

Python Celery を使用してスケジュールされたタスクを動的に追加する方法

1. 背景
実際の作業では、電子メールの送信やデータの取得など、スケジュールを設定する必要がある時間のかかる非同期タスクがいくつかあります。スクリプト
セロリを介してスケジューリングを実装する主なアイデアは、仲介者 Redis を導入し、タスク実行のためにワーカーを開始し、スケジュールされたタスク データ ストレージのためにセロリビートを導入することです
2. スケジュールされたタスクを動的に追加する Celery の公式ドキュメント
celery ドキュメント: https://docs.celeryproject.org/en/latest/userguide/periodic-tasks.html#beat-custom-schedulers
celery カスタム スケジューリング クラスの説明:
カスタム スケジューラ クラスはコマンド ライン (--scheduler パラメーター) で指定できます。
django-celery-beat ドキュメント: https://pypi. org/project/django-celery-beat/
django-celery-beat プラグインに関する説明:
この拡張機能を使用すると、定期的なタスクのスケジュールをデータベースに保存できます。定期的なタスクを管理できます。 Django 管理インターフェイスから、定期的なタスクを作成、編集、削除したり、タスクを実行する頻度を設定したりできます
3. Celery はシンプルで実用的です
3.1 基本的な環境構成
1. 最新バージョンの Django をインストールします
pip3 install django #当前我安装的版本是 3.0.6
2. プロジェクトを作成します
django-admin startproject typeidea django-admin startapp blog
3. celery をインストールします
pip3 install django-celery pip3 install -U Celery pip3 install "celery[librabbitmq,redis,auth,msgpack]" pip3 install django-celery-beat # 用于动态添加定时任务 pip3 install django-celery-results pip3 install redis
3.2 Celery アプリケーションを使用してテストします
1. ブログ ディレクトリを作成し、新しいタスクを作成します。py
まず、Django プロジェクトにブログ フォルダーを作成し、そのブログ フォルダーの下に task.py モジュールを作成します。
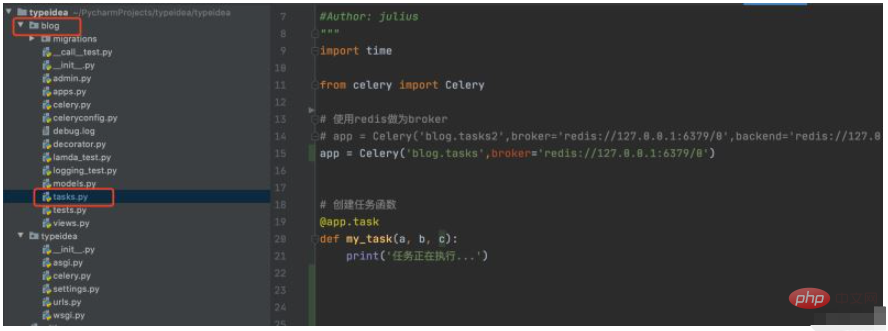
task.py コードは次のとおりです:
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
"""
#File: tasks.py
#Time: 2022/3/30 2:26 下午
#Author: julius
"""
from celery import Celery
# 使用redis做为broker
app = Celery('blog.tasks2',broker='redis://127.0.0.1:6379/0')
# 创建任务函数
@app.task
def my_task():
