

ChatGPT のコアメソッドを AI ペイントに使用でき、効果が 47% 向上 担当著者: OpenAI に切り替えました

ChatGPT には「ヒューマン フィードバック強化学習 (RLHF)」と呼ばれる核となるトレーニング方法があります。
これにより、モデルがより安全になり、出力結果が人間の意図とより一致するようになります。
Google Research と UC Berkeley の研究者らは、AI ペイントでこの方法を使用すると、画像が入力と完全に一致しない状況を「処理」でき、その効果も驚くほど良好であることを発見しました—
最大 47% の改善が達成できます。

△左が安定拡散、右が改善効果
現時点では、AIGC分野で人気の2つのモデルが見つかったようですある種の「共鳴」。
AI ペイントに RLHF を使用するにはどうすればよいですか?
RLHF、正式名は「Reinforcement Learning from Human Feedback」で、2017 年に OpenAI と DeepMind が共同開発した強化学習テクノロジーです。
名前が示すように、RLHF はモデルの出力結果 (つまりフィードバック) を人間が評価してモデルを直接最適化します。LLM では、「モデルの値」を人間の値とより一致させることができます。
AI 画像生成モデルでは、生成された画像をテキスト プロンプトと完全に一致させることができます。
具体的には、まず人間のフィードバックデータを収集します。
ここで、研究者らは合計 27,000 を超える「テキストと画像のペア」を生成し、何人かの人間にそれらを採点するように依頼しました。
わかりやすくするために、テキスト プロンプトには、量、色、背景、ブレンド オプションに関連する次の 4 つのカテゴリのみが含まれます。人間のフィードバックは、「良い」、「悪い」、「しない」の 3 つのみに分類されます。知っています(スキップ)" "。

