

Python を使用して MySQL に接続する方法

1. テーブルとキーの概念
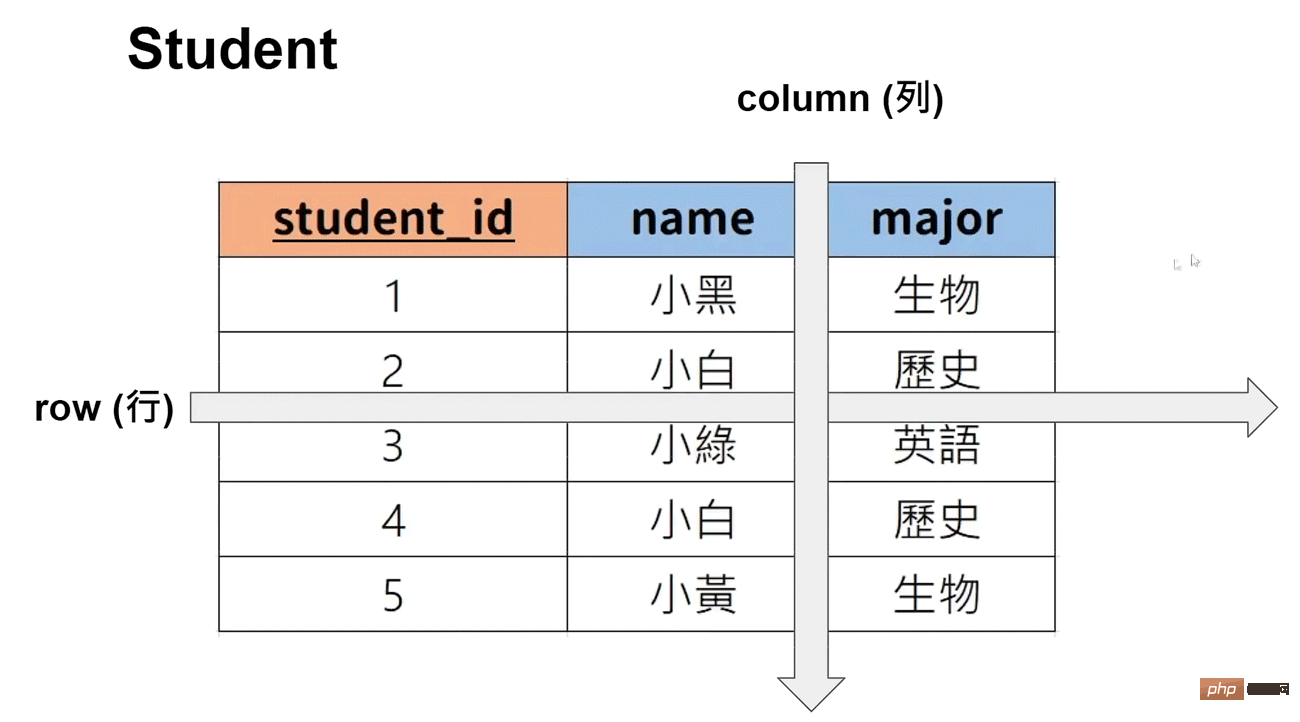
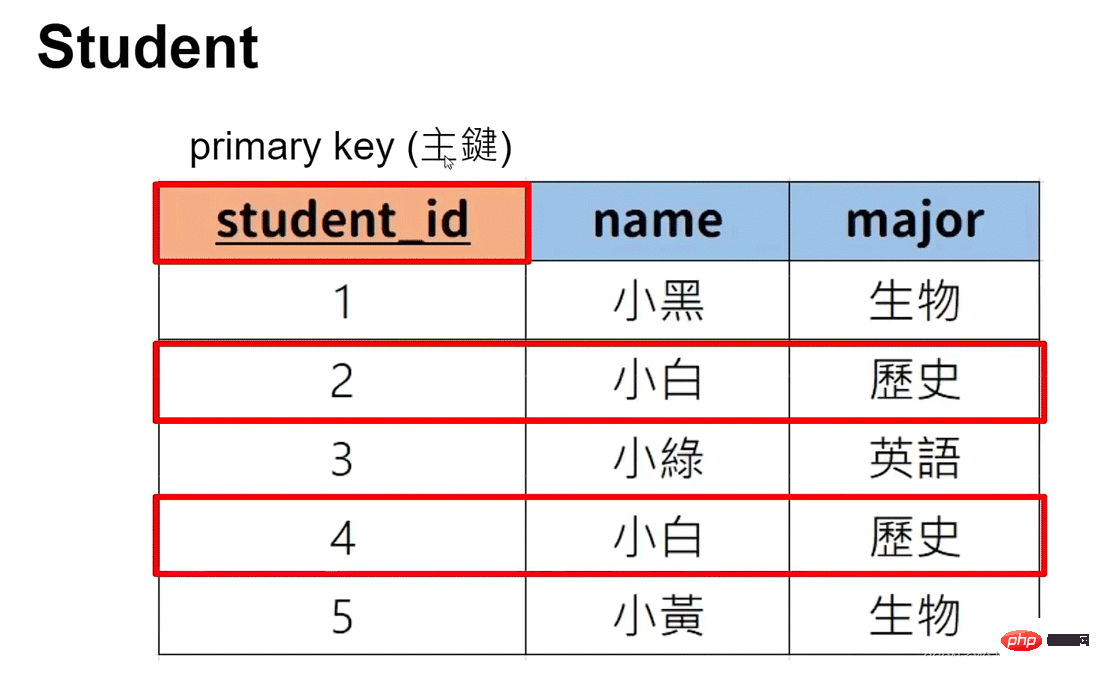
#主キー: Canデータを一意に表現します (複数のリストを主キーとして設定できます)
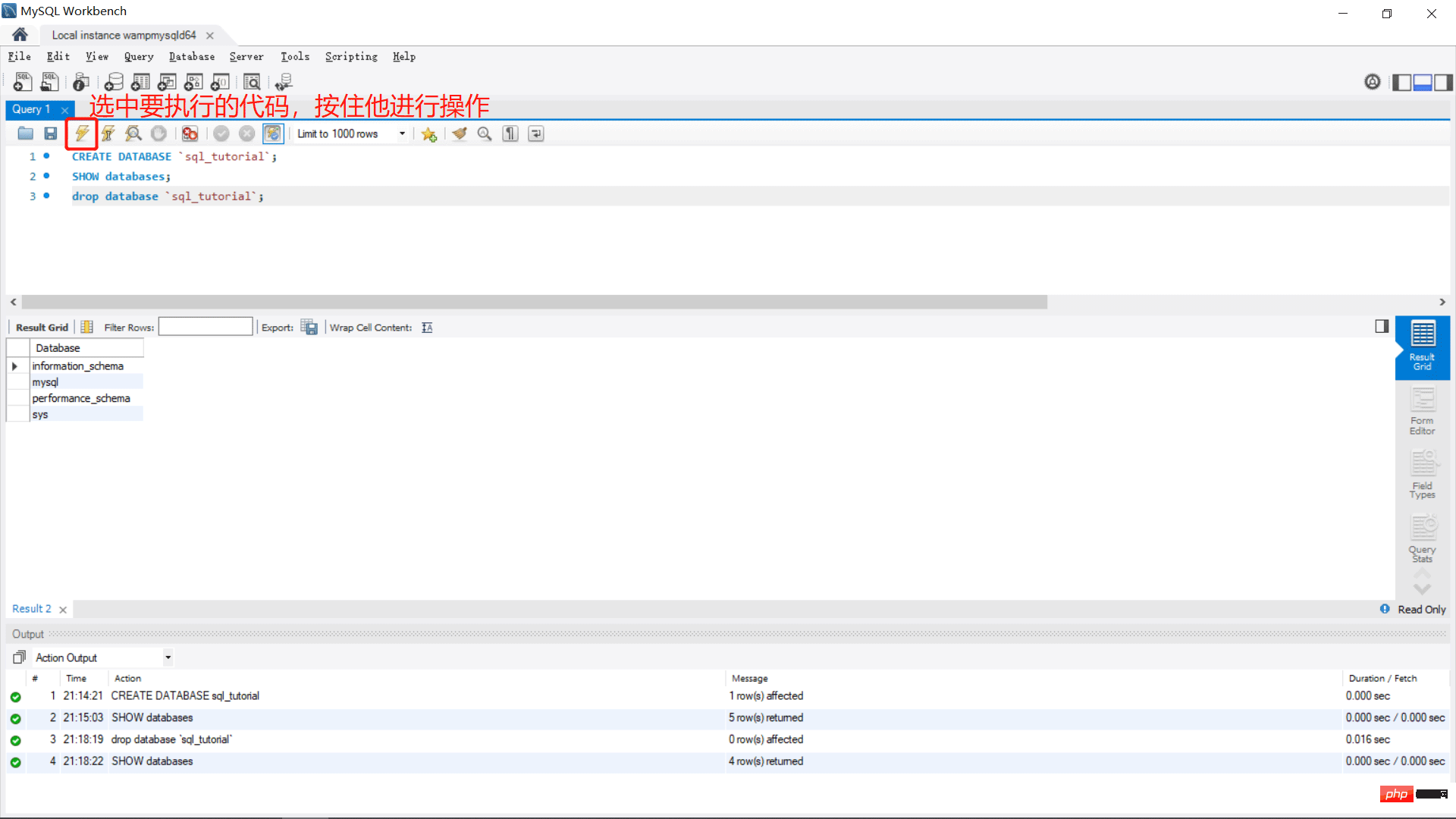
CREATE DATABASE `sql_tutorial`; --创建资料库
SHOW databases; --展示资料库
drop database `sql_tutorial`; --删除资料库
ログイン後にコピー
– コメントCREATE DATABASE `sql_tutorial`; --创建资料库 SHOW databases; --展示资料库 drop database `sql_tutorial`; --删除资料库
; 終了コマンドの形式として
MySQL データ フォーム:
- ##INT -- Integer
- DECIMAL(m,n) -- 小数点付きの数値 (3,2) は 2.33 です。合計 m 桁で、小数点は n 桁です
- VARCHAR(n ) --String
- BLOB --ピクチャービデオファイル...(バイナリデータ)
- DATE --日付 (yyyy-mm -dd)
- TIMESTAMP --記録時刻 (yyyy-mm-dd hh:mm:ss)
CREATE DATABASE `sql_tutorial`; -- 创建资料库 SHOW databases; -- 展示资料库 use `sql_tutorial`; -- 选择使用的资料库 create table student( `student_id` int primary key, -- 第一列 `name` varchar(20), -- 第二列 `major` varchar(20) -- 第三列,20指的是最大字符长度 ); -- 创建表格并设计属性 describe `student`; -- 展示表格 drop table `student`; -- 删除表格 alter table `student` add gpa decimal(3,2); -- 增加资料属性 alter table `student` drop column gpa ; -- 删除资料属性ログイン後にコピー
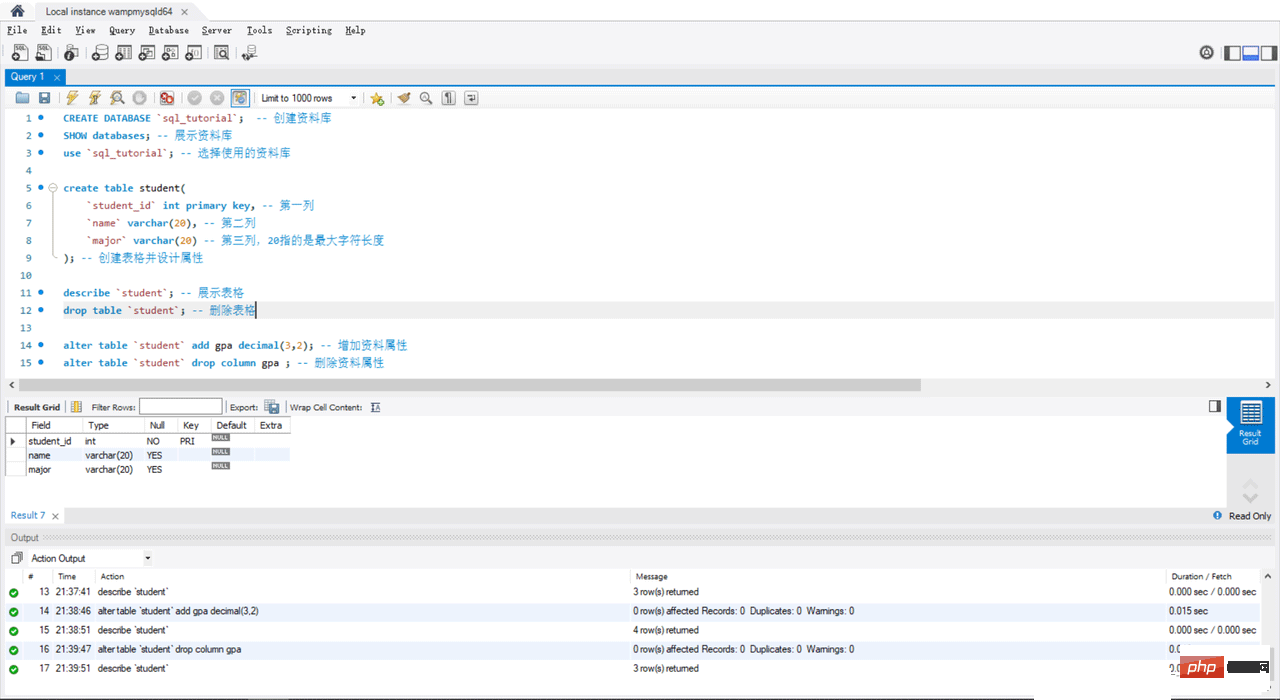 4. データの保存
4. データの保存
create table student(
`student_id` int primary key, -- 第一列
`name` varchar(20), -- 第二列
`major` varchar(20) -- 第三列,20指的是最大字符长度
); -- 创建表格并设计属性
select * from `student`; -- 搜索表格的全部资料
insert into `student` values(1,'小白','历史'); -- 写入表格数据
insert into `student` values(2,'小黑','生物'); -- 写入表格数据
insert into `student` values(3,'小绿',null); -- 写入表格数据,null为空
insert into `student`(`name`,`major`,`student_id`) values('小蓝','英语','4'); -- 按照设置写入表格数据
insert into `student`(`major`,`student_id`) values('英语','5'); -- 按照设置写入表格数据,没有的数据则为空白null##5. 制限事項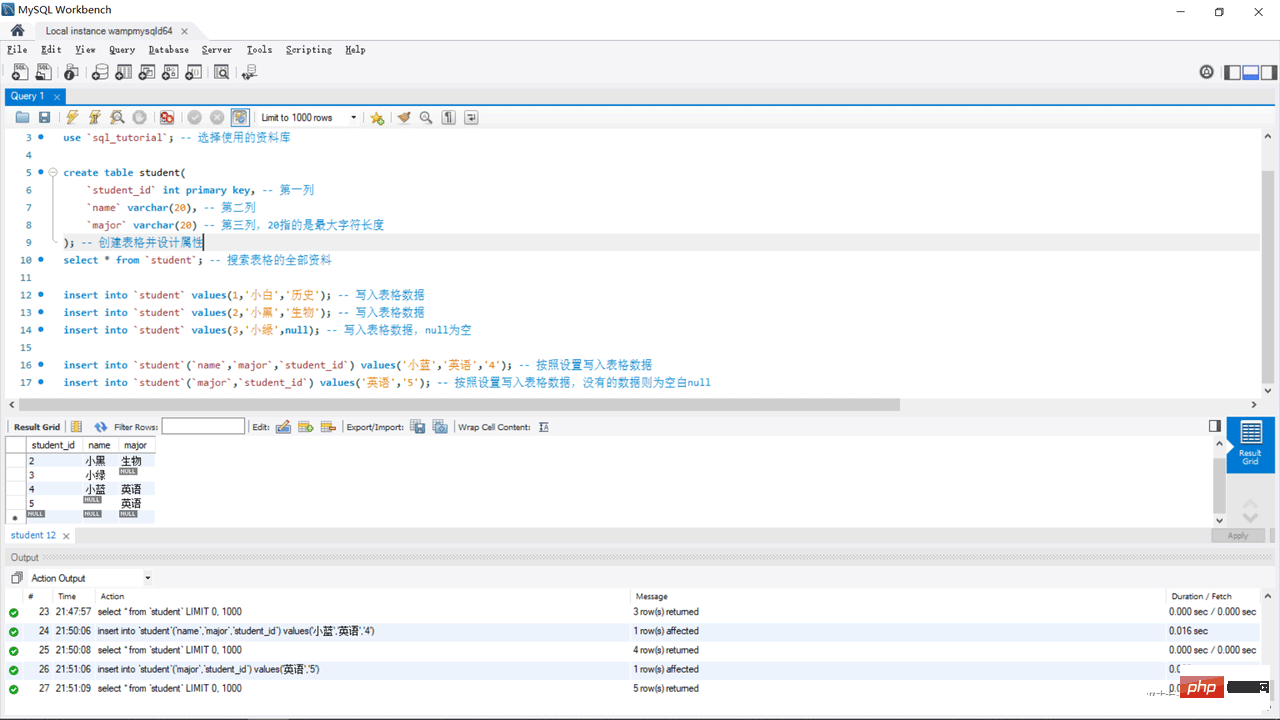
create table student(
`student_id` int primary key, -- 第一列
`name` varchar(20) not null, -- 第二列,not null指这个属性不可以为空
`major` varchar(20) unique -- 第三列,20指的是最大字符长度,unique指每个值不可以重复