print('任务正在执行...')Celery の最初のパラメータは、名前を設定することです。2 番目のパラメータは次のとおりです。ここでは仲介者として Redis を使用します。 my_task関数は私たちが作成したタスク関数で、デコレータapp.taskを追加することでブローカーのキューに登録されます。
2. Redis を起動してワーカーを作成します
今、ワーカーを作成し、キュー内のタスクの処理を待機しています。
プロジェクトのルート ディレクトリを入力し、コマンド celery -A celery_tasks.tasks worker -l info
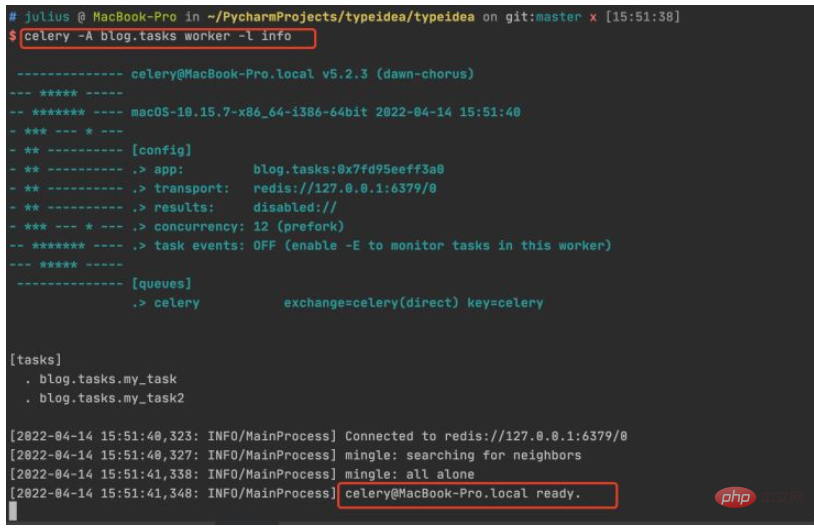
#3. タスクを呼び出します。
関数をテストし、タスクを作成してタスク キューに追加し、ワーカーを実行してみましょう。
入力して Python ターミナルを実行し、次のコードを実行します:
$ python manage.py shell >>> from blog.tasks import my_task >>> my_task.delay() <AsyncResult: 83484dfe-f729-417b-8e51-6c7ae32a1377>
タスク関数を呼び出すと、AsyncResult オブジェクトが返されます。このオブジェクトは、タスクのステータスを確認したり、戻り値を取得したりするために使用できます。タスクの。
4. 結果の確認
ワーカーの端末でタスクの実行ステータスを確認すると、83484dfe-f729-417b-8e51-6c7ae32a1377 タスクが実行されたことがわかります。タスク実行情報の取得

5. タスク実行ステータスの保存と表示
タスク実行結果の割り当てto ret, and then call result() will generated a DisabledBackend error. バックエンド ストレージが構成されていない場合、タスク実行のステータス情報を保存できないことがわかります。次のセクションでは、バックエンドを構成する方法について説明します。タスクの実行結果を保存する
$ python manage.py shell >>> from blog.tasks import my_task >>> ret=my_task.delay() >>> ret.result()
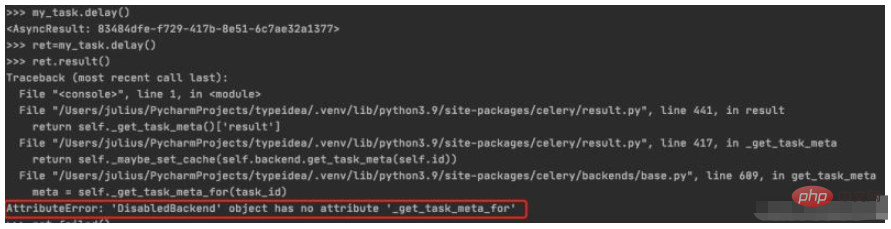
4. タスクの実行結果を保存するようにバックエンドを構成する
タスクのステータスを追跡したい場合、Celery は保存する必要があります。結果はどこかで。使用可能なストレージ オプションがいくつかあります: SQLAlchemy、Django ORM、Memcached、Redis、RPC (RabbitMQ/AMQP)。
1. バックエンド パラメーターを追加します
この例では、結果を保存するソリューションとして Redis を使用し、Celery のバックエンド パラメーターを通じてタスク結果の保存アドレスを設定します。タスク モジュールを次のように変更しました。
from celery import Celery
# 使用redis作为broker以及backend
app = Celery('celery_tasks.tasks',
broker='redis://127.0.0.1:6379/8',
backend='redis://127.0.0.1:6379/9')
# 创建任务函数
@app.task
def my_task(a, b):
print("任务函数正在执行....")
