

springboot+mybatis を使用して大量のデータをすばやく挿入する方法

1. JDBC 実装計画
for ループを使用してデータを 1 つずつ挿入し、この挿入と同様の挿入 SQL を生成します。 user(name,pwd) value('aa','123 ' ),('cc','123')...
最初の解決策は、for ステートメントを使用してループに挿入することです:
この解決策の利点は次のとおりです。 JDBC PreparedStatement にはプリコンパイル機能があり、プリコンパイル後にキャッシュされます。その後、SQL の実行が高速になり、JDBC によるバッチ処理が可能になり、このバッチ処理の実行は非常に強力です。
欠点は、多くの場合、SQL サーバーとアプリケーション サーバーが同じではないため、ネットワーク IO を考慮する必要があることです。ネットワーク IO に時間がかかると、SQL の実行が遅くなる可能性があります。
2 番目のオプションは、挿入用の SQL を生成することです。
このオプションの利点は、ネットワーク IO が 1 つだけであることです。シャーディングでもネットワーク IO は数回しかないため、このソリューションではネットワーク IO にそれほど多くの時間を費やすことはありません。
もちろん、この解決策には欠点もあります。まず、SQL が長すぎるため、シャーディング後にバッチ処理が必要になる場合があります。第 2 に、PreparedStatement の事前コンパイルの利点を十分に活用できず、SQL を再解析する必要があり、再利用できません。第 3 に、最終的に生成される SQLは長すぎるため、データベース管理者がそれを解析する必要があり、このような長い SQL も時間がかかります。
次に 2 番目のソリューションを使用して実装します。
2. 具体的な実装アイデア
挿入効率を高めたい場合は、1 つずつ挿入することはできません。foreach バッチ挿入を使用する必要があります。
パフォーマンスを向上させるために、非同期挿入にマルチスレッドを使用します。
一度に複数の挿入を送信することは不可能です。多数の挿入操作は非常に時間がかかり、短時間では完了できません。これを達成するには、タイミング タスクを使用できます。
次に、コードを使用して実装する方法について説明します。
3. コードの実装
このケースは主に、mybatis を統合した SpringBoot に基づいて実装されています。
1. 依存関係のインポート
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.4.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.48</version>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
</dependencies>2. スタートアップ クラスの作成
@SpringBootApplication //引导类核心注解
@EnableScheduling //开启定时任务
public class BatchApplication {
public static void main(String[] args) {
SpringApplication.run(BatchApplication.class,args);
}
}3. 設定ファイル application.yml
server:
port: 9999 # 指定端口号
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/springboot?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=UTC
username: root
password: 123
mybatis:
mapper-locations: classpath:mybatis/*.xml #指定mapper映射文件路径
type-aliases-package: com.qfedu.model # 别名4. テーブル クラスとエンティティ クラスの作成ユーザー
テーブルの作成:
CREATE TABLE `user` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `username` VARCHAR(30) DEFAULT NULL, `pwd` VARCHAR(20) DEFAULT NULL, `sex` INT(11) DEFAULT NULL, `birthday` DATETIME DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8