); -- 创建表格并设计属性
create table student(
`student_id` int primary key auto_increment, -- 第一列,auto_increment自动会加一
`name` varchar(20), -- 第二列,not null指这个属性不可以为空
`major` varchar(20) default '历史' -- 第三列,20指的是最大字符长度,default指预设值,如果没有写该属性,则为预设值
); -- 创建表格并设计属性
drop table `student`;
select * from `student`; -- 搜索表格的全部资料
insert into `student`(`name`,`major`) values('小蓝','英语'); -- 按照设置写入表格数据
insert into `student`(`name`) values('小黑'); -- 按照设置写入表格数据6. データの変更と削除 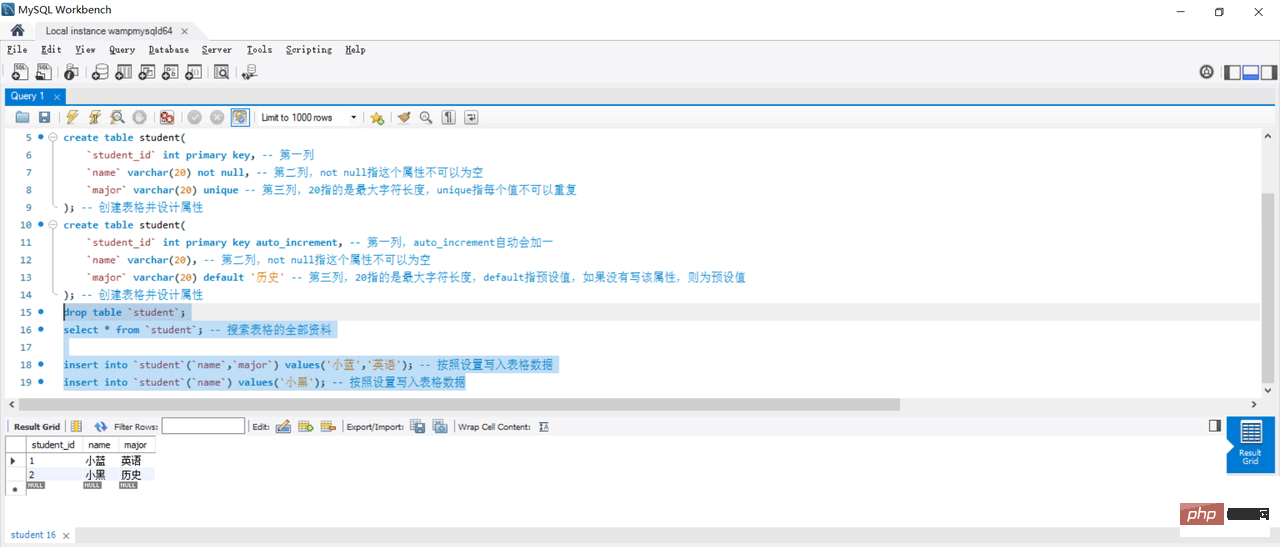
条件:
>,<,>=,<=,=,<>set sql_safe_updates = 0; -- 把预设更新模式关闭,这样更新操作才可以成功
create table student(
`student_id` int primary key auto_increment, -- 第一列
`name` varchar(20), -- 第二列
`major` varchar(20), -- 第三列,20指的是最大字符长度
`score` int
); -- 创建表格并设计属性
drop table `student`;
select * from `student`; -- 搜索表格的全部资料
insert into `student`(`name`,`major`) values('小蓝','英语'); -- 按照设置写入表格数据
insert into `student`(`name`,`major`) values('小白','化学'); -- 按照设置写入表格数据
insert into `student`(`name`,`major`) values('小黑','生物'); -- 按照设置写入表格数据
update `student` -- 更新哪个表格
set `major` = '英语文学' -- 将什么更新成什么
where `major` = '英语'; -- 将其中谁的什么进行更新
-- 还可以进行多个更新
update `student` -- 更新哪个表格
set `major` = '生化' -- 将什么更新成什么
where `major` = '生物' or `major` = '化学' ; -- 将其中谁的什么进行更新
update `student` -- 更新哪个表格
set `name` = '小辉',`major` = '生化' -- 将什么更新成什么
where `student_id`=1 ; -- 将其中谁的什么进行更新
-- 不加条件则都改
update `student` -- 更新哪个表格
set `major` = '物理'; -- 将其中谁的什么进行更新,都改成了生化
delete from `student`
where `student_id` = 3; -- 删除表格中的数据
-- 条件也可以设置多个
delete from `student`
where `name` = '小白' and `major`='物理'; -- 删除表格中的数据
delete from `student`; -- 删除所有的资料-- 取得资料 select * from `student`; -- 取得表格的全部资料 select `name` from `student`; -- 只取得表格的对应数据 select `name`, `major` from `student`; -- 取得表格的对应多个数据 select * from `student` ORDER BY `score`; -- 取得表格的全部资料,并排序(默认正序) select * from `student` ORDER BY `score` DESC; -- 取得表格的全部资料,并排序(由高到低,asc是由低到高) select * from `student` ORDER BY `score` ,`student_id`; -- 取得表格的全部资料,并排序(先有score做排序,score中相同的再由student_id做排序) select * from `student` LIMIT 3 ; -- 限制资料范围 select * from `student` ORDER BY `score` LIMIT 3 ; -- 排序并限制资料范围 select * from `student` where `major`= '英语'; -- 查找对应资料 select * from `student` where `major`= '英语' and `student_id` = 1; -- 查找对应资料(多条件) select * from `student` where `major` in('历史','英语','生物'); -- 查找对应资料(多条件)1
CREATE DATABASE `sql_tutorial`; -- 创建资料库
SHOW databases; -- 展示资料库
use `sql_tutorial`; -- 选择使用的资料库
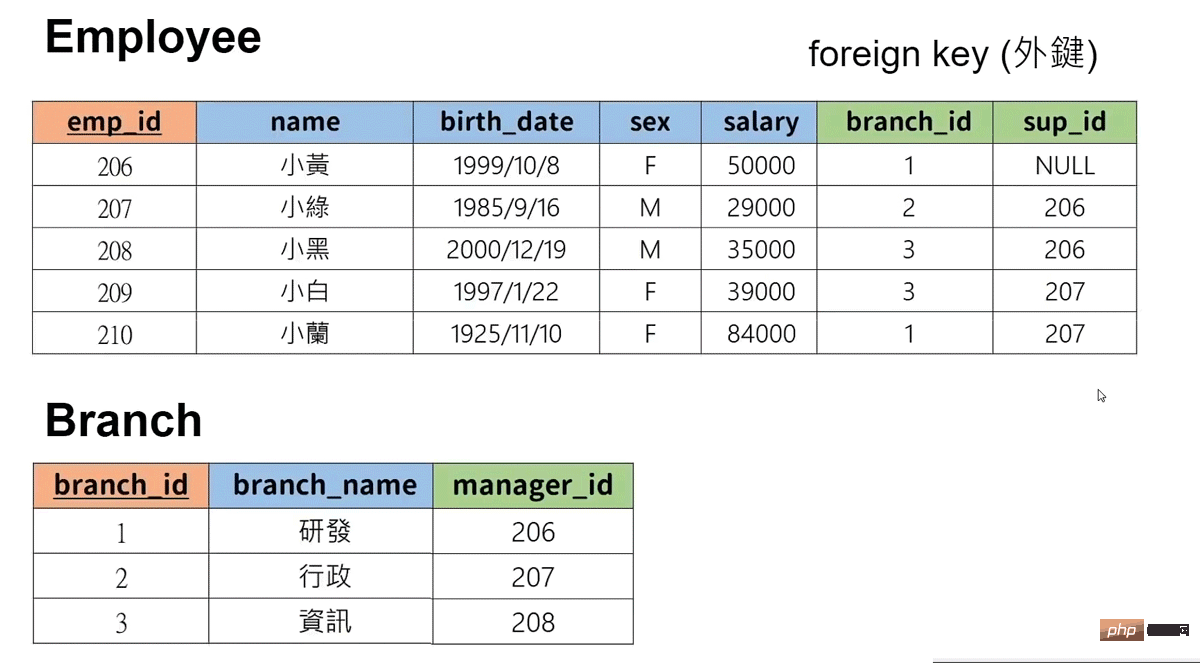
create table `employee`(
`emp_id` int primary key, -- 第一列
`name` varchar(20), -- 第二列,20指的是最大字符长度
`bath_date` date, -- 第三列
`sex` varchar(1),
`salary` int,
`branch_id` int,
`sup_id` int
); -- 创建表格并设计属性
create table `branch`(
`branch_id` int primary key , -- 第一列
`branch_name` varchar(20), -- 第二列
`manager_id` int, -- 第三列,20指的是最大字符长度
foreign key (`manager_id`) references `employee`(`emp_id`) on delete set null -- 设置好外键(选择什么是并对应什么表格的什么属性)
); -- 创建表格并设计属性
-- 补充外键(外表格对应)
alter table `employee` -- 在什么表格上进行更新
add foreign key(`branch_id`) -- 在他的什么属性上
references `branch`(`branch_id`) -- 从哪的什么属性对应
on delete set null;
-- 补充外键(内表格对应)
alter table `employee` -- 在什么表格上进行更新
add foreign key(`sup_id`) -- 在他的什么属性上
references `employee`(`emp_id`) -- 从哪的什么属性对应
on delete set null;
create table `client`(
`client_id` int primary key , -- 第一列
`client_name` varchar(20), -- 第二列
`phone` varchar(20) -- 第三列,20指的是最大字符长度
); -- 创建表格并设计属性
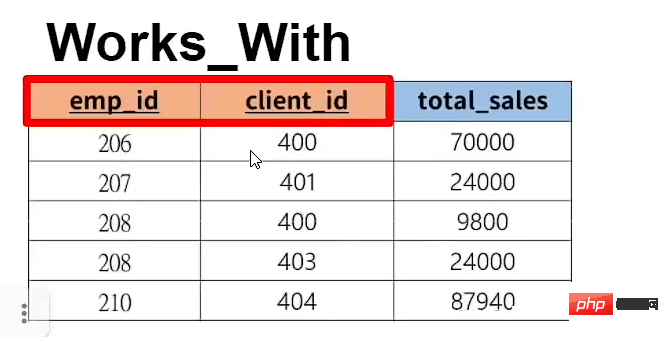
create table `works_with`(
`emp_id` int, -- 第一列
`client_id` int, -- 第二列
`total_sales` int, -- 第三列,20指的是最大字符长度
primary key(`emp_id`,`client_id`),
foreign key (`emp_id`) references `employee`(`emp_id`) on delete cascade, -- 设置好外键(选择什么是并对应什么表格的什么属性)
foreign key (`client_id`) references `client`(`client_id`) on delete cascade -- 设置好外键(选择什么是并对应什么表格的什么属性)
); -- 创建表格并设计属性
