

タオバオ推奨システムにおける連続転移学習クロスドメイン推奨ランキングモデルの適用

この記事では、業界における継続学習のフレームワークの下でクロスドメイン推奨モデルを実装する方法を検討し、継続的事前学習の中間層表現の結果を使用して、連続転移学習の新しいクロスドメイン推奨パラダイムを提案します。トレーニングされたソース ドメイン モデルとしてターゲット ドメイン モデルの追加知識に基づいて、クロスドメインの知識の移行を実現する軽量のアダプター モジュールが設計され、推奨製品のランキングで重要なビジネス成果を達成しました。
背景
近年、ディープモデルの適用により、業界におけるレコメンドシステムのレコメンド効果が大幅に向上しています。シナリオ内のデータに依存してモデルの構造と機能を最適化することがより困難になります。タオバオのような大規模な電子商取引プラットフォームでは、さまざまなユーザーの多様なニーズを満たすために、情報フローのレコメンデーション(ホームページで気に入るかもしれません)、優れたこれらのシナリオは淘宝網の製品システムを共有していますが、特定の製品選択プール、コア ユーザー、ビジネス目標には大きな違いがあり、シナリオによって規模も大きく異なります。今回の「良品」シナリオはタオバオの厳選商品のショッピングガイドシナリオです 情報フローレコメンデーション、メイン検索、その他のシナリオに比べて規模が比較的小さいため、転移学習、クロスドメインレコメンデーションの活用方法モデルの効果を向上させるためのその他の方法は常に存在しており、これは良品仕分けモデルを最適化する際の重要なポイントの 1 つです。 タオバオのさまざまなビジネス シナリオでは製品とユーザーが重複していますが、シナリオに大きな違いがあるため、情報フローの推奨などの大規模なシナリオのランキング モデルは、優れた製品が入手可能なシナリオに直接適用するとうまく機能しません。 。したがって、チームは、事前トレーニングや微調整、マルチシナリオの共同トレーニング、グローバル学習などの一連の既存の手法の使用を含め、クロスドメインの推奨に向けて多大な試みを行ってきました。これらの方法は、実際のオンライン アプリケーションでは十分に効果的ではないか、かなりの問題が発生します。継続的転移学習プロジェクトは、これらの手法をビジネスに適用する際の一連の問題に対して、シンプルかつ効果的な新しいクロスドメイン推奨手法を提案します。この方法
は、継続的に事前トレーニングされたソース ドメイン モデルの中間層表現の結果をターゲット ドメイン モデルの追加知識として使用し、淘宝網での優れた製品の推奨ランキングで重要なビジネス成果を達成しました。
この記事「淘宝網におけるクロスドメインのクリックスルー率予測のための継続的転移学習」の詳細版は、ArXiv https://arxiv.org/abs/2208.05728 で公開されています。方法
▐ 既存の研究とその欠点学界と産業界における既存のクロスドメイン研究の分析ドメイン レコメンデーション (CDR) 関連の作業は、主に、共同学習と事前トレーニングと微調整の 2 つのカテゴリに分類できます。このうち、共同トレーニング手法は、ソース ドメイン (Source Domain) モデルとターゲット ドメイン (Target Domain) モデルを同時に最適化します。ただし、このタイプの方法では、トレーニングにソース ドメイン データを導入する必要があり、ソース ドメインのサンプルは通常サイズが大きいため、膨大なコンピューティング リソースとストレージ リソースを消費します。多くの中小企業では、そのような大きなリソース オーバーヘッドを支払う余裕はありません。一方で、このタイプの方法は複数のシーンの目標を同時に最適化する必要があり、シーン間の違いも目標の競合による悪影響をもたらす可能性があるため、事前トレーニング微調整手法は、多くのシーンでより幅広い用途に使用できます。業界。