注: MyISAM の効率は INNODB よりも高速になります。
User.java
@Data
public class User {
private int id;
private String username;
private String pwd;
private int sex;
private LocalDate birthday;
}5. 永続層マッパーとマッピング ファイル
UserMapper.java
@Mapper
public interface UserMapper {
void insertBatch(@Param("userList") List<User> userList);
}UserMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.qfedu.mapper.UserMapper">
<insert id="addList" parameterType="User" >
insert into user (username,pwd,sex,birthday) values
<foreach collection="list" item="item" separator=",">
(#{item.username}, #{item.pwd}, #{item.sex}, #{item.birthday})
</foreach>
</insert>
</mapper>6. スケジュールされたタスクを有効にする
SpringBoot はデフォルトでスケジュールされたタスクを統合します。使用手順は次のとおりです:
ブート時 @EnableScheduling アノテーションをクラスに追加して、スケジュールされたタスクを有効にします。
@Scheduled アノテーションをビジネス層メソッドに追加して、cron 式の定期的な実行を定義します。
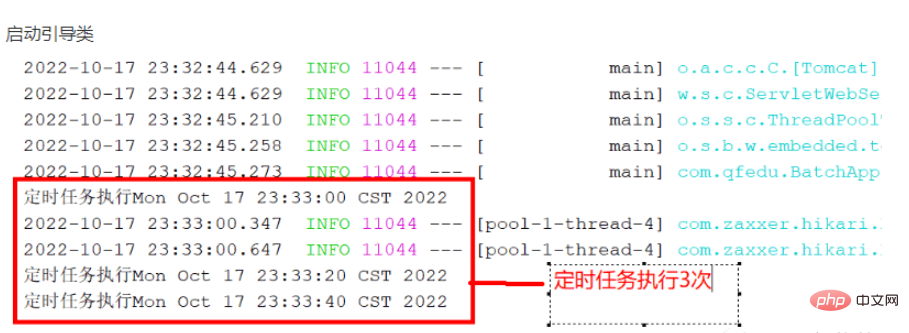
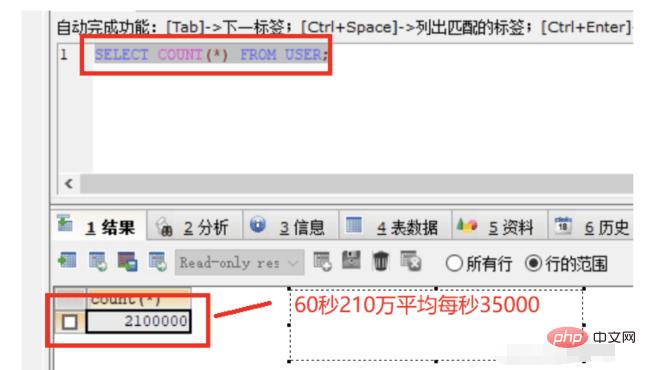
ビジネス層メソッドで開始されるスレッドは、現在のマシン構成に応じて変更できます。ここでは 7 つのスレッドを開き、各スレッドは 20 ループを実行し、一度に 5,000 個のデータを追加します。ここで、mybatis がバッチ挿入する場合、エラーが 10,000 を超えることは推奨されないことに注意してください。データ量が多すぎるため、スタックメモリのオーバーフローが発生しやすくなります。
@Component
public class UserServiceImpl {
@Autowired
private UserMapper userMapper;
@Autowired
//线程池
private ThreadPoolExecutor executor;
@Scheduled(cron = "0/20 * * * * ?") //每隔20秒执行一次
public void addList(){
System.out.println("定时器被触发");
long start = System.currentTimeMillis();
for (int i = 0; i < 7; i++) {
Thread thread = new Thread(() -> {
try {
for (int j = 0; j < 20; j++) {
userMapper.addList(UserUtil.getUsers(5000));
}
} catch (Exception e) {
e.printStackTrace();
}
});
try {
executor.execute(thread);
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
}
}7. オブジェクトの生成 util
挿入するデータの生成をシミュレーションするために使用しますが、実際の業務開発ではエクセルからデータをインポートすることができます。
public class UserUtil {
private static Random random = new Random();
public static List<User> getUsers(int num){
List<User> users = new ArrayList<>();
for (int i = 0;i<num;i++){
User user = new User();
user.setBirthday(LocalDate.now());
user.setSex(random.nextInt(2));