-- 当增加资料冲突的时候可以先将其设置为null然后再更新
insert into `branch` values(1,'研发',null);
insert into `employee` values(206,'xiaohuang','1998-10-08','F',50000,1,null);
update `branch`
set `manager_id` = 206
where `branch_id` = 1;ログイン後にコピー
9. 企業情報の取得CREATE DATABASE `sql_tutorial`; -- 创建资料库
SHOW databases; -- 展示资料库
use `sql_tutorial`; -- 选择使用的资料库
create table `employee`(
`emp_id` int primary key, -- 第一列
`name` varchar(20), -- 第二列,20指的是最大字符长度
`bath_date` date, -- 第三列
`sex` varchar(1),
`salary` int,
`branch_id` int,
`sup_id` int
); -- 创建表格并设计属性
create table `branch`(
`branch_id` int primary key , -- 第一列
`branch_name` varchar(20), -- 第二列
`manager_id` int, -- 第三列,20指的是最大字符长度
foreign key (`manager_id`) references `employee`(`emp_id`) on delete set null -- 设置好外键(选择什么是并对应什么表格的什么属性)
); -- 创建表格并设计属性
-- 补充外键(外表格对应)
alter table `employee` -- 在什么表格上进行更新
add foreign key(`branch_id`) -- 在他的什么属性上
references `branch`(`branch_id`) -- 从哪的什么属性对应
on delete set null;
-- 补充外键(内表格对应)
alter table `employee` -- 在什么表格上进行更新
add foreign key(`sup_id`) -- 在他的什么属性上
references `employee`(`emp_id`) -- 从哪的什么属性对应
on delete set null;
create table `client`(
`client_id` int primary key , -- 第一列
`client_name` varchar(20), -- 第二列
`phone` varchar(20) -- 第三列,20指的是最大字符长度
); -- 创建表格并设计属性
create table `works_with`(
`emp_id` int, -- 第一列
`client_id` int, -- 第二列
`total_sales` int, -- 第三列,20指的是最大字符长度
primary key(`emp_id`,`client_id`),
foreign key (`emp_id`) references `employee`(`emp_id`) on delete cascade, -- 设置好外键(选择什么是并对应什么表格的什么属性)
foreign key (`client_id`) references `client`(`client_id`) on delete cascade -- 设置好外键(选择什么是并对应什么表格的什么属性)
); -- 创建表格并设计属性
-- 当增加资料冲突的时候可以先将其设置为null然后再更新
insert into `branch` values(1,'研发',null);
insert into `employee` values(206,'xiaohuang','1998-10-08','F',50000,1,null);
update `branch`
set `manager_id` = 206
where `branch_id` = 1;-- 取得对应表格所有资料
select * from `employee`;
-- 取得对应表格所有资料并排序(默认低到高)
