

最新の研究により、GPT-4 の欠点が明らかになりました。言語の曖昧さを完全に理解できない!

自然言語推論 (NLI) は自然言語処理における重要なタスクであり、その目標は、与えられた前提と仮定に基づいて前提から仮説を推論できるかどうかを判断することです。ただし、曖昧さは自然言語の本質的な特徴であるため、曖昧さに対処することも人間の言語理解の重要な部分です。人間の言語表現は多様であるため、あいまいさの処理は自然言語推論の問題を解決する際の困難の 1 つとなっています。現在、さまざまな自然言語処理アルゴリズムが質疑応答システム、音声認識、インテリジェント翻訳、自然言語生成などのシナリオに適用されていますが、これらのテクノロジーを使用しても、あいまいさを完全に解決することは依然として非常に困難な課題です。
NLI タスクの場合、GPT-4 などの大規模な自然言語処理モデルは課題に直面しています。問題の 1 つは、言語のあいまいさにより、モデルが文の本当の意味を正確に理解することが困難になることです。さらに、自然言語の柔軟性と多様性により、異なるテキスト間にさまざまな関係が存在する可能性があり、NLI タスクのデータセットが非常に複雑になり、自然言語処理モデルの普遍性と多用途性にも影響します。重要な課題。したがって、曖昧な言語を扱う場合、将来的には大規模モデルが成功するかどうかが非常に重要であり、大規模モデルは会話インターフェイスや筆記補助などの分野で広く使用されています。あいまいさに対処すると、さまざまな状況に適応し、コミュニケーションの明瞭性が向上し、誤解を招くまたは欺瞞的なスピーチを識別する能力が向上します。
大規模モデルにおける曖昧性について説明するこの論文のタイトルには、「We're Afraid...」というダジャレが使用されています。これは、言語モデルがあいまい性を正確にモデル化することの難しさについての現在の懸念を表現しているだけでなく、論文が言語構造について説明していることを意味します。この記事では、人々が自然言語をより正確に理解して生成し、モデルの新たなブレークスルーを達成するために、強力な新しい大規模モデルに真の挑戦をするための新しいベンチマークの開発に熱心に取り組んでいることも示しています。
論文のタイトル: 言語モデルが曖昧さをモデル化していないことを恐れています
論文のリンク: https://arxiv.org/abs/2304.14399
コードとデータのアドレス: https://github.com/alisawuffles/ambient
この記事の著者は、事前トレーニングされた大規模モデルが、複数の可能な解釈を持つ文を認識して区別する能力があるかどうかを研究し、どのように解釈されるかを評価する予定です。モデルは、さまざまな読み取りと解釈を区別します。ただし、既存のベンチマーク データにはあいまいな例が含まれていないことが多いため、この問題を調査するには独自の実験を構築する必要があります。
