

トランスフォーマーが再びディフュージョンを破る! Google、新世代のテキスト画像生成モデル Muse をリリース:生成効率が 10 倍に向上

最近、Google は新しい テキスト画像生成 Muse モデルをリリースしました。これは、現在人気のある拡散モデルを使用せず、古典的な Transformer モデルを使用して、最も高度な画像生成を実現します。パフォーマンス: 比較拡散モデルまたは自己回帰モデルを使用すると、Muse モデルの効率も大幅に向上します。

# 論文リンク: https://arxiv.org/pdf/2301.00704.pdf
プロジェクトリンク: https://muse-model.github.io/
#Muse は離散トークン空間でマスクされたモデリング タスクを使用しますトレーニング対象: 事前トレーニングされた大規模言語モデル (LLM) から抽出されたテキスト埋め込みが与えられた場合、Muse のトレーニング プロセスは、ランダムにマスクされた画像トークンを予測することです。ピクセル空間拡散モデル (Imagen や DALL-E 2 など) と比較して、Muse は離散トークンを使用するため、必要なサンプリング反復が少なくなり、効率が向上します。 大幅に向上しました。
自己回帰モデル (Parti など) と比較すると、Muse は並列デコードを使用するため、より効率的です。

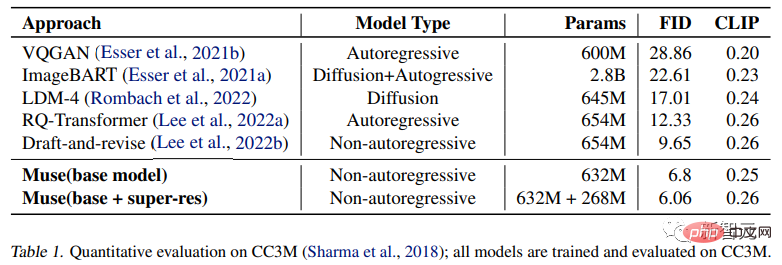
実験結果では、パラメータが 900M のみの Muse モデルが、CC3M 上で新しい SOTA パフォーマンスを達成し、FID スコアは 6.06 でした。
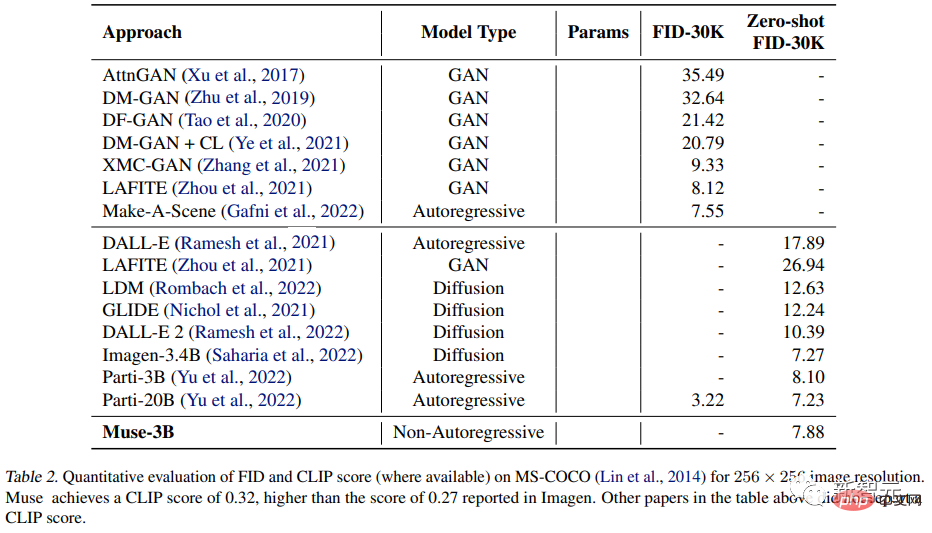
Muse 3B パラメトリック モデルは、ゼロショット COCO 評価で 7.88 の FID を達成し、CLIP スコアは 0.32 でした。

Muse モデル
Muse モデルのフレームワークには複数のコンポーネントが含まれており、トレーニング パイプラインは T5-XXL の事前トレーニング済みテキスト エンコーダー、ベース モデル、超解像度で構成されていますレートモデル。
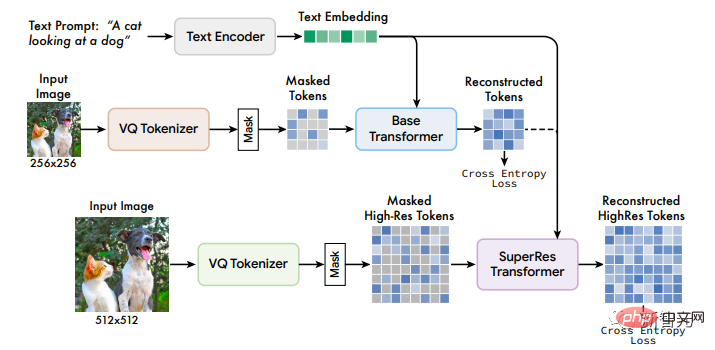
#1. 事前トレーニングされたテキスト エンコーダー ##以前の研究で得られた結論と同様に、研究者らは、事前トレーニングされた大規模言語モデル (LLM) の使用が高品質画像の生成を向上させるのに有益であることを発見しました。
たとえば、言語モデル T5-XXL から抽出された埋め込みには、オブジェクト (名詞)、アクション (動詞)、視覚的属性 (形容詞)、および空間関係 (前置詞) に関する情報が含まれています。カーダビリティや構成などの他の属性に関する豊富な情報も含まれています。
そこで研究者らは、次の仮説を提案しました。Muse モデルは、LLM 埋め込み内のこれらの豊富な視覚的および意味論的な概念を、生成された画像にマッピングすることを学習します。
最近の研究では、LLM によって学習された概念表現と、視覚タスクでトレーニングされたモデルによって学習された概念表現が、大まかに「線形マッピング」できることが証明されました。
入力テキスト タイトルが与えられると、それを凍結されたパラメータとともに T5-XXL エンコーダに渡すと、4096 次元の言語埋め込みベクトルが生成され、これが非表示のサイズ次元に線形投影されます。 Transformer モデル (ベースおよび超解像度)。
