai人工知能技術と組み合わせて、革新的なテクノロジーを備えたAltcoinsの間で驚くほど演奏しています。しかし、デジタル資産は今後数年間でどのように振る舞いますか? WLDの将来の価格を一緒に予測しましょう。 2025年のWLD価格予測は、2025年にWLDで大幅に増加すると予想されています。市場分析は、平均WLD価格が1.31ドルに達する可能性があり、最大1.36ドルであることを示しています。ただし、クマ市場では、価格は約0.55ドルに低下する可能性があります。この成長の期待は、主にWorldCoin2によるものです。
 クロスチェーントランザクションとはどういう意味ですか?クロスチェーントランザクションとは何ですか?
Apr 21, 2025 pm 11:39 PM
クロスチェーントランザクションとはどういう意味ですか?クロスチェーントランザクションとは何ですか?
Apr 21, 2025 pm 11:39 PM
クロスチェーントランザクションをサポートする交換:1。Binance、2。Uniswap、3。Sushiswap、4。CurveFinance、5。Thorchain、6。1inchExchange、7。DLNTrade、これらのプラットフォームはさまざまな技術を通じてマルチチェーン資産トランザクションをサポートします。
 なぜ仮想通貨価格の上昇または下落があるのですか?なぜ仮想通貨価格の上昇または下落があるのですか?
Apr 21, 2025 am 08:57 AM
なぜ仮想通貨価格の上昇または下落があるのですか?なぜ仮想通貨価格の上昇または下落があるのですか?
Apr 21, 2025 am 08:57 AM
仮想通貨価格の上昇の要因には、次のものが含まれます。1。市場需要の増加、2。供給の減少、3。刺激された肯定的なニュース、4。楽観的な市場感情、5。マクロ経済環境。衰退要因は次のとおりです。1。市場需要の減少、2。供給の増加、3。ネガティブニュースのストライキ、4。悲観的市場感情、5。マクロ経済環境。
 Aavenomicsは、Aaveプロトコルトークンを変更し、Tokenの買戻しを導入するための推奨事項です。
Apr 21, 2025 pm 06:24 PM
Aavenomicsは、Aaveプロトコルトークンを変更し、Tokenの買戻しを導入するための推奨事項です。
Apr 21, 2025 pm 06:24 PM
Aavenomicsは、Aaveプロトコルトークンを変更し、Aavedaoの定足数を実装したToken Reposを導入する提案です。 Aave Project Chain(ACI)の創設者であるMarc Zellerは、これをXで発表し、契約の新しい時代をマークしていることに注目しました。 Aave Chain Initiative(ACI)の創設者であるMarc Zellerは、Aavenomicsの提案にAave Protocolトークンの変更とトークンリポジトリの導入が含まれていると発表しました。 Zellerによると、これは契約の新しい時代を告げています。 Aavedaoのメンバーは、水曜日の週に100でした。
 カーネルエアドロップ報酬を獲得する方法バイナンスフルプロセス戦略
Apr 21, 2025 pm 01:03 PM
カーネルエアドロップ報酬を獲得する方法バイナンスフルプロセス戦略
Apr 21, 2025 pm 01:03 PM
暗号通貨の賑やかな世界では、新しい機会が常に現れます。現在、Kerneldao(Kernel)Airdropアクティビティは多くの注目を集め、多くの投資家の注目を集めています。それで、このプロジェクトの起源は何ですか? BNBホルダーはそれからどのような利点を得ることができますか?心配しないでください、以下はあなたのためにそれを一つ一つ明らかにします。
 ハイブリッドブロックチェーン取引プラットフォームとは何ですか?
Apr 21, 2025 pm 11:36 PM
ハイブリッドブロックチェーン取引プラットフォームとは何ですか?
Apr 21, 2025 pm 11:36 PM
暗号通貨交換を選択するための提案:1。流動性の要件については、優先度は、その順序の深さと強力なボラティリティ抵抗のため、Binance、gate.ioまたはokxです。 2。コンプライアンスとセキュリティ、Coinbase、Kraken、Geminiには厳格な規制の承認があります。 3.革新的な機能、Kucoinのソフトステーキング、Bybitのデリバティブデザインは、上級ユーザーに適しています。
 通貨サークル市場に関するリアルタイムデータの上位10の無料プラットフォーム推奨事項がリリースされます
Apr 22, 2025 am 08:12 AM
通貨サークル市場に関するリアルタイムデータの上位10の無料プラットフォーム推奨事項がリリースされます
Apr 22, 2025 am 08:12 AM
初心者に適した暗号通貨データプラットフォームには、Coinmarketcapと非小さいトランペットが含まれます。 1。CoinMarketCapは、初心者と基本的な分析のニーズに合わせて、グローバルなリアルタイム価格、市場価値、取引量のランキングを提供します。 2。小さい引用は、中国のユーザーが低リスクの潜在的なプロジェクトをすばやくスクリーニングするのに適した中国フレンドリーなインターフェイスを提供します。
 Rexas Finance(RXS)は、2025年にSolana(Sol)、Cardano(ADA)、XRP、Dogecoin(Doge)を上回ることができます
Apr 21, 2025 pm 02:30 PM
Rexas Finance(RXS)は、2025年にSolana(Sol)、Cardano(ADA)、XRP、Dogecoin(Doge)を上回ることができます
Apr 21, 2025 pm 02:30 PM
不安定な暗号通貨市場では、投資家は人気のある通貨を超えた代替品を探しています。 Solana(Sol)、Cardano(ADA)、XRP、Dogecoin(DOGE)などのよく知られた暗号通貨も、市場の感情、規制の不確実性、スケーラビリティなどの課題に直面しています。ただし、新しい新興プロジェクトであるRexasFinance(RXS)が出現しています。それは有名人の効果や誇大広告に依存するのではなく、現実世界の資産(RWA)とブロックチェーン技術を組み合わせて投資家に革新的な投資方法を提供することに焦点を当てています。この戦略により、2025年の最も成功したプロジェクトの1つになることを望んでいます。Rexasfi
