

現在、データ サイエンス コンテストで提供されるデータの量は数十ギガバイトから数百ギガバイトにまで増加しており、マシンのパフォーマンスとデータがテストされます。処理能力。
Python の Pandas は、一般的に使用されるデータ処理ツールです。これは、より大きなデータ セット (数千万行) を処理できます。しかし、データ量が数十億行に達すると、パンダは少し処理できなくなります。非常に遅いと言えます。
コンピューターのメモリなどのパフォーマンス要因もありますが、パンダ独自のデータ処理メカニズム (メモリに依存する) により、ビッグ データの処理能力も制限されます。
もちろん、パンダはデータをチャンクにまとめてバッチで読み取ることができますが、データ処理がより複雑になり、分析の各ステップでメモリと時間を消費するという欠点があります。
次に、pandas を使用して 4 列、1 億行の 3.7G データ セット (hdf5 形式) を読み取り、最初の行の平均を計算します。私のコンピュータの CPU は i7-8550U、メモリは 8G ですが、このロードと計算プロセスにどれくらい時間がかかるかを見てみましょう。
データセット:
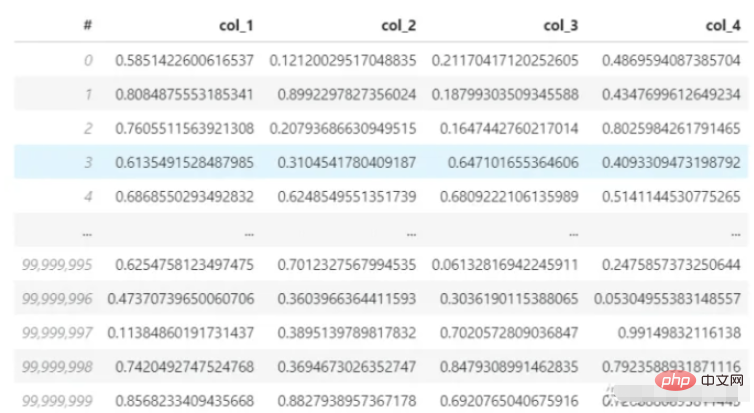
パンダを使用して読み取りと計算:
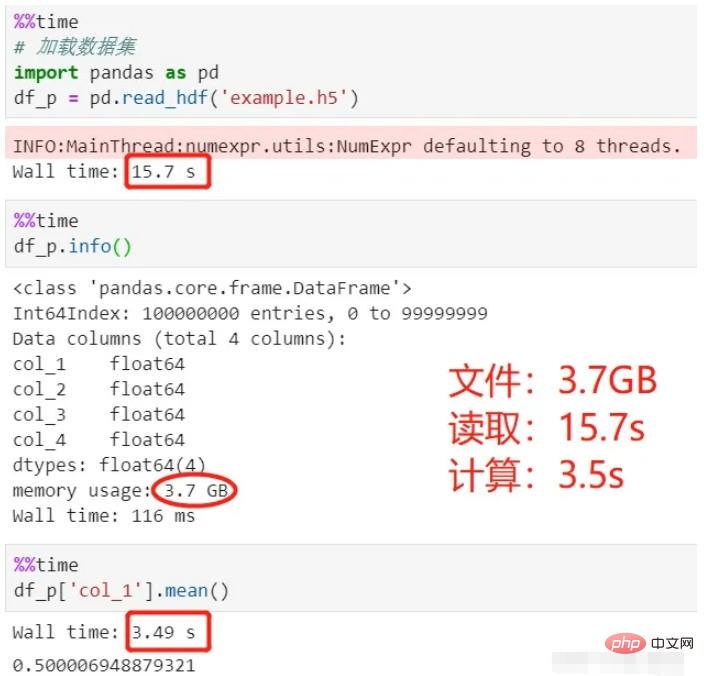
上記のプロセスを見てください。データのロードに 15 秒、平均の計算に 3.5 秒、合計 18.5 秒かかりました。
ここで使用する hdf5 ファイルは、csv に比べて大量のデータの保存に適しており、圧縮率が高く、読み書きが高速なファイル保存形式です。
今日の主人公vaexに変わって、同じデータを読み込んで同じ平均計算をしてみるとどれくらい時間がかかりますか?
vaex を使用して読み取りと計算を行います:
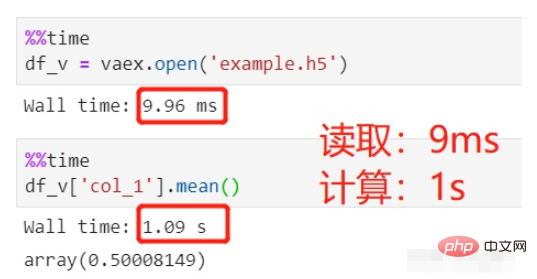
#ファイルの読み取りには 9 ミリ秒かかりましたが、これは無視できるほどであり、平均計算には 1 秒かかり、合計 1 秒かかりました。
同じ HDFS データ セット (1 億行) が読み取られますが、vaex では 0 秒近くかかるのに、panda では 10 秒以上かかるのはなぜですか?
