

Lava Alpaca LLaVA が登場: GPT-4 と同様に、写真の表示とチャットが可能で、招待コードは不要で、オンラインでプレイできます


#GPT-4 の画像認識機能はいつオンラインになりますか?この質問に対する答えはまだありません。
しかし、研究コミュニティはもう待ちきれずに DIY を開始しており、最も人気のあるプロジェクトは MiniGPT-4 と呼ばれるプロジェクトです。 MiniGPT-4 は、詳細な画像説明の生成や手書きの下書きから Web サイトを作成するなど、GPT-4 と同様の多くの機能を示します。さらに、著者らは、与えられた画像に基づいて物語や詩を作成すること、画像に示されている問題に対する解決策を提供すること、食べ物の写真に基づいて料理方法をユーザーに教えることなど、MiniGPT-4 の他の新しい機能を観察しました。このプロジェクトは、開始から 3 日以内に約 10,000 個のスターを獲得しました。

今日紹介するプロジェクト - LLaVA (Large Language and Vision Assistant) も同様で、ウィスコンシン大学によって開発されたプロジェクトです。 -Madison と Microsoft 研究所とコロンビア大学の研究者が共同でリリースした大規模なマルチモーダル モデル。

- 論文リンク: https://arxiv.org/pdf/2304.08485.pdf
- #プロジェクト リンク: https://llava-vl.github.io/
 #Heart of the Machine の試験結果は次のとおりです (詳細な結果については記事の最後を参照してください):
#Heart of the Machine の試験結果は次のとおりです (詳細な結果については記事の最後を参照してください):
論文概要
#人間は、視覚や言語などの複数のチャネルを通じて世界と対話します。これは、さまざまなチャネルが表現と伝達において独自の利点を持っているためです。特定のコンセプト、世界をより深く理解するためのマルチチャンネルの方法。人工知能の中心的な目標の 1 つは、視覚的または口頭による指示などのマルチモーダルな指示に効果的に従い、人間の意図を満たし、現実の環境でさまざまなタスクを完了できる万能アシスタントを開発することです。
この目的を達成するために、コミュニティでは言語拡張に基づいてビジュアル モデルを開発する傾向があります。このタイプのモデルは、分類、検出、セグメンテーション、グラフィックスなどのオープンワールドの視覚的理解における強力な機能に加え、ビジュアル生成およびビジュアル編集機能を備えています。各タスクは大規模なビジュアル モデルによって独立して解決され、タスクのニーズはモデル設計で暗黙的に考慮されます。さらに、言語は画像の内容を説明するためにのみ使用されます。このため、言語は視覚信号を言語セマンティクス (人間のコミュニケーションの共通チャネル) にマッピングする上で重要な役割を果たしますが、多くの場合、対話性やユーザー指示への適応性に制限のある固定インターフェイスを持つモデルが生成されます。
一方、大規模言語モデル (LLM) は、言語が汎用インテリジェント アシスタントのためのユニバーサル インタラクティブ インターフェイスとして、より幅広い役割を果たすことができることを示しました。共通のインターフェイスでは、さまざまなタスクの指示を言語で明示的に表現し、エンドツーエンドで訓練されたニューラル ネットワーク アシスタントをガイドしてモードを切り替えてタスクを完了することができます。たとえば、ChatGPT と GPT-4 の最近の成功は、人間の指示に従ってタスクを完了する LLM の力を実証し、オープンソース LLM 開発の波を引き起こしました。その中でもLLaMAはGPT-3と同等の性能を持つオープンソースLLMです。 Alpaca、Vicuna、GPT-4-LLM は、さまざまな機械生成された高品質命令トレース サンプルを利用して LLM のアライメント機能を向上させ、独自の LLM と比較して優れたパフォーマンスを示します。残念ながら、これらのモデルへの入力はテキストのみです。
