

Python と Excel の完璧な組み合わせ: よくある操作のまとめ (詳細な事例分析)


本文
かつて経営分析に相当する英語はBusiness Analysis、誰もが使っていた分析ツールはExcelでしたが、その後データ量が増加しました。が発生し、Excel では処理できなくなったため (Excel でサポートされる最大行数は 1,048,576 行)、人々は Python や R などの分析ツールに注目し始めました。
実際、Python と Excel の使用ガイドラインは同じであり、[繰り返しません] であり、機械的な操作と純粋な手作業を可能な限りより便利な操作に置き換えることです。 。
データ分析に Python を使用することは、有名な pandas パッケージから切り離せません。多くのバージョンの反復最適化を経て、現在の pandas エコシステムは完全に完成しました。公式 Web サイトには、他の分析ツールとの比較も掲載されています。:

この記事では主に pandas を使用しており、描画に使用するライブラリは plotly を使用しています。実装されている Excel の共通機能は次のとおりです。
- Python と Excelインタラクション
- vlookup関数
- ピボットテーブル
- 図面
今後Excelの機能をさらに発見したら、また戻ってきて続けます更新して補充します。開始する前に、まず通常どおり pandas パッケージを読み込みます。
import numpy as np
import pandas as pd
pd.set_option('max_columns', 10)
pd.set_option('max_rows', 20)
pd.set_option('display.float_format', lambda x: '%.2f' % x) # 禁用科学计数法Python と Excel の相互作用
pandas の Excel I/O に関連して最もよく使用される 4 つの関数は、read_csv/ read_excel/ to_csv/ です。 to_excel、それらはすべて、目的の読み取りとエクスポート効果をカスタマイズするための特定のパラメーター設定を持っています。
たとえば、このようなテーブルの左上部分を読み取りたい場合:
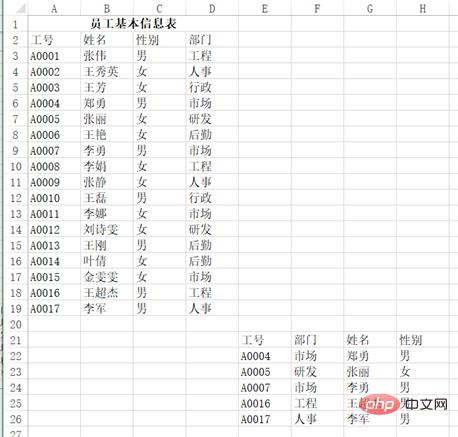
pd.read_excel("test.xlsx") を使用できます。 、 header=1 、 nrows=17、 usecols=3)、戻り結果:
df Out[]: 工号 姓名 性别部门 0 A0001 张伟男工程 1 A0002王秀英女人事 2 A0003 王芳女行政 3 A0004 郑勇男市场 4 A0005 张丽女研发 5 A0006 王艳女后勤 6 A0007 李勇男市场 7 A0008 李娟女工程 8 A0009 张静女人事 9 A0010 王磊男行政 10A0011 李娜女市场 11A0012刘诗雯女研发 12A0013 王刚男后勤 13A0014 叶倩女后勤 14A0015金雯雯女市场 15A0016王超杰男工程 16A0017 李军男人事
同じことが出力関数にも当てはまります。使用する列の数、インデックスを作成するかどうか、および配置方法を制御できます。タイトル。
vlookup 関数
vlookup は Excel のアーティファクトの 1 つとして知られており、幅広い用途に使用されています。次の例は Douban からのものです。VLOOKUP 関数の最も一般的に使用される 10 の使用例。あなたはいくつ知っていますか?
ケース 1
質問: セル領域 A3:B7 は文字グレード参照テーブルで、60 未満のスコアがグレード E、60 ~ 69 がグレード D であることを示しています。 、70~79がCグレード、80~89がBグレード、90以上がAグレードとなります。 D:G は、1 級 2 級の中国語テストのスコア表にリストされています。中国語のスコアに基づいて文字のグレードを返すにはどうすればよいですか?
