

Meta の「Divide Everything」の登場により、多くの人が CV はもう存在しないと叫んだ。
このモデルに基づいて、多くのネチズンがグラウンデッド SAM などのさらなる作業を行っています。
Stable Diffusion、Whisper、ChatGPT を組み合わせることで、音声を通じて犬を猿に変えることができます。

そして、音声だけでなく、マルチモーダル プロンプトを通じてあらゆる場所を一度にセグメント化できるようになりました。
具体的にはどうすればよいでしょうか?
#マウスをクリックして分割コンテンツを直接選択します。




さまざまな種類のキュー、視覚的なキュー (点、マーク、ボックス、落書き、画像の断片)、および言語的なキュー (テキストとオーディオ) を使用して、SEEM で画像を簡単にセグメント化します。

# この論文のタイトルで興味深いのは、2022 年に公開されたアメリカの SF 映画「Everything Everywhere All at Once」の名前に非常に似ていることです。
NVIDIA の科学者 Jim Fan 氏は、オスカー賞の最優秀論文のタイトルは「Segment Everything Everywhere All at Once」になると述べました
統合された多用途のタスク仕様インターフェイスを持つことは、大規模な基本モデルをスケールアップするための鍵となります。マルチモーダル プロンプトは未来の方法です。
論文を読んだ後、ネチズンは、CV はこれから大きなモデルを採用し始めるだろうと言いました。学生? ? 
#Oscar Best Title Paper
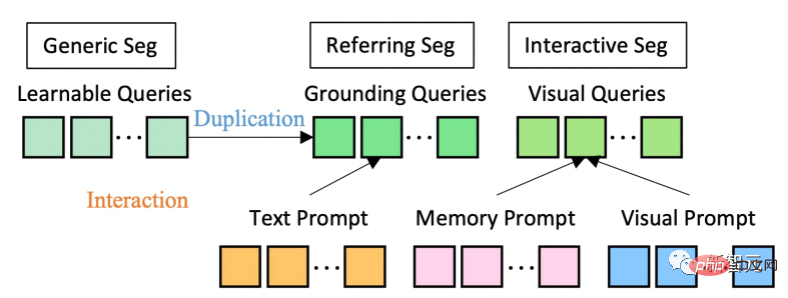
 は、以下に基づいた LLM の共通インターフェイスの開発に触発されました。研究者らは SEEM を提案しました。