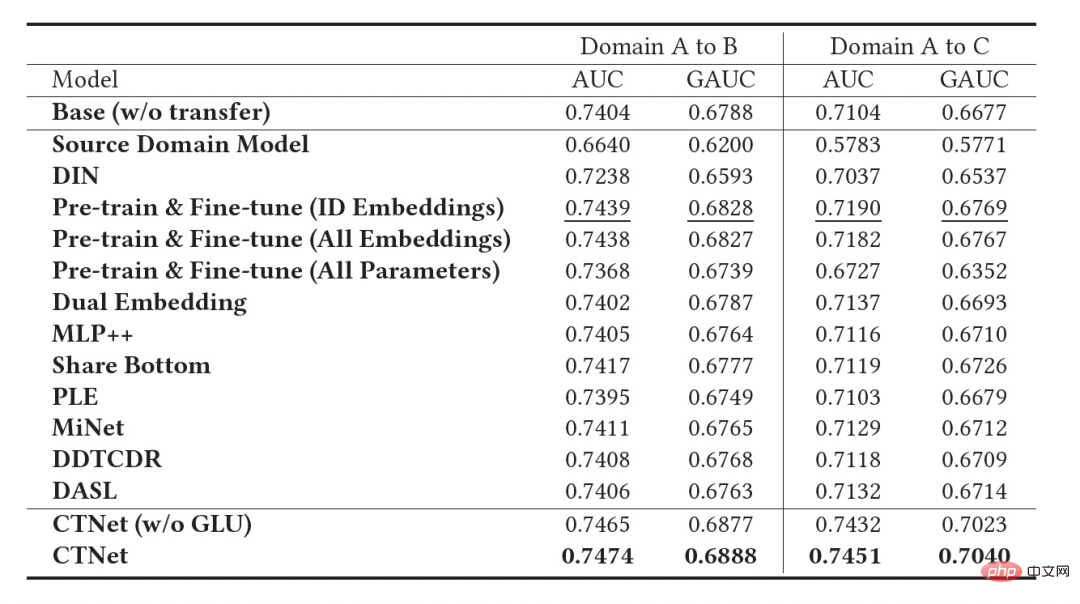
業界推奨システムの重要な特徴は、モデルのトレーニングが 継続学習 (継続学習) パラダイムに従っていることです。つまり、モデルは最新のサンプルを使用し、 を活用する必要があります。オフライン増分更新 (増分学習) または オンライン学習 および最新のデータ分布を学習するその他の方法。この記事で検討したクロスドメイン レコメンデーション タスクでは、ソース ドメインとターゲット ドメインのモデルは両方とも継続学習トレーニング手法に従います。したがって、私たちは、学術および産業用途で広く使用されるであろう新しい問題を提案します: 継続転移学習、これは、時間の経過とともに変化するあるドメインから、同様に時間の経過とともに変化する別のドメインに移動することとして定義されます。私たちは、業界推奨システム、検索エンジン、コンピュテーショナル広告などにおける既存のクロスドメイン推奨および転移学習手法の適用は、連続転移学習パラダイムに従うべき、つまり転移プロセスは連続的かつ複数回であるべきであると考えています。その理由は、データ分布は急速に変化するため、継続的な移行のみが安定した移行効果を保証できるからです。この業界推奨制度の特徴と組み合わせると、事前トレーニングや微調整の実用化には課題が見えてきます。ソース ドメインとターゲット ドメインのシーンの違いにより、ソース ドメイン モデルを微調整してより良い結果を得るには、通常、多数のサンプルを使用する必要があります。継続的な転移学習を実現するには、最新のソース ドメイン モデルを使用して時々再微調整する必要があるため、非常に膨大な学習コストがかかり、この学習方法をオンライン化することも困難です。さらに、これらの多数のサンプルを微調整に使用すると、ソース ドメイン モデルが保持されている有用な知識を忘れてしまう可能性もあり、モデル内の壊滅的な忘却問題を回避できます。ソース ドメイン モデルのパラメーターを使用して、以前に作成された元のパラメーターを置き換えます。ターゲット ドメインで学習された情報も元のモデルから歴史的に得られた有用な知識は破棄されます。したがって、業界の推奨シナリオに適した、より効率的な連続転移学習モデルを設計する必要があります。 この記事では、上記の問題を解決するためのシンプルで効果的なモデル CTNet (継続的転送ネットワーク、継続的移行ネットワーク) を提案します。従来の事前トレーニング微調整方法とは異なり、CTNet の中心的な考え方は、 が履歴内のモデルによって取得されたすべての知識を忘れたり破棄したりすることができず、元のソース ドメイン モデルとターゲットのすべてのパラメーターを保持するということです。ドメイン モデル 。これらのパラメーターには、非常に長い履歴データの学習を通じて得られた知識が保存されています (たとえば、淘宝網の詳細ランキング モデルは、2 年以上にわたって継続的に段階的にトレーニングされています)。 