

SpringBoot JPA共通アノテーションの使用方法

1. はじめに
Jpa は ORM 仕様のセットです
hibernate は単なる ORM フレームワークではありませんJPA
JPA (Java Persistence API): java 永続性 API
2 の実装を提供します。共通のアノテーション
2.1 @ Entity
は、現在のクラスをエンティティ クラスとしてマークし、指定されたデータベース テーブル
@Entity
public class Users {
}2.2 にマップされます。@Table
は通常、@Entity とともに注釈が付けられます。使用します。データベースのテーブル名とクラス名が一致している場合は、@Table アノテーションを使用しなくても問題ありません。
それ以外の場合は、@Table アノテーションを使用する必要があります。テーブル名を指定します
@Entity
@Table(name="t_users")
public class Users {
}2.3 @Id、@GeneratedValue、@SequenceGenerator、@Column
2.3.1 @Id
はエンティティ クラスの属性をマップするために使用されます主キーに
2.3.2 @ GeneratedValue
主キー生成戦略を指定します
package javax.persistence;
/**
* 策略类型
*/
public enum GenerationType {
/**
* 通过表产生主键,框架借由表模拟序列产生主键,使用该策略可以使应用更易于数据库移植
*/
TABLE,
/**
* 通过序列产生主键,通过 @SequenceGenerator 注解指定序列名
* MySql 不支持这种方式
* Oracle 支持
*/
SEQUENCE,
/**
* 采用数据库 ID自增长的方式来自增主键字段
* Oracle 不支持这种方式;
*/
IDENTITY,
/**
* 缺省值,JPA 根据数据库自动选择
*/
AUTO;
private GenerationType() {
}
}2.3.3 @SequenceGenerator
2.3.4 @Column
エンティティ クラスの属性名とデータベースの列名が一致しない場合、このアノテーションを使用する必要があります
@Entity
@Table(name="t_users")
public class Users {
@Id
@Column(name = "user_id")
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "user_seq")
@SequenceGenerator(name = "user_seq", sequenceName = "user_seq")
private Long userId;
}2.4 @Transient
現在の属性を使用する必要がないことを示しますデータベースにマッピングされます
2.5 @Temproal
主に日付型属性に使用され、このアノテーション
@Entity
@Table(name="t_users")
public class Users {
@Temporal(TemporalType.DATE)
private Date time1;
@Temporal(TemporalType.TIME)
private Date time2;
@Temporal(TemporalType.TIMESTAMP)
private Date time3;
}3を通じて時間の精度を指定できます。
は Hibernate の SessionFactory4 に似ています。4 種類の EntityManager エンティティ Status
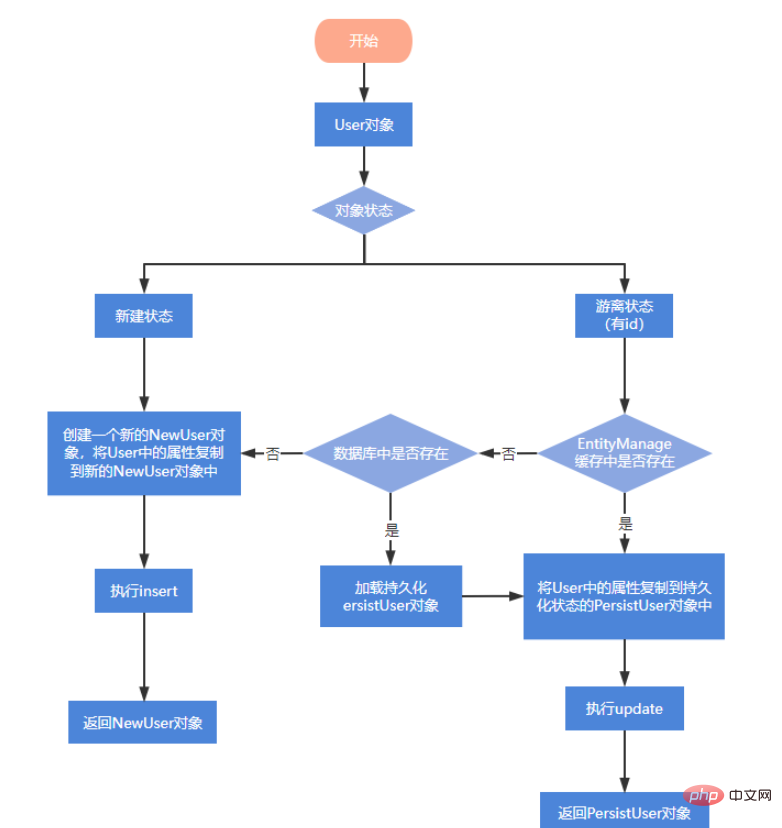
新しいステータス: 新しい作成にはまだありません永続的な主キー 永続ステータス: すでに永続的な主キーがあり、永続性とのコンテキスト関係が確立されています 空き状態: 永続的な主キーがありますが、永続性とのコンテキスト関係がありません 削除状態: 永続的な主キーがあり、永続性とのコンテキスト関係がありますが、データベースから削除されています
4.1 find(ClassentityClass, ObjectprimaryKey)休止状態でのセッションの get() と同様 #find はクエリが見つからない場合に null を返します
4.2 getReference(ClassentityClass, ObjectprimaryKey)
休止状態でのセッションのload()と同様にオブジェクト内の属性が実際に取得された場合のみクエリが実行されます。SQL文のgetReference()はプロキシオブジェクトを返すだけです
##getReference は、クエリされない場合は null を返さず、EntityNotFoundException をスローします。
注: このメソッドを使用すると、遅延読み込み例外が発生する可能性があります。つまり、属性がまだ取得されていないためです。
#4.3persist
注: メソッドの実行時に渡されるオブジェクトは主キー値を設定できないため、例外がスローされます
4.4 削除
注: このメソッドは永続オブジェクトのみを削除できますが、解放オブジェクトは削除できません (休止状態では削除できます)
/**
* 删除游离态(失败)