これは主に、pandas がデータをメモリに読み取り、それを処理と計算に使用するためです。 Vaex は、実際にデータをメモリに読み取るのではなく、データをメモリ マップするだけです。これは、Spark の遅延読み込みと同じです。宣言時ではなく、使用時にロードされます。
つまり、10GB、100GBなど、どれほど大きなデータをロードしても、vaexでは即座に実行できます。問題は、vaex の遅延読み込みが HDF5、Apache Arrow、Parquet、FITS およびその他のファイルのみをサポートし、テキスト ファイルはメモリ マップできないため、csv などのテキスト ファイルをサポートしていないことです。
一部の友人はメモリ マッピングをよく理解していないかもしれません。ここで説明します。詳細を確認するには、自分で調べる必要があります:
メモリ マッピングは、ハード上のファイルの場所を指します。ディスクとプロセスの論理アドレス、空間内の同じサイズの領域間の 1 対 1 の対応関係。この対応関係は純粋に論理的な概念であり、プロセス自体の論理アドレス空間が存在しないため、物理的には存在しません。メモリ マッピングのプロセスでは、実際のデータのコピーは行われません。ファイルはメモリにロードされるのではなく、論理的にメモリに配置されます。具体的には、コードに関しては、関連するデータ構造 (struct address_space) が確立されます。そして初期化されました。
先ほど vaex と pandas の間でビッグデータの処理速度を比較しましたが、vaex には明らかな利点があります。実力は抜群で、知名度はパンダほどではありませんが、vaexはまだ業界から出てきたばかりの新人です。
vaex は、Python ベースのデータ処理用のサードパーティ ライブラリでもあり、pip を使用してインストールできます。
公式 Web サイトでの vaex の紹介は 3 つのポイントに要約できます:
vaex は、pandas に似た、データを処理および表示するためのデータ テーブル ツールです。
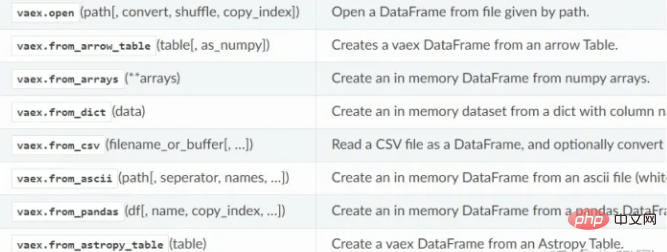
 データの読み取り
データの読み取り
 vaex データ読み取り関数:
vaex データ読み取り関数:
データに対してさまざまな変換、スクリーニング、計算などを実行する必要がある場合があり、パンダ処理の各ステップはメモリを消費し、時間がかかります。料金。チェーン処理を使用しない限り、プロセスは非常に不明確です。