この記事では、研究者らは視覚的な命令チューニング方法を提案しています。これは、命令チューニングをマルチモーダル空間に拡張する最初の試みであり、一般的な視覚アシスタントの構築への道を開きます。
具体的には、この論文は次のことに貢献します:
- マルチモーダル命令データ。現在の主要な課題の 1 つは、視覚的および口頭によるコマンド データの欠如です。この論文では、ChatGPT/GPT-4 を使用して画像とテキストのペアを適切な命令形式に変換するデータ再編成アプローチを提案します。
- 大規模マルチモーダル モデル。研究者らは、CLIPのオープンソースビジュアルエンコーダと言語デコーダLLaMAを接続することで大規模マルチモーダルモデル(LMM)-LLaVA-を開発し、生成された視覚的・言語的指示データに対してエンドツーエンドの微調整を実行しました。実証研究により、生成されたデータを LMM 命令チューニングに使用する有効性が検証され、視覚エージェントに従う汎用命令を構築するためのより実用的な手法が提供されます。 GPT-4 を使用することで、マルチモーダル推論データセットである Science QA で最先端のパフォーマンスを実現します。 ############オープンソース。研究者らは、生成されたマルチモーダル命令データ、データ生成とモデル トレーニング用のコード ライブラリ、モデル チェックポイント、およびビジュアル チャット デモンストレーションの資産を一般に公開しました。
- LLaVA アーキテクチャ
入力画像 X_v について、この記事では、事前学習済みの CLIP ビジュアル エンコーダ ViT-L/14 を処理に使用し、視覚特徴を取得します。 Z_v=g (X_v)。最後の Transformer レイヤーの前後のメッシュ フィーチャが実験で使用されました。この記事では、単純な線形レイヤーを使用して、画像特徴を単語埋め込み空間に接続します。具体的には、トレーニング可能な射影行列 W を適用して、Z_v を言語埋め込みトークン H_q に変換します。これは、言語モデルの単語埋め込み空間と同じ次元を持ちます。 
#その後、一連の視覚マーカー H_v が取得されます。このシンプルな投影スキームは軽量かつ低コストで、データ中心の実験を迅速に繰り返すことができます。また、Flamingo のゲート クロスアテンション メカニズムや BLIP-2 の Q-former など、画像と言語の機能を連結するためのより複雑な (しかし高価な) スキームや、オブジェクト レベルの機能を提供する他のビジュアル エンコーダを検討することもできます。サム。 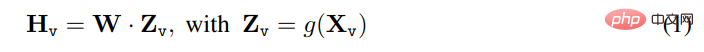
実験結果
マルチモーダル チャットボット
研究者は、チャット ロボットのサンプル製品を開発しました。 LLaVA の画像理解と対話機能を実証します。 LLaVA がどのように視覚入力を処理し、命令を処理する能力を実証するかをさらに研究するために、研究者らはまず、表 4 および 5 に示すように、元の GPT-4 論文の例を使用しました。使用されるプロンプトは画像の内容に適合する必要があります。比較のために、この記事ではマルチモーダル モデル GPT-4 のプロンプトと結果を論文から引用しています。

驚くべきことに、LLaVA は小規模なマルチモーダル命令データセット ((約 80K の固有の画像) を使用して実行されましたが、 ) ですが、上記の 2 つの例では、マルチモーダル モデル GPT-4 と非常によく似た推論結果が示されています。どちらの画像も LLaVA のデータセットの範囲外であることに注意してください。LLaVA はシーンを理解し、質問の指示に答えることができます。対照的に、BLIP-2 と OpenFlamingo は、ユーザーの指示に適切な方法で応答するのではなく、画像を記述することに重点を置いています。他の例を図 3、図 4、および図 5 に示します。 