return a + bバックエンド パラメータを Celery に追加し、結果ストレージとして redis を指定し、タスク関数を 2 つのパラメータと戻り値に変更しました。
2. タスクの呼び出し/タスクの実行結果の表示
もう一度タスクを呼び出して確認してみましょう。
$ python manage.py shell >>> from blog.tasks import my_task >>> res=my_task.delay(10,40) >>> res.result 50 >>> res.failed() False
次のように、ワーカーの実行ステータスを見てみましょう:

セロリ タスクが正常に実行されたことがわかります。
しかし、これは単なる始まりにすぎません。次のステップでは、スケジュールされたタスクを追加する方法を確認します。
4. Celery ディレクトリ構造の最適化
上記のコードでは、Celery アプリケーションの作成、構成、およびタスクのタスクがすべて 1 つのファイルに直接書き込まれています。これにより、将来のプロジェクトが大きくなり不便になります。大きめです。これを分解して、一般的に使用されるパラメーターをいくつか追加してみましょう。
基本的な構造は次のとおりです
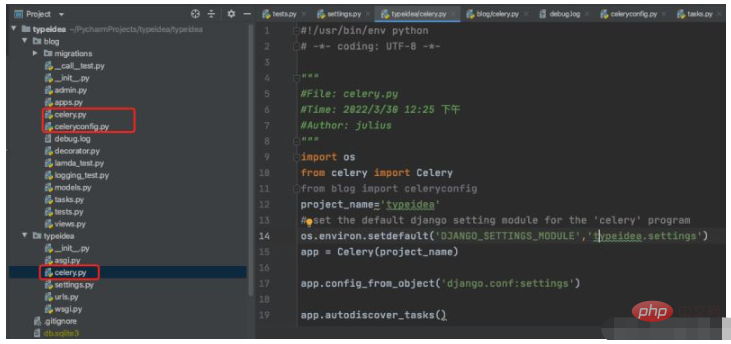
#!/usr/bin/env python # -*- coding: UTF-8 -*- """ #File: celery.py #Time: 2022/3/30 12:25 下午 #Author: julius """ import os from celery import Celery from blog import celeryconfig project_name='typeidea' # set the default django setting module for the 'celery' program os.environ.setdefault('DJANGO_SETTINGS_MODULE','typeidea.settings') app = Celery(project_name) app.config_from_object('django.conf:settings') app.autodiscover_tasks()
vim blog/celeryconfig.py (配置Celery的参数文件)
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
"""
#File: celeryconfig.py
#Time: 2022/3/30 2:54 下午
#Author: julius
"""
# 设置结果存储
from typeidea import settings
import os
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "typeidea.settings")
CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379/0'
# 设置代理人broker
BROKER_URL = 'redis://127.0.0.1:6379/1'
# celery 的启动工作数量设置
CELERY_WORKER_CONCURRENCY = 20
# 任务预取功能,就是每个工作的进程/线程在获取任务的时候,会尽量多拿 n 个,以保证获取的通讯成本可以压缩。
CELERYD_PREFETCH_MULTIPLIER = 20
# 非常重要,有些情况下可以防止死锁
CELERYD_FORCE_EXECV = True
# celery 的 worker 执行多少个任务后进行重启操作
CELERY_WORKER_MAX_TASKS_PER_CHILD = 100
# 禁用所有速度限制,如果网络资源有限,不建议开足马力。
CELERY_DISABLE_RATE_LIMITS = True
CELERY_ENABLE_UTC = False
CELERY_TIMEZONE = settings.TIME_ZONE
DJANGO_CELERY_BEAT_TZ_AWARE = False
CELERY_BEAT_SCHEDULER = 'django_celery_beat.schedulers:DatabaseScheduler'vim blog/tasks.py (tasks 任务文件)
import time
from blog.celery import app
# 创建任务函数
@app.task
def my_task(a, b, c):
print('任务正在执行...')
print('任务1函数休眠10s')
time.sleep(10)
return a + b + c五、开始使用django-celery-beat调度器
使用 django-celery-beat 动态添加定时任务 celery 4.x 版本在 django 框架中是使用 django-celery-beat 进行动态添加定时任务的。前面虽然已经安装了这个库,但是还要再说明一下。
1. 安装 django-celery-beat
pip3 install django-celery-beat
2.在项目的 settings 文件配置 django-celery-beat
INSTALLED_APPS = [
'blog',
'django_celery_beat',
...