は、以下に基づいた LLM の共通インターフェイスの開発に触発されました。研究者らは SEEM を提案しました。
図に示すように、SEEM モデルは、セマンティック セグメンテーション、インスタンス セグメンテーション、パノラマ セグメンテーションなど、オープン セット内のあらゆるセグメンテーション タスクをヒントなしで実行できます。
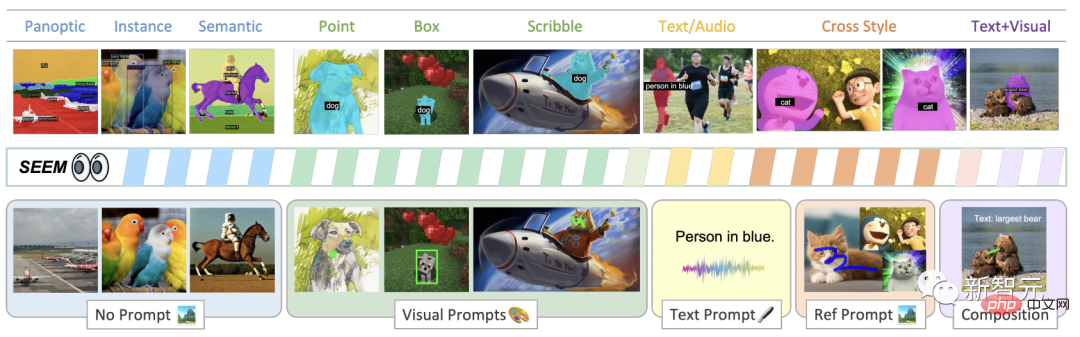
さらに、ビジュアル、テキスト、および参照領域のプロンプトの任意の組み合わせをサポートし、多用途かつインタラクティブな参照分割を可能にします。
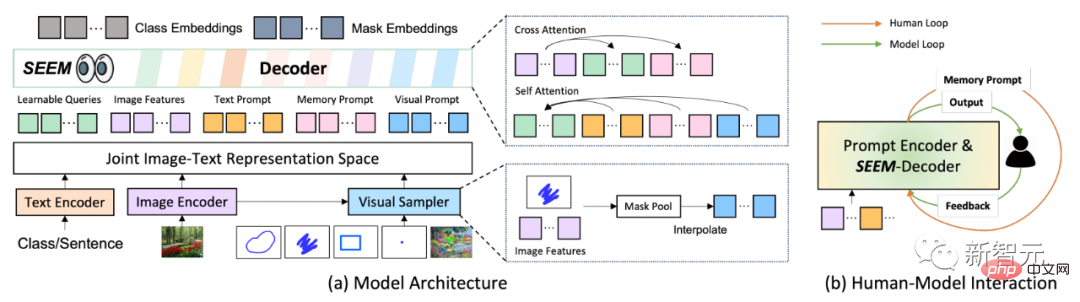
モデル アーキテクチャに関しては、SEEM は共通のエンコーダ/デコーダ アーキテクチャを採用しています。これをユニークにしているのは、クエリとプロンプトの間の複雑な相互作用です。
特徴とキューは、対応するエンコーダーまたはサンプラーによって共同視覚的意味空間にエンコードされます。
学習可能なクエリはランダムに初期化され、SEEM デコーダは学習可能なクエリ、画像の特徴、およびマスクとセマンティクス予測のクラスとマスクの埋め込みを含むテキスト キューを入出力として受け入れます。
SEEM モデルには複数ラウンドのインタラクションがあることに言及する価値があります。各ラウンドは手動サイクルとモデル サイクルで構成されます。
手動ループでは、前の反復のマスク出力が手動で受信され、次のデコード ラウンドへの正のフィードバックが視覚的な合図を通じて与えられます。モデル ループでは、モデルは将来の予測のためのメモリ キューを受信して更新します。
#SEEM を通じて、オプティマス プライムのトラックの写真を指定すると、任意のターゲット画像上でオプティマス プライムをセグメント化できます。