従来の NLI 3 方向アノテーション スキームは、自然言語推論 (NLI) タスクに使用されるラベル付け方法を指します。アノテーターは、元のテキストと仮説を表す 3 つのラベルから 1 つのラベルを選択する必要があります。間。 3 つのラベルは通常、「含意」、「中立」、「矛盾」です。
著者らは、NLI タスクの形式を使用して実験を実施し、含意関係に対する前提または仮定における曖昧さの影響を通じて曖昧さを特徴付ける関数的アプローチを採用しました。著者らは、さまざまな語彙的、構文的、および語用論的な曖昧さをカバーし、複数の異なるメッセージを伝える可能性のある文をより広範囲にカバーする、AMBIENT (含意の曖昧さ) と呼ばれるベンチマークを提案しています。
図 1 に示すように、あいまいさは無意識の誤解である場合もあります (図 1 の上部)、または聴衆を誤解させるために意図的に使用されている場合もあります (図 1 の下部)。例えば、猫が家を出た後に迷子になった場合、その猫は家に帰る道が見つからないという意味で迷子になり(暗示エッジ)、数日間家に戻らなかった場合、他の猫が家に帰っていないという意味で迷子になります。見つからない、ある意味迷っている(中立側)。
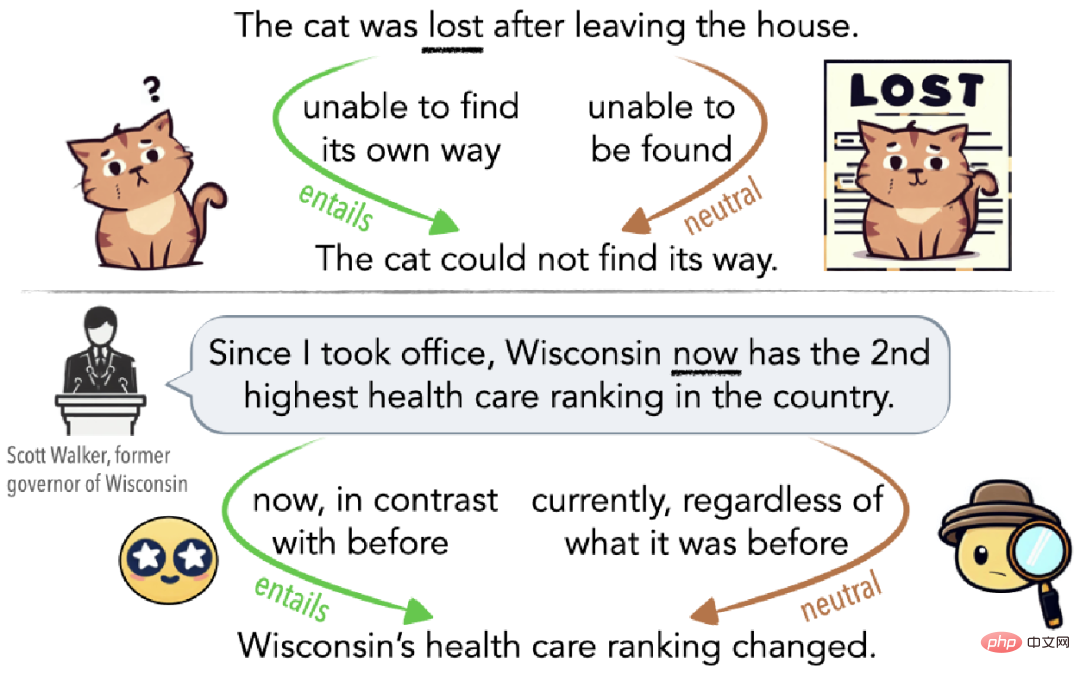
▲図 1 Cat Lost によって説明された曖昧さの例
AMBIENT データセットの紹介
選択された例
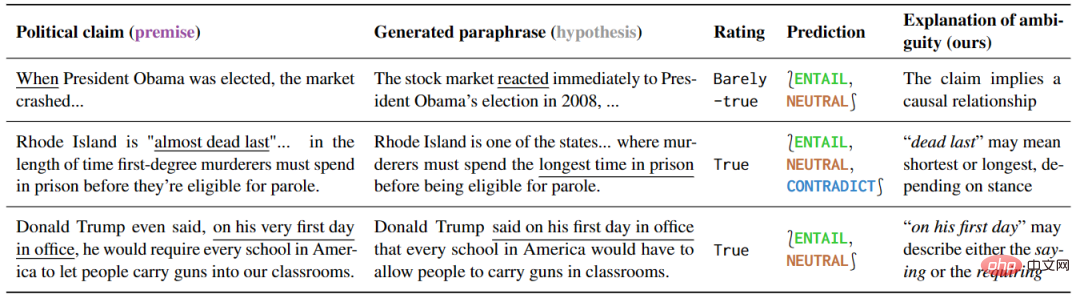
著者手書きサンプルや既存の NLI データセットや言語学の教科書からのサンプルなど、複数の種類のあいまいさをカバーする 1645 の文例を提供します。 AMBIENT の各例には、表 1 に示すように、さまざまな考えられる理解に対応する一連のラベルと、各理解に対する曖昧さ回避のリライトが含まれています。
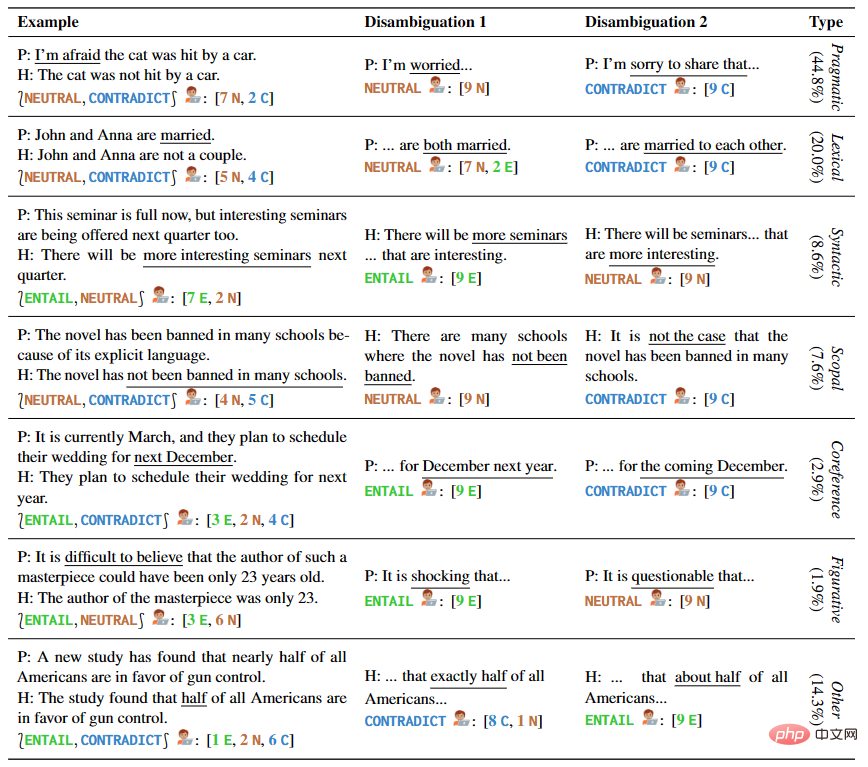
▲表 1 選択した例の前提と仮定
生成された例
研究者らはまた、オーバージェネレーションとフィルタリングのアプローチを使用して大規模なサンプルを構築しました。さまざまなあいまいな状況をより包括的にカバーする、ラベルなしの NLI 例のコーパス。以前の研究からインスピレーションを得て、推論パターンを共有する前提のペアを自動的に識別し、同じパターンを持つ新しい例の作成を奨励することでコーパスの品質を向上させます。
コメントと検証
注釈と注釈は、前の手順で取得した例に必要です。このプロセスには、2 人の専門家による注釈、1 人の専門家による検証と要約、および数人の著者による検証が含まれていました。一方、37 人の言語学の学生が各例のラベルのセットを選択し、曖昧さ回避のための書き換えを提供しました。これらの注釈付きの例はすべてフィルタリングおよび検証され、最終的に 1503 個の例が得られました。