CTNet はシンプルなツインタワー構造を採用し、軽量のアダプター層を使用して、継続的に事前トレーニングされたソース ドメイン モデルの中間層表現の結果をターゲット ドメイン モデルの追加知識としてマッピングします。連続転移学習を実現するためにデータのバックトラッキングが必要な事前トレーニング微調整方法とは異なり、CTNet では増分データの更新のみが必要なため、効率的な連続転移学習が実現します。 ##########################################方法####### #継続的な転移学習を達成するには増分データのみが必要です ##共同トレーニング #表 1: CTNet と既存のクロスドメイン推奨モデルの比較 時間の経過とともに変化し続けるソース ドメインとターゲット ドメインを考慮すると、継続的転移学習 (継続的転移学習) では、次のことが可能になることが期待されます。過去の、または現在取得されているソース ドメインとターゲット ドメインの知識を使用して、将来のターゲット ドメインの予測精度を向上させます。 継続的転移学習の問題を、淘宝網のクロスドメイン レコメンデーション タスクに適用します。このタスクには次の特徴があります。
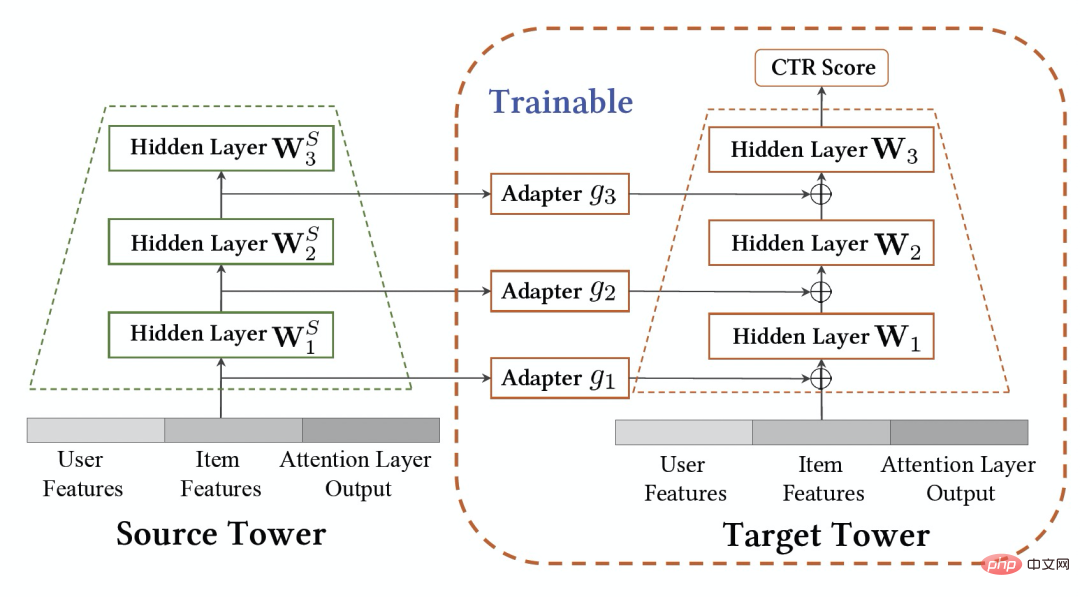
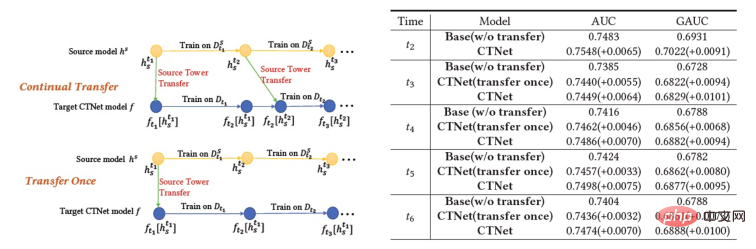
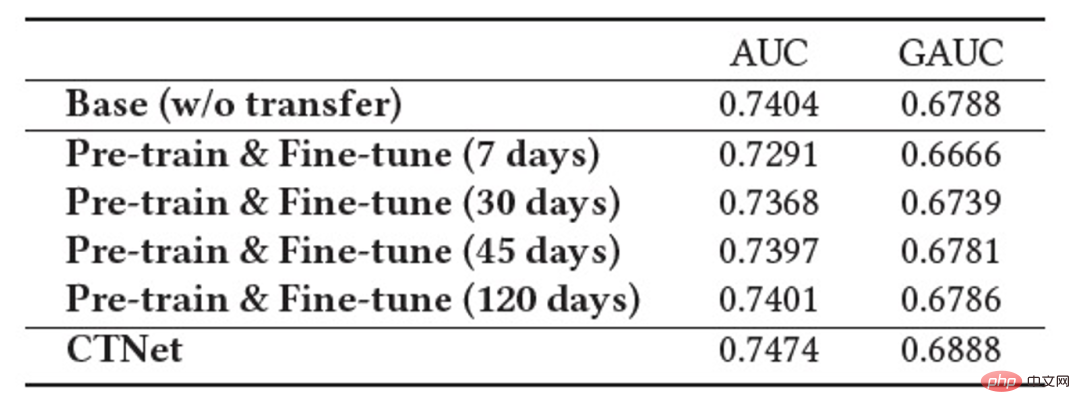
上の図は、私たちのメソッドをオンラインで展開した様子を示しています。 瞬間の前に、ソース ドメイン モデルとターゲット ドメイン モデルは、それぞれのシーンの監視データのみを使用して、個別かつ継続的に増分的にトレーニングされました。 図 2: 継続的移行ネットワーク CTNet 図 2 に示すように、私たちが提案した連続転送ネットワーク (CTNet) モデルは、すべてのソース ドメイン モデルをターゲット ドメインのオリジナルのファインランキング モデルに埋め込みます。それらのネットワーク パラメータは 2 つのタワー構造を形成し、CTNet の左側のタワーがソース タワー、右側のタワーがターゲット タワーです。ソース ドメイン モデルの最終スコアリングのみを使用する、または一部の浅い表現 (埋め込みなど) のみを使用する一般的な方法とは異なり、軽量のアダプター ネットワークを使用して、ソース ドメイン モデルのすべての中間隠れ層を結合します。 MLP (特に、ソース ドメイン MLP に深く含まれるユーザーとアイテムの )、表現結果 をターゲット レコメンデーション ドメインにマッピングし、その結果をターゲット タワーの対応するレイヤー CTNet の効果を向上させる鍵は、MLP での深い表現情報の移行を利用することです。ゲート線形ユニット (GLU) のアイデアに基づいて、アダプター ネットワークはゲート線形層を使用し、ソース ドメイン特徴の適応特徴選択を効果的に実装できます。モデル内の有用な知識は移行され、モデルと矛盾する情報は移行されます。シーンの特徴が転送されます。フィルターで除外できます。ソース ドメイン モデルは継続的な事前トレーニングに最新のソース ドメイン監視データを使用し続けるため、トレーニング プロセス中、Source Tower は最新の更新されたソース ドメイン モデル パラメーターの読み込みも継続し、バックプロパゲーション プロセス中も固定されたままになります。