2. セマンティック トークン化に VQGAN を使用する
VQGAN モデルはエンコーダーとデコーダーで構成されます。量子化層は、学習されたコードブックからのトークンのシーケンスに入力画像をマッピングします。
次に、エンコーダーとデコーダーは完全に畳み込み層で構築され、さまざまな解像度の画像のエンコードをサポートします。
エンコーダには、入力の空間次元を削減するためにいくつかのダウンサンプリング ブロックが含まれていますが、デコーダには、潜在データを元の画像サイズにマップし直すための対応する数のアップサンプリング ブロックがあります。
研究者らは 2 つの VQGAN モデルをトレーニングしました。1 つはダウンサンプリング レート f=16 で、モデルは 256×256 ピクセルの画像上で基本モデルのラベルを取得し、 16×16マークの空間サイズ、もう1つはダウンサンプリング率f=8であり、超解像モデルのトークンは512×512画像上で取得され、対応する空間サイズは64×64である。
エンコード後に取得された離散トークンは、画像の高レベルのセマンティクスをキャプチャし、低レベルのノイズも除去できます。トークンの離散性に応じて、クロスエントロピー損失は次のようになります。次の段階でマスクされたトークンを予測します
#3. ベース モデル
##Muse モデルはマスクされた Transformer で、入力はマップされた T5 埋め込みと画像トークンです。
研究者は、すべてのテキスト埋め込みをマスク解除に設定し、ランダムにマスクアウトした後、さまざまな画像トークンの一部。特別な [MASK] タグを使用して元のトークンを置き換えます。
その後、画像トークンは必要な Transformer 入力または非表示サイズの画像入力に線形にマッピングされます。埋め込みと同時に 2D 位置の埋め込みを学習します
は、セルフ アテンション ブロック、クロスアテンション ブロック、および MLP ブロックを使用した、いくつかのトランスフォーマー層を含む、元の Transformer アーキテクチャと同じです。特徴を抽出します。
出力層では、MLP を使用して、各マスクされた画像埋め込みを一連のロジット (VQGAN コードブックのサイズに対応) に変換し、グラウンドとのクロスエントロピーを使用します。ターゲット損失としての真実のトークン。
トレーニング フェーズでは、基本モデルのトレーニング目標は、各ステップですべての msked トークンを予測することですが、推論フェーズでは、マスク予測が反復的に実行されます。品質を大幅に向上させることができます。
4. 超解像度モデル
研究者らは、512 倍を直接予測できることを発見しました。 512 解像度の画像では、モデルは高レベルのセマンティクスではなく、低レベルの詳細に焦点を当てます。
モデルのカスケードを使用すると、この状況を改善できます。
最初に 1 つを使用して 16×16 の潜在マップを生成します ( 256×256 画像)、次に基本潜在マップを 64×64(512×512 画像に相当)にアップサンプリングする超解像度モデル。超解像モデルは、基本モデルのトレーニングが完了した後にトレーニングされます。
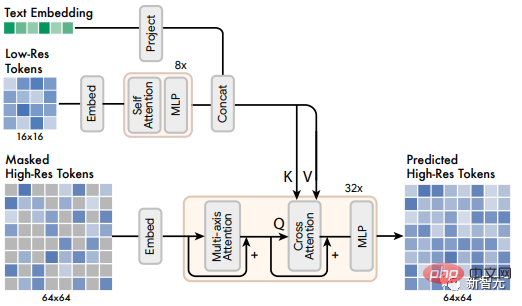
前述したように、研究者は合計 2 つの VQGAN モデルをトレーニングしました。1 つは 16×16 の潜在解像度と 256×256 の空間解像度レートで、もう 1 つは、64×64 の潜在解像度と 512×512 の空間解像度です。