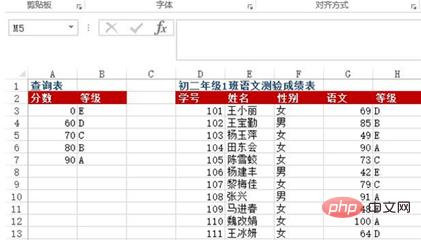
方法: H3:H13 セル領域に =VLOOKUP(G3, $A$3:$B$7, 2) を入力します。
Python 実装:
df = pd.read_excel("test.xlsx", sheet_name=0)
def grade_to_point(x):
if x >= 90:
return 'A'
elif x >= 80:
return 'B'
elif x >= 70:
return 'C'
elif x >= 60:
return 'D'
else:
return 'E'
df['等级'] = df['语文'].apply(grade_to_point)
df
Out[]:
学号 姓名 性别 语文 等级
0 101王小丽女 69D
1 102王宝勤男 85B
2 103杨玉萍女 49E
3 104田东会女 90A
4 105陈雪蛟女 73C
5 106杨建丰男 42E
6 107黎梅佳女 79C
7 108 张兴 男 91A
8 109马进春女 48E
9 110魏改娟女100A
10111王冰研女 64Dケース 2
質問: Sheet1 の減価償却詳細表の対応する番号の下にある月次減価償却額を見つけるにはどうすればよいですか? (クロステーブルクエリ)。


df1 = pd.read_excel("test.xlsx", sheet_name='折旧明细表')
df2 = pd.read_excel("test.xlsx", sheet_name=1) #题目里的sheet1
df2.merge(df1[['编号', '月折旧额']], how='left', on='编号')
Out[]:
编号 资产名称月折旧额
0YT001电动门 1399
1YT005桑塔纳轿车1147
2YT008打印机51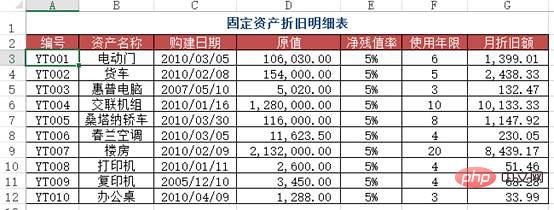
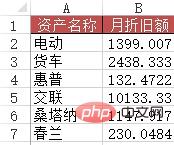 #方法: B2:B7 領域に数式 =VLOOKUP(A2&"*", 減価償却スケジュール!$B$2:) を入力します。 :$G$12、6、0)。
#方法: B2:B7 領域に数式 =VLOOKUP(A2&"*", 減価償却スケジュール!$B$2:) を入力します。 :$G$12、6、0)。
Python 実装: これは前の実装よりも面倒で、パンダの使用スキルが必要です。
df1 = pd.read_excel("test.xlsx", sheet_name='折旧明细表')
df3 = pd.read_excel("test.xlsx", sheet_name=3) #含有资产名称简写的表
df3['月折旧额'] = 0
for i in range(len(df3['资产名称'])):
df3['月折旧额'][i] = df1[df1['资产名称'].map(lambda x:df3['资产名称'][i] in x)]['月折旧额']
df3
Out[]:
资产名称 月折旧额
0 电动 1399
1 货车 2438
2 惠普132
3 交联10133
4桑塔纳 1147
5 春兰230ケース 4
問題: Excel にデータ情報を入力する際、作業効率を向上させるために、データのキーワードを入力することでレコードの残りの情報を自動的に表示したいと考えています。 , 例えば、従業員の役職番号を入力すると従業員名が自動的に表示され、材料番号を入力すると材料の製品名や単価などが自動的に表示されます。
図は、ある部署の全従業員の基本情報のデータソース表ですが、ワークシート「2010年3月度の従業員休暇統計表」において、A列に従業員番号を入力すると、 、従業員の名前、ID 番号、部門、役職、入社日、その他の情報の対応する自動入力を実現するにはどうすればよいですか?さらに、パブリック アカウント Linux を検索して、バックグラウンドで「git Books」と返信する方法を学び、サプライズ ギフト パッケージを入手してください。
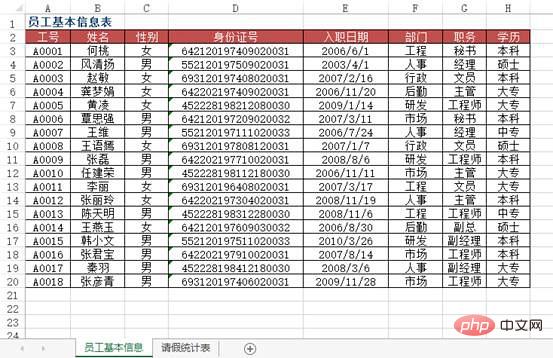
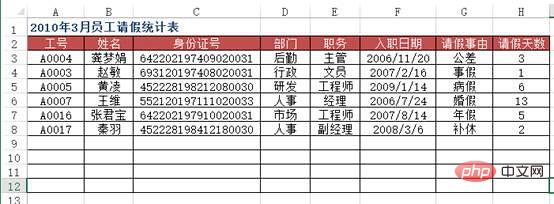
