

SpringBoot 統合ローカル キャッシュ パフォーマンスのカフェイン インスタンス分析

引言
使用缓存的目的就是提高性能,今天码哥带大家实践运用 spring-boot-starter-cache 抽象的缓存组件去集成本地缓存性能之王 Caffeine。
大家需要注意的是:in-memeory 缓存只适合在单体应用,不适合与分布式环境。
分布式环境的情况下需要将缓存修改同步到每个节点,需要一个同步机制保证每个节点缓存数据最终一致。
Spring Cache 是什么
不使用 Spring Cache 抽象的缓存接口,我们需要根据不同的缓存框架去实现缓存,需要在对应的代码里面去对应缓存加载、删除、更新等。
比如查询我们使用旁路缓存策略:先从缓存中查询数据,如果查不到则从数据库查询并写到缓存中。
伪代码如下:
public User getUser(long userId) {
// 从缓存查询
User user = cache.get(userId);
if (user != null) {
return user;
}
// 从数据库加载
User dbUser = loadDataFromDB(userId);
if (dbUser != null) {
// 设置到缓存中
cache.put(userId, dbUser)
}
return dbUser;
}我们需要写大量的这种繁琐代码,Spring Cache 则对缓存进行了抽象,提供了如下几个注解实现了缓存管理:
@Cacheable:触发缓存读取操作,用于查询方法上,如果缓存中找到则直接取出缓存并返回,否则执行目标方法并将结果缓存。
@CachePut:触发缓存更新的方法上,与 Cacheable 相比,该注解的方法始终都会被执行,并且使用方法返回的结果去更新缓存,适用于 insert 和 update 行为的方法上。
@CacheEvict:触发缓存失效,删除缓存项或者清空缓存,适用于 delete 方法上。
除此之外,抽象的 CacheManager 既能集成基于本地内存的单体应用,也能集成 EhCache、Redis 等缓存服务器。
最方便的是通过一些简单配置和注解就能接入不同的缓存框架,无需修改任何代码。
集成 Caffeine
码哥带大家使用注解方式完成缓存操作的方式来集成,完整的代码请访问 github:在 pom.xml 文件添加如下依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
</dependency>使用 JavaConfig 方式配置 CacheManager:
@Slf4j
@EnableCaching
@Configuration
public class CacheConfig {
@Autowired
@Qualifier("cacheExecutor")
private Executor cacheExecutor;
@Bean
public Caffeine<Object, Object> caffeineCache() {
return Caffeine.newBuilder()
// 设置最后一次写入或访问后经过固定时间过期
.expireAfterAccess(7, TimeUnit.DAYS)
// 初始的缓存空间大小
.initialCapacity(500)
// 使用自定义线程池
.executor(cacheExecutor)
.removalListener(((key, value, cause) -> log.info("key:{} removed, removalCause:{}.", key, cause.name())))
// 缓存的最大条数
.maximumSize(1000);
}
@Bean
public CacheManager cacheManager() {
CaffeineCacheManager caffeineCacheManager = new CaffeineCacheManager();
caffeineCacheManager.setCaffeine(caffeineCache());
// 不缓存空值
caffeineCacheManager.setAllowNullValues(false);
return caffeineCacheManager;
}
}准备工作搞定,接下来就是如何使用了。
@Slf4j
@Service
public class AddressService {
public static final String CACHE_NAME = "caffeine:address";
private static final AtomicLong ID_CREATOR = new AtomicLong(0);
private Map<Long, AddressDTO> addressMap;
public AddressService() {
addressMap = new ConcurrentHashMap<>();
