

ChatGPT健忘症を完全解決! Transformer の入力制限を突破: 200 万の有効なトークンをサポートできると測定

ChatGPT (Transformer クラス モデル) には、忘れられやすいという致命的な欠陥があります。入力シーケンスのトークンがコンテキスト ウィンドウのしきい値を超えると、その後の出力内容は前のロジックと一致しなくなります。
ChatGPT は 4000 トークン (約 3000 ワード) の入力しかサポートできません。新しくリリースされた GPT-4 でさえ、最大トークン ウィンドウは 32000 しかサポートしていません。入力シーケンスの長さが増加し続けると、計算量が増加します。も増加します。二次関数的に増加します。
最近、DeepPavlov、AIRI、およびロンドン数理科学研究所の研究者は、リカレント メモリ トランスフォーマー (RMT) を使用して、BERT の有効コンテキスト長を「前例のない 200 万トークン」に増やしながら、維持した技術レポートを発表しました。高いメモリ検索精度。
ペーパーリンク: https://www.php.cn/link/459ad054a6417248a1166b30f6393301
このメソッドは、ローカルおよびグローバル情報を保存および処理でき、ループを使用して情報を保存できるようにします。入力シーケンスの各部分がセグメント間を流れます。
実験セクションでは、このアプローチの有効性を実証します。このアプローチは、自然言語の理解および生成タスクにおける長期的な依存関係の処理を強化し、メモリを大量に消費するアプリケーションの大規模なコンテキスト処理を可能にする並外れた可能性を秘めています。
ただし、世界にはフリーランチはありません。RMT はメモリ消費量を増やすことができず、ほぼ無制限のシーケンス長まで拡張できますが、RNN には依然としてメモリ減衰の問題があり、より長い推論時間が必要です。 。

しかし、一部のネチズンが解決策を提案しました。RMT は長期記憶に使用され、大きなコンテキストは短期記憶に使用され、モデルトレーニングは夜間に実行されます。 /メンテナンス中。
Cyclic Memory Transformer
2022 年、チームは、入力または出力シーケンスに特別なメモリ トークンを追加し、制御するモデルをトレーニングすることにより、Cyclic Memory Transformer (RMT) モデルを提案しました。メモリ操作とシーケンス表現処理は、元の Transformer モデルを変更せずに新しいメモリ メカニズムを実装できます。

