

OpenAI の新世代モデルはオープンソースの爆発です!清華大学卒業生の宋楊氏の作品、「拡散」よりも速くて強い

画像生成の分野は再び変化しているようです。
たった今、OpenAI は拡散モデルよりも高速で優れた一貫性モデルをオープンソース化しました:
敵対的トレーニングなしで高品質の画像を生成できます。
この大ヒットニュースが発表されるやいなや、学界はたちまち爆発しました。

論文自体は 3 月に控えめに発表されましたが、当時は OpenAI と詳細は実際には公開されません。

予想外なことに、今回はオープンソースが直接登場しました。一部のネチズンはすぐに効果のテストを開始し、約 64 枚の 256×256 画像を生成するのに約 3.5 秒しかかからないことを発見しました:
ゲーム オーバー!

これはこのネチズンによって生成された画像効果です。非常に良く見えます:

これもネチズンです冗談: 今回はついに OpenAI がオープンしました!

この論文の筆頭著者である OpenAI 科学者 Song Yang 氏は清華大学の卒業生であり、16 歳で清華大学の基礎数学と科学に入学したことは注目に値します。リーダーシッププログラムを通じてクラスを受講します。
今回はOpenAIがどのような研究をオープンソース化しているのかを見てみましょう。
どのような大ヒット研究がオープンソース化されていますか?
画像生成AIとしてのConsistency Modelの最大の特徴は高速で優れていることです。
拡散モデルと比較すると、これには 2 つの主な利点があります:
まず、敵対的トレーニングを行わずに高品質の画像サンプルを直接生成できます。
第二に、数百、さらには数千の反復を必要とする拡散モデルと比較して、一貫性モデルでは、カラーリング、ノイズ除去、スーパー スコアリングなどのさまざまな画像タスクを処理するのに 1 つまたは 2 つのステップしか必要としません。 . はすべて、これらのタスクに関する明示的なトレーニングを必要とせず、いくつかの手順で実行できます。 (もちろん、少数サンプル学習を実行すると、生成効果はより良くなります)
 それでは、整合性モデルはどのようにしてこの効果を達成するのでしょうか?
それでは、整合性モデルはどのようにしてこの効果を達成するのでしょうか?
原理的な観点から見ると、整合性モデルの誕生は ODE (常微分方程式) 生成拡散モデルに関連しています。
図からわかるように、ODE はまず画像データを段階的にノイズに変換し、次に逆の解法を実行してノイズから画像を生成する方法を学習します。
このプロセスでは、著者らは生成モデリングのために ODE 軌道上の任意の点 (Xt、Xt、Xr など) をその原点 (X0 など) にマッピングしようとしました。
その後、このマッピングされたモデルは、出力がすべて同じ軌道上の同じ点にあるため、整合性モデルと名付けられました。
 これに基づくアイデア一貫性モデルは、比較的高品質のイメージを生成するために長い反復を行う必要がなくなり、ワン ステップで生成できるようになりました。