addressMap.put(ID_CREATOR.incrementAndGet(), AddressDTO.builder().customerId(ID_CREATOR.get()).address("地址1").build());
addressMap.put(ID_CREATOR.incrementAndGet(), AddressDTO.builder().customerId(ID_CREATOR.get()).address("地址2").build());
addressMap.put(ID_CREATOR.incrementAndGet(), AddressDTO.builder().customerId(ID_CREATOR.get()).address("地址3").build());
}
@Cacheable(cacheNames = {CACHE_NAME}, key = "#customerId")
public AddressDTO getAddress(long customerId) {
log.info("customerId:{} 没有走缓存,开始从数据库查询", customerId);
return addressMap.get(customerId);
}
@CachePut(cacheNames = {CACHE_NAME}, key = "#result.customerId")
public AddressDTO create(String address) {
long customerId = ID_CREATOR.incrementAndGet();
AddressDTO addressDTO = AddressDTO.builder().customerId(customerId).address(address).build();
addressMap.put(customerId, addressDTO);
return addressDTO;
}
@CachePut(cacheNames = {CACHE_NAME}, key = "#result.customerId")
public AddressDTO update(Long customerId, String address) {
AddressDTO addressDTO = addressMap.get(customerId);
if (addressDTO == null) {
throw new RuntimeException("没有 customerId = " + customerId + "的地址");
}
addressDTO.setAddress(address);
return addressDTO;
}
@CacheEvict(cacheNames = {CACHE_NAME}, key = "#customerId")
public boolean delete(long customerId) {
log.info("缓存 {} 被删除", customerId);
return true;
}
}使用 CacheName 隔离不同业务场景的缓存,每个 Cache 内部持有一个 map 结构存储数据,key 可用使用 Spring 的 Spel 表达式。
单元测试走起:
@RunWith(SpringRunner.class)
@SpringBootTest(classes = CaffeineApplication.class)
@Slf4j
public class CaffeineApplicationTests {
@Autowired
private AddressService addressService;
@Autowired
private CacheManager cacheManager;
@Test
public void testCache() {
// 插入缓存 和数据库
AddressDTO newInsert = addressService.create("南山大道");
// 要走缓存
AddressDTO address = addressService.getAddress(newInsert.getCustomerId());
long customerId = 2;
// 第一次未命中缓存,打印 customerId:{} 没有走缓存,开始从数据库查询
AddressDTO address2 = addressService.getAddress(customerId);
// 命中缓存
AddressDTO cacheAddress2 = addressService.getAddress(customerId);
// 更新数据库和缓存
addressService.update(customerId, "地址 2 被修改");
// 更新后查询,依然命中缓存
AddressDTO hitCache2 = addressService.getAddress(customerId);
Assert.assertEquals(hitCache2.getAddress(), "地址 2 被修改");
