


Let's go!
機械学習のパラメータ調整プロセスを練習に使用します。方法は 3 つあります。最初のオプションは、コマンド ライン解析専用の人気のある Python モジュールである argparse を使用することです。もう 1 つは、すべてのハイパーパラメータを配置できる JSON ファイルを読み取ることです。3 番目のオプションもあまり知られていません。解決策は、YAML ファイルを使用することです。興味があるなら、始めましょう!
以下のコードでは、非常に効率的な統合 Python 開発環境である Visual Studio Code を使用します。このツールの利点は、拡張機能をインストールすることであらゆるプログラミング言語をサポートし、ターミナルを統合し、多数の Python スクリプトと Jupyter ノートブックを同時に操作できることです。
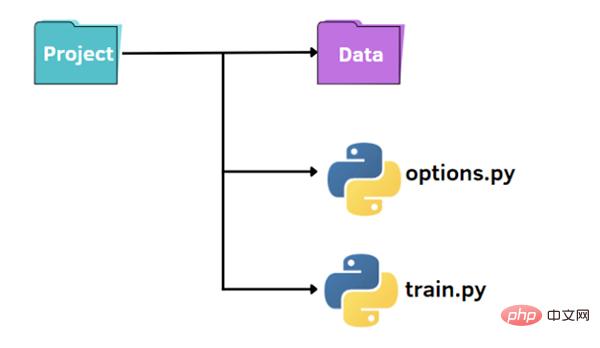 ##上の図に示すように、小さなプロジェクトを整理するための標準構造があります。
##上の図に示すように、小さなプロジェクトを整理するための標準構造があります。
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error
from options import train_options
df = pd.read_csv('datahour.csv')
print(df.head())
opt = train_options()
X=df.drop(['instant','dteday','atemp','casual','registered','cnt'],axis=1).values
y =df['cnt'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
if opt.normalize == True:
scaler = StandardScaler()
X = scaler.fit_transform(X)
rf = RandomForestRegressor(n_estimators=opt.n_estimators,max_features=opt.max_features,max_depth=opt.max_depth)
model = rf.fit(X_train,y_train)
y_pred = model.predict(X_test)
rmse = np.sqrt(mean_squared_error(y_pred, y_test))
mae = mean_absolute_error(y_pred, y_test)
print("rmse: ",rmse)
print("mae: ",mae)import argparse
def train_options():
parser = argparse.ArgumentParser()
parser.add_argument("--normalize", default=True, type=bool, help='maximum depth')
parser.add_argument("--n_estimators", default=100, type=int, help='number of estimators')
parser.add_argument("--max_features", default=6, type=int, help='maximum of features',)
parser.add_argument("--max_depth", default=5, type=int,help='maximum depth')
opt = parser.parse_args()
return optpython train.py
ハイパーパラメータのデフォルト値を変更するには、2 つの方法があります。最初のオプションは、options.py ファイルに異なるデフォルト値を設定することです。別のオプションは、コマンド ラインからハイパーパラメータ値を渡すことです。 
python train.py --n_estimators 200
python train.py --n_estimators 200 --max_depth 7
以前と同様に、同様のファイル構造を維持できます。この場合、options.py ファイルを JSON ファイルに置き換えます。つまり、JSON ファイルでハイパーパラメータの値を指定し、train.py ファイルに渡したいと考えます。 JSON ファイルは、キーと値のペアを利用してデータを保存するため、argparse ライブラリに代わる高速かつ直感的な代替手段となります。次に、後で他のコードに渡す必要があるデータを含む options.json ファイルを作成します。 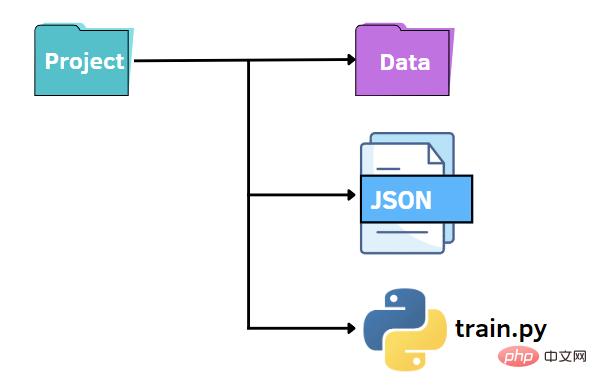
{
"normalize":true,
"n_estimators":100,
"max_features":6,
"max_depth":5
}f = open("options.json", "rb")
parameters = json.load(f)if parameters["normalize"] == True: scaler = StandardScaler() X = scaler.fit_transform(X) rf=RandomForestRegressor(n_estimators=parameters["n_estimators"],max_features=parameters["max_features"],max_depth=parameters["max_depth"],random_state=42) model = rf.fit(X_train,y_train) y_pred = model.predict(X_test)
最後のオプションは、YAML の可能性を活用することです。 JSON ファイルと同様に、YAML ファイルを Python コードで辞書として読み取り、ハイパーパラメータの値にアクセスします。 YAML は人間が判読できるデータ表現言語であり、JSON ファイルのような括弧ではなくダブルスペース文字を使用して階層が表現されます。以下に、options.yaml ファイルの内容を示します。 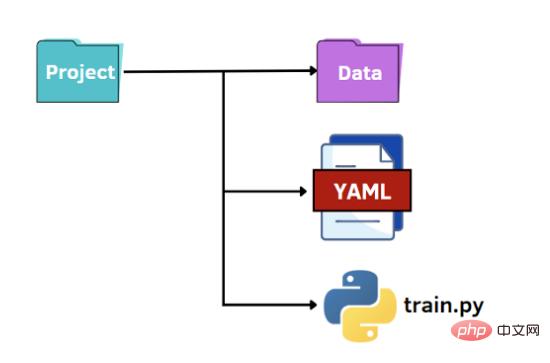
normalize: True n_estimators: 100 max_features: 6 max_depth: 5
import yaml
f = open('options.yaml','rb')
parameters = yaml.load(f, Loader=yaml.FullLoader)以上がPython でパラメータを解析する 3 つの方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