方法:使用VLOOKUP+MATCH函数,在“2010年3月员工请假统计表”工作表中选择B3:F8单元格区域,输入下列公式=IF($A3="","",VLOOKUP($A3,员工基本信息!$A:$H,MATCH(B$2,员工基本信息!$2:$2,0),0)),按下【Ctrl+Enter】组合键结束。
python实现:上面的Excel的方法用得很灵活,但是pandas的想法和操作更简单方便些。
df4 = pd.read_excel("test.xlsx", sheet_name='员工基本信息表')
df5 = pd.read_excel("test.xlsx", sheet_name='请假统计表')
df5.merge(df4[['工号', '姓名', '部门', '职务', '入职日期']], on='工号')
Out[]:
工号 姓名部门 职务 入职日期
0A0004龚梦娟后勤 主管 2006-11-20
1A0003 赵敏行政 文员 2007-02-16
2A0005 黄凌研发工程师 2009-01-14
3A0007 王维人事 经理 2006-07-24
4A0016张君宝市场工程师 2007-08-14
5A0017 秦羽人事副经理 2008-03-06案例五
问题:用VLOOKUP函数实现批量查找,VLOOKUP函数一般情况下只能查找一个,那么多项应该怎么查找呢?如下图,如何把张一的消费额全部列出?
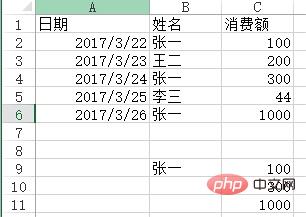
方法:在C9:C11单元格里面输入公式=VLOOKUP(B$9&ROW(A1),IF({1,0},$B$2:$B$6&COUNTIF(INDIRECT("b2:b"&ROW($2:$6)),B$9),$C$2:$C$6),2,),按SHIFT+CTRL+ENTER键结束。
python实现:vlookup函数有两个不足(或者算是特点吧),一个是被查找的值一定要在区域里的第一列,另一个是只能查找一个值,剩余的即便能匹配也不去查找了,这两点都能通过灵活应用if和indirect函数来解决,不过pandas能做得更直白一些。
df6 = pd.read_excel("test.xlsx", sheet_name='消费额')
df6[df6['姓名'] == '张一'][['姓名', '消费额']]
Out[]:
姓名 消费额
0张一 100
2张一 300
4张一1000数据透视表
数据透视表是Excel的另一个神器,本质上是一系列的表格重组整合的过程。这里用的案例来自知乎,Excel数据透视表有什么用途:(https://www.zhihu.com/question/22484899/answer/39933218 )
问题:需要汇总各个区域,每个月的销售额与成本总计,并同时算出利润。
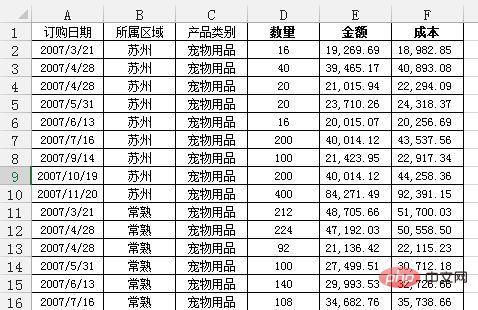
通过Excel的数据透视表的操作最终实现了下面这样的效果:
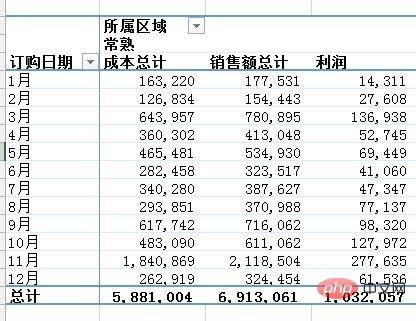
python实现:对于这样的分组的任务,首先想到的就是pandas的groupby,代码写起来也简单,思路就是把刚才Excel的点鼠标的操作反映到代码命令上:
df = pd.read_excel('test.xlsx', sheet_name='销售统计表')
df['订购月份'] = df['订购日期'].apply(lambda x:x.month)
df2 = df.groupby(['订购月份', '所属区域'])[['销售额', '成本']].agg('sum')
df2['利润'] = df2['销售额'] - df2['成本']
df2
Out[]:
销售额 成本利润
订购月份 所属区域
1南京134313.61 94967.8439345.77
常熟177531.47163220.0714311.40
无锡316418.09231822.2884595.81
昆山159183.35145403.3213780.03
苏州287253.99238812.0348441.96
2南京187129.13138530.4248598.71
常熟154442.74126834.3727608.37
无锡464012.20376134.9887877.22
昆山102324.46 86244.5216079.94
苏州105940.34 91419.5414520.80
...... ...