// 删除缓存
addressService.delete(customerId);
// 未命中缓存, 从数据库读取
AddressDTO hit = addressService.getAddress(customerId);
System.out.println(hit.getCustomerId());
}
}大家发现没,只需要在对应的方法上加上注解,就能愉快的使用缓存了。需要注意的是, 设置的 cacheNames 一定要对应,每个业务场景使用对应的 cacheNames。
另外 key 可以使用 spel 表达式,大家重点可以关注 @CachePut(cacheNames = {CACHE_NAME}, key = "#result.customerId"),result 表示接口返回结果,Spring 提供了几个元数据直接使用。
| 名称 | 地点 | 描述 | 例子 |
|---|---|---|---|
| methodName | 根对象 | 被调用的方法的名称 | #root.methodName |
| method | 根对象 | 被调用的方法 | #root.method.name |
| target | 根对象 | 被调用的目标对象 | #root.target |
| targetClass | 根对象 | 被调用的目标的类 | #root.targetClass |
| args | 根对象 | 用于调用目标的参数(作为数组) | #root.args[0] |
| caches | 根对象 | 运行当前方法的缓存集合 | #root.caches[0].name |
| 参数名称 | 评估上下文 | 任何方法参数的名称。如果名称不可用(可能是由于没有调试信息),则参数名称也可在#a where#arg代表参数索引(从 开始0)下获得。 | #iban或#a0(您也可以使用#p0或#p表示法作为别名)。 |
| result | 评估上下文 | 方法调用的结果(要缓存的值)。仅在unless 表达式、cache put表达式(计算key)或cache evict 表达式(when beforeInvocationis false)中可用。对于支持的包装器(例如 Optional),#result指的是实际对象,而不是包装器。 | #result |
コア原則
Java キャッシュは、CachingProvider、CacheManager、Cache、Entry、および Expiry という 5 つのコア インターフェイスを定義します。
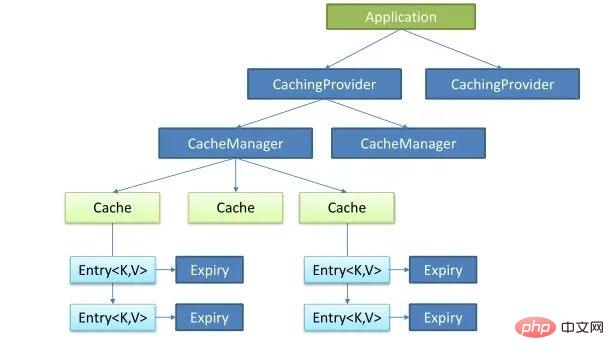
# コア クラス図:
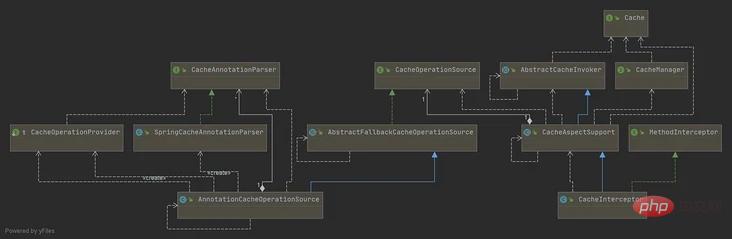
- ##キャッシュ: get( などのキャッシュ操作を抽象化します。 ), put();
- CacheManager: Cache を管理します。これは Cache のコレクション管理として理解できます。Cache が複数ある理由は、異なるキャッシュに応じて異なるキャッシュを使用できるためです。有効期限と数量制限。
- CacheInterceptor、CacheAspectSupport、AbstractCacheInvoker: CacheInterceptor は、メソッドの前後で追加のロジック (クエリ操作など) を実行する AOP メソッド インターセプターであり、最初にキャッシュを確認し、問題があればメソッドを実行します。これは、CacheAspectSupport (キャッシュ操作のメイン ロジック) と AbstractCacheInvoker (キャッシュの読み取りと書き込みをカプセル化する) を継承します。
- CacheOperation、AnnotationCacheOperationSource、SpringCacheAnnotationParser: CacheOperationはキャッシュ操作のキャッシュ名、キャッシュキー、キャッシュ条件、CacheManagerなどを定義する AnnotationCacheOperationSourceは、に対応するキャッシュアノテーションを取得するクラスです。 CacheOperation、SpringCacheAnnotationParser アノテーションを解析するクラスで、解析後はAnnotationCacheOperationSourceが検索できるようにCacheOperationコレクションにカプセル化されます。
- CacheOperationSource を通じてすべての CacheOperation リストを取得します。
- @CacheEvict アノテーションがあり、マーク 呼び出す前に実行するには、キャッシュを削除/クリアします。
- @Cacheable アノテーションがある場合は、キャッシュをクエリします。
- キャッシュが見つからない場合は (クエリ結果は null)、cachePutRequests に追加され、その後の実行後に元のメソッドがキャッシュに書き込まれます。