継続的な転移学習の効率的な進行。したがって、CTNet モデルは継続学習パラダイムに非常に適しており、ターゲット ドメイン モデルがソース ドメイン モデルによって提供される最新の知識を継続的に学習して、最新のデータ分布の変更に適応できます。同時に、モデルはターゲット ドメイン データでのみトレーニングされるため、モデルはソース ドメインのトレーニング目標の影響を受けず、ソース ドメイン データのトレーニングをまったく必要とせず、大量のストレージを回避できます。そして計算のオーバーヘッド。さらに、このようなネットワーク構造は加算設計手法を採用しているため、移行プロセス中に元のモデルの MLP 層のディメンションを変更する必要がなく、ターゲット タワーは元のターゲット ドメインのオンライン モデルによって完全に初期化され、 MLP 層のランダムな再初期化により、元のモデルの効果が最大限に損なわれず、良好な結果を得るために必要な増分データが少なくなり、モデルのホット スタートが実現されます。 ソース ドメイン モデルを #図 3: CTNet トレーニング #実験 表2: オフライン実験結果 上の表に示すように、2 つのサブシナリオ (表のドメイン B および C) に対応する実稼働データ セットがあります。良品ビジネス 一連のオフライン実験は、ソース ドメイン (表のドメイン A) がホームページ情報フロー推奨シナリオである Web サイト上で実行されました。情報フローのレコメンデーション (ホームページで気に入っているかもしれません) ランキング モデルのスコアリング結果 (表のソース ドメイン モデル) を直接使用することは、良い商品のビジネスには効果的ではないことがわかります。 、絶対値は GAUC-5.88.% と GAUC-9.06% であり、シナリオ間の違いが証明されています。 また、一般的な事前トレーニング微調整手法や共同トレーニング手法 (MLP、PLE、MiNet、DDTCDR、DASL など) を含む、一連の従来のクロスドメイン レコメンデーション ベースライン手法も比較しました。 、そして提案された CTNet は両方のデータセットで既存の方法を大幅に上回っています。完全オンラインのメイン モデルと比較して、CTNet は 2 つのデータ セットでそれぞれ 1.0% と 3.6% という GAUC の大幅な改善を達成しました。さらに、実験を通じて、単一転送と比較した連続転送の利点を分析しました。 CTNet のフレームワークでは、1 回の転送による効果の向上はモデルの増分更新に伴って減衰しますが、継続的な転送学習によりモデル効果の安定した向上を保証できます。 # 図 4: 単一転移と比較した連続転移学習の利点 次の表は、従来の事前トレーニング微調整の効果を示しています。完全なソース ドメイン モデルを使用して、ターゲット ドメイン データでトレーニングします。フィールド間の違いにより、モデルの効果を完全なオンライン基本モデルと同等のレベルに調整するには、非常に多くのサンプル (120 日サンプルなど) が必要になります。継続的な転移学習を実現するには、最新のソースドメインモデルを用いて定期的に再調整を行う必要があり、その都度の調整に膨大なコストがかかるため、継続的な転移学習には適していません。さらに、この方法は効果の点で移行なしのベースモデルを超えることはありませんが、その主な理由は、大規模なターゲットドメインサンプルトレーニングの使用により、モデルが元のソースドメインの知識を忘れてしまい、最終的なモデル効果が得られないためです。