

jieba は、中国語単語セグメンテーション用の優れたサードパーティ ライブラリです。中国語の文章では各漢字が連続して書かれているため、単語ごとに特定の方法を使用して取得する必要があります。この方法は単語分割と呼ばれます。 Jieba は、Python コンピューティング エコシステムで中国語の単語を分割するための非常に優れたサードパーティ ライブラリであり、使用するにはインストールする必要があります。
jieba ライブラリには 3 つの単語分割モードが用意されていますが、実際には、単語分割効果を実現するには、非常にシンプルで効果的な 1 つの機能を習得するだけで十分です。
サードパーティのライブラリをインストールするには、pip ツールを使用し、コマンド ライン (IDLE ではなく) でインストール コマンドを実行する必要があります。注: Python ディレクトリとその下の Scripts ディレクトリを環境変数に追加する必要があります。
コマンド pip install jieba を使用して、サードパーティ ライブラリをインストールします。インストール後、インストールが成功したかどうかを示すメッセージが表示されます。
単語分割の原理: 簡単に言えば、jieba ライブラリは中国語語彙ライブラリを通じて単語分割を識別します。まず、中国語辞書を使用して、辞書を介して単語を構成する漢字間の関連確率を計算するため、漢字間の確率を計算することにより、単語の分割結果を形成できます。もちろん、jieba 独自の中国語語彙ライブラリに加えて、ユーザーはそれにカスタム フレーズを追加することもでき、それによって jieba の単語の分割を特定の分野での使用に近づけることができます。
jieba は Python 用の中国語単語分割ライブラリです。その使用方法は次のとおりです。
方式1: pip install jieba 方式2: 先下载 http://pypi.python.org/pypi/jieba/ 然后解压,运行 python setup.py install
Jieba でよく使用される 3 つのモード:
正確モード、文をテキスト分析に適した最も正確な形式に切り取ろうとします。
フル モードでは、文内の単語に変換できるすべての単語をスキャンします。これは非常に高速です。しかし、あいまいさは解決できません ;
検索エンジン モードは、正確なモードに基づいて、長い単語を再分割して再現率を向上させ、検索エンジンの単語の分割に適しています。
単語の分割には jieba.cut メソッドと jieba.cut_for_search メソッドを使用できます。両方のメソッドから返される構造は反復可能なジェネレーターです。では、for ループを使用して単語分割後に取得した各単語 (Unicode) を取得するか、jieba.lcut および jieba.lcut_for_search を直接使用してリストを返すことができます。
jieba.Tokenizer(dictionary=DEFAULT_DICT): このメソッドを使用してトークナイザーをカスタマイズし、同時に異なる辞書を使用します。 jieba.dt はデフォルトの単語セグメンタであり、すべてのグローバル単語セグメンテーション関連関数はこの単語セグメンタのマッピングです。
jieba.cut および jieba.lcut 受け入れ可能なパラメータは次のとおりです。
単語の分割が必要な文字列 ( unicode または UTF-8 文字列、GBK 文字列)
cut_all: フル モードを使用するかどうか。デフォルト値は False
HMM: HMM モデルを使用するかどうかを制御するために使用されます。デフォルト値は True
##jieba.cut_for_search および です。 jieba.lcut_for_search 2 つのパラメータを受け入れます:
True
# 全匹配
seg_list = jieba.cut("今天哪里都没去,在家里睡了一天", cut_all=True)
print(list(seg_list)) # ['今天', '哪里', '都', '没去', '', '', '在家', '家里', '睡', '了', '一天']
# 精确匹配 默认模式
seg_list = jieba.cut("今天哪里都没去,在家里睡了一天", cut_all=False)
print(list(seg_list)) # ['今天', '哪里', '都', '没', '去', ',', '在', '家里', '睡', '了', '一天']
# 精确匹配
seg_list = jieba.cut_for_search("今天哪里都没去,在家里睡了一天")
print(list(seg_list)) # ['今天', '哪里', '都', '没', '去', ',', '在', '家里', '睡', '了', '一天']使用法: jieba.load_userdict(dict_path)
大学コースディープラーニング
以下は、完全一致、完全一致、およびカスタム辞書の使用の違いを比較しています:
import jieba
test_sent = """
数学是一门基础性的大学课程,深度学习是基于数学的,尤其是线性代数课程
"""
words = jieba.cut(test_sent)
print(list(words))
# ['\n', '数学', '是', '一门', '基础性', '的', '大学', '课程', ',', '深度',
# '学习', '是', '基于', '数学', '的', ',', '尤其', '是', '线性代数', '课程', '\n']
words = jieba.cut(test_sent, cut_all=True)
print(list(words))
# ['\n', '数学', '是', '一门', '基础', '基础性', '的', '大学', '课程', '', '', '深度',
# '学习', '是', '基于', '数学', '的', '', '', '尤其', '是', '线性', '线性代数', '代数', '课程', '\n']
jieba.load_userdict("userdict.txt")
words = jieba.cut(test_sent)
print(list(words))
# ['\n', '数学', '是', '一门', '基础性', '的', '大学课程', ',', '深度学习', '是',
# '基于', '数学', '的', ',', '尤其', '是', '线性代数', '课程', '\n']
jieba.add_word("尤其是")