基本モデルは 16×16 の潜在マップに対応するトークンを出力するため、超解像度モジュールは低解像度の潜在マップを高解像度の潜在マップに「変換」することを学習します。マップを作成し、高解像度 VQGAN デコードを通じて最終的な高解像度画像を取得します。翻訳モデルも、基本モデルと同様の方法でテキスト コンディショニングとクロスアテンションを使用してトレーニングされます。
5. デコーダの微調整
モデルの詳細を生成する能力をさらに向上させるために、研究者らは、エンコーダーの容量を変更せずに、より多くの残りのレイヤーとチャネルを追加することで、VQGAN デコーダーの容量を増やすことを選択しました。
次に、VQGAN エンコーダの重み、コードブック、トランスフォーマー (つまり、ベース モデルと超解像度モデル) を変更せずに、新しいデコーダを微調整します。このアプローチにより、他のモデル コンポーネントを再トレーニングする必要がなく、生成された画像の視覚的な品質が向上します (視覚的なトークンは固定されたままであるため)。

ご覧のとおり、デコーダはより多くのより鮮明な詳細を再構築するために微調整されています。
#6. 変数マスキング率
研究者が使用するモデルは変数マスクでトレーニングされますCsoine スケジューリングに基づくレート: 各トレーニング例について、マスク レート r∈[0, 1] は、次のような密度関数を使用して切り捨てられたアークコス分布から抽出されます。 マスク レートの期待値は 0.64 です。これは、マスク レートが高いほど好ましいことを意味し、予測問題がより困難になります。
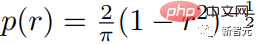
7. 分類器なしガイダンス (CFG)
研究者は分類器なしガイダンスを使用します(CFG) 画像生成の品質とテキストと画像の位置合わせを向上させます。
トレーニング中に、ランダムに選択されたサンプルの 10% からテキスト条件が削除され、注意メカニズムは画像トークン自体の自己注意に縮小されます。推論段階では、マスクされたトークンごとに条件付きロジット lc と無条件ロジット lu が計算され、その後、量 t が、形成するためのガイドスケールとして無条件ロジットから削除されます。最終的なロジット lg:
直感的には、CFG は多様性を犠牲にして忠実度を犠牲にしますが、以前の方法とは異なり、Muse はサンプリングを使用します。このプロセスにより、ガイダンス スケール t が直線的に増加します。多様性の損失を軽減し、少ないガイダンスまたはガイダンスなしで初期のトークンをより自由にサンプリングできるようにしますが、後のトークンに対する条件付きキューの影響も増加します。
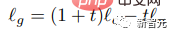
8. 推論中の反復並列デコード
モデル推論の時間効率を向上させるための重要な部分は、単一の順方向チャネルで複数の出力トークンを予測するために並列処理デコーディングを使用する場合、重要な前提の 1 つはマルコフ特性です。つまり、多くのトークンは他のトークンから条件付きで独立しています。
デコードはコサイン スケジュールに従って実行され、固定比率で最も信頼度の高いマスクが予測用に選択され、残りのステップでトークンがマスク解除されるように設定されます。マスクされたトークンが適切に削減されます。上記のプロセスによれば、基本モデルでは 256 個のトークンの推論を達成するために 24 の復号ステップのみを使用できますが、超解像モデルでは 8 つの復号ステップを使用できます。 4096 トークンの推論。これに対し、自己回帰モデルでは 256 または 4096 ステップ、拡散モデルでは数百ステップです。