トレーニングは、ターゲット ドメイン データのみに対するトレーニングの効果に似ています。事前トレーニングと微調整のパラダイムでは、すべてのパラメーターを再利用するよりも、一部の埋め込みパラメーターのみをロードする方が優れています (表 2 を参照)。 #表 3: 事前トレーニングされたソース ドメイン モデルを使用したターゲット ドメインでのトレーニングの効果 CTR 2.5%、追加購入 6.7%、トランザクション数 3.4%、GMV 7.7%C シナリオ: CTR 12.3%、滞在期間 8.8%、追加購入 10.9%、トランザクション数 30.9%、GMV 31.9% 概要と展望 チーム紹介##大量のソース ドメイン サンプルを使用する必要はありません
#いいえ
#いいえ #はい
トレーニング前の微調整
はい はい いいえ
この記事で提案する CTNet
は です##### #######はい############### ▐ 問題の定義
# #この記事では、継続的転移学習の新しい問題について検討します: # さまざまな推奨シナリオの規模は大きく異なり、より大きなソース ドメインでトレーニングされたモデルの知識を使用して、推奨シナリオを改善できます。対象ドメインの推薦効果。
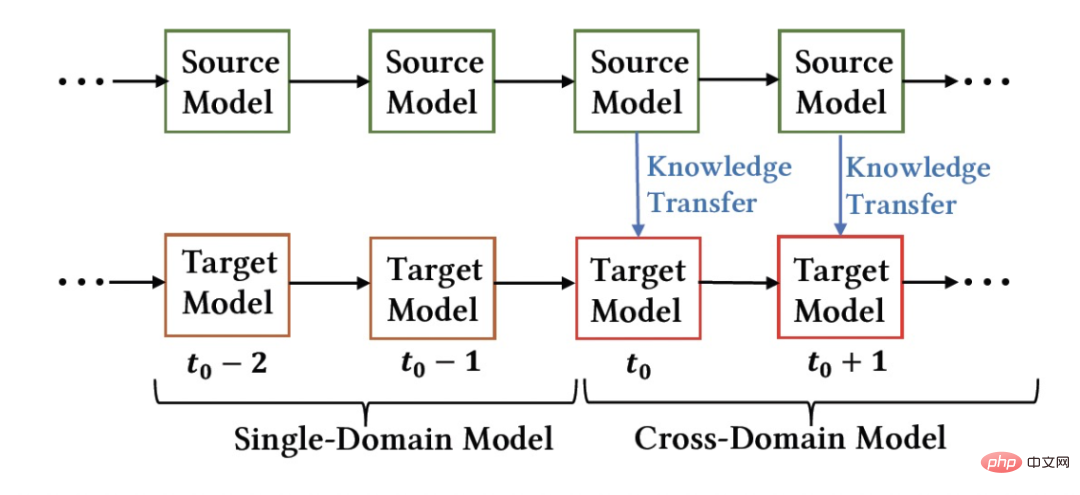 #図 1: モデル展開の概略図
#図 1: モデル展開の概略図 の瞬間から、クロスドメイン レコメンデーション モデル CTNet をターゲット ドメインにデプロイしました。このモデルは、履歴で得た知識を忘れることなくターゲット ドメイン データをインクリメントし続けます。トレーニングは継続的に行われます。最新のソース ドメイン モデルから知識を移転します。 #▐ 継続的移行ネットワーク モデル (CTNet)
の瞬間から、クロスドメイン レコメンデーション モデル CTNet をターゲット ドメインにデプロイしました。このモデルは、履歴で得た知識を忘れることなくターゲット ドメイン データをインクリメントし続けます。トレーニングは継続的に行われます。最新のソース ドメイン モデルから知識を移転します。 #▐ 継続的移行ネットワーク モデル (CTNet)
 # に追加します (以下の式は # の状況を表します) #######)。
# に追加します (以下の式は # の状況を表します) #######)。 

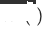 (元の単一ドメイン推奨ターゲット ドメイン モデル) として定義します。は
(元の単一ドメイン推奨ターゲット ドメイン モデル) として定義します。は 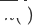 、新しくデプロイされたターゲット ドメインのクロスドメイン推奨モデルは
、新しくデプロイされたターゲット ドメインのクロスドメイン推奨モデルは 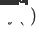 、
、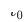 はオンラインでのクロスドメイン推奨モデルのデプロイですモデルは時間