*/
public void testRemove(){
Users user = new Users();
Users.setUserId(1);
entityManager.remove(customer);
}
/**
* 删除持久化状态(成功)
*/
public void testRemove(){
Users user = entityManager.find(Users.class, 1);
entityManager.remove(user);
}4.5 マージ(T エンティティ)
# // 新建状态
public void testMerge (){
Users user= new Users();
// 省略一系列的set
// user.set.....
Users newUser = entityManager.merge(user);
// user.getUserId() == null ==> true
// newUser.getUserId() == null ==> false
}ログイン後にコピー
// 新建状态
public void testMerge (){
Users user= new Users();
// 省略一系列的set
// user.set.....
Users newUser = entityManager.merge(user);
// user.getUserId() == null ==> true
// newUser.getUserId() == null ==> false
}4.6 flash()
 休止状態のセッションでの flash() と同様
休止状態のセッションでの flash() と同様
#コンテキスト内のすべての未保存エンティティをデータベースに保存します
4.6 fresh() #休止状態のセッションrefresh()と同様すべてのエンティティの属性値を更新します5.EntityTransaction
EntityManager.getTransaction()
#5.1 begin
5.2 commit
5.3 rollback6. マッピング関係
6.1 一方向 one-to -many
ユーザーと注文の関係を例に挙げます。ユーザーには複数の注文があり、1 つの注文は 1 人のユーザーにのみ属します。ペアの場合 複数の関係を挿入する場合、多数の関係を挿入する場合、側または一方の側が最初に挿入されると、多側は挿入中に外部キー列を挿入しないため、追加の更新ステートメントが生成されます。
/**
* 订单和用户是多对一的关系
*/
@Entity
@Table(name="t_order")
public class Order {
// lazy为懒加载,默认为eager立即查询
@ManyToOne(fetch=FetchType.Lazy)
// @JoinColumn标注字段是一个类,userId为该类的主键
@JoinColumn(name="user_id")
private Users user;
}ログイン後にコピーログイン後にコピー
6.2 一方向多対 1 /**
* 订单和用户是多对一的关系
*/
@Entity
@Table(name="t_order")
public class Order {
// lazy为懒加载,默认为eager立即查询
@ManyToOne(fetch=FetchType.Lazy)
// @JoinColumn标注字段是一个类,userId为该类的主键
@JoinColumn(name="user_id")
private Users user;
}ユーザーと注文の関係を例に挙げます。ユーザーには複数の注文があり、注文は 1 人のユーザーにのみ属します多対 1 の関係での挿入の場合、次のようになります。最善から最初に、一人を救う終わり、そして多くの人を救う終わり。
最初に多端を保存し、次に一端を保存する場合、外部キー関係を維持するために、多端で追加の更新操作を実行する必要があります
/**
* 订单和用户是多对一的关系
*/
@Entity
@Table(name="t_order")
public class Order {
// lazy为懒加载,默认为eager立即查询
@ManyToOne(fetch=FetchType.Lazy)
// @JoinColumn标注字段是一个类,userId为该类的主键
@JoinColumn(name="user_id")
private Users user;
}6.3 双方向多対 1
を使用します。ユーザーと注文の関係を例に挙げます。ユーザーには複数の注文があり、注文は 1 人のユーザーにのみ属します。
双方向の多対1 つは、上記 2 つを組み合わせたもので、@OneToMany と @ManyToOne/** * 用户和订单是一对多的关系 */ @Entity @Table(name="t_users") public class User { // 如果两侧都要描述关联关系的话,维护关联关系的任务要交给多的一方 // 使用 @OneToMany 了 mappedBy 的代表不维护关联关系,也就是不会产生额外的update语句 // @OneToMany 和 @JoinColumn 不能同时使用会报错 @OneToMany(mappedBy="user") private Set<Orders> orders; } /** * 订单和用户是多对一的关系 */ @Entity @Table(name="t_orders") public class Order { // lazy为懒加载,默认为eager立即查询 @ManyToOne(fetch=FetchType.Lazy) // @JoinColumn标注字段是一个类,userId为该类的主键 @JoinColumn(name="user_id") private Users user; }ログイン後にコピー