select * from `employee` order by `salary`; -- 低为加desc
-- 增加限制取出条件
select * from `employee` order by `salary` desc limit 3 ; -- 取出前三高
-- 取出对应属性
select `name` from `employee` ;
-- 取出对应属性的内容(且不重复)
select distinct `name` from `employee` ;
ログイン後にコピー
10. 集計関数-- 取得对应表格所有资料 select * from `employee`; -- 取得对应表格所有资料并排序(默认低到高) select * from `employee` order by `salary`; -- 低为加desc -- 增加限制取出条件 select * from `employee` order by `salary` desc limit 3 ; -- 取出前三高 -- 取出对应属性 select `name` from `employee` ; -- 取出对应属性的内容(且不重复) select distinct `name` from `employee` ;
-- 取得人数
select count(*) from `employee`; -- 统计几笔资料
select count(`sup_id`) from `employee`; -- 统计对应属性资料个数(null不计入)
-- 增加条件取数
select count(*)
from `employee`
where `bath_date` > '1970-01-01' and `sex` = 'F'; -- 统计几笔资料
-- 计算对应的属性的平均
select avg(`salary`) from `employee`;
-- 计算对应的属性的总和
select sum(`salary`) from `employee`;
-- 取得最高的
select max(`salary`) from `employee`;
-- 取得最低的
select min(`salary`) from `employee`;
ログイン後にコピー
11.ユニバーサル サブ要素 -- 取得人数 select count(*) from `employee`; -- 统计几笔资料 select count(`sup_id`) from `employee`; -- 统计对应属性资料个数(null不计入) -- 增加条件取数 select count(*) from `employee` where `bath_date` > '1970-01-01' and `sex` = 'F'; -- 统计几笔资料 -- 计算对应的属性的平均 select avg(`salary`) from `employee`; -- 计算对应的属性的总和 select sum(`salary`) from `employee`; -- 取得最高的 select max(`salary`) from `employee`; -- 取得最低的 select min(`salary`) from `employee`;
-- %表示多个子元,_表示一个子元
-- 取得尾数335的数据
select * from `client` where `phone` like '%335';
-- 取得姓艾的
select * from `client` where `client_name` like '艾%';
-- 取得生日是10月的
select * from `employee` where `bath_date` like '_____10%';
ログイン後にコピー
12、ユニオン-- %表示多个子元,_表示一个子元 -- 取得尾数335的数据 select * from `client` where `phone` like '%335'; -- 取得姓艾的 select * from `client` where `client_name` like '艾%'; -- 取得生日是10月的 select * from `employee` where `bath_date` like '_____10%';
-- 员工与客户合并为一列(类型必须相同)