#定量的な評価結果を表 3 に示します。

ScienceQA
ScienceQA には、21,000 個のマルチモーダルな複数選択の質問が含まれています、3 つのテーマ、26 のトピック、127 のカテゴリ、および 379 のスキルが含まれており、ドメインの多様性が豊かです。ベンチマーク データセットは、トレーニング、検証、テストの各部分に分割されており、それぞれ 12726、4241、4241 個のサンプルがあります。この記事では、GPT-3.5 モデル (text-davinci-002) と、思考連鎖 (CoT) バージョン、LLaMA アダプター、およびマルチモーダル思考連鎖 (MM-CoT) を含まない GPT-3.5 モデルを含む 2 つの代表的な方法を比較します [57] ]、これはこのデータセットに対する現在の SoTA メソッドであり、その結果を表 6 に示します。

論文に記載されているビジュアライゼーションの使用方法のページで、マシンハートはいくつかの画像と命令を入力しようとしました。 。 1 つ目は、Q&A における複数人で行う一般的なタスクです。テストの結果、人数を数える際に小さなターゲットが無視されること、重なっている人に対して認識エラーが発生すること、性別についても認識エラーが発生することが判明しました。


#次に、写真に名前を付ける、または絵に基づいてストーリーを語るなど、いくつかの生成タスクを試しました。絵物語。モデルによって出力される結果は依然として画像コンテンツの理解に偏っており、生成機能を強化する必要があります。


以上がLava Alpaca LLaVA が登場: GPT-4 と同様に、写真の表示とチャットが可能で、招待コードは不要で、オンラインでプレイできますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7465
7465
 15
1376
52
77
11
18
19
15
1376
52
77
11
18
19