6.4 双向一对一
以学校和校长之间的关系为例,一个学校只有一个校长,一个校长也只属于一个学校
一方使用 @OneToMany + @JoinColumn,另一方使用 @OneToOne(mappedBy=“xx”)
具体由哪一方维护关联关系都可以,这里我们以学校一端维护关联关系为例
保存时先保存不维护关联关系的一方(也就是使用@OneToOne(mappedBy=“xx”)的一方),否则会产生额外的 update 语句
/**
* 学校
*/
@Entity
@Table(name="t_school")
public class School {
// 默认为eager立即查询
@OneToOne
// 添加唯一约束
@JoinColumn(name="school_master_id", unique = true)
private SchoolMaster schoolMaster;
}
/**
* 校长
*/
@Entity
@Table(name="t_school_master")
public class SchoolMaster {
// 不维护关联关系要使用 mappedBy
@OneToOne(mappedBy="schoolMaster")
private School school;
}6.5 双向多对多
以学生和课程之间的关系为例,一个学生可以选多门课,一个课程也有多个学生,多对多需要一个中间表,也就是选课表
维护关联关系的一方需要使用 @JoinTable
关联关系也是只有一方维护即可,这里我们由学生表进行维护
/**
* 学生
*/
@Entity
@Table(name="t_student")
public class Student {
@GeneratedValue
@Id
private Long student_id;
// 要使用 set 集合接收
// 默认为lazy懒加载
@ManyToMany
// name 为中间表的表名
@JoinTable(name="t_student_choose_course",
// name 为与中间表与当前表所关联的字段的名称,referencedColumnName 为当前表中与中间表关联的字段的名称
joinColumns={@JoinColumn(name="student_id", referencedColumnName="student_id")},
// name 为与中间表与多对多另一方表所关联的字段的名称,referencedColumnName 为多对多另一方与中间表关联的字段的名称
inverseJoinColumns={@JoinColumn(name="course_id", referencedColumnName="course_id")})
private Set<Course> courses;
}
/**
* 课程
*/
@Entity
@Table(name="t_course")
public class Course {
@GeneratedValue
@Id
private Long course_id;
// 要使用 set 集合接收
// 默认为lazy懒加载
@ManyToMany(mappedBy="courses")
private Set<Student> students;
}7. 二级缓存
开启了二级缓存之后,缓存是可以跨越 EntityManager 的,
默认是一级缓存也就是在一个 EntityManager 中是有缓存的
二级缓存可以实现,关闭了 EntityManager 之后缓存不会被清除
使用 @Cacheable(true) 开启二级缓存
8. JPQL
8.1 查询接口
8.1.1 createQuery
public void testCreateQuery(){
// 这里我们使用了一个 new Student,因为我们是查询 Student 中的部分属性,如果不适用 new Student 查询返回的结果就不是 Student 类型而是一个 Object[] 类型的 List
// 也可以在实体类中创建对应的构造器,然后使用如下这种 new Student 的方式,来把返回结果封装为Student 对象
String jpql = "SELECT new Student(s.name, s.age) FROM t_student s WHERE s.student_id > ?";
// setParameter 时下标是从1开始的
List result = entityManager.createQuery(jpql).setParameter(1, 1).getResultList();
}8.1.2 createNamedQuery
需要在类上使用 @NamedQuery 注解,事先声明 sql 语句
@NamedQuery(name="testNamedQuery", query="select * from t_student WHERE student_id = ?")