select `name` from `employee`
union
select `client_name` from `client`;
-- 多个数据合并为多列(类型必须相同)
select `emp_id`, `name` from `employee`
union
select `client_id`, `client_name` from `client`;
-- 多个数据合并为多列(类型必须相同)顺便改个名
select `emp_id` as `total_id`, `name` as `total_name` from `employee`
union
select `client_id`, `client_name` from `client`;
ログイン後にコピー
13、接続-- 员工与客户合并为一列(类型必须相同) select `name` from `employee` union select `client_name` from `client`; -- 多个数据合并为多列(类型必须相同) select `emp_id`, `name` from `employee` union select `client_id`, `client_name` from `client`; -- 多个数据合并为多列(类型必须相同)顺便改个名 select `emp_id` as `total_id`, `name` as `total_name` from `employee` union select `client_id`, `client_name` from `client`;
-- 连接
-- 取得所有部门经理名字,这就需要先确定部门再确定经理(二表相连)
select * from `employee` join `branch` on `emp_id` = `manager_id`;
-- 还可以写成
select * from `employee` join `branch` on `employee`.`emp_id` = `branch`.`manager_id`;
-- 附加条件
select * from `employee` left join `branch` on `employee`.`emp_id` = `branch`.`manager_id`; -- 左边的表格(join的左边)返回全部数据,右边的必须满足才可
ログイン後にコピー
14、サブクエリ-- 连接 -- 取得所有部门经理名字,这就需要先确定部门再确定经理(二表相连) select * from `employee` join `branch` on `emp_id` = `manager_id`; -- 还可以写成 select * from `employee` join `branch` on `employee`.`emp_id` = `branch`.`manager_id`; -- 附加条件 select * from `employee` left join `branch` on `employee`.`emp_id` = `branch`.`manager_id`; -- 左边的表格(join的左边)返回全部数据,右边的必须满足才可
-- 查询套查询
select `name` from `employee`
where `emp_id` = (
select `manager_id`
from `branch`
where `branch_name` = '研发'
); -- 查找研发部门的经理名字
select `emp_id` from `employee`
where `emp_id` in (
select `emp_id`
from `works_with`
where `total_sales` > 50000
); -- 销售资金超50000的人有哪些ログイン後にコピー
5、削除時On delete set null この機能は、データが削除された (またはデータに対応しなくなった) 場合、null に設定されるというものです。-- 查询套查询
select `name` from `employee`
where `emp_id` = (
select `manager_id`
from `branch`
where `branch_name` = '研发'
); -- 查找研发部门的经理名字