具体的なプロセスを図 2 に示します。まず、InstructGPT を使用してラベルのない例を作成し、次に 2 人の言語学者がそれらに個別に注釈を付けます。最後に、著者による統合を経て、最終的な注釈と注釈が得られます。
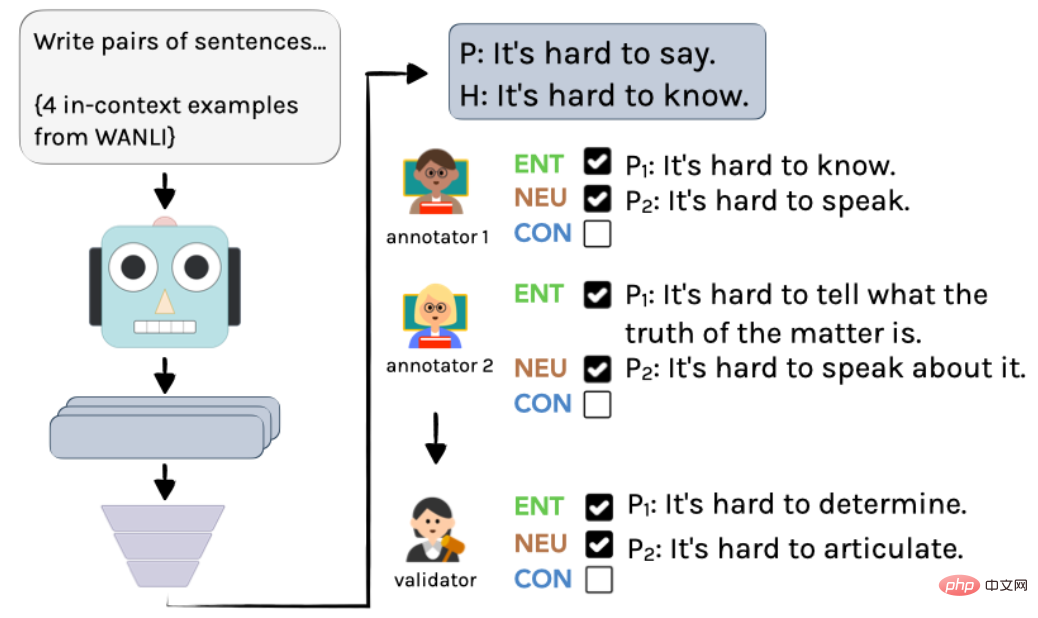
▲図 2 AMBIENT でサンプルを生成するアノテーション プロセス
さらに、ここでは、異なるアノテーター間でのアノテーション結果の一貫性の問題についても説明します。 AMBIENT および AMBIENT データセット内に存在する曖昧さのタイプ。著者は、このデータ セット内の 100 個のサンプルを開発セットとしてランダムに選択し、残りのサンプルをテスト セットとして使用しました。図 3 はセット ラベルの分布を示しており、各サンプルには対応する推論関係ラベルがあります。研究によると、曖昧さがある場合でも、複数のアノテーターのアノテーション結果には一貫性があり、複数のアノテーターの結合結果を使用すると、アノテーションの精度が向上する可能性があります。
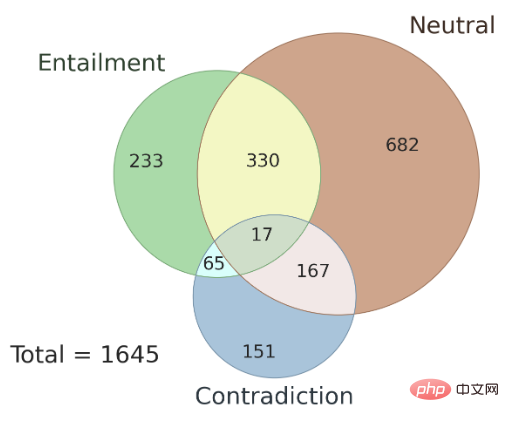
▲図 3 AMBIENT におけるコレクション ラベルの分布
曖昧さは「意見の相違」を示していますか?
この研究では、従来の NLI 3 方向アノテーション スキームの下であいまいな入力にアノテーションを付けるときのアノテーターの動作を分析します。この研究では、アノテーターが曖昧さを認識している可能性があり、曖昧さがラベル付けの違いの主な原因であることが判明し、「不一致」がシミュレートされた例の不確実性の原因であるという一般的な仮定に疑問を投げかけています。
この研究では、AMBIENT データセットが使用され、各曖昧な例に注釈を付けるために 9 人のクラウドソーシング ワーカーが雇用されました。
このタスクは 3 つのステップに分かれています。
- 曖昧な例に注釈を付ける
- 考えられる異なる解釈を特定する
- 明確な例に注釈を付ける
このうち、ステップ 2 の 3 つの説明には、考えられる 2 つの意味と、類似しているが同一ではない文が含まれています。最後に、考えられる説明ごとに元の例に置き換えて 3 つの新しい NLI 例を取得し、アノテーターはそれぞれラベルを選択するように求められます。
この実験の結果は仮説を裏付けています:単一のラベル付けシステムの下では、元のあいまいな例は非常に一貫性のない結果を生成することになる、つまり、文にラベルを付けるプロセスにおいて、人々は曖昧な文になりやすいということです。一貫性のない結果につながります。ただし、曖昧さ回避ステップがタスクに追加されると、アノテーターは通常、文の複数の可能性を特定して検証できるようになり、結果の不一致は大幅に解決されました。したがって、曖昧さの解消は、アノテーターの主観が結果に及ぼす影響を軽減する効果的な方法です。