- キャッシュがヒットすると、キャッシュ値が次のように使用されます。結果; キャッシュがミスするか、 @CachePut アノテーションが付けられている場合は、元のメソッドを呼び出し、元のメソッドの戻り値を結果として使用する必要があります。 @CachePut アノテーションを、cachePutRequests に追加します。
- キャッシュがミスした場合は、クエリ結果の値がキャッシュに書き込まれます。@CachePut アノテーションがある場合は、メソッドの実行結果も書き込まれます。キャッシュに
- @CacheEvict アノテーションがあり、呼び出し後に実行するようにマークされている場合は、キャッシュを削除/クリアします
以上がSpringBoot 統合ローカル キャッシュ パフォーマンスのカフェイン インスタンス分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7569
7569
 15
1386
52
87
11
28
107
15
1386
52
87
11
28
107

 Springboot が Jasypt を統合して構成ファイルの暗号化を実装する方法
Jun 01, 2023 am 08:55 AM
Springboot が Jasypt を統合して構成ファイルの暗号化を実装する方法
Jun 01, 2023 am 08:55 AM
Jasypt の概要 Jasypt は、開発者が最小限の労力で基本的な暗号化機能を自分のプロジェクトに追加できる Java ライブラリであり、暗号化の仕組みを深く理解する必要はありません。一方向および双方向暗号化の高いセキュリティ。標準ベースの暗号化テクノロジー。パスワード、テキスト、数値、バイナリを暗号化します... Spring ベースのアプリケーション、オープン API への統合、JCE プロバイダーでの使用に適しています... 次の依存関係を追加します: com.github.ulisesbocchiojasypt-spring-boot-starter2. 1.1 Jasypt の特典はシステムのセキュリティを保護し、コードが漏洩した場合でもデータ ソースは保証されます。
 SpringBoot が Redisson を統合して遅延キューを実装する方法
May 30, 2023 pm 02:40 PM
SpringBoot が Redisson を統合して遅延キューを実装する方法
May 30, 2023 pm 02:40 PM
使用シナリオ 1. 注文は正常に行われましたが、支払いが 30 分以内に行われませんでした。支払いがタイムアウトになり、注文が自動的にキャンセルされました 2. 注文に署名があり、署名後 7 日間評価が行われませんでした。注文がタイムアウトして評価されない場合、システムはデフォルトでプラスの評価を設定します 3. 注文は正常に行われます。販売者が 5 分間注文を受け取らない場合、注文はキャンセルされます。 4. 配送がタイムアウトします。 SMS リマインダーをプッシュします... 遅延が長く、リアルタイム パフォーマンスが低いシナリオでは、タスク スケジュールを使用して定期的なポーリング処理を実行できます。例: xxl-job 今日は選択します
 Redis を使用して SpringBoot に分散ロックを実装する方法
Jun 03, 2023 am 08:16 AM
Redis を使用して SpringBoot に分散ロックを実装する方法
Jun 03, 2023 am 08:16 AM
1. Redis は分散ロックの原則を実装しており、分散ロックが必要な理由 分散ロックについて話す前に、分散ロックが必要な理由を説明する必要があります。分散ロックの反対はスタンドアロン ロックです。マルチスレッド プログラムを作成するとき、共有変数を同時に操作することによって引き起こされるデータの問題を回避します。通常、ロックを使用して共有変数を相互に除外し、データの正確性を確保します。共有変数の使用範囲は同じプロセス内です。共有リソースを同時に操作する必要があるプロセスが複数ある場合、どうすれば相互排他的になるのでしょうか?今日のビジネス アプリケーションは通常マイクロサービス アーキテクチャであり、これは 1 つのアプリケーションが複数のプロセスをデプロイすることも意味します。複数のプロセスが MySQL の同じレコード行を変更する必要がある場合、順序の乱れた操作によって引き起こされるダーティ データを避けるために、分散が必要です。今回導入するスタイルはロックされています。ポイントを獲得したい
 Springbootがjarパッケージにファイルを読み込んだ後にファイルにアクセスできない問題を解決する方法
Jun 03, 2023 pm 04:38 PM
Springbootがjarパッケージにファイルを読み込んだ後にファイルにアクセスできない問題を解決する方法
Jun 03, 2023 pm 04:38 PM