vaex はプロセス全体を通じてメモリがゼロです。その処理は論理表現である式を生成するだけなので実行されず、最終結果生成段階でのみ実行されます。さらに、プロセス全体のデータはストリーミングされるため、メモリのバックログは発生しません。
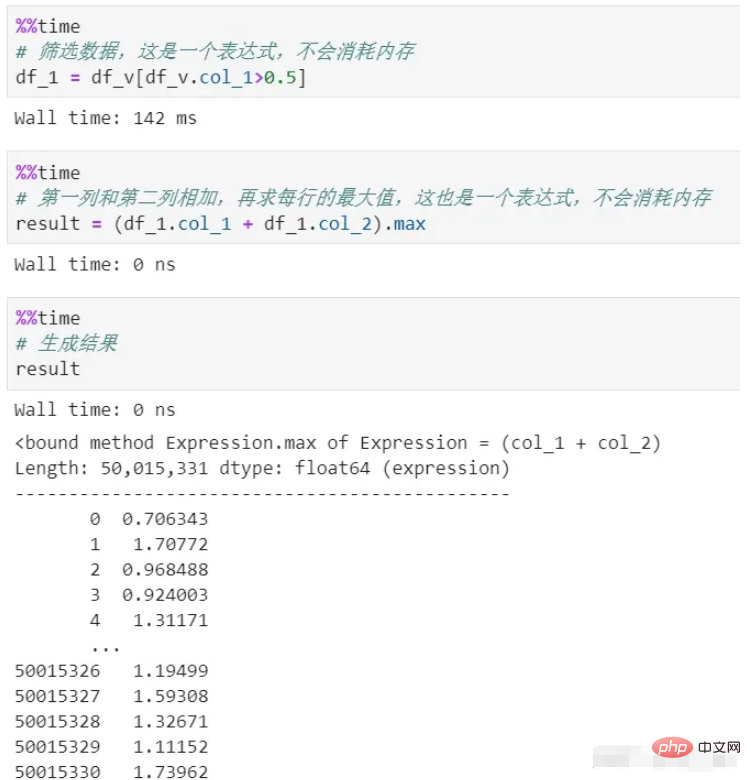
上記ではフィルタリングと計算の 2 つのプロセスがあり、どちらもメモリをコピーしていないことがわかります。ここでは遅延計算 (遅延メカニズム) が使用されています。実際に各処理を計算するとメモリ消費はもちろん、時間コストだけでも莫大なものになってしまいます。
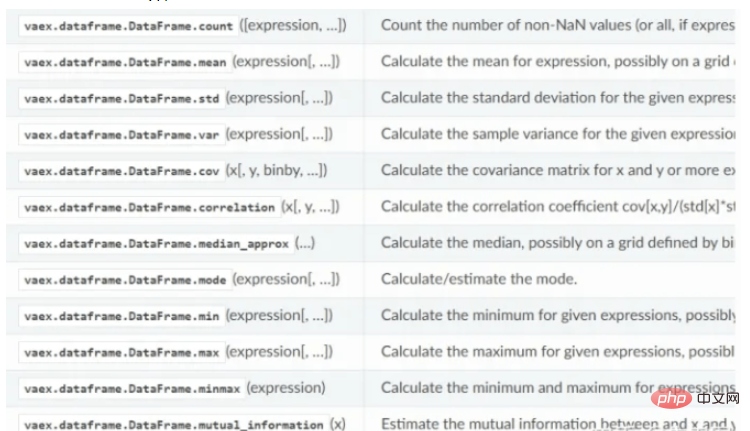
vaex の統計計算機能:
vaex は数百億のデータでも迅速なビジュアル表示を実行できます。それでも数秒で写真を作成できます。
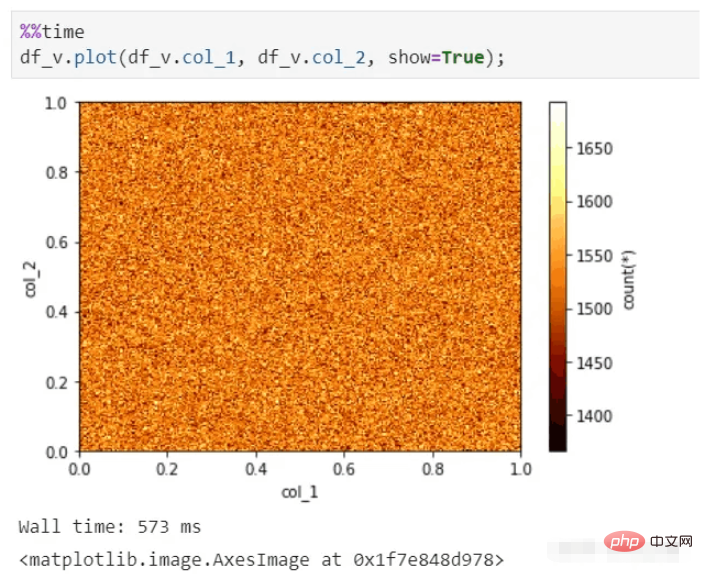
vaex 可視化機能:

vaex は、spark の組み合わせに似ています。 pandas は、データ量が多ければ多いほど、その利点をより多く反映できます。ハードドライブに必要なだけのデータを保存できる限り、データを迅速に分析できます。
vaex は現在も急速に開発を続けており、ますます多くの pandas 機能を統合しており、github でのスター数は 5,000 であり、その成長の可能性は非常に大きいです。
添付ファイル: hdf5 データ セット生成コード (4 列、1 億行のデータ)
import pandas as pd import vaex df = pd.DataFrame(np.random.rand(100000000,4),columns=['col_1','col_2','col_3','col_4']) df.to_csv('example.csv',index=False) vaex.read('example.csv',convert='example1.hdf5')
HDF5 の形式は vaex と互換性がないため、pandas を使用して hdf5 を直接生成しないことに注意してください。
以上がPython Vaex が 100G の大容量データを迅速に分析する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