2 番目に、報酬関数を学習します。
このステップでは、取得した人間の評価で構成されるデータセットを使用して報酬関数をトレーニングし、この関数を使用してモデルの出力に対する人間の満足度を予測します (式の赤い部分)。
このようにして、モデルは結果がテキストとどの程度一致するかを認識します。
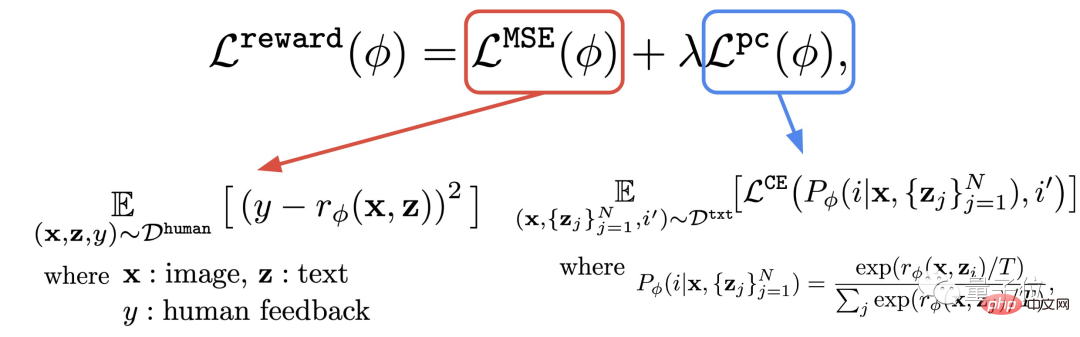
#報酬関数に加えて、著者は補助タスク (式の青い部分) も提案しています。
つまり、画像生成が完了した後、モデルは大量のテキストを提供しますが、元のテキストはそのうちの 1 つだけであり、画像が一致するかどうかを報酬モデルに「自らチェック」させます。文章。
この逆の操作により、効果を「二重の保険」にすることができます (下図のステップ 2 を理解するのに役立ちます)。
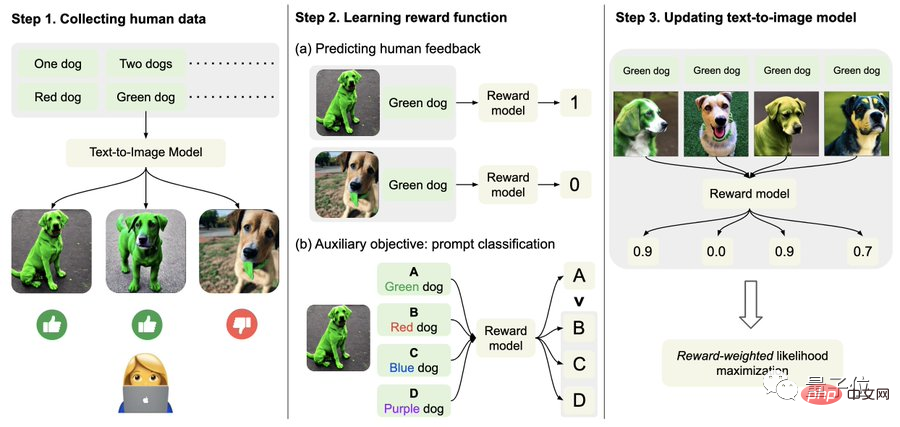
最後に、微調整です。
つまり、テキスト画像生成モデルは、報酬重み付け尤度最大化 (以下の式の最初の項目) を通じて更新されます。
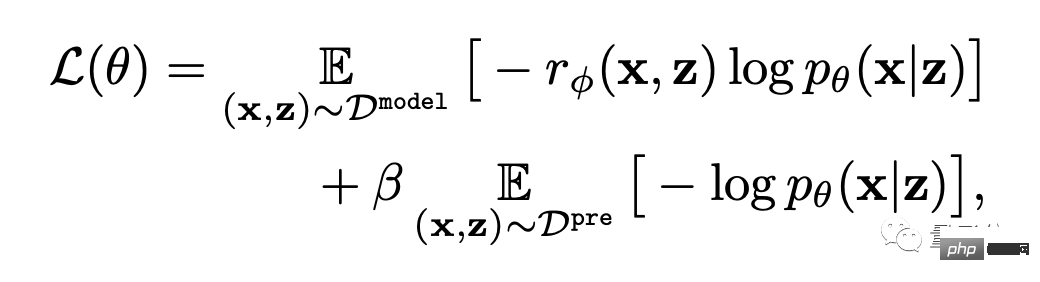
#過学習を避けるために、作成者はトレーニング前のデータセットの NLL 値 (式の第 2 項) を最小化しました。このアプローチは、structGPT (ChatGPT の「直接の前身」) に似ています。
エフェクトは 47% 増加しましたが、明瞭度は 5% 低下しました。
次の一連のエフェクトに示すように、元の安定した拡散と比較して、RLHF で微調整されたモデルは、 :
(1) テキスト内の「two」と「green」をより正確に理解します;

(2) ではありません「海」を無視する 背景要件として;
(3) 赤いタイガーが必要な場合は、「より赤い」結果が得られます。
具体的なデータから判断すると、微調整モデルの人間の満足度は 50% で、元のモデル (3%) と比較して 47% 向上しています。
ただし、その代償として画像の鮮明さが 5% 失われます。
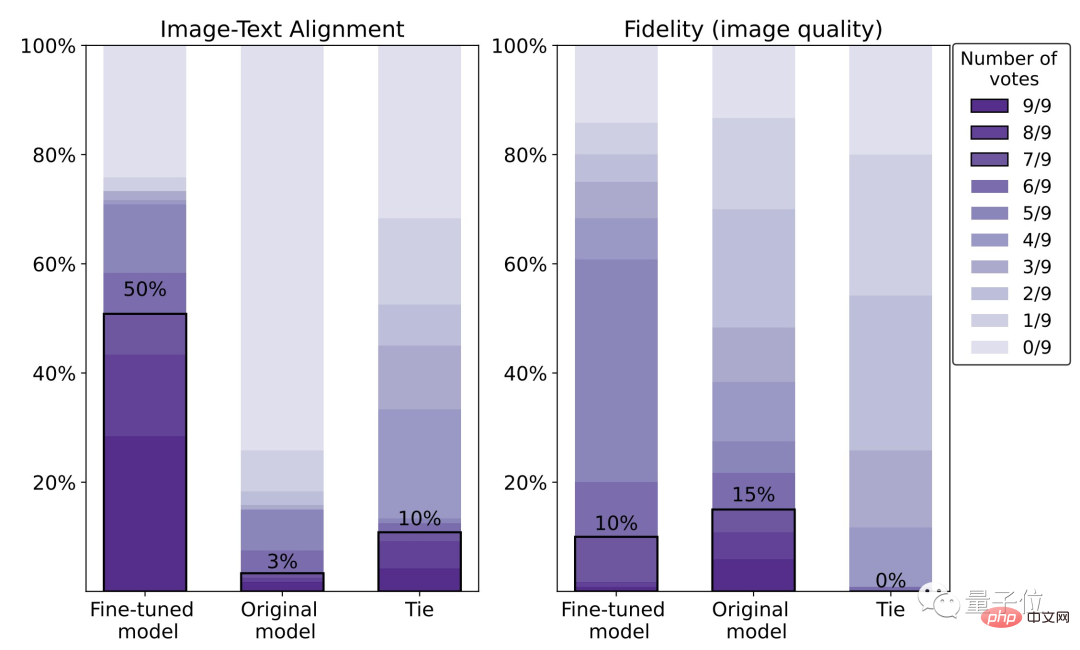
下の写真からも、右側のオオカミが左側のオオカミよりも明らかにぼやけていることがわかります。
はい したがって、著者らは、より大規模な人による評価データセットとより優れた最適化 (RL) 手法を使用することで状況を改善できる可能性があると示唆しています。
著者について
この記事の著者は合計 9 名です。