Springboot はファイルを読み取りますが、jar パッケージにパッケージ化した後、最新の開発にアクセスできません。jar パッケージにパッケージ化した後、Springboot がファイルを読み取れない状況があります。その理由は、パッケージ化後、ファイルの仮想パスが変更されるためです。は無効であり、ストリーム経由でのみアクセスできます。読み取ります。ファイルはリソースの下にあります publicvoidtest(){Listnames=newArrayList();InputStreamReaderread=null;try{ClassPathResourceresource=newClassPathResource("name.txt");Input
 SpringBootとSpringMVCの比較と差異分析
Dec 29, 2023 am 11:02 AM
SpringBootとSpringMVCの比較と差異分析
Dec 29, 2023 am 11:02 AM
SpringBoot と SpringMVC はどちらも Java 開発で一般的に使用されるフレームワークですが、それらの間には明らかな違いがいくつかあります。この記事では、これら 2 つのフレームワークの機能と使用法を調べ、その違いを比較します。まず、SpringBoot について学びましょう。 SpringBoot は、Spring フレームワークに基づいたアプリケーションの作成と展開を簡素化するために、Pivotal チームによって開発されました。スタンドアロンの実行可能ファイルを構築するための高速かつ軽量な方法を提供します。
 SQL ステートメントを使用せずに Springboot+Mybatis-plus を実装して複数のテーブルを追加する方法
Jun 02, 2023 am 11:07 AM
SQL ステートメントを使用せずに Springboot+Mybatis-plus を実装して複数のテーブルを追加する方法
Jun 02, 2023 am 11:07 AM
Springboot+Mybatis-plus が SQL ステートメントを使用して複数テーブルの追加操作を実行しない場合、私が遭遇した問題は、テスト環境で思考をシミュレートすることによって分解されます: パラメーターを含む BrandDTO オブジェクトを作成し、パラメーターをバックグラウンドに渡すことをシミュレートします。 Mybatis-plus で複数テーブルの操作を実行するのは非常に難しいことを理解してください。Mybatis-plus-join などのツールを使用しない場合は、対応する Mapper.xml ファイルを設定し、臭くて長い ResultMap を設定するだけです。対応する SQL ステートメントを記述します。この方法は面倒に見えますが、柔軟性が高く、次のことが可能です。
 SpringBoot が Redis をカスタマイズしてキャッシュのシリアル化を実装する方法
Jun 03, 2023 am 11:32 AM
SpringBoot が Redis をカスタマイズしてキャッシュのシリアル化を実装する方法
Jun 03, 2023 am 11:32 AM
1. RedisAPI のデフォルトのシリアル化メカニズムである RedisTemplate1.1 をカスタマイズします。API ベースの Redis キャッシュ実装では、データ キャッシュ操作に RedisTemplate テンプレートを使用します。ここで、RedisTemplate クラスを開いて、クラスのソース コード情報を表示します。publicclassRedisTemplateextendsRedisAccessorimplementsRedisOperations、BeanClassLoaderAware{//キーを宣言、値の各種シリアル化メソッド、初期値は空 @NullableprivateRedisSe
 Springbootでapplication.ymlの値を取得する方法
Jun 03, 2023 pm 06:43 PM
Springbootでapplication.ymlの値を取得する方法
Jun 03, 2023 pm 06:43 PM
プロジェクトでは、構成情報が必要になることがよくありますが、この情報はテスト環境と本番環境で構成が異なる場合があり、実際のビジネス状況に基づいて後で変更する必要がある場合があります。これらの構成をコードにハードコーディングすることはできません。構成ファイルに記述することをお勧めします。たとえば、この情報を application.yml ファイルに書き込むことができます。では、コード内でこのアドレスを取得または使用するにはどうすればよいでしょうか?方法は2つあります。方法 1: @Value アノテーションが付けられた ${key} を介して、構成ファイル (application.yml) 内のキーに対応する値を取得できます。この方法は、マイクロサービスが比較的少ない状況に適しています。方法 2: 実際には、プロジェクト、業務が複雑な場合、ロジック