漸進的蒸留やより優れた ODE ソルバーなどの最近の研究により、拡散モデルのサンプリング ステップが大幅に削減されましたが、これらの方法は大規模なテキストから画像への生成では広く検証されていません。 研究者らは、T5-XXL に基づいて、さまざまなパラメーター量 (600M から 3B) で一連の基本的なトランス モデルをトレーニングしました。 #生成された画像の品質 #実験では、さまざまな属性を持つテキスト プロンプトを処理する Muse モデルの機能をテストしました。カーディナリティの基本的な理解は、非特異オブジェクトの場合、Muse は同じオブジェクト ピクセルを複数回生成しないが、イメージ全体をより現実的にするためにコンテキストの変更を追加するということです。 たとえば、象の大きさや向き、ワインボトルの包装紙の色、テニスボールの回転など。 定量的比較 研究者らは、CC3M および COCO データセット、メトリクスについて、他の研究手法との実験比較を実施しました。これには、サンプルの品質と多様性を測定する Frechet Inception Distance (FID) と、画像とテキストの配置を測定する CLIP スコアが含まれます。 実験結果は、632M Muse モデルが CC3M で SOTA 結果を達成し、FID スコアを改善し、最高の結果を達成したことを証明しました。得点。 MS-COCO データセットでは、3B モデルは 7.88 の FID スコアを達成しました。これは、Parti-3B モデルよりわずかに優れています。同様のパラメータ量で、8.1 ポイントを達成しました。 実験結果

以上がトランスフォーマーが再びディフュージョンを破る! Google、新世代のテキスト画像生成モデル Muse をリリース:生成効率が 10 倍に向上の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7513
7513
 15
1378
52
79
11
19
64
15
1378
52
79
11
19
64


 DeepSeekを検索する方法
Feb 19, 2025 pm 05:39 PM
DeepSeekを検索する方法
Feb 19, 2025 pm 05:39 PM
DeepSeekは、特定のデータベースまたはシステムでのみ検索する独自の検索エンジンであり、より速く、より正確です。それを使用する場合、ユーザーはドキュメントを読み、さまざまな検索戦略を試し、ユーザーエクスペリエンスに関するヘルプを求めてフィードバックを求めて、利点を最大限に活用することをお勧めします。
 セサミオープンドア交換Webページ登録リンクゲートトレーディングアプリ登録Webサイト最新
Feb 28, 2025 am 11:06 AM
セサミオープンドア交換Webページ登録リンクゲートトレーディングアプリ登録Webサイト最新
Feb 28, 2025 am 11:06 AM
この記事では、SESAME Open Exchange(gate.io)Webバージョンの登録プロセスとGate Tradingアプリを詳細に紹介します。 Web登録であろうとアプリの登録であろうと、公式Webサイトまたはアプリストアにアクセスして、本物のアプリをダウンロードし、ユーザー名、パスワード、電子メール、携帯電話番号、その他の情報を入力し、電子メールまたは携帯電話の確認を完了する必要があります。
 Bybit Exchangeリンクを直接ダウンロードしてインストールできないのはなぜですか?