]
# Django设置时区
LANGUAGE_CODE = 'zh-hans' # 使用中国语言
TIME_ZONE = 'Asia/Shanghai' # 设置Django使用中国上海时间
# 如果USE_TZ设置为True时,Django会使用系统默认设置的时区,此时的TIME_ZONE不管有没有设置都不起作用
# 如果USE_TZ 设置为False,TIME_ZONE = 'Asia/Shanghai', 则使用上海的UTC时间。
USE_TZ = False3. 创建 django-celery-beat 相关表
执行Django数据库迁移: python manage.py migrate

4. 配置Celery使用 django-celery-beat
配置 celery.py
import os
from celery import Celery
from blog import celeryconfig
# 为celery 设置环境变量
os.environ.setdefault("DJANGO_SETTINGS_MODULE","typeidea.settings")
# 创建celery app
app = Celery('blog')
# 从单独的配置模块中加载配置
app.config_from_object(celeryconfig)
# 设置app自动加载任务
app.autodiscover_tasks([
'blog',
])配置 celeryconfig.py
# 设置结果存储
from typeidea import settings
import os
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "typeidea.settings")
CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379/0'
# 设置代理人broker
BROKER_URL = 'redis://127.0.0.1:6379/1'
# celery 的启动工作数量设置
CELERY_WORKER_CONCURRENCY = 20
# 任务预取功能,就是每个工作的进程/线程在获取任务的时候,会尽量多拿 n 个,以保证获取的通讯成本可以压缩。
CELERYD_PREFETCH_MULTIPLIER = 20
# 非常重要,有些情况下可以防止死锁
CELERYD_FORCE_EXECV = True
# celery 的 worker 执行多少个任务后进行重启操作
CELERY_WORKER_MAX_TASKS_PER_CHILD = 100
# 禁用所有速度限制,如果网络资源有限,不建议开足马力。
CELERY_DISABLE_RATE_LIMITS = True
CELERY_ENABLE_UTC = False
CELERY_TIMEZONE = settings.TIME_ZONE
DJANGO_CELERY_BEAT_TZ_AWARE = False
CELERY_BEAT_SCHEDULER = 'django_celery_beat.schedulers:DatabaseScheduler'编写任务 tasks.py
import time
from celery import Celery
from blog.celery import app
# 使用redis做为broker
# app = Celery('blog.tasks2',broker='redis://127.0.0.1:6379/0',backend='redis://127.0.0.1:6379/1')
# 创建任务函数
@app.task
def my_task(a, b, c):
print('任务正在执行...')
print('任务1函数休眠10s')
time.sleep(10)
return a + b + c
@app.task
def my_task2():
print("任务2函数正在执行....")