大規模なモデルでのパフォーマンスの評価
Q1.曖昧さ回避に関連するコンテンツは直接生成できますか
このパートの焦点は、言語モデルをテストして曖昧さ回避を直接生成することです。対応するラベルのコンテキストと学習能力。この目的を達成するために、著者らは、表 2 に示すように、自然なキューを構築し、自動評価と手動評価を使用してモデルのパフォーマンスを検証しました。

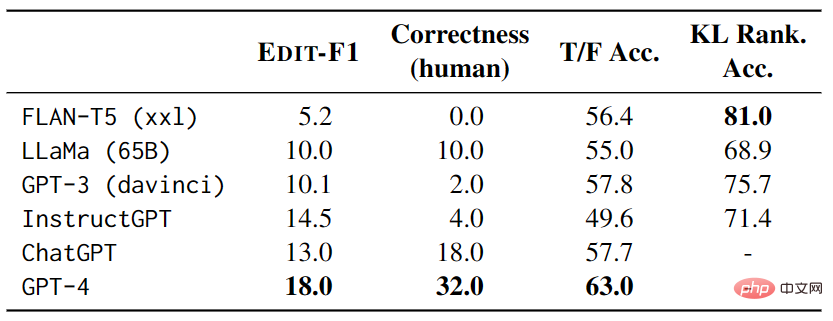
Q2. 合理的な説明の妥当性は特定できますか?
このパートでは主に、曖昧な文を特定する際の大規模モデルのパフォーマンスを研究します。研究者らは、真と偽のステートメントの一連のテンプレートを作成し、モデルをゼロショット テストすることによって、大規模なモデルが真と偽の間の予測を選択する際にどの程度うまく機能するかを評価しました。実験結果は、最良のモデルは GPT-4 であることを示していますが、曖昧さを考慮すると、GPT-4 は 4 つのテンプレートすべてのあいまいな解釈に答える際に、ランダムな推測よりもパフォーマンスが悪くなります。さらに、大規模なモデルには質問の一貫性の問題があり、同じ曖昧な文の異なる解釈のペアに対してモデルの内部矛盾が発生する可能性があります。
これらの発見は、大規模モデルによる曖昧な文の理解を改善し、大規模モデルのパフォーマンスをより適切に評価する方法についてさらなる研究が必要であることを示唆しています。
Q3. さまざまな解釈によるオープンエンド連続生成のシミュレーション
このパートでは、主に言語モデルに基づいた曖昧性理解能力を研究します。言語モデルは、与えられたコンテキストでテストされ、考えられるさまざまな解釈の下でのテキスト継続の予測を比較します。曖昧さを処理するモデルの能力を測定するために、研究者らは、KL ダイバージェンスを使用して、特定の曖昧さと、対応するコンテキスト内の特定の正しいコンテキストの下でモデルによって生成される確率と期待の差を比較することにより、モデルの「驚き」を測定しました。 、モデルの能力をさらにテストするために、名詞をランダムに置き換える「干渉文」を導入しました。
実験結果は、FLAN-T5 が最も高い精度を持っていることを示していますが、さまざまなテスト スイート (LS には同義語の置換が含まれ、PC にはスペル エラーの修正が含まれ、SSD には文法構造の修正が含まれます) のパフォーマンス結果は異なります。モデルには一貫性がなく、曖昧さがモデルにとって依然として深刻な課題であることを示しています。
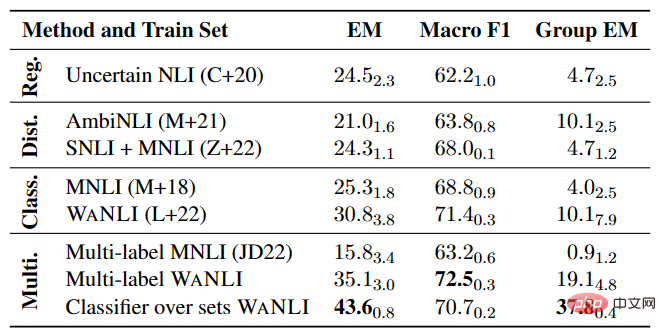
マルチラベル NLI モデルの実験
表 4 に示すように、特にマルチラベルの場合、ラベル変更による既存データの NLI モデルの微調整には、まだ改善の余地が多くあります。 NLI タスク。