select `emp_id` from `employee`
where `emp_id` in (
select `emp_id`
from `works_with`
where `total_sales` > 50000
); -- 销售资金超50000的人有哪些- On deletedecade対応するデータが削除された場合 (または一致できない場合)、テーブル内のデータは削除されます。
は設定できません。主キーテーブル `branch`(
16.MySQL`branch_id` int primary key , -- 第一列 `branch_name` varchar(20), -- 第二列 `manager_id` int, -- 第三列,20指的是最大字符长度 foreign key (`manager_id`) references `employee`(`emp_id`) on delete set null -- 设置好外键(选择什么是并对应什么表格的什么属性) ); -- 创建表格并设计属性 create table `works_with`( `emp_id` int, -- 第一列 `client_id` int, -- 第二列 `total_sales` int, -- 第三列,20指的是最大字符长度 primary key(`emp_id`,`client_id`), foreign key (`emp_id`) references `employee`(`emp_id`) on delete cascade, -- 设置好外键(选择什么是并对应什么表格的什么属性) foreign key (`client_id`) references `client`(`client_id`) on delete cascade -- 设置好外键(选择什么是并对应什么表格的什么属性) ); -- 创建表格并设计属性ログイン後にコピーへの Python 接続) の場合、削除時に nullcreate を設定します# 导入功能包(mysql-connector-python) import mysql.connector # 创入连线 connection = mysql.connector.connect(host='localhost', # mysql的位置 port='3306', # 连接通道 user='root', # 使用者名称 password='123456') # 使用者密码 '''connection = mysql.connector.connect(host='localhost', # mysql的位置 port='3306', # 连接通道 user='root', # 使用者名称 password='123456', # 使用者密码 database='sql_tutorial') # 直接打开目标资料库''' # 告知开始使用操作 cursor = connection.cursor() # 在对mysql操作时即用该格式:cursor.execute("你要执行的mysql语句命令") # 创建资料库 # cursor.execute("CREATE DATABASE `qq`;") # 取得所有资料库名称 cursor.execute("show databases;") records = cursor.fetchall() # 取出回传资料库 for r in records: print(r) # 因为回传列表,为便于观察,进行循环打印 # 选择资料库 cursor.execute("use `sql_tutorial`;") # 创建表格 # 告知关闭操作 cursor.close() # 若要懂资料进行修改需要结尾加一个指令,这样才能提交指令生效 connection.commit() # 关闭连线 connection.close()ログイン後にコピー以上がPython を使用して MySQL に接続する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7409
7409
 15
1631
14
1358
52
1268
25
1218
29
15
1631
14
1358
52
1268
25
1218
29

 携帯電話でXMLをPDFに変換するとき、変換速度は高速ですか?
