

SpringBoot が Kafka ツールクラスを統合する方法

カフカとは何ですか?
Kafka は、Apache Software Foundation によって開発され、Scala と Java で書かれたオープン ソースのストリーム処理プラットフォームです。 Kafka は、Web サイト内の消費者のすべてのアクション ストリーミング データを処理できる、高スループットの分散型パブリッシュ/サブスクライブ メッセージング システムです。このようなアクション (Web ブラウジング、検索、その他のユーザー アクション) は、現代の Web 上の多くのソーシャル機能の重要な要素です。通常、このデータは、スループット要件のため、ログの処理とログの集計によって処理されます。これは、ログ データや Hadoop などのオフライン分析システムにとっては実現可能なソリューションですが、リアルタイム処理の制約が必要です。 Kafka の目的は、Hadoop の並列読み込みメカニズムを通じてオンラインとオフラインのメッセージ処理を統合し、クラスターを通じてリアルタイム メッセージを提供することです。
アプリケーション シナリオ
メッセージ システム: Kafka と従来のメッセージ システム (メッセージ ミドルウェアとも呼ばれる) はどちらも、システムの分離、冗長ストレージ、トラフィックのピークカットを備えています。非同期通信、スケーラビリティ、リカバリ性などの機能。同時に、Kafka は、ほとんどのメッセージング システムでは実現が難しいメッセージ シーケンスの保証と遡及的な消費機能も提供します。
ストレージ システム: Kafka はメッセージをディスクに保存するため、他のメモリ ストレージ ベースのシステムと比較してデータ損失のリスクが効果的に軽減されます。 Kafka のメッセージ永続化機能とマルチコピー メカニズムのおかげで、対応するデータ保持ポリシーを「永続」に設定するか、トピックのログ圧縮機能を有効にするだけで、Kafka を長期データ ストレージ システムとして使用できます。それでおしまい。
ストリーミング処理プラットフォーム: Kafka は、一般的なストリーミング フレームワークごとに信頼できるデータ ソースを提供するだけでなく、ウィンドウ、結合、変換などのさまざまな操作などの完全なストリーミング クラス ライブラリも提供します。そして集合体。
SpringBoot を統合する Kafka ツール クラスの詳細なコードを見てみましょう。
pom.xml
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.6.3</version>
</dependency>
<dependency>
<groupId>fastjson</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.83</version>
</dependency>ツールクラス
package com.bbl.demo.utils;
import org.apache.commons.lang3.exception.ExceptionUtils;
import org.apache.kafka.clients.admin.*;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.KafkaFuture;
import org.apache.kafka.common.errors.TopicExistsException;
import org.apache.kafka.common.errors.UnknownTopicOrPartitionException;
import com.alibaba.fastjson.JSONObject;
import java.time.Duration;
import java.util.*;
import java.util.concurrent.ExecutionException;
public class KafkaUtils {
private static AdminClient admin;
/**
* 私有静态方法,创建Kafka生产者
* @author o
* @return KafkaProducer
*/
private static KafkaProducer<String, String> createProducer() {
Properties props = new Properties();
//声明kafka的地址
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"node01:9092,node02:9092,node03:9092");
//0、1 和 all:0表示只要把消息发送出去就返回成功;1表示只要Leader收到消息就返回成功;all表示所有副本都写入数据成功才算成功
props.put("acks", "all");
//重试次数
props.put("retries", Integer.MAX_VALUE);
//批处理的字节数
props.put("batch.size", 16384);
//批处理的延迟时间,当批次数据未满之时等待的时间
props.put("linger.ms", 1);
//用来约束KafkaProducer能够使用的内存缓冲的大小的,默认值32MB
props.put("buffer.memory", 33554432);
// properties.put("value.serializer",
// "org.apache.kafka.common.serialization.ByteArraySerializer");
// properties.put("key.serializer",
// "org.apache.kafka.common.serialization.ByteArraySerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
return new KafkaProducer<String, String>(props);
}
/**
* 私有静态方法,创建Kafka消费者
* @author o
* @return KafkaConsumer
*/
private static KafkaConsumer<String, String> createConsumer() {
Properties props = new Properties();
//声明kafka的地址
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"node01:9092,node02:9092,node03:9092");
//每个消费者分配独立的消费者组编号
props.put("group.id", "111");
//如果value合法,则自动提交偏移量
props.put("enable.auto.commit", "true");
//设置多久一次更新被消费消息的偏移量
props.put("auto.commit.interval.ms", "1000");
//设置会话响应的时间,超过这个时间kafka可以选择放弃消费或者消费下一条消息
props.put("session.timeout.ms", "30000");
//自动重置offset
props.put("auto.offset.reset","earliest");
// properties.put("value.serializer",
// "org.apache.kafka.common.serialization.ByteArraySerializer");
// properties.put("key.serializer",
// "org.apache.kafka.common.serialization.ByteArraySerializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
return new KafkaConsumer<String, String>(props);
}
/**
* 私有静态方法,创建Kafka集群管理员对象
* @author o
*/
public static void createAdmin(String servers){