論文リンク: https://arxiv.org/abs/2207.06881
公開されたカンファレンス: NeurIPS 2022
with Transformer-XLそれに比べて、RMT は必要なメモリが少なく、より長い一連のタスクを処理できます。
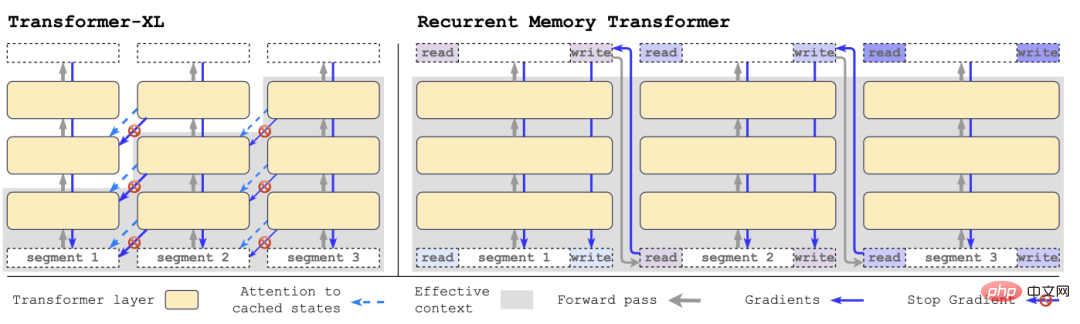
具体的には、RMT は m 個の実数値の学習可能なベクトルで構成されます。長すぎる入力シーケンスはいくつかのセグメントに分割され、メモリ ベクトルは最初のセグメントにプリセットされます。セグメントの埋め込みとセグメント トークンと一緒に処理されます。
2022 年に提案されたオリジナルの RMT モデルとは異なり、BERT のような純粋なエンコーダー モデルの場合、メモリはセグメントの先頭に 1 回だけ追加され、デコード モデルは記憶は読み取りと書き込みの 2 つの部分に分かれています。
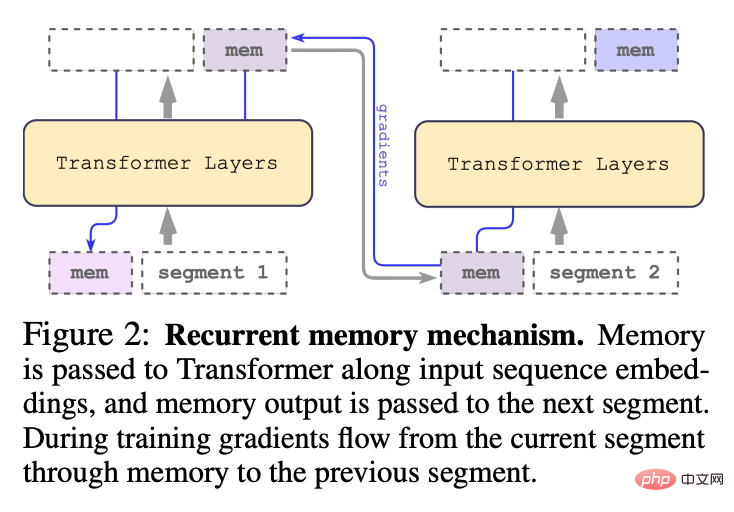
各タイム ステップとセグメントで、次のようにループします。ここで、N はトランスフォーマー層の数、t はタイム ステップ、H はセグメントです
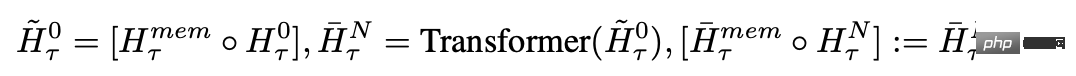
入力シーケンスのセグメントを順番に処理した後、再帰的接続を実現するために、研究者は現在のセグメントのメモリ トークンの出力を次のセグメントの入力に渡します。
RMT のメモリとループはグローバル メモリ トークンのみに基づいており、バックボーンの Transformer モデルを変更せずに維持できるため、RMT のメモリ拡張機能はあらゆる Transformer モデルと互換性があります。 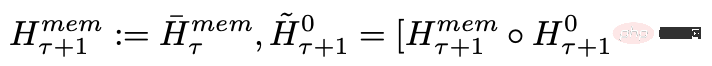
線形拡張は、入力シーケンスをいくつかのセグメントに分割し、セグメントの境界内でのみアテンション マトリックス全体を計算することによって実現されます。長さは固定されており、RMT の推論速度はモデル サイズに関係なく直線的に増加します。 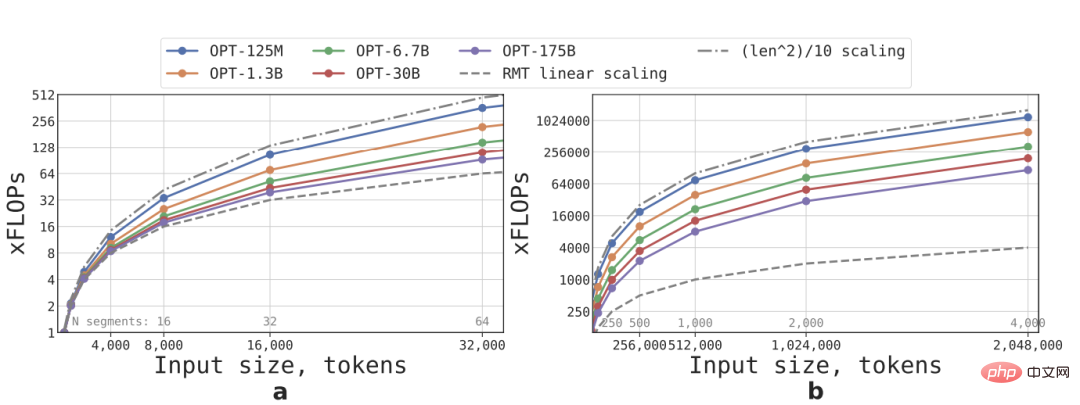
FFN 層の計算量が多いため、大規模な Transformer モデルでは、シーケンスの長さに比べて二次関数の成長率が遅くなる傾向がありますが、長さが 32,000 を超える非常に長いシーケンスでは、FLOP は二次関数に戻ります。成長の様子。