Apr 02, 2025 pm 10:09 PM
携帯電話でXMLをPDFに変換するとき、変換速度は高速ですか?
Apr 02, 2025 pm 10:09 PM
Mobile XMLからPDFへの速度は、次の要因に依存します。XML構造の複雑さです。モバイルハードウェア構成変換方法(ライブラリ、アルゴリズム)コードの品質最適化方法(効率的なライブラリ、アルゴリズムの最適化、キャッシュデータ、およびマルチスレッドの利用)。全体として、絶対的な答えはなく、特定の状況に従って最適化する必要があります。
 携帯電話のXMLファイルをPDFに変換する方法は?
Apr 02, 2025 pm 10:12 PM
携帯電話のXMLファイルをPDFに変換する方法は?
Apr 02, 2025 pm 10:12 PM
単一のアプリケーションで携帯電話でXMLからPDF変換を直接完了することは不可能です。クラウドサービスを使用する必要があります。クラウドサービスは、2つのステップで達成できます。1。XMLをクラウド内のPDFに変換し、2。携帯電話の変換されたPDFファイルにアクセスまたはダウンロードします。
 C言語合計の機能は何ですか?
Apr 03, 2025 pm 02:21 PM
C言語合計の機能は何ですか?
Apr 03, 2025 pm 02:21 PM
C言語に組み込みの合計機能はないため、自分で書く必要があります。合計は、配列を通過して要素を蓄積することで達成できます。ループバージョン:合計は、ループとアレイの長さを使用して計算されます。ポインターバージョン:ポインターを使用してアレイ要素を指し示し、効率的な合計が自己概要ポインターを通じて達成されます。アレイバージョンを動的に割り当てます:[アレイ]を動的に割り当ててメモリを自分で管理し、メモリの漏れを防ぐために割り当てられたメモリが解放されます。
 XMLをPDFに変換できるモバイルアプリはありますか?
Apr 02, 2025 pm 09:45 PM
XMLをPDFに変換できるモバイルアプリはありますか?
Apr 02, 2025 pm 09:45 PM
XML構造が柔軟で多様であるため、すべてのXMLファイルをPDFSに変換できるアプリはありません。 XMLのPDFへのコアは、データ構造をページレイアウトに変換することです。これには、XMLの解析とPDFの生成が必要です。一般的な方法には、ElementTreeなどのPythonライブラリを使用してXMLを解析し、ReportLabライブラリを使用してPDFを生成することが含まれます。複雑なXMLの場合、XSLT変換構造を使用する必要がある場合があります。パフォーマンスを最適化するときは、マルチスレッドまたはマルチプロセスの使用を検討し、適切なライブラリを選択します。
 XMLを写真に変換する方法
Apr 03, 2025 am 07:39 AM
XMLを写真に変換する方法
Apr 03, 2025 am 07:39 AM
XMLは、XSLTコンバーターまたは画像ライブラリを使用して画像に変換できます。 XSLTコンバーター:XSLTプロセッサとスタイルシートを使用して、XMLを画像に変換します。画像ライブラリ:PILやImageMagickなどのライブラリを使用して、形状やテキストの描画などのXMLデータから画像を作成します。
 推奨されるXMLフォーマットツール
Apr 02, 2025 pm 09:03 PM
推奨されるXMLフォーマットツール
Apr 02, 2025 pm 09:03 PM
XMLフォーマットツールは、読みやすさと理解を向上させるために、ルールに従ってコードを入力できます。ツールを選択するときは、カスタマイズ機能、特別な状況の処理、パフォーマンス、使いやすさに注意してください。一般的に使用されるツールタイプには、オンラインツール、IDEプラグイン、コマンドラインツールが含まれます。
 携帯電話でXMLを高品質でPDFに変換するにはどうすればよいですか?
Apr 02, 2025 pm 09:48 PM
携帯電話でXMLを高品質でPDFに変換するにはどうすればよいですか?
Apr 02, 2025 pm 09:48 PM
携帯電話の高品質でXMLをPDFに変換する必要があります。クラウドでXMLを解析し、サーバーレスコンピューティングプラットフォームを使用してPDFを生成します。効率的なXMLパーサーとPDF生成ライブラリを選択します。エラーを正しく処理します。携帯電話の重いタスクを避けるために、クラウドコンピューティングの能力を最大限に活用してください。複雑なXML構造の処理、マルチページPDFの生成、画像の追加など、要件に応じて複雑さを調整します。デバッグを支援するログ情報を印刷します。パフォーマンスを最適化し、効率的なパーサーとPDFライブラリを選択し、非同期プログラミングまたは前処理XMLデータを使用する場合があります。優れたコードの品質と保守性を確保します。
 Android電話でXMLをPDFに変換する方法は?
Apr 02, 2025 pm 09:51 PM
Android電話でXMLをPDFに変換する方法は?
Apr 02, 2025 pm 09:51 PM
Android電話でXMLをPDFに直接変換することは、組み込み機能を介して実現できません。次の手順を通じて国を保存する必要があります。XMLデータをPDFジェネレーター(テキストやHTMLなど)によって認識された形式に変換します。フライングソーサーなどのHTML生成ライブラリを使用して、HTMLをPDFに変換します。