はオンラインでのクロスドメイン推奨モデルのデプロイですモデルは時間 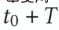 まで継続的に増分更新されます。アダプター、ソース タワー、およびターゲット タワーのパラメーターは、それぞれ
まで継続的に増分更新されます。アダプター、ソース タワー、およびターゲット タワーのパラメーターは、それぞれ  、
、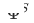 、および
、および 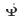 です。 CTNet トレーニングのプロセスは次のとおりです。
です。 CTNet トレーニングのプロセスは次のとおりです。 
▐ オフライン効果
CTNetは早ければ2021年末までに完成し、2022年2月から優良商品のレコメンド事業を本格的に開始する予定です。前世代のフルモデルと比較して、2 つの推奨シナリオでビジネス指標の大幅な改善が達成されました。シナリオ B:
以上がタオバオ推奨システムにおける連続転移学習クロスドメイン推奨ランキングモデルの適用の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7468
7468
 15
1376
52
77
11
19
27
15
1376
52
77
11
19
27

 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
 Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
FP8 以下の浮動小数点数値化精度は、もはや H100 の「特許」ではありません。 Lao Huang は誰もが INT8/INT4 を使用できるようにしたいと考え、Microsoft DeepSpeed チームは NVIDIA からの公式サポートなしで A100 上で FP6 の実行を開始しました。テスト結果は、A100 での新しい方式 TC-FPx の FP6 量子化が INT4 に近いか、場合によってはそれよりも高速であり、後者よりも精度が高いことを示しています。これに加えて、エンドツーエンドの大規模モデルのサポートもあり、オープンソース化され、DeepSpeed などの深層学習推論フレームワークに統合されています。この結果は、大規模モデルの高速化にも即座に影響します。このフレームワークでは、シングル カードを使用して Llama を実行すると、スループットはデュアル カードのスループットの 2.65 倍になります。 1つ
 オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
前に書かれたプロジェクトのリンク: https://nianticlabs.github.io/mickey/ 2 枚の写真が与えられた場合、それらの写真間の対応関係を確立することで、それらの間のカメラのポーズを推定できます。通常、これらの対応は 2D 対 2D であり、推定されたポーズはスケール不定です。いつでもどこでもインスタント拡張現実などの一部のアプリケーションでは、スケール メトリクスの姿勢推定が必要なため、スケールを回復するために外部深度推定器に依存します。この論文では、3D カメラ空間でのメトリックの対応を予測できるキーポイント マッチング プロセスである MicKey を提案します。画像全体の 3D 座標マッチングを学習することで、相対的なメトリックを推測できるようになります。