jieba.add_word("线性代数课程")
words = jieba.cut(test_sent)
print(list(words))
# ['\n', '数学', '是', '一门', '基础性', '的', '大学课程', ',', '深度学习', '是',
# '基于', '数学', '的', ',', '尤其是', '线性代数课程', '\n']上の例からわかるように、カスタム辞書の使用とデフォルトの辞書の使用の違い。
jieba.add_word(): カスタム辞書に単語を追加します。
キーワード抽出
キーワード抽出には jieba.analyse.extract_tags() 関数を使用します。パラメータは次のとおりです。
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowedPOS=( ))
也可以使用 jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件。
基于 TF-IDF 算法和TextRank算法的关键词抽取:
import jieba.analyse file = "sanguo.txt" topK = 12 content = open(file, 'rb').read() # 使用tf-idf算法提取关键词 tags = jieba.analyse.extract_tags(content, topK=topK) print(tags) # ['玄德', '程远志', '张角', '云长', '张飞', '黄巾', '封谞', '刘焉', '邓茂', '邹靖', '姓名', '招军'] # 使用textrank算法提取关键词 tags2 = jieba.analyse.textrank(content, topK=topK) # withWeight=True:将权重值一起返回 tags = jieba.analyse.extract_tags(content, topK=topK, withWeight=True) print(tags) # [('玄德', 0.1038549799467099), ('程远志', 0.07787459004363208), ('张角', 0.0722532891360849), # ('云长', 0.07048801593691037), ('张飞', 0.060972692853113214), ('黄巾', 0.058227157790330185), # ('封谞', 0.0563904127495283), ('刘焉', 0.05470798376886792), ('邓茂', 0.04917692565566038), # ('邹靖', 0.04427258239705188), ('姓名', 0.04219704283997642), ('招军', 0.04182041076757075)]
上面的代码是读取文件,提取出现频率最高的前12个词。
词性标注主要是标记文本分词后每个词的词性,使用例子如下:
import jieba
import jieba.posseg as pseg
# 默认模式
seg_list = pseg.cut("今天哪里都没去,在家里睡了一天")
for word, flag in seg_list:
print(word + " " + flag)
"""
使用 jieba 默认模式的输出结果是:
我 r
Prefix dict has been built successfully.
今天 t
吃 v
早饭 n
了 ul
"""
# paddle 模式
words = pseg.cut("我今天吃早饭了",use_paddle=True)
"""
使用 paddle 模式的输出结果是:
我 r
今天 TIME
吃 v
早饭 n
了 xc
"""paddle模式的词性对照表如下:
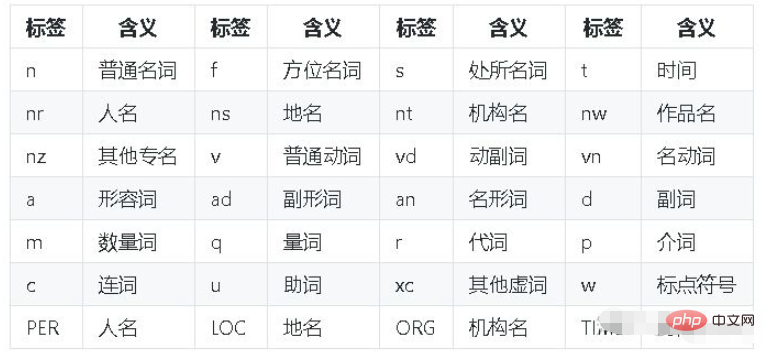
jieba分词有三种模式:精确模式、全模式和搜索引擎模式。
简单说,精确模式就是把一段文本精确的切分成若干个中文单词,若干个中文单词之间经过组合就精确的还原为之前的文本,其中不存在冗余单词。精确模式是最常用的分词模式。
进一步jieba又提供了全模式,全模式是把一段中文文本中所有可能的词语都扫描出来,可能有一段文本它可以切分成不同的模式或者有不同的角度来切分变成不同的词语,那么jieba在全模式下把这样的不同的组合都挖掘出来,所以如果用全模式来进行分词,分词的信息组合起来并不是精确的原有文本,会有很多的冗余。
而搜索引擎模式更加智能,它是在精确模式的基础上对长词进行再次切分,将长的词语变成更短的词语,进而适合搜索引擎对短词语的索引和搜索,在一些特定场合用的比较多。
jieba.lcut(s)
精确模式,能够对一个字符串精确地返回分词结果,而分词的结果使用列表形式来组织。例如:
>>> import jieba
>>> jieba.lcut("中国是一个伟大的国家")
Building prefix dict from the default dictionary ...
Dumping model to file cache C:\Users\ADMINI~1\AppData\Local\Temp\jieba.cache
Loading model cost 2.489 seconds.
Prefix dict has been built successfully.
['中国', '是', '一个', '伟大', '的', '国家']jieba.lcut(s,cut_all=True)
全模式,能够返回一个列表类型的分词结果,但结果存在冗余。例如:
>>> import jieba
>>> jieba.lcut("中国是一个伟大的国家",cut_all=True)
['中国', '国是', '一个', '伟大', '的', '国家']jieba.lcut_for_search(s)
搜索引擎模式,能够返回一个列表类型的分词结果,也存在冗余。例如:
>>> import jieba
>>> jieba.lcut_for_search("中华人民共和国是伟大的")
['中华', '华人', '人民', '共和', '共和国', '中华人民共和国', '是', '伟大', '的']jieba.add_word(w)
向分词词库添加新词w
最重要的就是jieba.lcut(s)函数,完成精确的中文分词。
以上がPythonでjiebaライブラリを使用するにはどうすればよいですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



