

人間は、人間の生活や仕事の処理を支援できるロボットを常に夢見てきました。 「エアコンの温度を下げるのを手伝ってください」や「ショッピング モールの Web サイトの作成を手伝ってください」さえも、近年では OpenAI がリリースしたホーム アシスタントや Copilot によって実現されています。
GPT-4 の出現は、視覚的な理解におけるマルチモーダル大規模モデルの可能性をさらに示しています。オープンソースの中小規模のモデルでは、LLAVA や minigpt-4 がよく機能しており、写真を見てチャットしたり、人間の食べ物の写真からレシピを推測したりすることもできます。ただし、これらのモデルは、実際の実装においては依然として重要な課題に直面しています: 正確な位置決め機能がなく、画像内のオブジェクトの特定の位置を与えることができず、特定のオブジェクトを検出するための人間の複雑な指示を理解できないため、多くの場合、モデルは、特定のオブジェクトを検出できない人間のタスクや特定のタスクを実行します。実際のシナリオでは、人々は複雑な問題に遭遇することがありますが、写真を撮ってスマートアシスタントに正しい答えを尋ねることができれば、このような「写真を撮って尋ねる」機能は単純に素晴らしいです。
「写真を撮って質問する」という機能を実現するには、ロボットには複数の能力が必要です:
1. 言語理解能力: 聞くことができる 人間の意図を理解して理解することができる
#2. 視覚理解能力: 目に映る絵の中の物体を理解することができる
#3 . 常識的推論能力 : 複雑な人間の意図を、位置を特定できる正確なターゲットに変換する能力
#4. オブジェクト位置特定能力 : 画面上で対応するオブジェクトを位置特定し、検出する能力
現在、これらの 4 つの機能を備えているのは、少数の大規模モデル (Google の PaLM-E など) だけです。しかし、香港科技大学と香港大学の研究者は、完全にオープンソースのモデル DetGPT (正式名 DetectionGPT) を提案しました。このモデルでは 300 万のパラメータを微調整するだけでよく、モデルは複雑な推論とローカルな機能を簡単に持つことができます。オブジェクトの位置決め機能を備えており、大規模なほとんどのシーンに一般化できます。これは、モデルが自身の知識に基づいた推論を通じて人間の抽象的な指示を理解し、画像内の人間の興味のあるオブジェクトを簡単に識別できることを意味します。彼らはモデルを「写真と質問」のデモにしました。オンラインで体験することを歓迎します: https://detgpt.github.io/