@Entity
@Table(name="t_student")
public class Student {
@GeneratedValue
@Id
private Long student_id;
@Column
private String name;
@Column
private int age;
} public void testCreateNamedQuery(){
Query query = entityManager.createNamedQuery("testNamedQuery").setParameter(1, 3);
Student student = (Student) query.getSingleResult();
}8.1.3 createNativeQuery
public void testCreateNativeQuery(){
// 本地sql的意思是只能在数据库中执行的sql语句
String sql = "SELECT age FROM t_student WHERE student_id = ?";
Query query = entityManager.createNativeQuery(sql).setParameter(1, 18);
Object result = query.getSingleResult();
}8.2 关联查询
存在一对多关系时,当我们查询一的一端时,默认多的一端是懒加载。此时我们如果想要一次性查询出所有的数据就需要使用关联查询
注意: 下面 sql 中的重点就是要加上 fetch u.orders,表示要查询出用户所关联的所有订单
public void testLeftOuterJoinFetch(){
String jpql = "FROM t_users u LEFT OUTER JOIN FETCH u.orders WHERE u.id = ?";
Users user = (Users) entityManager.createQuery(jpql).setParameter(1, 123).getSingleResult();
}以上がSpringBoot JPA共通アノテーションの使用方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7475
7475
 15
1377
52
77
11
19
31
15
1377
52
77
11
19
31

 Springboot が Jasypt を統合して構成ファイルの暗号化を実装する方法
Jun 01, 2023 am 08:55 AM
Springboot が Jasypt を統合して構成ファイルの暗号化を実装する方法
Jun 01, 2023 am 08:55 AM
Jasypt の概要 Jasypt は、開発者が最小限の労力で基本的な暗号化機能を自分のプロジェクトに追加できる Java ライブラリであり、暗号化の仕組みを深く理解する必要はありません。一方向および双方向暗号化の高いセキュリティ。標準ベースの暗号化テクノロジー。パスワード、テキスト、数値、バイナリを暗号化します... Spring ベースのアプリケーション、オープン API への統合、JCE プロバイダーでの使用に適しています... 次の依存関係を追加します: com.github.ulisesbocchiojasypt-spring-boot-starter2. 1.1 Jasypt の特典はシステムのセキュリティを保護し、コードが漏洩した場合でもデータ ソースは保証されます。
 jpa と mybatis ではどちらが優れていますか?
Jan 15, 2024 pm 01:48 PM
jpa と mybatis ではどちらが優れていますか?
Jan 15, 2024 pm 01:48 PM
JPA または MyBatis のどちらを選択するかは、特定のニーズと好みによって異なります。 JPA と MyBatis はどちらも Java 永続層フレームワークであり、Java オブジェクトをデータベース テーブルにマッピングする機能を提供します。クロスデータベース操作をサポートする成熟したフレームワークが必要な場合、またはプロジェクトがすでに永続層ソリューションとして JPA を採用している場合は、JPA を引き続き使用する方が良い選択となる可能性があります。より高いパフォーマンスとより柔軟な SQL 記述機能が必要な場合、またはデータベースへの依存度が低いソリューションを探している場合は、MyBatis の方が適しています。
 Redis を使用して SpringBoot に分散ロックを実装する方法
Jun 03, 2023 am 08:16 AM
Redis を使用して SpringBoot に分散ロックを実装する方法
Jun 03, 2023 am 08:16 AM
1. Redis は分散ロックの原則を実装しており、分散ロックが必要な理由 分散ロックについて話す前に、分散ロックが必要な理由を説明する必要があります。分散ロックの反対はスタンドアロン ロックです。マルチスレッド プログラムを作成するとき、共有変数を同時に操作することによって引き起こされるデータの問題を回避します。通常、ロックを使用して共有変数を相互に除外し、データの正確性を確保します。共有変数の使用範囲は同じプロセス内です。共有リソースを同時に操作する必要があるプロセスが複数ある場合、どうすれば相互排他的になるのでしょうか?今日のビジネス アプリケーションは通常マイクロサービス アーキテクチャであり、これは 1 つのアプリケーションが複数のプロセスをデプロイすることも意味します。複数のプロセスが MySQL の同じレコード行を変更する必要がある場合、順序の乱れた操作によって引き起こされるダーティ データを避けるために、分散が必要です。今回導入するスタイルはロックされています。ポイントを獲得したい