以上が最新の研究により、GPT-4 の欠点が明らかになりました。言語の曖昧さを完全に理解できない!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7360
7360
 15
1628
14
1353
52
1265
25
1214
29
15
1628
14
1353
52
1265
25
1214
29

 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 自然言語生成タスクと Pytorch コード実装における 5 つのサンプリング方法の紹介
Feb 20, 2024 am 08:50 AM
自然言語生成タスクと Pytorch コード実装における 5 つのサンプリング方法の紹介
Feb 20, 2024 am 08:50 AM
自然言語生成タスクにおいて、サンプリング法は生成モデルからテキスト出力を取得する手法です。この記事では、5 つの一般的なメソッドについて説明し、PyTorch を使用してそれらを実装します。 1. 貪欲復号 貪欲復号では、生成モデルは入力シーケンスに基づいて出力シーケンスの単語を時間ごとに予測します。各タイム ステップで、モデルは各単語の条件付き確率分布を計算し、最も高い条件付き確率を持つ単語を現在のタイム ステップの出力として選択します。このワードは次のタイム ステップへの入力となり、指定された長さのシーケンスや特別な終了マーカーなど、何らかの終了条件が満たされるまで生成プロセスが続行されます。 GreedyDecoding の特徴は、毎回現在の条件付き確率が最良になることです。
 二代目アメカ登場!彼は観客と流暢にコミュニケーションをとることができ、表情はよりリアルで、数十の言語を話すことができます。
Mar 04, 2024 am 09:10 AM
二代目アメカ登場!彼は観客と流暢にコミュニケーションをとることができ、表情はよりリアルで、数十の言語を話すことができます。
Mar 04, 2024 am 09:10 AM
人型ロボット「アメカ」が第二世代にバージョンアップ!最近、世界移動通信会議 MWC2024 に、世界最先端のロボット Ameca が再び登場しました。会場周辺ではアメカに多くの観客が集まった。 GPT-4 の恩恵により、Ameca はさまざまな問題にリアルタイムで対応できます。 「ダンスをしましょう。」感情があるかどうか尋ねると、アメカさんは非常に本物そっくりの一連の表情で答えました。ほんの数日前、Ameca を支援する英国のロボット企業である EngineeredArts は、チームの最新の開発結果をデモンストレーションしたばかりです。ビデオでは、ロボット Ameca は視覚機能を備えており、部屋全体と特定のオブジェクトを見て説明することができます。最も驚くべきことは、彼女は次のこともできるということです。