Feb 21, 2025 pm 10:57 PM
Bybit Exchangeリンクを直接ダウンロードしてインストールできないのはなぜですか?
Feb 21, 2025 pm 10:57 PM
Bybit Exchangeリンクを直接ダウンロードしてインストールできないのはなぜですか? BYBITは、ユーザーにトレーディングサービスを提供する暗号通貨交換です。 Exchangeのモバイルアプリは、次の理由でAppStoreまたはGooglePlayを介して直接ダウンロードすることはできません。1。AppStoreポリシーは、AppleとGoogleがApp Storeで許可されているアプリケーションの種類について厳しい要件を持つことを制限しています。暗号通貨交換アプリケーションは、金融サービスを含み、特定の規制とセキュリティ基準を必要とするため、これらの要件を満たしていないことがよくあります。 2。法律と規制のコンプライアンス多くの国では、暗号通貨取引に関連する活動が規制または制限されています。これらの規制を遵守するために、BYBITアプリケーションは公式Webサイトまたはその他の認定チャネルを通じてのみ使用できます
 セサミオープンドアトレーディングプラットフォームダウンロードモバイルバージョンgateioトレーディングプラットフォームのダウンロードアドレス
Feb 28, 2025 am 10:51 AM
セサミオープンドアトレーディングプラットフォームダウンロードモバイルバージョンgateioトレーディングプラットフォームのダウンロードアドレス
Feb 28, 2025 am 10:51 AM
アプリをダウンロードしてアカウントの安全を確保するために、正式なチャネルを選択することが重要です。
 セサミオープンドアエクスチェンジウェブページログイン最新バージョンgateio公式ウェブサイトの入り口
Mar 04, 2025 pm 11:48 PM
セサミオープンドアエクスチェンジウェブページログイン最新バージョンgateio公式ウェブサイトの入り口
Mar 04, 2025 pm 11:48 PM
ログインステップやパスワード回復プロセスなど、セサミオープンエクスチェンジWebバージョンのログイン操作の詳細な紹介も、ログイン障害、ページを開くことができず、プラットフォームにスムーズにログインするのに役立つ検証コードを受信できません。
 Binance Binance公式Webサイト最新バージョンログインポータル
Feb 21, 2025 pm 05:42 PM
Binance Binance公式Webサイト最新バージョンログインポータル
Feb 21, 2025 pm 05:42 PM
Binance Webサイトログインポータルの最新バージョンにアクセスするには、これらの簡単な手順に従ってください。公式ウェブサイトに移動し、右上隅の[ログイン]ボタンをクリックします。既存のログインメソッドを選択してください。「登録」してください。登録済みの携帯電話番号または電子メールとパスワードを入力し、認証を完了します(モバイル検証コードやGoogle Authenticatorなど)。検証が成功した後、Binance公式WebサイトLogin Portalの最新バージョンにアクセスできます。
 Crypto Digital Asset Trading App(2025グローバルランキング)に推奨されるトップ10
Mar 18, 2025 pm 12:15 PM
Crypto Digital Asset Trading App(2025グローバルランキング)に推奨されるトップ10
Mar 18, 2025 pm 12:15 PM
この記事では、Binance、Okx、Gate.io、Bitflyer、Kucoin、Bybit、Coinbase Pro、Kraken、Bydfi、Xbit分散化された交換など、注意を払う価値のある上位10の暗号通貨取引プラットフォームを推奨しています。これらのプラットフォームには、トランザクションの数量、トランザクションの種類、セキュリティ、コンプライアンス、特別な機能の点で独自の利点があります。適切なプラットフォームを選択するには、あなた自身の取引体験、リスク許容度、投資の好みに基づいて包括的な検討が必要です。 この記事があなたがあなた自身に最適なスーツを見つけるのに役立つことを願っています