 ddrescue を使用して Linux 上のデータを回復する
Mar 20, 2024 pm 01:37 PM
ddrescue を使用して Linux 上のデータを回復する
Mar 20, 2024 pm 01:37 PM
DDREASE は、ハード ドライブ、SSD、RAM ディスク、CD、DVD、USB ストレージ デバイスなどのファイル デバイスまたはブロック デバイスからデータを回復するためのツールです。あるブロック デバイスから別のブロック デバイスにデータをコピーし、破損したデータ ブロックを残して正常なデータ ブロックのみを移動します。 ddreasue は、回復操作中に干渉を必要としないため、完全に自動化された強力な回復ツールです。さらに、ddasue マップ ファイルのおかげでいつでも停止および再開できます。 DDREASE のその他の主要な機能は次のとおりです。 リカバリされたデータは上書きされませんが、反復リカバリの場合にギャップが埋められます。ただし、ツールに明示的に指示されている場合は切り詰めることができます。複数のファイルまたはブロックから単一のファイルにデータを復元します
 オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
0.この記事は何をするのですか?私たちは、多用途かつ高速な最先端の生成単眼深度推定モデルである DepthFM を提案します。従来の深度推定タスクに加えて、DepthFM は深度修復などの下流タスクでも最先端の機能を実証します。 DepthFM は効率的で、いくつかの推論ステップ内で深度マップを合成できます。この作品について一緒に読みましょう〜 1. 論文情報タイトル: DepthFM: FastMonocularDepthEstimationwithFlowMatching 著者: MingGui、JohannesS.Fischer、UlrichPrestel、PingchuanMa、Dmytr
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google が推進する JAX のパフォーマンスは、最近のベンチマーク テストで Pytorch や TensorFlow のパフォーマンスを上回り、7 つの指標で 1 位にランクされました。また、テストは最高の JAX パフォーマンスを備えた TPU では行われませんでした。ただし、開発者の間では、依然として Tensorflow よりも Pytorch の方が人気があります。しかし、将来的には、おそらくより大規模なモデルが JAX プラットフォームに基づいてトレーニングされ、実行されるようになるでしょう。モデル 最近、Keras チームは、ネイティブ PyTorch 実装を使用して 3 つのバックエンド (TensorFlow、JAX、PyTorch) をベンチマークし、TensorFlow を使用して Keras2 をベンチマークしました。まず、主流のセットを選択します
 iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhone のモバイル データ接続に遅延や遅い問題が発生していませんか?通常、携帯電話の携帯インターネットの強度は、地域、携帯ネットワークの種類、ローミングの種類などのいくつかの要因によって異なります。より高速で信頼性の高いセルラー インターネット接続を実現するためにできることがいくつかあります。解決策 1 – iPhone を強制的に再起動する 場合によっては、デバイスを強制的に再起動すると、携帯電話接続を含む多くの機能がリセットされるだけです。ステップ 1 – 音量を上げるキーを 1 回押して放します。次に、音量小キーを押して、もう一度放します。ステップ 2 – プロセスの次の部分は、右側のボタンを押し続けることです。 iPhone の再起動が完了するまで待ちます。セルラーデータを有効にし、ネットワーク速度を確認します。もう一度確認してください 修正 2 – データ モードを変更する 5G はより優れたネットワーク速度を提供しますが、信号が弱い場合はより適切に機能します
 Kuaishou バージョンの Sora「Ke Ling」がテスト用に公開されています。120 秒以上のビデオを生成し、物理学をより深く理解し、複雑な動きを正確にモデル化できます。
Jun 11, 2024 am 09:51 AM
Kuaishou バージョンの Sora「Ke Ling」がテスト用に公開されています。120 秒以上のビデオを生成し、物理学をより深く理解し、複雑な動きを正確にモデル化できます。
Jun 11, 2024 am 09:51 AM
何?ズートピアは国産AIによって実現するのか?ビデオとともに公開されたのは、「Keling」と呼ばれる新しい大規模な国産ビデオ生成モデルです。 Sora も同様の技術的ルートを使用し、自社開発の技術革新を多数組み合わせて、大きく合理的な動きをするだけでなく、物理世界の特性をシミュレートし、強力な概念的結合能力と想像力を備えたビデオを制作します。データによると、Keling は、最大 1080p の解像度で 30fps で最大 2 分の超長時間ビデオの生成をサポートし、複数のアスペクト比をサポートします。もう 1 つの重要な点は、Keling は研究所が公開したデモやビデオ結果のデモンストレーションではなく、ショートビデオ分野のリーダーである Kuaishou が立ち上げた製品レベルのアプリケーションであるということです。さらに、主な焦点は実用的であり、白紙小切手を書かず、リリースされたらすぐにオンラインに移行することです。Ke Ling の大型モデルは Kuaiying でリリースされました。
 超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
世界は狂ったように大きなモデルを構築していますが、インターネット上のデータだけではまったく不十分です。このトレーニング モデルは「ハンガー ゲーム」のようであり、世界中の AI 研究者は、データを貪欲に食べる人たちにどのように餌を与えるかを心配しています。この問題は、マルチモーダル タスクで特に顕著です。何もできなかった当時、中国人民大学学部のスタートアップチームは、独自の新しいモデルを使用して、中国で初めて「モデル生成データフィード自体」を実現しました。さらに、これは理解側と生成側の 2 つの側面からのアプローチであり、両方の側で高品質のマルチモーダルな新しいデータを生成し、モデル自体にデータのフィードバックを提供できます。モデルとは何ですか? Awaker 1.0 は、中関村フォーラムに登場したばかりの大型マルチモーダル モデルです。チームは誰ですか?ソフォンエンジン。人民大学ヒルハウス人工知能大学院の博士課程学生、ガオ・イージャオ氏によって設立されました。
 アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
最近、軍事界は、米軍戦闘機が AI を使用して完全自動空戦を完了できるようになったというニュースに圧倒されました。そう、つい最近、米軍のAI戦闘機が初めて公開され、その謎が明らかになりました。この戦闘機の正式名称は可変安定性飛行シミュレーター試験機(VISTA)で、アメリカ空軍長官が自ら飛行させ、一対一の空戦をシミュレートした。 5 月 2 日、フランク ケンダル米国空軍長官は X-62AVISTA でエドワーズ空軍基地を離陸しました。1 時間の飛行中、すべての飛行動作が AI によって自律的に完了されたことに注目してください。ケンダル氏は「過去数十年にわたり、私たちは自律型空対空戦闘の無限の可能性について考えてきたが、それは常に手の届かないものだと思われてきた」と語った。しかし今では、