11 南京286329.88221687.1164642.77
常熟 2118503.54 1840868.53 277635.01
无锡633915.41536866.7797048.64
昆山351023.24342420.18 8603.06
苏州 1269351.39 1144809.83 124541.56
12 南京894522.06808959.3285562.74
常熟324454.49262918.8161535.68
无锡 1040127.19856816.72 183310.48
昆山 1096212.75951652.87 144559.87
苏州347939.30302154.2545785.05
[60 rows x 3 columns]也可以使用pandas里的pivot_table函数来实现:
df3 = pd.pivot_table(df, values=['销售额', '成本'], index=['订购月份', '所属区域'] , aggfunc='sum') df3['利润'] = df3['销售额'] - df3['成本'] df3 Out[]: 成本销售额利润 订购月份 所属区域 1南京 94967.84134313.6139345.77 常熟163220.07177531.4714311.40 无锡231822.28316418.0984595.81 昆山145403.32159183.3513780.03 苏州238812.03287253.9948441.96 2南京138530.42187129.1348598.71 常熟126834.37154442.7427608.37 无锡376134.98464012.2087877.22 昆山 86244.52102324.4616079.94 苏州 91419.54105940.3414520.80 ...... ... 11 南京221687.11286329.8864642.77 常熟 1840868.53 2118503.54 277635.01 无锡536866.77633915.4197048.64 昆山342420.18351023.24 8603.06 苏州 1144809.83 1269351.39 124541.56 12 南京808959.32894522.0685562.74 常熟262918.81324454.4961535.68 无锡856816.72 1040127.19 183310.48 昆山951652.87 1096212.75 144559.87 苏州302154.25347939.3045785.05 [60 rows x 3 columns]
pandas的pivot_table的参数index/ columns/ values和Excel里的参数是对应上的(当然,我这话说了等于没说,数据透视表里不就是行/列/值吗还能有啥。)
但是我个人还是更喜欢用groupby,因为它运算速度非常快。我在打kaggle比赛的时候,有一张表是贷款人的行为信息,大概有2700万行,用groupby算了几个聚合函数,几秒钟就完成了。
groupby的功能很全面,内置了很多aggregate函数,能够满足大部分的基本需求,如果你需要一些其他的函数,可以搭配使用apply和lambda。
不过pandas的官方文档说了,groupby之后用apply速度非常慢,aggregate内部做过优化,所以很快,apply是没有优化的,所以建议有问题先想想别的方法,实在不行的时候再用apply。
我打比赛的时候,为了生成一个新变量,用了groupby的apply,写了这么一句:ins['weight'] = ins[['SK_ID_PREV', 'DAYS_ENTRY_PAYMENT']].groupby('SK_ID_PREV').apply(lambda x: 1-abs(x)/x.sum().abs()).iloc[:,1],1000万行的数据,足足算了十多分钟,等得我心力交瘁。
绘图
因为Excel画出来的图能够交互,能够在图上进行一些简单操作,所以这里用的python的可视化库是plotly,案例就用我这个学期发展经济学课上的作业吧,当时的图都是用Excel画的,现在用python再画一遍。开始之前,首先加载plotly包。
import plotly.offline as off import plotly.graph_objs as go off.init_notebook_mode()
柱状图
当时用Excel画了很多的柱状图,其中的一幅图是:
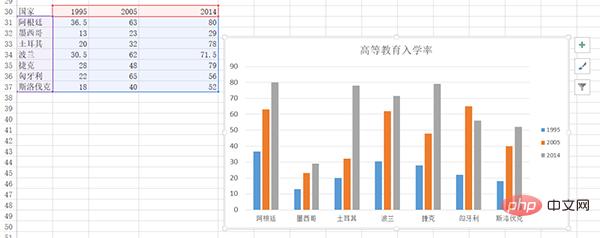
下面用plotly来画一下:
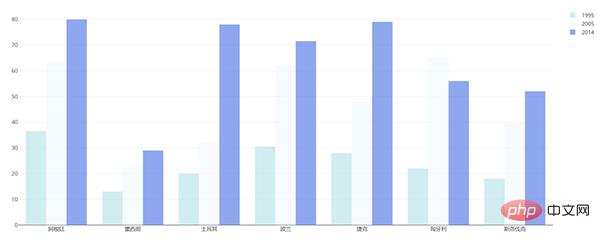
df = pd.read_excel("plot.xlsx", sheet_name='高等教育入学率')
trace1 = go.Bar(
x=df['国家'],
y=df[1995],
name='1995',
opacity=0.6,
marker=dict(
color='powderblue'
)
)
trace2 = go.Bar(
x=df['国家'],
y=df[2005],
name='2005',
opacity=0.6,
marker=dict(
color='aliceblue',
)
)
trace3 = go.Bar(
x=df['国家'],
y=df[2014],
name='2014',
opacity=0.6,
marker=dict(
color='royalblue'
)
)
layout = go.Layout(barmode='group')
data = [trace1, trace2, trace3]
fig = go.Figure(data, layout)
off.plot(fig)雷达图
用Excel画的:
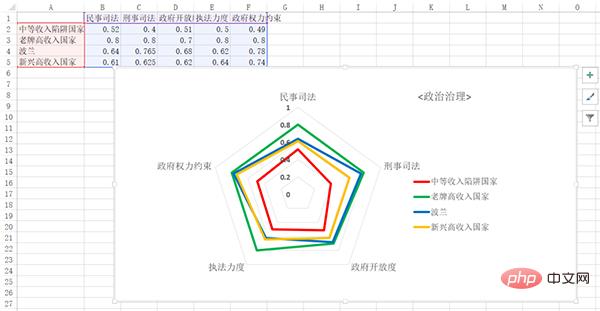
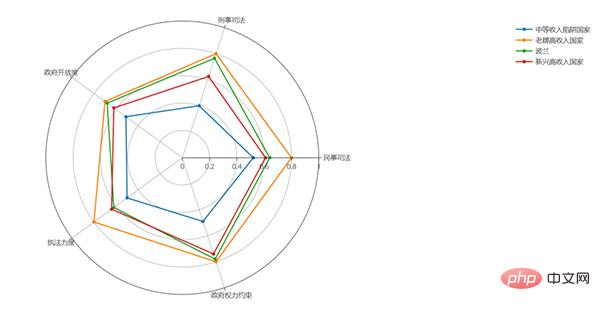
用python画的:
df = pd.read_excel('plot.xlsx', sheet_name='政治治理')
theta = df.columns.tolist()
theta.append(theta[0])
names = df.index
df[''] = df.iloc[:,0]
df = np.array(df)
trace1 = go.Scatterpolar(
r=df[0],
theta=theta,
name=names[0]
)
trace2 = go.Scatterpolar(
r=df[1],
theta=theta,
name=names[1]
)
trace3 = go.Scatterpolar(
r=df[2],
theta=theta,
name=names[2]
)
trace4 = go.Scatterpolar(
r=df[3],
theta=theta,
name=names[3]
)
data = [trace1, trace2, trace3, trace4]
layout = go.Layout(
polar=dict(
radialaxis=dict(
visible=True,
range=[0,1]
)
),
showlegend=True
)
fig = go.Figure(data, layout)
off.plot(fig)画起来比Excel要麻烦得多。
总体而言,如果画简单基本的图形,用Excel是最方便的,如果要画高级一些的或者是需要更多定制化的图形,使用python更合适。
以上がPython と Excel の完璧な組み合わせ: よくある操作のまとめ (詳細な事例分析)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7526
7526
 15
1378
52
81
11
21
74
15
1378
52
81
11
21
74

 Python:ゲーム、GUIなど
Apr 13, 2025 am 12:14 AM
Python:ゲーム、GUIなど
Apr 13, 2025 am 12:14 AM
PythonはゲームとGUI開発に優れています。 1)ゲーム開発は、2Dゲームの作成に適した図面、オーディオ、その他の機能を提供し、Pygameを使用します。 2)GUI開発は、TKINTERまたはPYQTを選択できます。 TKINTERはシンプルで使いやすく、PYQTは豊富な機能を備えており、専門能力開発に適しています。
 PHPとPython:2つの一般的なプログラミング言語を比較します
Apr 14, 2025 am 12:13 AM
PHPとPython:2つの一般的なプログラミング言語を比較します
Apr 14, 2025 am 12:13 AM
PHPとPythonにはそれぞれ独自の利点があり、プロジェクトの要件に従って選択します。 1.PHPは、特にWebサイトの迅速な開発とメンテナンスに適しています。 2。Pythonは、データサイエンス、機械学習、人工知能に適しており、簡潔な構文を備えており、初心者に適しています。
 Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