print('任务2函数休眠10s')
time.sleep(10)5. 启动定时任务work
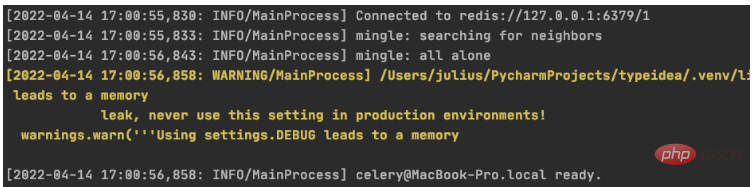
启动定时任务首先需要有一个work执行异步任务,然后再启动一个定时器触发任务。
启动任务 work
$ celery -A blog worker -l info
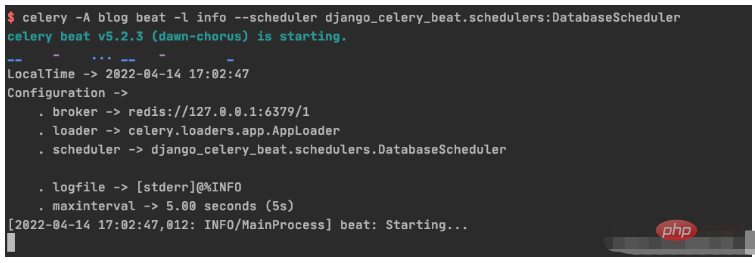
启动定时器触发 beat
celery -A blog beat -l info --scheduler django_celery_beat.schedulers:DatabaseScheduler
六、具体操作演练
6.1 创建基于间隔时间的周期性任务
1. 初始化周期间隔对象interval 对象
>>> from django_celery_beat.models import PeriodicTask, IntervalSchedule >>> schedule, created = IntervalSchedule.objects.get_or_create( ... every=10, ... period=IntervalSchedule.SECONDS, ... ) >>> IntervalSchedule.objects.all() <QuerySet [<IntervalSchedule: every 10 seconds>]>
2.创建一个无参数的周期性间隔任务
>>>PeriodicTask.objects.create(interval=schedule,name='my_task2',task='blog.tasks.my_task2',) <PeriodicTask: my_task2: every 10 seconds>
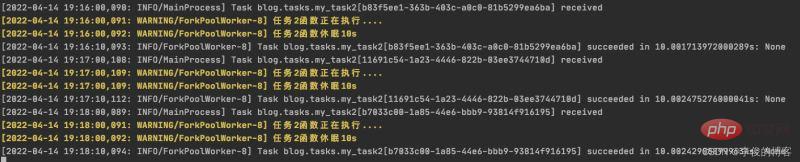
beat 调度服务日志显示如下:

worker 服务日志显示如下:

3.创建一个带参数的周期性间隔任务
>>> PeriodicTask.objects.create(interval=schedule,name='my_task',task='blog.tasks.my_task',args=json.dumps([10,20,30])) <PeriodicTask: my_task: every 10 seconds>
beat 调度服务日志结果:

worker 服务日志结果:

4.如何高并发执行任务
需要并行执行任务的时候,就需要设置多个worker来执行任务。
6.2 创建一个不带参数的周期性间隔任务
1.初始化 crontab 的调度对象
>>> import pytz >>> schedule, _ = CrontabSchedule.objects.get_or_create( ... minute='*', ... hour='*', ... day_of_week='*', ... day_of_month='*', ... timezone=pytz.timezone('Asia/Shanghai') ... )
2. 创建不带参数的定时任务
PeriodicTask.objects.create(crontab=schedule,name='my_task2_crontab',task='blog.tasks.my_task2',)
beat 调度服务执行结果

worker 执行服务结果
6.3 周期性任务的查询、删除操作
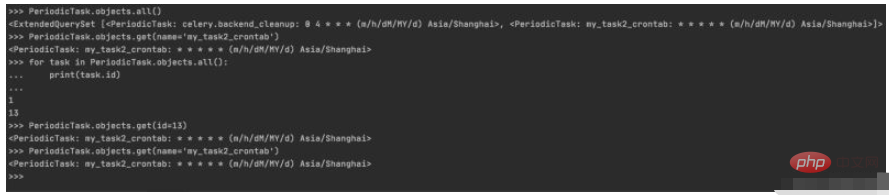
1. 周期性任务的查询
>>> PeriodicTask.objects.all() <ExtendedQuerySet [<PeriodicTask: celery.backend_cleanup: 0 4 * * * (m/h/dM/MY/d) Asia/Shanghai>, <PeriodicTask: my_task2_crontab: * * * * * (m/h/dM/MY/d) Asia/Shanghai>]> >>> PeriodicTask.objects.get(name='my_task2_crontab') <PeriodicTask: my_task2_crontab: * * * * * (m/h/dM/MY/d) Asia/Shanghai> >>> for task in PeriodicTask.objects.all(): ... print(task.id) ... 1 13 >>> PeriodicTask.objects.get(id=13) <PeriodicTask: my_task2_crontab: * * * * * (m/h/dM/MY/d) Asia/Shanghai> >>> PeriodicTask.objects.get(name='my_task2_crontab') <PeriodicTask: my_task2_crontab: * * * * * (m/h/dM/MY/d) Asia/Shanghai>