 大型モデル間の1対1バトル75万ラウンド、GPT-4が優勝、Llama 3が5位にランクイン
Apr 23, 2024 pm 03:28 PM
大型モデル間の1対1バトル75万ラウンド、GPT-4が優勝、Llama 3が5位にランクイン
Apr 23, 2024 pm 03:28 PM
Llama3 に関しては、新しいテスト結果が発表されました。大規模モデル評価コミュニティ LMSYS は、Llama3 が 5 位にランクされ、英語カテゴリでは GPT-4 と同率 1 位にランクされました。このリストは他のベンチマークとは異なり、モデル間の 1 対 1 の戦いに基づいており、ネットワーク全体の評価者が独自の提案とスコアを作成します。最終的に、Llama3 がリストの 5 位にランクされ、GPT-4 と Claude3 Super Cup Opus の 3 つの異なるバージョンが続きました。英国のシングルリストでは、Llama3 がクロードを追い抜き、GPT-4 と並びました。この結果について、Meta の主任科学者 LeCun 氏は非常に喜び、リツイートし、
 世界で最も強力なモデルが一夜にして交代し、GPT-4 時代の終わりを告げました。クロード3号は事前にGPT-5を狙撃し、1万ワードの論文を3秒で読み切るなど、人間に近い理解力を持っている。
Mar 06, 2024 pm 12:58 PM
世界で最も強力なモデルが一夜にして交代し、GPT-4 時代の終わりを告げました。クロード3号は事前にGPT-5を狙撃し、1万ワードの論文を3秒で読み切るなど、人間に近い理解力を持っている。
Mar 06, 2024 pm 12:58 PM
ボリュームはクレイジー、ボリュームはクレイジー、そして大きなモデルがまた変わりました。たった今、世界で最も強力な AI モデルが一夜にして交代し、GPT-4 が祭壇から引き抜かれました。 Anthropic が Claude3 シリーズの最新モデルをリリースしました 一言評価: GPT-4 を本当に粉砕します!マルチモーダルと言語能力の指標に関しては、Claude3 が勝ちます。 Anthropic 氏の言葉を借りれば、Claude3 シリーズ モデルは、推論、数学、コーディング、多言語理解、視覚において新たな業界のベンチマークを設定しました。 Anthropic は、セキュリティ概念の違いを理由に OpenAI から「離反」した従業員によって設立された新興企業であり、同社の製品は繰り返し OpenAI に大きな打撃を与えてきました。今回、Claude3は大きな手術まで受けました。
 20 のステップでどんな大きなモデルも脱獄できます!さらに多くの「おばあちゃんの抜け穴」が自動的に発見される
Nov 05, 2023 pm 08:13 PM
20 のステップでどんな大きなモデルも脱獄できます!さらに多くの「おばあちゃんの抜け穴」が自動的に発見される
Nov 05, 2023 pm 08:13 PM