user.setPwd("123"+random.nextInt(100000));
user.setUsername("batch"+random.nextInt(num));
users.add(user);
}
return users;
}
}8. スレッド プールの設定
スレッド プール パラメーター:
corePoolSize コア スレッドの数、スレッド プール内で保証されるスレッドの最小数。
mainumPoolSize は、スレッドの最大数、つまりスレッド プール内で実行できるスレッドの最大数です。
keepAliveTime は、スレッドがアイドル状態になるまでの生存時間を保証します。スレッドをリサイクルするため;
unit は keepAliveTime (時間単位) と組み合わせて使用されます;
workQueue 作業キューは、タスクが実行される前にタスクを保存するために使用されます。
@Configuration
public class ThreadPoolExecutorConfig {
@Bean
public ThreadPoolExecutor threadPoolExecutor() {
//线程池中6个线程,最大8个线程,用于缓存任务的阻塞队列数5个
ThreadPoolExecutor executor = new ThreadPoolExecutor(6, 8, 5, TimeUnit.SECONDS, new ArrayBlockingQueue<>(100));
executor.allowCoreThreadTimeOut(true);//允许超时
return executor;
}
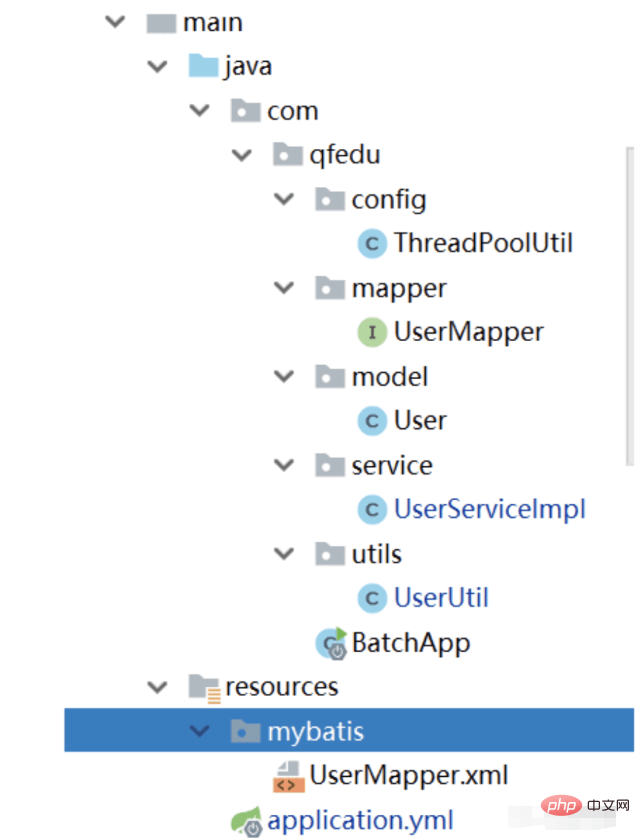
}9. 完全なプロジェクト構造
10. テスト
 ##
##
以上がspringboot+mybatis を使用して大量のデータをすばやく挿入する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7859
7859
 15
1649
14
1403
52
1300
25
1242
29
15
1649
14
1403
52
1300
25
1242
29

 iBatis と MyBatis: どちらがあなたにとって優れていますか?
Feb 19, 2024 pm 04:38 PM
iBatis と MyBatis: どちらがあなたにとって優れていますか?
Feb 19, 2024 pm 04:38 PM
iBatis と MyBatis: どちらを選択するべきですか?はじめに: Java 言語の急速な発展に伴い、多くの永続化フレームワークが登場しました。 iBatis と MyBatis は 2 つの人気のある永続化フレームワークであり、どちらもシンプルで効率的なデータ アクセス ソリューションを提供します。この記事では、iBatis と MyBatis の機能と利点を紹介し、適切なフレームワークを選択するのに役立つ具体的なコード例をいくつか示します。 iBatis の紹介: iBatis はオープンソースの永続化フレームワークです。
 JPAとMyBatisの機能・性能の比較分析
Feb 19, 2024 pm 05:43 PM
JPAとMyBatisの機能・性能の比較分析
Feb 19, 2024 pm 05:43 PM
JPA と MyBatis: 機能とパフォーマンスの比較分析 はじめに: Java 開発では、永続化フレームワークが非常に重要な役割を果たします。一般的な永続化フレームワークには、JPA (JavaPersistenceAPI) や MyBatis などがあります。この記事では、2 つのフレームワークの機能とパフォーマンスを比較分析し、具体的なコード例を示します。 1. 機能の比較: JPA: JPA は JavaEE の一部であり、オブジェクト指向のデータ永続化ソリューションを提供します。アノテーションまたはXが渡されます
 MyBatis動的SQLタグのSetタグ機能の詳細説明
Feb 26, 2024 pm 07:48 PM
MyBatis動的SQLタグのSetタグ機能の詳細説明
Feb 26, 2024 pm 07:48 PM
MyBatis 動的 SQL タグの解釈: Set タグの使用法の詳細な説明 MyBatis は、豊富な動的 SQL タグを提供し、データベース操作ステートメントを柔軟に構築できる優れた永続層フレームワークです。このうち、Set タグは、UPDATE ステートメントで SET 句を生成するために使用され、更新操作でよく使用されます。この記事では、MyBatis での Set タグの使用法を詳細に説明し、特定のコード例を通じてその機能を示します。 SetタグとはMyBatiで使用するSetタグです。