DetGPT を使用すると、ユーザーは自然な操作ですべてを操作できます。煩雑なコマンドまたはインターフェイスが必要です。同時に、DetGPT はインテリジェントな推論機能とターゲット検出機能も備えており、ユーザーのニーズと意図を正確に理解できます。たとえば、人間が「冷たい飲み物が飲みたい」という音声コマンドを送ると、ロボットはまず現場で冷たい飲み物を探しますが、見つかりません。それで「このシーンには冷たい飲み物がないんだけど、どこで見つけたらいいんだろう?」と考え始めたんです。強力な常識推論モデルを通じて冷蔵庫を思い出したので、シーンをスキャンして冷蔵庫を見つけ、飲み物の場所をロックすることに成功しました。
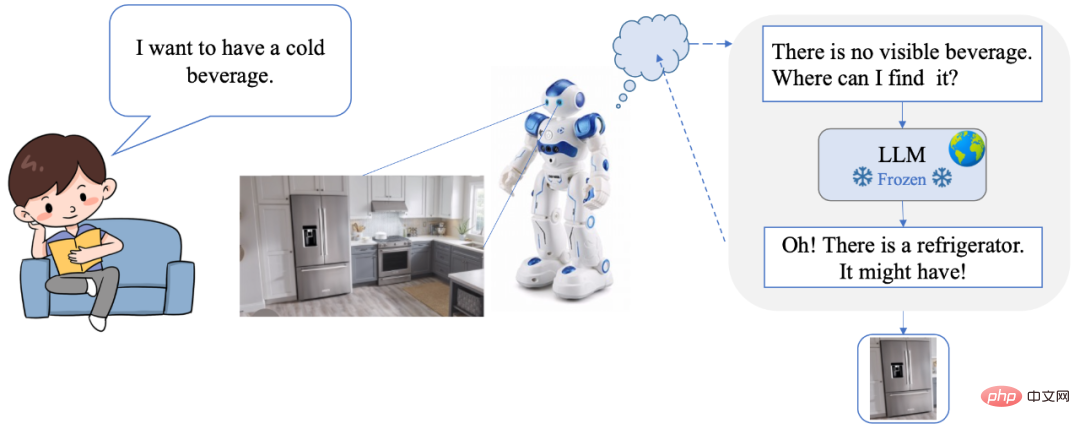
夏に喉が渇いたら、写真のアイスドリンクはどこにありますか? DetGPT わかりやすい 冷蔵庫を探す:
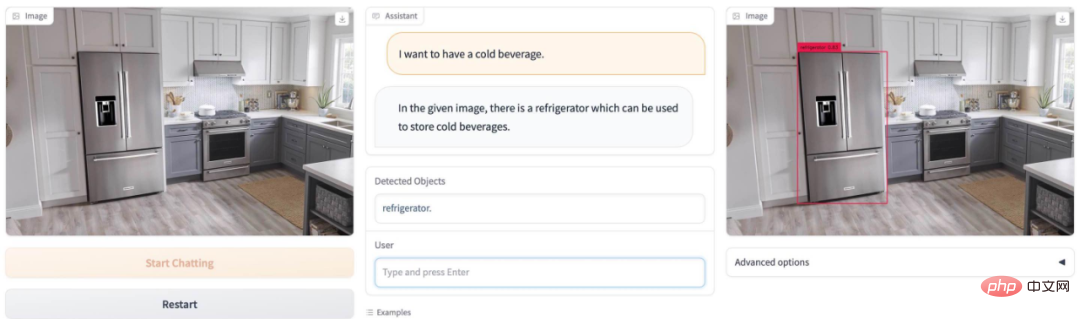
明日早起きしたいですか? DetGPT 簡単ピック電子目覚まし時計:
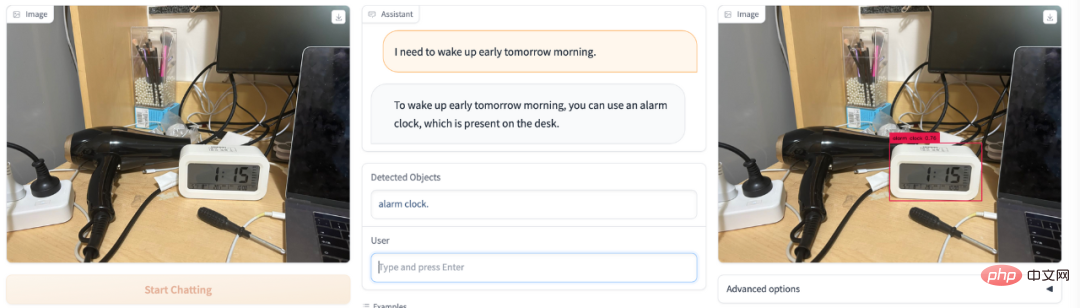
高血圧で疲れやすいですか?果物市場に行っても、どの果物を買えば高血圧を軽減できるのかわかりませんか? DetGPT は栄養の先生の役割を果たします:
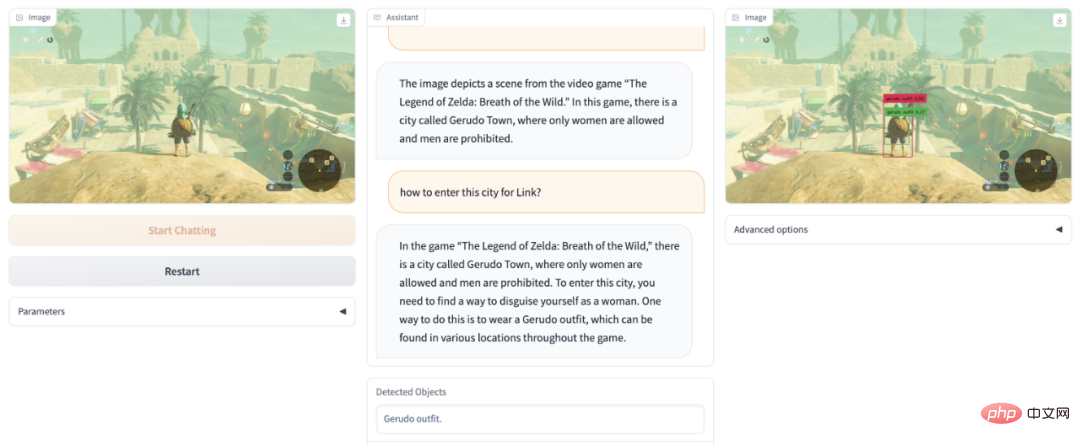
ゼルダ ゲームをクリアできないですか? DetGPT は、娘の王国レベルを偽装して合格するのに役立ちます:
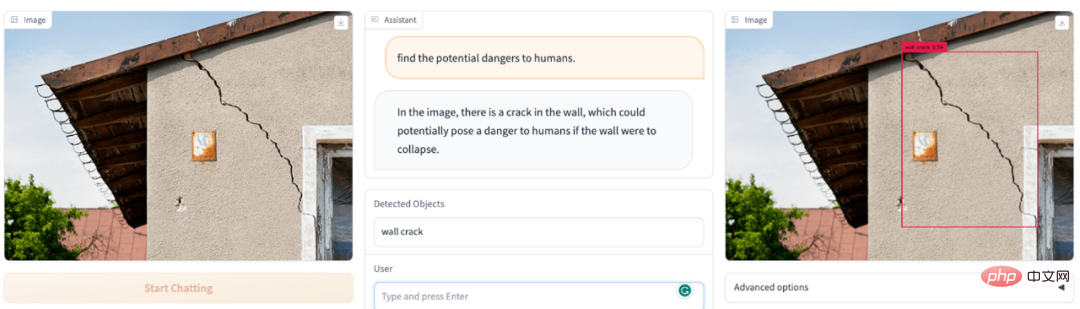
# 画像の視野内に危険なものはありますか? DetGPT があなたの安全担当者になります:
写真の中のどのアイテムが子供にとって危険ですか? DetGPT はまだ大丈夫です:
DetGPT の機能は何ですか?#注目に値する新しい方向性: 常識的な推論を使用して、より正確なオープン セット ターゲット検出を実現します

##従来の検出タスクでは、検出対象となる可能性のあるオブジェクト カテゴリを事前に設定する必要があります。しかし、検出対象のオブジェクトを正確かつ包括的に記述することは、人間にとって不親切であり、非現実的ですらあります。具体的には、(1)人間は限られた記憶・知識に制限されているため、検出したい対象物を常に正確に表現できるわけではありません。たとえば、医師は高血圧の人にカリウムを補うためにより多くの果物を食べることを推奨しますが、どの果物にカリウムが豊富に含まれているかがわからないため、モデルが検出する特定の果物の名前を指定することはできず、検出モデルには「果物の識別」がスローされます。人間は写真を撮るだけで、モデル自体が考え、推論し、カリウムが豊富な果物を検出します。この問題ははるかに単純です。 (2) 人間が例示できる対象カテゴリーは包括的ではありません。例えば、公共の場での公序良俗に反する行為を監視する場合、人間はナイフの所持や喫煙などのシナリオをいくつか挙げるだけで済むかもしれませんが、「公序良俗に反する行為を検知する」という問題を直接渡してしまうと、モデルが独自に考え、自身の知識に基づいて推論を行う場合、より多くの悪質な行為を捕捉し、検出する必要があるより多くの関連カテゴリに一般化することができます。結局のところ、普通の人間が理解できる知識には限界があり、引用できる物の種類も限られていますが、ChatGPTのような補助や推論を行う脳があれば、人間が与えるべき指示はずっとシンプルになるでしょうし、得られる答えは、より正確で包括的なものになることもあります。