これに基づくアイデア一貫性モデルは、比較的高品質のイメージを生成するために長い反復を行う必要がなくなり、ワン ステップで生成できるようになりました。
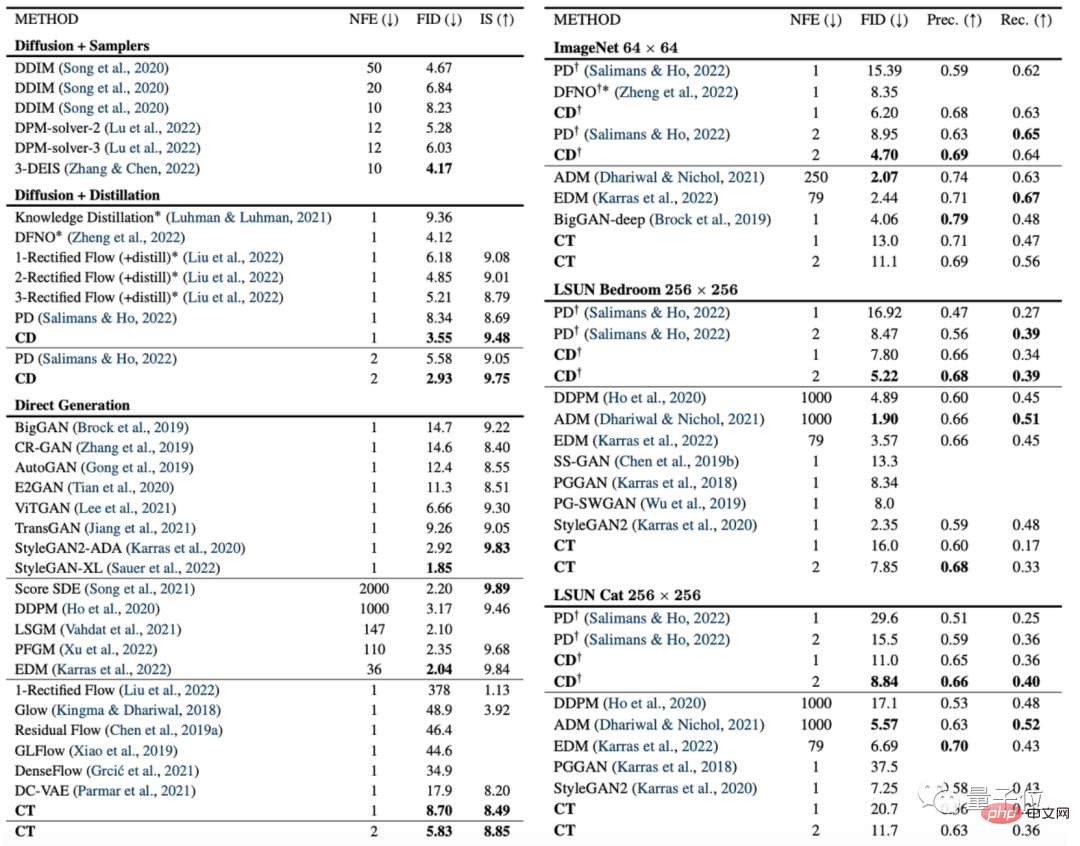
次の図は、画像生成指標 FID に関する一貫性モデル (CD) と拡散モデル (PD) の比較です。
このうち、PDとはスタンフォード大学とGoogle Brainが昨年提案した最新の普及モデル手法である漸進蒸留(プログレッシブ蒸留)の略称で、CD(コンシステンシー蒸留)は一貫性蒸留法のことです。
ほとんどすべてのデータ セットで、一貫性モデルの画像生成効果が拡散モデルの画像生成効果より優れていることがわかります。唯一の例外は 256×256 の部屋データ セットです:
 さらに、著者らは、拡散モデル、一貫性モデル、GAN、および他のさまざまなデータセット上の他のモデルも比較しました。
さらに、著者らは、拡散モデル、一貫性モデル、GAN、および他のさまざまなデータセット上の他のモデルも比較しました。
しかし、一部のネチズンは、オープンソース AI 一貫性モデルによって生成された画像がまだ小さすぎると述べています:
この画像がオープンソースであることは悲しいことです生成されるバージョンがまだ小さすぎるため、より大きな画像を生成するオープンソース バージョンが提供されれば、非常にエキサイティングです。
# 一部のネチズンは、OpenAI がまだトレーニングされていないのではないかと推測しています。しかし、おそらくトレーニング後にコード(手動の犬の頭)を取得できない可能性があります。
しかし、この作業の重要性について、TechCrunch は次のように述べています:
GPU が多数ある場合は、拡散モデルを使用して 1 ~ 2 分で 1,500 回以上反復し、確かに画像生成効果は非常に良いですね。
しかし、携帯電話上で、またはチャットでの会話中にリアルタイムで画像を生成したい場合は、明らかに拡散モデルが最良の選択ではありません。
一貫性モデルは、OpenAI の次の重要な動きです。
OpenAI が高解像度の画像生成 AI の波をオープンソース化することを願っています~
清華大学の卒業生、宋楊が論文の最初の著者です
宋楊は論文の最初の著者です論文の著者であり、現在は OpenAI の研究員です。

#14 歳のとき、17 人の審査員の満場一致投票で「清華大学新 100 周年リーダーシップ プログラム」に選ばれました。翌年の大学入学試験では、連雲港市の理科でトップの成績を収め、清華大学に合格した。
2016 年、ソン ヤンは清華大学の基礎数学と物理学のクラスを卒業し、その後、スタンフォード大学に進学しました。 2022 年に、Song Yang はスタンフォード大学でコンピューター サイエンスの博士号を取得し、その後 OpenAI に入社しました。
博士課程在学中の最初の論文「確率微分方程式によるスコアベースの生成モデリング」も、ICLR 2021 Outstanding Paper Awardを受賞しました。