複数のセグメントを持つシーケンス (この調査では 512 より大きい) の場合、RMT は非巡回モデルよりも FLOP が低く、小規模なモデルでは FLOP の効率を最大 295 倍向上させることができます。 OPT-175Bなどの機種では29倍まで増やすことができます。
記憶タスク
記憶能力をテストするために、研究者らは、モデルが単純な事実と基本的な推論を記憶することを必要とする合成データセットを構築しました。
タスク入力は、1 つまたは複数の事実と、これらすべての事実でのみ回答できる質問で構成されます。
タスクの難易度を高めるために、質問や回答に関係のない自然言語テキストもタスクに追加されますが、これらのテキストはノイズとみなされる可能性があるため、モデルのタスクは実際に事実を無関係なテキストから分離し、事実に基づくテキストを使用して質問に回答します。

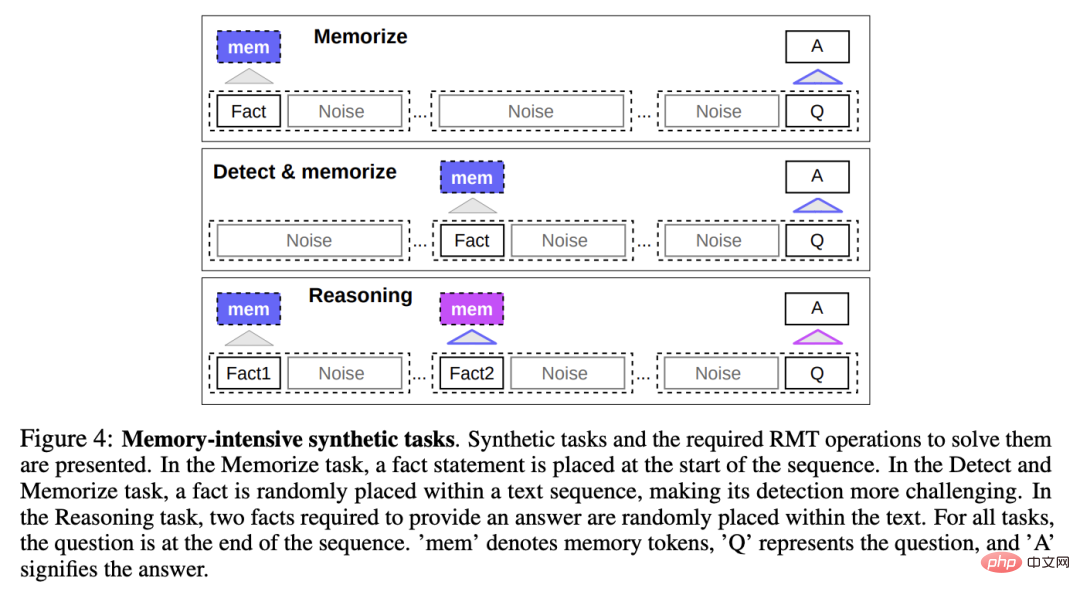
事実の記憶
テスト RMT は、長期間にわたってメモリに情報を書き込み、保存します。時間パワー: 最も単純なケースでは、事実は入力の先頭にあり、質問は入力の最後にあり、モデルが一度にすべての入力を受け入れられなくなるまで、質問と回答の間にある無関係なテキストの量が徐々に増加します。 。

事実の検出と記憶
事実の検出は、入力内のランダムな位置に事実を移動することでタスクの難易度を高めます。 , required モデルはまず事実を無関係なテキストから分離し、それらをメモリに書き込み、最後に質問に答えます。
記憶された事実に基づく推論
記憶のもう 1 つの重要な操作は、記憶された事実と現在のコンテキストを使用して推論することです。
この機能を評価するために、研究者らは、2 つのファクトが生成され、入力シーケンスにランダムに配置される、より複雑なタスクを導入しました。その質問に答えるには、シーケンスの最後に尋ねられる質問を選択する必要があります。正しい事実。

実験結果
研究者らは、すべての実験で RMT のバックボーンとして HuggingFace Transformers の事前トレーニング済み Bert ベース ケース モデルを使用しました。モデルはサイズ 10 の拡張メモリに基づいていました。
4 ~ 8 個の NVIDIA 1080Ti GPU でトレーニングと評価を行います。シーケンスが長い場合は、単一の 40GB NVIDIA A100 に切り替えて評価を高速化します。
カリキュラム学習
研究者らは、トレーニング スケジューリングを使用すると、ソリューションの精度と安定性が大幅に向上する可能性があることを観察しました。
最初は短いタスク バージョンで RMT をトレーニングさせます。トレーニングが収束したら、セグメントを追加してタスクの長さを増やし、理想的な入力長に達するまでコース学習プロセスを続けます。