人間による指示の抽象化と限界に基づいて、香港科技大学と香港大学の研究者は、「推論的ターゲット検出」という新しい方向性を提案しました。簡単に言うと、人間がいくつかの抽象的なタスクを与えると、モデルは画像内のどのオブジェクトがこのタスクを完了する可能性があるかを自ら理解して推論し、検出することができます。簡単な例を挙げると、人間が「冷たい飲み物が欲しいのですが、どこにありますか?」と話すと、モデルはキッチンの写真を見て「冷蔵庫」を検出できます。このトピックでは、マルチモーダル モデルの画像理解機能と大規模な言語モデルに保存されている豊富な知識を完璧に組み合わせて、それらをきめ細かい検出タスク シナリオで使用する必要があります。つまり、言語モデルの頭脳を使用して人間の抽象的な命令を理解し、正確に理解する必要があります。事前に設定されたオブジェクト カテゴリを持たない、人間が興味のあるオブジェクトの写真を検索します。
「推論的ターゲット検出」は、難しい問題です。検出器は、ユーザーの粗粒/抽象的な指示を理解し、推論する必要があるだけでなく、ターゲットのターゲットを分析する必要があるためです。視覚的な情報を参照して、ターゲットオブジェクトを見つけます。この方向に向けて、HKUST と HKU の研究者はいくつかの予備調査を実施しました。具体的には、事前にトレーニングされたビジュアル エンコーダ (BLIP-2) を利用して画像の視覚的特徴を取得し、位置合わせ機能を通じて視覚的特徴をテキスト空間に位置合わせします。大規模な言語モデル (Robin/Vicuna) を使用してユーザーの質問を理解し、表示された視覚情報を組み合わせて、ユーザーが本当に関心のあるオブジェクトについて推論します。次に、オブジェクト名は、特定の場所を予測するために事前トレーニングされた検出器 (Grouding-DINO) に供給されます。このようにして、モデルはユーザーの指示に従って画像を分析し、ユーザーの関心のあるオブジェクトの位置を正確に予測できます。
ここでの難しさは主に、さまざまな特定のタスクに対して、モデルがモデルの元の機能をそれほど損なうことなくタスク固有の出力を達成できなければならないことにあることに注意する価値があります。できるだけ。 。言語モデルが特定のパターンに従い、推論を実行し、画像とユーザーの指示を理解するという前提の下でターゲット検出形式に準拠した出力を生成するように導くために、研究チームは ChatGPT を使用してクロスモーダルな指示データを生成し、モデルを調整します。