Properties props = new Properties();
props.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG,servers);
admin = AdminClient.create(props);
}
/**
* 私有静态方法,创建Kafka集群管理员对象
* @author o
* @return AdminClient
*/
private static void createAdmin(){
createAdmin("node01:9092,node02:9092,node03:9092");
}
/**
* 传入kafka约定的topic,json格式字符串,发送给kafka集群
* @author o
* @param topic
* @param jsonMessage
*/
public static void sendMessage(String topic, String jsonMessage) {
KafkaProducer<String, String> producer = createProducer();
producer.send(new ProducerRecord<String, String>(topic, jsonMessage));
producer.close();
}
/**
* 传入kafka约定的topic消费数据,用于测试,数据最终会输出到控制台上
* @author o
* @param topic
*/
public static void consume(String topic) {
KafkaConsumer<String, String> consumer = createConsumer();
consumer.subscribe(Arrays.asList(topic));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(100));
for (ConsumerRecord<String, String> record : records){
System.out.printf("offset = %d, key = %s, value = %s",record.offset(), record.key(), record.value());
System.out.println();
}
}
}
/**
* 传入kafka约定的topic数组,消费数据
* @author o
* @param topics
*/
public static void consume(String ... topics) {
KafkaConsumer<String, String> consumer = createConsumer();
consumer.subscribe(Arrays.asList(topics));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(100));
for (ConsumerRecord<String, String> record : records){
System.out.printf("offset = %d, key = %s, value = %s",record.offset(), record.key(), record.value());
System.out.println();
}
}
}
/**
* 传入kafka约定的topic,json格式字符串数组,发送给kafka集群
* 用于批量发送消息,性能较高。
* @author o
* @param topic
* @param jsonMessages
* @throws InterruptedException
*/
public static void sendMessage(String topic, String... jsonMessages) throws InterruptedException {
KafkaProducer<String, String> producer = createProducer();
for (String jsonMessage : jsonMessages) {
producer.send(new ProducerRecord<String, String>(topic, jsonMessage));
}
producer.close();
}
/**
* 传入kafka约定的topic,Map集合,内部转为json发送给kafka集群 <br>
* 用于批量发送消息,性能较高。
* @author o
* @param topic
* @param mapMessageToJSONForArray
*/
public static void sendMessage(String topic, List<Map<Object, Object>> mapMessageToJSONForArray) {
KafkaProducer<String, String> producer = createProducer();
for (Map<Object, Object> mapMessageToJSON : mapMessageToJSONForArray) {
String array = JSONObject.toJSON(mapMessageToJSON).toString();
producer.send(new ProducerRecord<String, String>(topic, array));
}
producer.close();
}
/**
* 传入kafka约定的topic,Map,内部转为json发送给kafka集群
* @author o
* @param topic
* @param mapMessageToJSON
*/
public static void sendMessage(String topic, Map<Object, Object> mapMessageToJSON) {
KafkaProducer<String, String> producer = createProducer();
String array = JSONObject.toJSON(mapMessageToJSON).toString();
producer.send(new ProducerRecord<String, String>(topic, array));
producer.close();
}
/**
* 创建主题
* @author o
* @param name 主题的名称
* @param numPartitions 主题的分区数
* @param replicationFactor 主题的每个分区的副本因子
*/
public static void createTopic(String name,int numPartitions,int replicationFactor){
if(admin == null) {
createAdmin();
}
Map<String, String> configs = new HashMap<>();
CreateTopicsResult result = admin.createTopics(Arrays.asList(new NewTopic(name, numPartitions, (short) replicationFactor).configs(configs)));
//以下内容用于判断创建主题的结果
for (Map.Entry<String, KafkaFuture<Void>> entry : result.values().entrySet()) {
try {
entry.getValue().get();
System.out.println("topic "+entry.getKey()+" created");
} catch (InterruptedException | ExecutionException e) {
if (ExceptionUtils.getRootCause(e) instanceof TopicExistsException) {
System.out.println("topic "+entry.getKey()+" existed");