韓国科学技術研究院の Google AI 研究科学者 Kimin Lee 博士は、カリフォルニア大学バークレー校で博士研究員として研究を実施しました。

中国人著者は 3 人です:
Liu Hao カリフォルニア大学バークレー校の博士課程の学生で、主な研究対象はフィードバック ニューラルです。ネットワーク。
Du Yuqing はカリフォルニア大学バークレー校の博士課程候補者で、主な研究方向は教師なし強化学習法です。
責任著者のShixiang Shane Gu (Gu Shixiang) は、学部の学位を三大巨人の一人であるヒントンに師事し、ケンブリッジ大学を卒業して博士号を取得しました。

△Gu Shixiang
この記事を書いているとき、彼はまだ Google 社員でしたが、現在は OpenAI に転職しました。 ChatGPT担当者からの報告に直属します。
論文アドレス:
https://arxiv.org/abs/2302.12192
参考リンク: [1] https://www.php .cn/link/4d42d2f5010c1c13f23492a35645d6a7
[2] https://openai.com/blog/instruction-following/
以上がChatGPT のコアメソッドを AI ペイントに使用でき、効果が 47% 向上 担当著者: OpenAI に切り替えましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7478
7478
 15
1377
52
77
11
19
33
15
1377
52
77
11
19
33

 酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
データベース酸属性の詳細な説明酸属性は、データベーストランザクションの信頼性と一貫性を確保するための一連のルールです。データベースシステムがトランザクションを処理する方法を定義し、システムのクラッシュ、停電、または複数のユーザーの同時アクセスの場合でも、データの整合性と精度を確保します。酸属性の概要原子性:トランザクションは不可分な単位と見なされます。どの部分も失敗し、トランザクション全体がロールバックされ、データベースは変更を保持しません。たとえば、銀行の譲渡が1つのアカウントから控除されているが別のアカウントに増加しない場合、操作全体が取り消されます。 TRANSACTION; updateaccountssetbalance = balance-100wh
 mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
MySQLはJSONデータを返すことができます。 json_extract関数はフィールド値を抽出します。複雑なクエリについては、Where句を使用してJSONデータをフィルタリングすることを検討できますが、そのパフォーマンスへの影響に注意してください。 JSONに対するMySQLのサポートは絶えず増加しており、最新バージョンと機能に注意を払うことをお勧めします。
 マスターSQL制限条項:クエリの行数を制御する
Apr 08, 2025 pm 07:00 PM
マスターSQL制限条項:クエリの行数を制御する
Apr 08, 2025 pm 07:00 PM
sqllimit句:クエリ結果の行数を制御します。 SQLの制限条項は、クエリによって返される行数を制限するために使用されます。これは、大規模なデータセット、パジネートされたディスプレイ、テストデータを処理する場合に非常に便利であり、クエリ効率を効果的に改善することができます。構文の基本的な構文:SelectColumn1、column2、... FromTable_nameLimitnumber_of_rows; number_of_rows:返された行の数を指定します。オフセットの構文:SelectColumn1、column2、... FromTable_nameLimitoffset、number_of_rows; offset:skip
 高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
MySQLデータベースパフォーマンス最適化ガイドリソース集約型アプリケーションでは、MySQLデータベースが重要な役割を果たし、大規模なトランザクションの管理を担当しています。ただし、アプリケーションのスケールが拡大すると、データベースパフォーマンスのボトルネックが制約になることがよくあります。この記事では、一連の効果的なMySQLパフォーマンス最適化戦略を検討して、アプリケーションが高負荷の下で効率的で応答性の高いままであることを保証します。実際のケースを組み合わせて、インデックス作成、クエリ最適化、データベース設計、キャッシュなどの詳細な主要なテクノロジーを説明します。 1.データベースアーキテクチャの設計と最適化されたデータベースアーキテクチャは、MySQLパフォーマンスの最適化の基礎です。いくつかのコア原則は次のとおりです。適切なデータ型を選択し、ニーズを満たす最小のデータ型を選択すると、ストレージスペースを節約するだけでなく、データ処理速度を向上させることもできます。
 Prometheus MySQL ExporterでMySQLおよびMariadb液滴を監視します
Apr 08, 2025 pm 02:42 PM
Prometheus MySQL ExporterでMySQLおよびMariadb液滴を監視します
Apr 08, 2025 pm 02:42 PM
MySQLおよびMariaDBデータベースの効果的な監視は、最適なパフォーマンスを維持し、潜在的なボトルネックを特定し、システム全体の信頼性を確保するために重要です。 Prometheus MySQL Exporterは、プロアクティブな管理とトラブルシューティングに重要なデータベースメトリックに関する詳細な洞察を提供する強力なツールです。
 MySQLの主な鍵はヌルにすることができます
Apr 08, 2025 pm 03:03 PM
MySQLの主な鍵はヌルにすることができます
Apr 08, 2025 pm 03:03 PM
MySQLプライマリキーは、データベース内の各行を一意に識別するキー属性であるため、空にすることはできません。主キーが空になる可能性がある場合、レコードを一意に識別することはできません。これにより、データの混乱が発生します。一次キーとして自己挿入整数列またはUUIDを使用する場合、効率やスペース占有などの要因を考慮し、適切なソリューションを選択する必要があります。
 MongoDBデータベースパスワードを表示するNAVICATの方法
Apr 08, 2025 pm 09:39 PM
MongoDBデータベースパスワードを表示するNAVICATの方法
Apr 08, 2025 pm 09:39 PM
Hash値として保存されているため、Navicatを介してMongoDBパスワードを直接表示することは不可能です。紛失したパスワードを取得する方法:1。パスワードのリセット。 2。構成ファイルを確認します(ハッシュ値が含まれる場合があります)。 3.コードを確認します(パスワードをハードコードできます)。
 SQLで条項ごとに注文をマスターする:効果的にデータを並べ替える
Apr 08, 2025 pm 07:03 PM
SQLで条項ごとに注文をマスターする:効果的にデータを並べ替える
Apr 08, 2025 pm 07:03 PM
SQLORDERBY句の詳細な説明:Data OrderBY句の効率的なソートは、クエリ結果セットをソートするために使用されるSQLの重要なステートメントです。単一の列または複数の列で昇順(ASC)または下降順序(DESC)で配置でき、データの読みやすさと分析効率を大幅に改善できます。 Orderby Syntax SelectColumn1、column2、... fromTable_nameOrderByColumn_name [asc | desc]; column_name:列ごとに並べ替えます。 ASC:昇順の注文ソート(デフォルト)。 DESC:降順で並べ替えます。 Orderbyの主な機能:マルチコラムソート:複数の列のソートをサポートし、列の順序によりソートの優先度が決まります。以来