 JPAとMyBatisの機能・性能の比較分析
Feb 19, 2024 pm 05:43 PM
JPAとMyBatisの機能・性能の比較分析
Feb 19, 2024 pm 05:43 PM
JPA と MyBatis: 機能とパフォーマンスの比較分析 はじめに: Java 開発では、永続化フレームワークが非常に重要な役割を果たします。一般的な永続化フレームワークには、JPA (JavaPersistenceAPI) や MyBatis などがあります。この記事では、2 つのフレームワークの機能とパフォーマンスを比較分析し、具体的なコード例を示します。 1. 機能の比較: JPA: JPA は JavaEE の一部であり、オブジェクト指向のデータ永続化ソリューションを提供します。アノテーションまたはXが渡されます
 Springbootがjarパッケージにファイルを読み込んだ後にファイルにアクセスできない問題を解決する方法
Jun 03, 2023 pm 04:38 PM
Springbootがjarパッケージにファイルを読み込んだ後にファイルにアクセスできない問題を解決する方法
Jun 03, 2023 pm 04:38 PM
Springboot はファイルを読み取りますが、jar パッケージにパッケージ化した後、最新の開発にアクセスできません。jar パッケージにパッケージ化した後、Springboot がファイルを読み取れない状況があります。その理由は、パッケージ化後、ファイルの仮想パスが変更されるためです。は無効であり、ストリーム経由でのみアクセスできます。読み取ります。ファイルはリソースの下にあります publicvoidtest(){Listnames=newArrayList();InputStreamReaderread=null;try{ClassPathResourceresource=newClassPathResource("name.txt");Input
 SpringBootとSpringMVCの比較と差異分析
Dec 29, 2023 am 11:02 AM
SpringBootとSpringMVCの比較と差異分析
Dec 29, 2023 am 11:02 AM
SpringBoot と SpringMVC はどちらも Java 開発で一般的に使用されるフレームワークですが、それらの間には明らかな違いがいくつかあります。この記事では、これら 2 つのフレームワークの機能と使用法を調べ、その違いを比較します。まず、SpringBoot について学びましょう。 SpringBoot は、Spring フレームワークに基づいたアプリケーションの作成と展開を簡素化するために、Pivotal チームによって開発されました。スタンドアロンの実行可能ファイルを構築するための高速かつ軽量な方法を提供します。
 SQL ステートメントを使用せずに Springboot+Mybatis-plus を実装して複数のテーブルを追加する方法
Jun 02, 2023 am 11:07 AM
SQL ステートメントを使用せずに Springboot+Mybatis-plus を実装して複数のテーブルを追加する方法
Jun 02, 2023 am 11:07 AM
Springboot+Mybatis-plus が SQL ステートメントを使用して複数テーブルの追加操作を実行しない場合、私が遭遇した問題は、テスト環境で思考をシミュレートすることによって分解されます: パラメーターを含む BrandDTO オブジェクトを作成し、パラメーターをバックグラウンドに渡すことをシミュレートします。 Mybatis-plus で複数テーブルの操作を実行するのは非常に難しいことを理解してください。Mybatis-plus-join などのツールを使用しない場合は、対応する Mapper.xml ファイルを設定し、臭くて長い ResultMap を設定するだけです。対応する SQL ステートメントを記述します。この方法は面倒に見えますが、柔軟性が高く、次のことが可能です。
 SpringBoot が Redis をカスタマイズしてキャッシュのシリアル化を実装する方法
Jun 03, 2023 am 11:32 AM
SpringBoot が Redis をカスタマイズしてキャッシュのシリアル化を実装する方法
Jun 03, 2023 am 11:32 AM
1. RedisAPI のデフォルトのシリアル化メカニズムである RedisTemplate1.1 をカスタマイズします。API ベースの Redis キャッシュ実装では、データ キャッシュ操作に RedisTemplate テンプレートを使用します。ここで、RedisTemplate クラスを開いて、クラスのソース コード情報を表示します。publicclassRedisTemplateextendsRedisAccessorimplementsRedisOperations、BeanClassLoaderAware{//キーを宣言、値の各種シリアル化メソッド、初期値は空 @NullableprivateRedisSe