}
}
}
}
/**
* 删除主题
* @author o
* @param names 主题的名称
*/
public static void deleteTopic(String name,String ... names){
if(admin == null) {
createAdmin();
}
Map<String, String> configs = new HashMap<>();
Collection<String> topics = Arrays.asList(names);
topics.add(name);
DeleteTopicsResult result = admin.deleteTopics(topics);
//以下内容用于判断删除主题的结果
for (Map.Entry<String, KafkaFuture<Void>> entry : result.values().entrySet()) {
try {
entry.getValue().get();
System.out.println("topic "+entry.getKey()+" deleted");
} catch (InterruptedException | ExecutionException e) {
if (ExceptionUtils.getRootCause(e) instanceof UnknownTopicOrPartitionException) {
System.out.println("topic "+entry.getKey()+" not exist");
}
}
}
}
/**
* 查看主题详情
* @author o
* @param names 主题的名称
*/
public static void describeTopic(String name,String ... names){
if(admin == null) {
createAdmin();
}
Map<String, String> configs = new HashMap<>();
Collection<String> topics = Arrays.asList(names);
topics.add(name);
DescribeTopicsResult result = admin.describeTopics(topics);
//以下内容用于显示主题详情的结果
for (Map.Entry<String, KafkaFuture<TopicDescription>> entry : result.values().entrySet()) {
try {
entry.getValue().get();
System.out.println("topic "+entry.getKey()+" describe");
System.out.println("\t name: "+entry.getValue().get().name());
System.out.println("\t partitions: ");
entry.getValue().get().partitions().stream().forEach(p-> {
System.out.println("\t\t index: "+p.partition());
System.out.println("\t\t\t leader: "+p.leader());
System.out.println("\t\t\t replicas: "+p.replicas());
System.out.println("\t\t\t isr: "+p.isr());
});
System.out.println("\t internal: "+entry.getValue().get().isInternal());
} catch (InterruptedException | ExecutionException e) {
if (ExceptionUtils.getRootCause(e) instanceof UnknownTopicOrPartitionException) {
System.out.println("topic "+entry.getKey()+" not exist");
}
}
}
}
/**
* 查看主题列表
* @author o
* @return Set<String> TopicList
*/
public static Set<String> listTopic(){
if(admin == null) {
createAdmin();
}
ListTopicsResult result = admin.listTopics();
try {
result.names().get().stream().map(x->x+"\t").forEach(System.out::print);
return result.names().get();
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
return null;
}
}
public static void main(String[] args) {
System.out.println(listTopic());
}
}以上がSpringBoot が Kafka ツールクラスを統合する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7338
7338
 9
1627
14
1352
46
1265
25
1209
29
9
1627
14
1352
46
1265
25
1209
29

 PHP と Kafka を使用してリアルタイム株価分析を実装する方法
Jun 28, 2023 am 10:04 AM
PHP と Kafka を使用してリアルタイム株価分析を実装する方法
Jun 28, 2023 am 10:04 AM
インターネットとテクノロジーの発展に伴い、デジタル投資への関心が高まっています。多くの投資家は、より高い投資収益率を得ることを期待して、投資戦略を模索し、研究し続けています。株式取引では、リアルタイムの株式分析が意思決定に非常に重要であり、Kafka のリアルタイム メッセージ キューと PHP テクノロジの使用は効率的かつ実用的な手段です。 1. Kafka の概要 Kafka は、LinkedIn によって開発された高スループットの分散型パブリッシュおよびサブスクライブ メッセージング システムです。 Kafka の主な機能は次のとおりです。
 SpringBootとSpringMVCの比較と差異分析
Dec 29, 2023 am 11:02 AM
SpringBootとSpringMVCの比較と差異分析
Dec 29, 2023 am 11:02 AM
SpringBoot と SpringMVC はどちらも Java 開発で一般的に使用されるフレームワークですが、それらの間には明らかな違いがいくつかあります。この記事では、これら 2 つのフレームワークの機能と使用法を調べ、その違いを比較します。まず、SpringBoot について学びましょう。 SpringBoot は、Spring フレームワークに基づいたアプリケーションの作成と展開を簡素化するために、Pivotal チームによって開発されました。スタンドアロンの実行可能ファイルを構築するための高速かつ軽量な方法を提供します。
 Kafkaを探索するための可視化ツール5選
Feb 01, 2024 am 08:03 AM
Kafkaを探索するための可視化ツール5選
Feb 01, 2024 am 08:03 AM
Kafka 視覚化ツールの 5 つのオプション ApacheKafka は、大量のリアルタイム データを処理できる分散ストリーム処理プラットフォームです。これは、リアルタイム データ パイプライン、メッセージ キュー、イベント駆動型アプリケーションの構築に広く使用されています。 Kafka の視覚化ツールは、ユーザーが Kafka クラスターを監視および管理し、Kafka データ フローをより深く理解するのに役立ちます。以下は、5 つの人気のある Kafka 視覚化ツールの紹介です。 ConfluentControlCenterConfluent
 Kafka 視覚化ツールの比較分析: 最適なツールを選択するには?
