

ConcurrentHashMap を使用して Java でスレッドセーフ マッピングを実装するにはどうすればよいですか?

jdk1.7バージョン
データ構造
/**
* The segments, each of which is a specialized hash table.
*/
final Segment<K,V>[] segments;主にSegment配列であり、コメントも書かれており、それぞれが特殊なハッシュテーブルであることがわかります。
セグメントとは何かを見てみましょう。
static final class Segment<K,V> extends ReentrantLock implements Serializable {
......
/**
* The per-segment table. Elements are accessed via
* entryAt/setEntryAt providing volatile semantics.
*/
transient volatile HashEntry<K,V>[] table;
transient int threshold;
final float loadFactor;
// 构造函数
Segment(float lf, int threshold, HashEntry<K,V>[] tab) {
this.loadFactor = lf;
this.threshold = threshold;
this.table = tab;
}
......
}上記はコードの一部ですが、セグメントが ReentrantLock を継承していることがわかり、実際には各セグメントがロックになっています。
HashEntry 配列が格納され、変数は volatile で変更されます。 HashEntry はハッシュマップのノードに似ており、リンク リストのノードでもあります。
具体的なコードを見てみましょう. メンバー変数が volatile で変更されているという点で hashmap とは少し異なることがわかります。
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
HashEntry(int hash, K key, V value, HashEntry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
......
}ということで、ConcurrentHashMapのデータ構造はほぼ下図のようになっています。
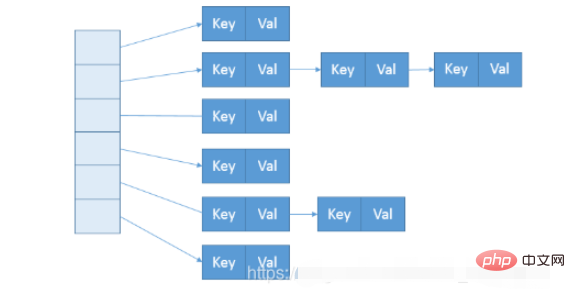
構築中、セグメントの数はいわゆる concurrentcyLevel によって決まります。デフォルトは 16 です。対応するコンストラクターで直接指定することもできます。 Java では 2 のべき乗値である必要があることに注意してください。入力が 15 のような非べき乗値の場合、16 のような 2 のべき乗値に自動的に調整されます。
単純な get メソッドから始めてソース コードを見てみましょう
get()
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
// 通过unsafe获取Segment数组的元素
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
// 还是通过unsafe获取HashEntry数组的元素
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}get のロジックは非常に単純です。つまり、セグメントの添字に対応する HashEntry 配列を検索し、HashEntry 配列の添字に対応するリンク リスト ヘッダーを見つけて、リンク リストを走査してデータを取得します。
配列内のデータを取得するには、UNSAFE.getObjectVolatile(segments, u) を使用します。Unsafe は、C 言語のようにメモリに直接アクセスする機能を提供します。このメソッドは、オブジェクトの対応するオフセットのデータを取得できます。 u は計算されたオフセットであるため、segments[i] と同等ですが、より効率的です。
put()
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}put 操作では、対応するセグメントが Unsafe 呼び出しメソッドを通じて直接取得され、スレッドセーフな put 操作が実行されます。主なロジックは Segment 内の put メソッドです
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// scanAndLockForPut会去查找是否有key相同Node
// 无论如何,确保获取锁
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
// 更新已有value...
}
else {
// 放置HashEntry到特定位置,如果超过阈值,进行rehash
// ...
}
}
} finally {
unlock();
}
return oldValue;
}size()
メイン コードを見てみましょう。
for (;;) {
// 如果重试次数等于默认的2,就锁住所有的segment,来计算值
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
// 如果sum不再变化,就表示得到了一个确切的值
if (sum == last)
break;
last = sum;
}これは実際に、すべてのセグメントの数の合計が一致する場合 取得された値が等しい場合は、マップが操作されていないことを意味し、この値は比較的正しい値です。 2回リトライしても統一値が取得できない場合は、全セグメントをロックして再度値を取得してください。
拡張
private void rehash(HashEntry<K,V> node) {
HashEntry<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
// 新表的大小是原来的两倍
int newCapacity = oldCapacity << 1;
threshold = (int)(newCapacity * loadFactor);
HashEntry<K,V>[] newTable =
(HashEntry<K,V>[]) new HashEntry[newCapacity];
int sizeMask = newCapacity - 1;
for (int i = 0; i < oldCapacity ; i++) {
HashEntry<K,V> e = oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
int idx = e.hash & sizeMask;
if (next == null) // Single node on list
newTable[idx] = e;
else { // Reuse consecutive sequence at same slot
// 如果有多个节点
HashEntry<K,V> lastRun = e;
int lastIdx = idx;
// 这里操作就是找到末尾的一段索引值都相同的链表节点,这段的头结点是lastRun.
for (HashEntry<K,V> last = next;
last != null;
last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
// 然后将lastRun结点赋值给数组位置,这样lastRun后面的节点也跟着过去了。
newTable[lastIdx] = lastRun;
// 之后就是复制开头到lastRun之间的节点
// Clone remaining nodes
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
}jdk1.8バージョン
データ構造
ConcurrentHashmapの1.8バージョンは全体としてHashmapと似ていますが、セグメントは削除されました。ノードを使用する配列です。
transient volatile Node<K,V>[] table;
1.8 には Segment という内部クラスがまだ存在しますが、その存在はシリアル化の互換性のためのみであり、現在は使用されていません。
ノードを見てみましょう。node
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
Node(int hash, K key, V val, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
......
}これは、HashMap のノードノードに似ていますが、Map.Entry も実装しています。違いは、val と next が volatile で変更されていることです。視認性を確保します。
put()
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
// 初始化
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 利用CAS去进行无锁线程安全操作,如果bin是空的
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
// 细粒度的同步修改操作...
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 找到相同key就更新
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
// 没有相同的就新增
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// 如果是树节点,进行树的操作
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
// Bin超过阈值,进行树化
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}同期ロジックでは、通常推奨される ReentrantLock などの代わりに synchronized が使用されていることがわかります。これはなぜですか? JDK1.8ではsynchronizedの最適化が継続されているため、性能差をあまり気にする必要がなくなり、またReentrantLockに比べてメモリ消費量も削減できる点も非常に大きなメリットです。
同時に、Unsafe を使用することでより詳細な実装が最適化されており、たとえば、tabAt は getObjectAcquire を直接使用して、間接呼び出しのオーバーヘッドを回避しています。
それでは、サイズがどのように機能するかを見てみましょう。
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}ここでは、メンバー変数 counterCells を取得し、トラバースして合計数を取得します。
実際、CounterCell の動作は java.util.concurrent.atomic.LongAdder に基づいており、Striped64 内の複雑なロジックを利用して、JVM が効率を高める代わりにスペースを使用する方法です。これは非常に特殊なものですが、ほとんどの場合、ほとんどのアプリケーションのパフォーマンスのニーズを満たすのに十分な AtomicLong を使用することをお勧めします。
拡張
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
......
// 初始化
if (nextTab == null) { // initiating
try {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
transferIndex = n;
}
int nextn = nextTab.length;
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
// 是否继续处理下一个
boolean advance = true;
// 是否完成
boolean finishing = false; // to ensure sweep before committing nextTab
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing)
advance = false;
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
// 首次循环才会进来这里
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
//扩容结束后做后续工作
if (finishing) {
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
//每当一条线程扩容结束就会更新一次 sizeCtl 的值,进行减 1 操作
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
finishing = advance = true;
i = n; // recheck before commit
}
}
// 如果是null,设置fwd
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
// 说明该位置已经被处理过了,不需要再处理
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
else {
// 真正的处理逻辑
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
if (fh >= 0) {
int runBit = fh & n;
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
// 树节点操作
else if (f instanceof TreeBin) {
......
}
}
}
}
}
} }
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
// 树节点操作
else if (f instanceof TreeBin) {
......
}
}
}
}
}
}以上がConcurrentHashMap を使用して Java でスレッドセーフ マッピングを実装するにはどうすればよいですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7563
7563
 15
1385
52
84
11
28
99
15
1385
52
84
11
28
99


 ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
Java の Weka へのガイド。ここでは、weka java の概要、使い方、プラットフォームの種類、利点について例を交えて説明します。

 Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
この記事では、Java Spring の面接で最もよく聞かれる質問とその詳細な回答をまとめました。面接を突破できるように。
 Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8は、Stream APIを導入し、データ収集を処理する強力で表現力のある方法を提供します。ただし、ストリームを使用する際の一般的な質問は次のとおりです。 従来のループにより、早期の中断やリターンが可能になりますが、StreamのForeachメソッドはこの方法を直接サポートしていません。この記事では、理由を説明し、ストリーム処理システムに早期終了を実装するための代替方法を調査します。 さらに読み取り:JavaストリームAPIの改善 ストリームを理解してください Foreachメソッドは、ストリーム内の各要素で1つの操作を実行する端末操作です。その設計意図はです
 Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプに関するガイド。ここでは、Java でタイムスタンプを日付に変換する方法とその概要について、例とともに説明します。
 カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルは3次元の幾何学的図形で、両端にシリンダーと半球で構成されています。カプセルの体積は、シリンダーの体積と両端に半球の体積を追加することで計算できます。このチュートリアルでは、さまざまな方法を使用して、Javaの特定のカプセルの体積を計算する方法について説明します。 カプセルボリュームフォーミュラ カプセルボリュームの式は次のとおりです。 カプセル体積=円筒形の体積2つの半球体積 で、 R:半球の半径。 H:シリンダーの高さ(半球を除く)。 例1 入力 RADIUS = 5ユニット 高さ= 10単位 出力 ボリューム= 1570.8立方ユニット 説明する 式を使用してボリュームを計算します。 ボリューム=π×R2×H(4
 Spring Tool Suiteで最初のSpring Bootアプリケーションを実行するにはどうすればよいですか?
Feb 07, 2025 pm 12:11 PM
Spring Tool Suiteで最初のSpring Bootアプリケーションを実行するにはどうすればよいですか?
Feb 07, 2025 pm 12:11 PM
Spring Bootは、Java開発に革命をもたらす堅牢でスケーラブルな、生産対応のJavaアプリケーションの作成を簡素化します。 スプリングエコシステムに固有の「構成に関する慣習」アプローチは、手動のセットアップを最小化します。