DebianシステムのReadDir関数は、ディレクトリコンテンツの読み取りに使用されるシステムコールであり、Cプログラミングでよく使用されます。この記事では、ReadDirを他のツールと統合して機能を強化する方法について説明します。方法1:C言語プログラムを最初にパイプラインと組み合わせて、cプログラムを作成してreaddir関数を呼び出して結果をinclude#include#include inctargc、char*argv []){dir*dir; structdireant*entry; if(argc!= 2){(argc!= 2){
 Pythonと時間:勉強時間を最大限に活用する
Apr 14, 2025 am 12:02 AM
Pythonと時間:勉強時間を最大限に活用する
Apr 14, 2025 am 12:02 AM
限られた時間でPythonの学習効率を最大化するには、PythonのDateTime、時間、およびスケジュールモジュールを使用できます。 1. DateTimeモジュールは、学習時間を記録および計画するために使用されます。 2。時間モジュールは、勉強と休息の時間を設定するのに役立ちます。 3.スケジュールモジュールは、毎週の学習タスクを自動的に配置します。
 Nginx SSL証明書更新Debianチュートリアル
Apr 13, 2025 am 07:21 AM
Nginx SSL証明書更新Debianチュートリアル
Apr 13, 2025 am 07:21 AM
この記事では、DebianシステムでNGINXSSL証明書を更新する方法について説明します。ステップ1:最初にCERTBOTをインストールして、システムがCERTBOTおよびPython3-Certbot-Nginxパッケージがインストールされていることを確認してください。インストールされていない場合は、次のコマンドを実行してください。sudoapt-getupdatesudoapt-getinstolcallcertbotthon3-certbot-nginxステップ2:certbotコマンドを取得して構成してlet'sencrypt証明書を取得し、let'sencryptコマンドを取得し、nginx:sudocertbot - nginxを構成します。
 debian opensslでHTTPSサーバーを構成する方法
Apr 13, 2025 am 11:03 AM
debian opensslでHTTPSサーバーを構成する方法
Apr 13, 2025 am 11:03 AM
DebianシステムでHTTPSサーバーの構成には、必要なソフトウェアのインストール、SSL証明書の生成、SSL証明書を使用するWebサーバー(ApacheやNginxなど)の構成など、いくつかのステップが含まれます。 Apachewebサーバーを使用していると仮定して、基本的なガイドです。 1.最初に必要なソフトウェアをインストールし、システムが最新であることを確認し、ApacheとOpenSSL:sudoaptupdatesudoaptupgraysudoaptinstaをインストールしてください
 DebianのGitlabのプラグイン開発ガイド
Apr 13, 2025 am 08:24 AM
DebianのGitlabのプラグイン開発ガイド
Apr 13, 2025 am 08:24 AM
DebianでGitLabプラグインを開発するには、特定の手順と知識が必要です。このプロセスを始めるのに役立つ基本的なガイドを以下に示します。最初にgitlabをインストールすると、debianシステムにgitlabをインストールする必要があります。 GitLabの公式インストールマニュアルを参照できます。 API統合を実行する前に、APIアクセストークンを取得すると、GitLabのAPIアクセストークンを最初に取得する必要があります。 gitlabダッシュボードを開き、ユーザー設定で「アクセストーケン」オプションを見つけ、新しいアクセストークンを生成します。生成されます
 Apacheとは何ですか
Apr 13, 2025 pm 12:06 PM
Apacheとは何ですか
Apr 13, 2025 pm 12:06 PM
アパッチはインターネットの背後にあるヒーローです。それはWebサーバーであるだけでなく、膨大なトラフィックをサポートし、動的なコンテンツを提供する強力なプラットフォームでもあります。モジュラー設計を通じて非常に高い柔軟性を提供し、必要に応じてさまざまな機能を拡張できるようにします。ただし、モジュール性は、慎重な管理を必要とする構成とパフォーマンスの課題も提示します。 Apacheは、高度にカスタマイズ可能で複雑なニーズを満たす必要があるサーバーシナリオに適しています。