Jan 05, 2024 pm 12:15 PM
Kafka 視覚化ツールの比較分析: 最適なツールを選択するには?
Jan 05, 2024 pm 12:15 PM
適切な Kafka 視覚化ツールを選択するにはどうすればよいですか? 5 つのツールの比較分析 はじめに: Kafka は、ビッグ データの分野で広く使用されている、高性能、高スループットの分散メッセージ キュー システムです。 Kafka の人気に伴い、Kafka クラスターを簡単に監視および管理するためのビジュアル ツールを必要とする企業や開発者が増えています。この記事では、読者がニーズに合ったツールを選択できるように、一般的に使用される 5 つの Kafka 視覚化ツールを紹介し、その特徴と機能を比較します。 1.カフカマネージャー
 SpringBoot+Dubbo+Nacos開発実践チュートリアル
Aug 15, 2023 pm 04:49 PM
SpringBoot+Dubbo+Nacos開発実践チュートリアル
Aug 15, 2023 pm 04:49 PM
この記事では、dubbo+nacos+Spring Boot の実際の開発について詳しく説明する例を書きます。この記事では理論的な知識はあまり取り上げませんが、dubbo を nacos と統合して開発環境を迅速に構築する方法を説明する最も簡単な例を書きます。
 Rocky Linux に Apache Kafka をインストールするにはどうすればよいですか?
Mar 01, 2024 pm 10:37 PM
Rocky Linux に Apache Kafka をインストールするにはどうすればよいですか?
Mar 01, 2024 pm 10:37 PM
RockyLinux に ApacheKafka をインストールするには、次の手順に従います。 システムの更新: まず、RockyLinux システムが最新であることを確認し、次のコマンドを実行してシステム パッケージを更新します: sudoyumupdate Java のインストール: ApacheKafka は Java に依存しているため、最初に JavaDevelopmentKit (JDK) をインストールします)。 OpenJDK は、次のコマンドを使用してインストールできます。 sudoyuminstalljava-1.8.0-openjdk-devel ダウンロードして解凍します。 ApacheKafka 公式 Web サイト () にアクセスして、最新のバイナリ パッケージをダウンロードします。安定したバージョンを選択してください
 go-zero と Kafka+Avro の実践: 高性能対話型データ処理システムの構築
Jun 23, 2023 am 09:04 AM
go-zero と Kafka+Avro の実践: 高性能対話型データ処理システムの構築
Jun 23, 2023 am 09:04 AM
近年、ビッグ データと活発なオープン ソース コミュニティの台頭により、ますます多くの企業が増大するデータ ニーズを満たすために高性能の対話型データ処理システムを探し始めています。このテクノロジー アップグレードの波の中で、go-zero と Kafka+Avro はますます多くの企業に注目され、採用されています。 go-zero は、Golang 言語をベースに開発されたマイクロサービス フレームワークで、高いパフォーマンス、使いやすさ、拡張の容易さ、メンテナンスの容易さという特徴を備えており、企業が効率的なマイクロサービス アプリケーション システムを迅速に構築できるように設計されています。その急速な成長
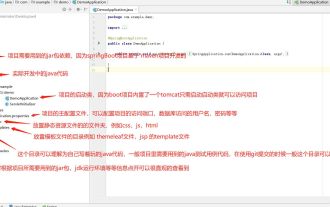 springBoot プロジェクトで一般的に使用されるディレクトリは何ですか?
Jun 27, 2023 pm 01:42 PM
springBoot プロジェクトで一般的に使用されるディレクトリは何ですか?
Jun 27, 2023 pm 01:42 PM
SpringBootプロジェクトでよく使われるディレクトリ SpringBoot開発時のディレクトリ構成と命名仕様を基に、SpringBootプロジェクトのディレクトリ構成と命名仕様を紹介します 導入を通じて問題解決をお手伝いします 実際のディレクトリ構成の計画方法プロジェクト?ディレクトリにもっと標準化された名前を付けるにはどうすればよいでしょうか?各ディレクトリは何を意味しますか? 3 つの質問をお待ちください。ディレクトリの説明 servicex//プロジェクト名|-admin-ui//管理サービス フロントエンド コード (通常、管理を容易にするために、UI とサービスは 1 つのプロジェクトにまとめられます)|-servicex-auth//モジュール 1|-servicex-common//モジュール 2|-servicex-gateway//モジュール 3|