 MyBatis でバッチ削除操作を実装するさまざまな方法
Feb 19, 2024 pm 07:31 PM
MyBatis でバッチ削除操作を実装するさまざまな方法
Feb 19, 2024 pm 07:31 PM
MyBatis でバッチ削除ステートメントを実装するいくつかの方法には、特定のコード例が必要です。近年、データ量の増加により、バッチ操作がデータベース操作の重要な部分になっています。実際の開発では、データベース内のレコードを一括で削除する必要が生じることがよくあります。この記事では、MyBatis でバッチ削除ステートメントを実装するいくつかの方法に焦点を当て、対応するコード例を示します。 foreach タグを使用してバッチ削除を実装します。MyBatis は、セットを簡単に横断できる foreach タグを提供します。
 MyBatis バッチ削除ステートメントの使用方法の詳細な説明
Feb 20, 2024 am 08:31 AM
MyBatis バッチ削除ステートメントの使用方法の詳細な説明
Feb 20, 2024 am 08:31 AM
MyBatis バッチ削除ステートメントの使用方法の詳細な説明には、特定のコード例が必要です はじめに: MyBatis は、豊富な SQL 操作機能を提供する優れた永続層フレームワークです。実際のプロジェクト開発では、データを一括で削除する必要がある場面に遭遇することがよくあります。この記事では、MyBatis のバッチ削除ステートメントの使用方法を詳しく紹介し、具体的なコード例を添付します。使用シナリオ: データベース内の大量のデータを削除する場合、削除ステートメントを 1 つずつ実行するのは非効率です。このとき、MyBatisの一括削除機能が利用できます。
 MyBatis キャッシュ メカニズムの詳細な説明: キャッシュ ストレージの原理を 1 つの記事で理解する
Feb 23, 2024 pm 04:09 PM
MyBatis キャッシュ メカニズムの詳細な説明: キャッシュ ストレージの原理を 1 つの記事で理解する
Feb 23, 2024 pm 04:09 PM
MyBatis キャッシュ メカニズムの詳細な説明: キャッシュ ストレージの原理を理解するための 1 つの記事 はじめに MyBatis をデータベース アクセスに使用する場合、キャッシュは非常に重要なメカニズムであり、データベースへのアクセスを効果的に削減し、システム パフォーマンスを向上させることができます。この記事では、キャッシュの分類、ストレージの原則、具体的なコード例など、MyBatis のキャッシュ メカニズムを詳しく紹介します。 1. キャッシュの分類 MyBatis のキャッシュは、主に 1 次キャッシュと 2 次キャッシュの 2 種類に分かれます。 1 次キャッシュは SqlSession レベルのキャッシュです。
 MyBatis 1次キャッシュの詳細解説:データアクセス効率を高めるには?
Feb 23, 2024 pm 08:13 PM
MyBatis 1次キャッシュの詳細解説:データアクセス効率を高めるには?
Feb 23, 2024 pm 08:13 PM
MyBatis 1次キャッシュの詳細解説:データアクセス効率を高めるには?開発プロセス中、効率的なデータ アクセスは常にプログラマーの焦点の 1 つでした。 MyBatis のような永続層フレームワークの場合、キャッシュはデータ アクセス効率を向上させるための重要な方法の 1 つです。 MyBatis は、一次キャッシュと二次キャッシュという 2 つのキャッシュ メカニズムを提供しており、一次キャッシュはデフォルトで有効になっています。この記事では、MyBatis の 1 次キャッシュのメカニズムを詳細に紹介し、読者の理解を深めるために具体的なコード例を示します。
 MyBatis のバッチ挿入実装原理の深い理解
Feb 21, 2024 pm 04:42 PM
MyBatis のバッチ挿入実装原理の深い理解
Feb 21, 2024 pm 04:42 PM
MyBatis は、さまざまな Java プロジェクトで広く使用されている人気のある Java 永続層フレームワークです。その中でも、バッチ挿入は、データベース操作のパフォーマンスを効果的に向上させることができる一般的な操作です。この記事では、MyBatis でのバッチ挿入の実装原理を深く調査し、特定のコード例を使用して詳細に分析します。 MyBatis でのバッチ挿入 MyBatis では、通常、バッチ挿入操作は動的 SQL を使用して実装されます。複数の挿入値を含む S を構築することによって