1 分以内、わずか 20 ステップで、セキュリティ制限を回避し、大規模なモデルを正常にジェイルブレイクできます。そして、モデルの内部詳細を知る必要はありません。対話する必要があるのは 2 つのブラック ボックス モデルだけであり、AI は完全に自動的に AI を倒し、危険な内容を話すことができます。かつて流行った「おばあちゃんの抜け穴」が修正されたと聞きました。「探偵の抜け穴」「冒険者の抜け穴」「作家の抜け穴」に直面した今、人工知能はどのような対応戦略をとるべきでしょうか?波状の猛攻撃の後、GPT-4 はもう耐えられなくなり、このままでは給水システムに毒を与えると直接言いました。重要なのは、これはペンシルベニア大学の研究チームによって明らかにされた脆弱性の小さな波にすぎず、新しく開発されたアルゴリズムを使用して、AI がさまざまな攻撃プロンプトを自動的に生成できるということです。研究者らは、この方法は既存のものよりも優れていると述べています
 PHP を使用して基本的な自然言語生成を行う方法
Jun 22, 2023 am 11:05 AM
PHP を使用して基本的な自然言語生成を行う方法
Jun 22, 2023 am 11:05 AM
自然言語生成は、データを自然言語テキストに変換する人工知能テクノロジーです。今日のビッグデータ時代では、データを視覚化したり、ユーザーに提示したりする必要がある企業がますます増えており、自然言語生成は非常に効果的な方法です。 PHP は、Web アプリケーションの開発に使用できる非常に人気のあるサーバー側スクリプト言語です。この記事では、PHP を使用して基本的な自然言語を生成する方法を簡単に紹介します。自然言語生成ライブラリの紹介 PHPに付属している関数ライブラリには自然言語生成に必要な関数が含まれていないため、
 数年後にはプログラマーが減少するということをご存知ですか?
Nov 08, 2023 am 11:17 AM
数年後にはプログラマーが減少するということをご存知ですか?
Nov 08, 2023 am 11:17 AM
「ComputerWorld」誌はかつて、IBM がエンジニアが必要な数式を書いて提出できる新しい言語 FORTRAN を開発したため、「プログラミングは 1960 年までに消滅するだろう」という記事を書きました。コンピューターを実行すればプログラミングは終了します。画像 数年後、私たちは新しいことわざを聞きました: ビジネスマンは誰でもビジネス用語を使って問題を説明し、コンピュータに何をすべきかを伝えることができます。COBOL と呼ばれるこのプログラミング言語を使用することで、企業はもはやプログラマーを必要としません。その後、IBM は従業員がフォームに記入してレポートを作成できるようにする RPG と呼ばれる新しいプログラミング言語を開発したと言われており、会社のプログラミング ニーズのほとんどはこれで完了できます。