個人ホームページの情報によると、ソン・ヤン氏は2024年1月からカリフォルニア工科大学電子・計算数科学学科に助手として正式に加わる予定です。教授。
プロジェクトアドレス:
https://www.php.cn/link/4845b84d63ea5fa8df6268b8d1616a8f
論文アドレス:
https://www.php.cn/link/5f25fbe144e4a81a1b0080b6c1032778
参考リンク:
[1]https://twitter.com/alfredplpl/status/1646217811898011648
[2]https://twitter.com/_akhaliq/status/1646168119658831874
以上がOpenAI の新世代モデルはオープンソースの爆発です!清華大学卒業生の宋楊氏の作品、「拡散」よりも速くて強いの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7698
7698
 15
1640
14
1393
52
1287
25
1229
29
15
1640
14
1393
52
1287
25
1229
29

 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
 オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
前に書かれたプロジェクトのリンク: https://nianticlabs.github.io/mickey/ 2 枚の写真が与えられた場合、それらの写真間の対応関係を確立することで、それらの間のカメラのポーズを推定できます。通常、これらの対応は 2D 対 2D であり、推定されたポーズはスケール不定です。いつでもどこでもインスタント拡張現実などの一部のアプリケーションでは、スケール メトリクスの姿勢推定が必要なため、スケールを回復するために外部深度推定器に依存します。この論文では、3D カメラ空間でのメトリックの対応を予測できるキーポイント マッチング プロセスである MicKey を提案します。画像全体の 3D 座標マッチングを学習することで、相対的なメトリックを推測できるようになります。
 Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
FP8 以下の浮動小数点数値化精度は、もはや H100 の「特許」ではありません。 Lao Huang は誰もが INT8/INT4 を使用できるようにしたいと考え、Microsoft DeepSpeed チームは NVIDIA からの公式サポートなしで A100 上で FP6 の実行を開始しました。テスト結果は、A100 での新しい方式 TC-FPx の FP6 量子化が INT4 に近いか、場合によってはそれよりも高速であり、後者よりも精度が高いことを示しています。これに加えて、エンドツーエンドの大規模モデルのサポートもあり、オープンソース化され、DeepSpeed などの深層学習推論フレームワークに統合されています。この結果は、大規模モデルの高速化にも即座に影響します。このフレームワークでは、シングル カードを使用して Llama を実行すると、スループットはデュアル カードのスループットの 2.65 倍になります。 1つ
 OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
AIモデルによって与えられた答えがまったく理解できない場合、あなたはそれをあえて使用しますか?機械学習システムがより重要な分野で使用されるにつれて、なぜその出力を信頼できるのか、またどのような場合に信頼してはいけないのかを実証することがますます重要になっています。複雑なシステムの出力に対する信頼を得る方法の 1 つは、人間または他の信頼できるシステムが読み取れる、つまり、考えられるエラーが発生する可能性がある点まで完全に理解できる、その出力の解釈を生成することをシステムに要求することです。見つかった。たとえば、司法制度に対する信頼を築くために、裁判所に対し、決定を説明し裏付ける明確で読みやすい書面による意見を提供することを求めています。大規模な言語モデルの場合も、同様のアプローチを採用できます。ただし、このアプローチを採用する場合は、言語モデルが
 総合的にDPOを超える:Chen Danqi氏のチームはシンプルなプリファレンス最適化SimPOを提案し、最強の8Bオープンソースモデルも洗練させた
Jun 01, 2024 pm 04:41 PM
総合的にDPOを超える:Chen Danqi氏のチームはシンプルなプリファレンス最適化SimPOを提案し、最強の8Bオープンソースモデルも洗練させた
Jun 01, 2024 pm 04:41 PM
大規模言語モデル (LLM) を人間の価値観や意図に合わせるには、人間のフィードバックを学習して、それが有用で、正直で、無害であることを確認することが重要です。 LLM を調整するという点では、ヒューマン フィードバックに基づく強化学習 (RLHF) が効果的な方法です。 RLHF 法の結果は優れていますが、最適化にはいくつかの課題があります。これには、報酬モデルをトレーニングし、その報酬を最大化するためにポリシー モデルを最適化することが含まれます。最近、一部の研究者はより単純なオフライン アルゴリズムを研究しており、その 1 つが直接優先最適化 (DPO) です。 DPO は、RLHF の報酬関数をパラメータ化することで、選好データに基づいてポリシー モデルを直接学習するため、明示的な報酬モデルの必要性がなくなります。この方法は簡単で安定しています