控制台实际操作记录
2.周期性任务的暂停/启动
2.1 设置my_taks2_crontab 暂停任务
>>> my_task2_crontab = PeriodicTask.objects.get(id=13) >>> my_task2_crontab.enabled True >>> my_task2_crontab.enabled=False >>> my_task2_crontab.save()
查看worker输出:

可以看到worker从19:31以后已经没有输出了,说明已经成功吧my_task2_crontab 任务暂停
2.2 设置my_task2_crontab 开启任务
把任务的 enabled 为 True 即可:
>>> my_task2_crontab.enabled False >>> my_task2_crontab.enabled=True >>> my_task2_crontab.save()
查看worker输出:
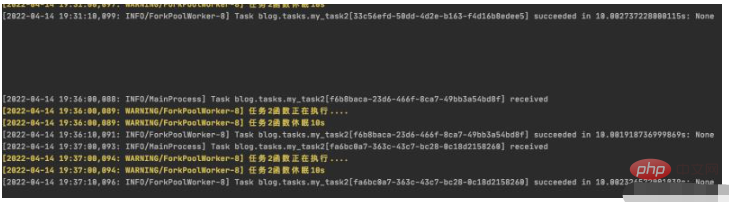
可以看到worker从19:36开始有输出,说明已把my_task2_crontab 任务重新启动
3. 周期性任务的删除
获取到指定的任务后调用delete(),再次查询指定任务会发现已经不存在了
PeriodicTask.objects.get(name='my_task2_crontab').delete()
>>> PeriodicTask.objects.get(name='my_task2_crontab')
Traceback (most recent call last):
File "<console>", line 1, in <module>
File "/Users/julius/PycharmProjects/typeidea/.venv/lib/python3.9/site-packages/django/db/models/manager.py", line 85, in manager_method
return getattr(self.get_queryset(), name)(*args, **kwargs)
File "/Users/julius/PycharmProjects/typeidea/.venv/lib/python3.9/site-packages/django/db/models/query.py", line 435, in get
raise self.model.DoesNotExist(
django_celery_beat.models.PeriodicTask.DoesNotExist: PeriodicTask matching query does not exist.以上がPython Celery を使用してスケジュールされたタスクを動的に追加する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7450
7450
 15
1374
52
77
11
14
8
15
1374
52
77
11
14
8

 PSが荷重を見せ続ける理由は何ですか?
Apr 06, 2025 pm 06:39 PM
PSが荷重を見せ続ける理由は何ですか?
Apr 06, 2025 pm 06:39 PM
PSの「読み込み」の問題は、リソースアクセスまたは処理の問題によって引き起こされます。ハードディスクの読み取り速度は遅いか悪いです。CrystaldiskInfoを使用して、ハードディスクの健康を確認し、問題のあるハードディスクを置き換えます。不十分なメモリ:高解像度の画像と複雑な層処理に対するPSのニーズを満たすためのメモリをアップグレードします。グラフィックカードドライバーは時代遅れまたは破損しています:ドライバーを更新して、PSとグラフィックスカードの間の通信を最適化します。ファイルパスが長すぎるか、ファイル名に特殊文字があります。短いパスを使用して特殊文字を避けます。 PS独自の問題:PSインストーラーを再インストールまたは修理します。
 PSの負荷速度をスピードアップする方法は?
Apr 06, 2025 pm 06:27 PM
PSの負荷速度をスピードアップする方法は?
Apr 06, 2025 pm 06:27 PM
Slow Photoshopの起動の問題を解決するには、次のような多面的なアプローチが必要です。ハードウェアのアップグレード(メモリ、ソリッドステートドライブ、CPU)。時代遅れまたは互換性のないプラグインのアンインストール。システムのゴミと過剰な背景プログラムを定期的にクリーンアップします。無関係なプログラムを慎重に閉鎖する。起動中に多数のファイルを開くことを避けます。
 PSが開始されたときにロードの問題を解決する方法は?
Apr 06, 2025 pm 06:36 PM
PSが開始されたときにロードの問題を解決する方法は?