単一セグメントに適合するシーケンスで実験を開始します。3 つの BERT の特殊マーカーと 10 個のメモリ プレースホルダーがモデル入力から保持されるため、実際のセグメント サイズは 499 となり、合計サイズは 512 になります。
短いタスクでトレーニングした後、RMT はより少ないトレーニング ステップで完璧なソリューションに収束するため、長いタスクを解決するのが簡単であることがわかります。
外挿能力
さまざまなシーケンス長に対する RMT の汎化能力を観察するために、研究者らは、さまざまな数のセグメントでトレーニングされたモデルを評価し、次のタスクを解決しました。より長い長さ。
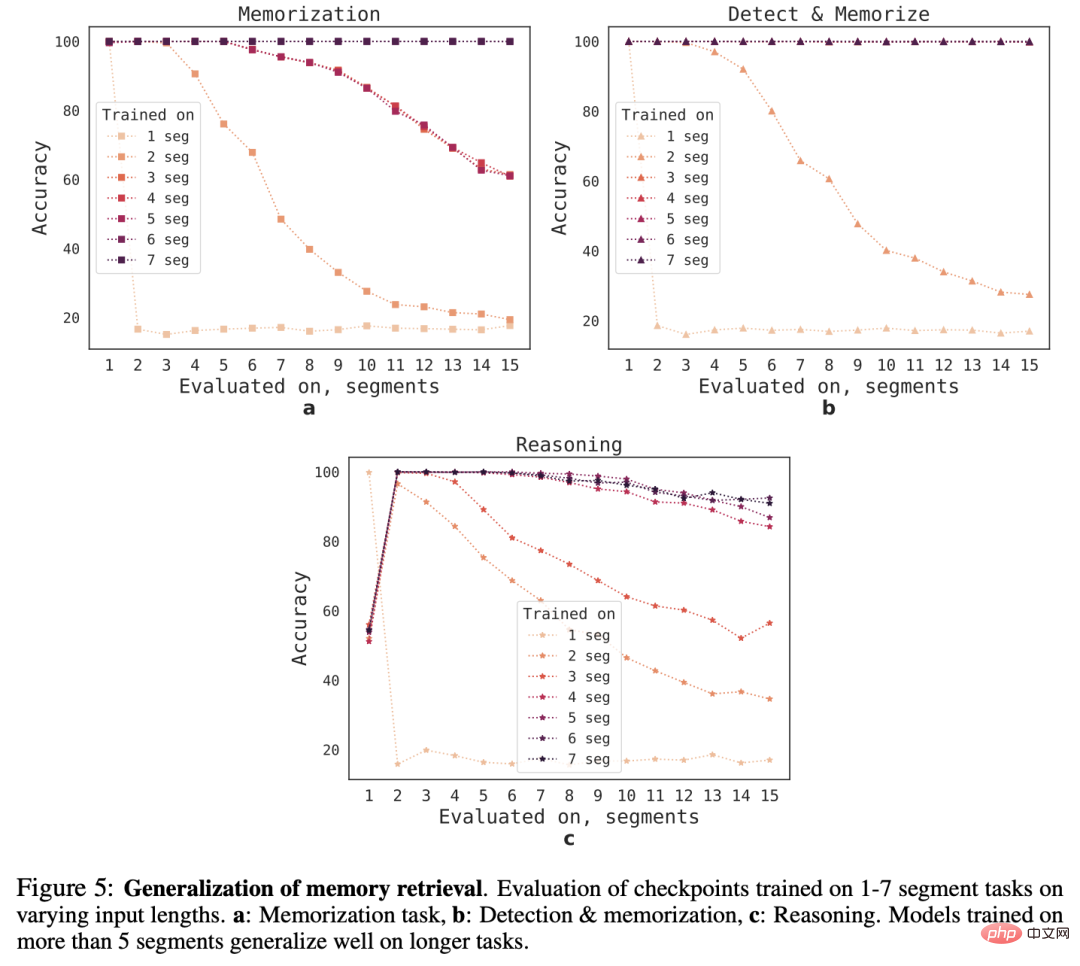
モデルは多くの場合、短いタスクでは良好に実行されますが、より長いシーケンスでモデルをトレーニングした後は、単一セグメントの推論タスクを処理することが困難になることがわかります。
考えられる説明の 1 つは、タスク サイズが 1 セグメントを超えるため、モデルが最初のセグメントの問題を予測しなくなり、その結果品質が低下するということです。
興味深いことに、トレーニング セグメントの数が増加するにつれて、RMT のより長いシーケンスに対する一般化能力も現れます。5 つ以上のセグメントでトレーニングした後、RMT は 2 倍の長さのシーケンスを処理できるようになります。タスクのほぼ完璧な一般化です。
一般化の限界をテストするために、研究者らは検証タスクのサイズを 4096 セグメント (つまり、2,043,904 トークン) に増加しました。
RMT は、このような長いシーケンスに驚くほどよく耐えます。その中で「検出と記憶」タスクが最も単純で、推論タスクが最も複雑です。
参考資料: https://www.php.cn/link/459ad054a6417248a1166b30f6393301
以上がChatGPT健忘症を完全解決! Transformer の入力制限を突破: 200 万の有効なトークンをサポートできると測定の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7455
7455
 15
1375
52
77
11
14
9
15
1375
52
77
11
14
9

 ChatGPT では、無料ユーザーが 1 日あたりの制限付きで DALL-E 3 を使用して画像を生成できるようになりました
Aug 09, 2024 pm 09:37 PM