具体的には、5,000 枚の coco 画像に基づいて、ChatGPT を利用して 30,000 個のクロスモーダル画像テキスト微調整データセットを作成しました。トレーニングの効率を向上させるために、他のモデル パラメーターを固定し、クロスモーダル線形マッピングのみを学習しました。実験結果は、線形層のみが微調整された場合でも、言語モデルが詳細な画像の特徴を理解し、特定のパターンに従って推論ベースの画像検出タスクを実行でき、優れたパフォーマンスを示すことを証明しています。
この研究テーマには大きな可能性があります。このテクノロジーに基づいて、家庭用ロボットの分野はさらに輝かしくなります。在宅の人々は、抽象的または粗粒度の音声指示を使用して、ロボットに必要なアイテムを理解、識別、位置特定させ、関連サービスを提供させることができます。産業用ロボットの分野では、このテクノロジーは無限の活力を放つでしょう。産業用ロボットは、人間の作業者とより自然に連携し、その指示とニーズを正確に理解し、インテリジェントな意思決定と操作を実現できます。生産ラインでは、人間の作業者が粗粒度の音声指示やテキスト入力を使用して、ロボットに処理が必要なアイテムを自動的に理解、識別、位置特定させることができるため、生産効率と品質が向上します。
独自の推論機能を備えたターゲット検出モデルに基づいて、よりインテリジェントで自然かつ効率的なロボットを開発し、より便利で効率的かつ人道的なサービスを人間に提供できます。これは広い展望を持つ分野です。また、より多くの研究者が注目し、さらなる調査が行われる価値があります。
DetGPT は複数の言語モデルをサポートしており、Robin-13B と Vicuna-13B の 2 つの言語モデルに基づいて検証されていることは言及する価値があります。 Robin シリーズの言語モデルは、香港科技大学の LMFlow チーム (https://github.com/OptimalScale/LMFlow) によってトレーニングされた対話モデルであり、複数の言語能力評価ベンチマークにおいて Vicuna と同等の結果を達成しています。 (モデルのダウンロード: https://github.com/OptimalScale/LMFlow#model-zoo)。 Heart of the Machine は以前、LMFlow チームがコンシューマ グラフィック カード 3090 上で専用の ChatGPT をわずか 5 時間でトレーニングできると報告しました。今日、このチームと HKU NLP Laboratory は、マルチモーダルな驚きを私たちにもたらしてくれました。
以上がDetGPT は、画像の読み取り、チャット、クロスモーダル推論と測位の実行が可能で、複雑なシナリオを実装するためにここにあります。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