Apr 06, 2025 pm 06:36 PM
ブートがさまざまな理由によって引き起こされる可能性がある場合、「読み込み」に巻き込まれたPS:腐敗したプラグインまたは競合するプラグインを無効にします。破損した構成ファイルの削除または名前変更。不十分なプログラムを閉じたり、メモリをアップグレードしたりして、メモリが不十分であることを避けます。ソリッドステートドライブにアップグレードして、ハードドライブの読み取りをスピードアップします。 PSを再インストールして、破損したシステムファイルまたはインストールパッケージの問題を修復します。エラーログ分析の起動プロセス中にエラー情報を表示します。
 HTML次ページ関数
Apr 06, 2025 am 11:45 AM
HTML次ページ関数
Apr 06, 2025 am 11:45 AM
<p>次のページ関数は、HTMLを介して作成できます。手順には、コンテナ要素の作成、コンテンツの分割、ナビゲーションリンクの追加、他のページの隠し、スクリプトの追加が含まれます。この機能により、ユーザーはセグメント化されたコンテンツを閲覧でき、一度に1つのページのみを表示し、大量のデータやコンテンツを表示するのに適しています。 </p>
 PSがファイルを開いたときにロードの問題を解決する方法は?
Apr 06, 2025 pm 06:33 PM
PSがファイルを開いたときにロードの問題を解決する方法は?
Apr 06, 2025 pm 06:33 PM
「ロード」は、PSでファイルを開くときに発生します。理由には、ファイルが大きすぎるか破損しているか、メモリが不十分で、ハードディスクの速度が遅い、グラフィックカードドライバーの問題、PSバージョンまたはプラグインの競合が含まれます。ソリューションは、ファイルのサイズと整合性を確認し、メモリの増加、ハードディスクのアップグレード、グラフィックカードドライバーの更新、不審なプラグインをアンインストールまたは無効にし、PSを再インストールします。この問題は、PSパフォーマンス設定を徐々にチェックして使用し、優れたファイル管理習慣を開発することにより、効果的に解決できます。
 遅いPSの読み込みはコンピューター構成に関連していますか?
Apr 06, 2025 pm 06:24 PM
遅いPSの読み込みはコンピューター構成に関連していますか?
Apr 06, 2025 pm 06:24 PM
PSの負荷が遅い理由は、ハードウェア(CPU、メモリ、ハードディスク、グラフィックスカード)とソフトウェア(システム、バックグラウンドプログラム)の影響を組み合わせたものです。ソリューションには、ハードウェアのアップグレード(特にソリッドステートドライブの交換)、ソフトウェアの最適化(システムガベージのクリーンアップ、ドライバーの更新、PS設定のチェック)、およびPSファイルの処理が含まれます。定期的なコンピューターのメンテナンスは、PSのランニング速度を改善するのにも役立ちます。
 PSが常にロードされていることを常に示しているときに、ロードの問題を解決する方法は?
Apr 06, 2025 pm 06:30 PM
PSが常にロードされていることを常に示しているときに、ロードの問題を解決する方法は?
Apr 06, 2025 pm 06:30 PM
PSカードは「ロード」ですか?ソリューションには、コンピューターの構成(メモリ、ハードディスク、プロセッサ)の確認、ハードディスクの断片化のクリーニング、グラフィックカードドライバーの更新、PS設定の調整、PSの再インストール、優れたプログラミング習慣の開発が含まれます。
 PDFエクスポートはPSによってバッチでエクスポートできますか?
Apr 06, 2025 pm 04:54 PM
PDFエクスポートはPSによってバッチでエクスポートできますか?
Apr 06, 2025 pm 04:54 PM
PSでバッチでPDFをエクスポートするには3つの方法があります。PSアクション関数を使用します。ファイルを記録および開き、PDFアクションをエクスポートし、ループでアクションを実行します。サードパーティのソフトウェアを使用して、ファイル管理ソフトウェアまたは自動化ツールを使用して、入力フォルダーと出力フォルダーを指定し、ファイル名形式を設定します。スクリプトを使用:スクリプトを書き込み、バッチエクスポートロジックをカスタマイズしますが、プログラミングの知識が必要です。