ChatGPT では、無料ユーザーが 1 日あたりの制限付きで DALL-E 3 を使用して画像を生成できるようになりました
Aug 09, 2024 pm 09:37 PM
DALL-E 3は、前モデルより大幅に改良されたモデルとして2023年9月に正式導入されました。これは、複雑な詳細を含む画像を作成できる、これまでで最高の AI 画像ジェネレーターの 1 つと考えられています。ただし、発売当初は対象外でした
 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
 Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
FP8 以下の浮動小数点数値化精度は、もはや H100 の「特許」ではありません。 Lao Huang は誰もが INT8/INT4 を使用できるようにしたいと考え、Microsoft DeepSpeed チームは NVIDIA からの公式サポートなしで A100 上で FP6 の実行を開始しました。テスト結果は、A100 での新しい方式 TC-FPx の FP6 量子化が INT4 に近いか、場合によってはそれよりも高速であり、後者よりも精度が高いことを示しています。これに加えて、エンドツーエンドの大規模モデルのサポートもあり、オープンソース化され、DeepSpeed などの深層学習推論フレームワークに統合されています。この結果は、大規模モデルの高速化にも即座に影響します。このフレームワークでは、シングル カードを使用して Llama を実行すると、スループットはデュアル カードのスループットの 2.65 倍になります。 1つ
 オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
前に書かれたプロジェクトのリンク: https://nianticlabs.github.io/mickey/ 2 枚の写真が与えられた場合、それらの写真間の対応関係を確立することで、それらの間のカメラのポーズを推定できます。通常、これらの対応は 2D 対 2D であり、推定されたポーズはスケール不定です。いつでもどこでもインスタント拡張現実などの一部のアプリケーションでは、スケール メトリクスの姿勢推定が必要なため、スケールを回復するために外部深度推定器に依存します。この論文では、3D カメラ空間でのメトリックの対応を予測できるキーポイント マッチング プロセスである MicKey を提案します。画像全体の 3D 座標マッチングを学習することで、相対的なメトリックを推測できるようになります。