ユーザーが入力したテキストからワンクリック セグメンテーション用のマスクを生成します。

さらに、SEEM は、参照画像をクリックするか落書きするだけで、ターゲット画像に同様のセマンティクスを追加できます。セグメント化されています。

さらに、SEEM はソリューション空間の関係をよく理解しています。左上の列のシマウマが落書きされた後、一番左のシマウマもセグメント化されます。



インタラクティブなセグメンテーション
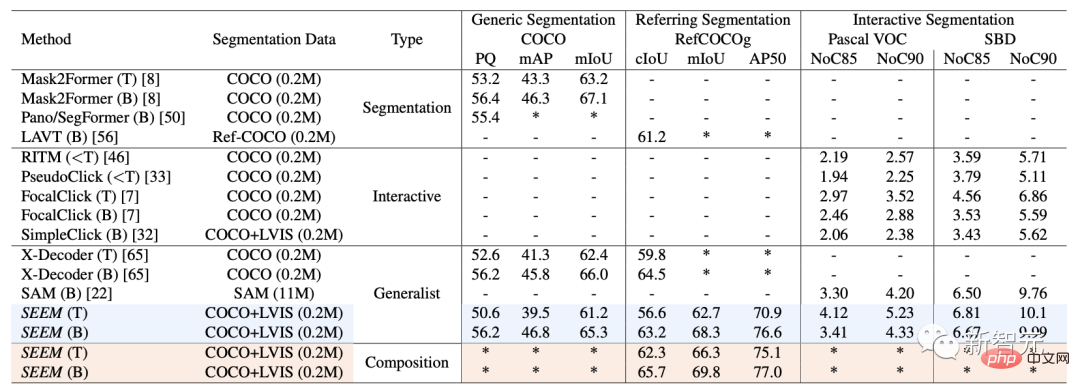
インタラクティブ セグメンテーションに関して、研究者は SEEM と最先端のインタラクティブ セグメンテーション モデルを比較しました。 SEEM は、一般的なモデルとして、RITM、SimpleClick などと同等のパフォーマンスを実現しています。また、SAM と非常によく似たパフォーマンスを実現し、SAM はさらに 50 個以上のセグメント化されたデータをトレーニングに使用します。 注目すべきことに、既存のインタラクティブ モデルとは異なり、SEEM は従来のセグメンテーション タスクだけでなく、テキスト、ポイント、落書き、境界ボックスなどの幅広いマルチモーダル入力もサポートする最初の製品です。と画像を組み合わせて、強力な組み合わせ機能を提供します。 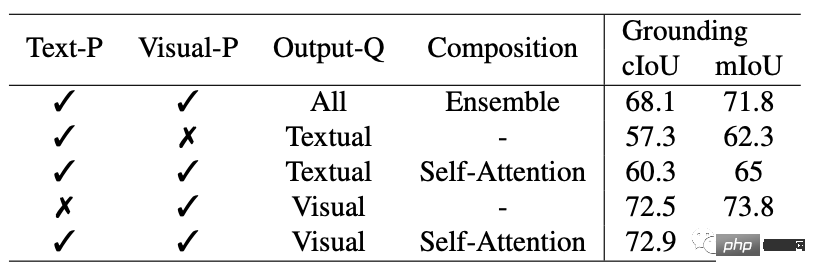
##ユニバーサル セグメンテーション
すべての A セットに合格セグメンテーション タスク用に事前トレーニングされたパラメーターを使用して、研究者が一般的なセグメンテーション データセットでのパフォーマンスを直接評価できるようにします。
SEEM は、パノラマ ビュー、インスタンス、セマンティック セグメンテーションのパフォーマンスを向上させます。
#1 。多用途のヒント エンジンを導入して、ポイント、ボックス、落書き、マスク、テキスト、別の画像の参照領域など、さまざまなタイプのヒントを処理します;
2. 複雑さ: ジョイントを学習することによって視覚的意味空間、視覚的およびテキストの手がかりを組み合わせて、瞬時のクエリ推論を行うことができます;
3. インタラクティブ性: 学習可能な記憶の手がかりをマスキングを通じて統合することにより、コードガイドによる相互注意により会話履歴が保存されます情報;
4. 意味認識: テキスト エンコーダーを使用してテキスト クエリとマスク タグをエンコードすることにより、オープンな語彙のセグメンテーションを有効にします。
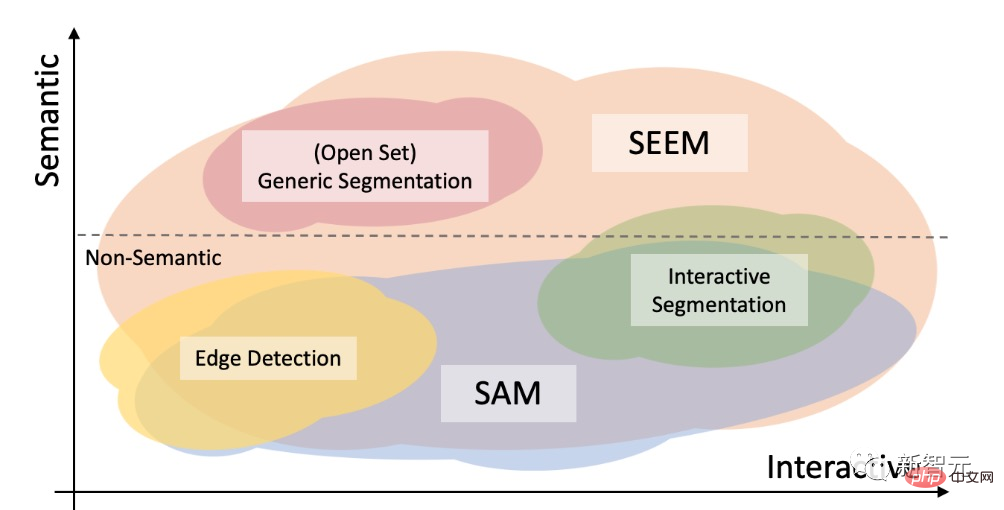
#SAM と SAM の違い
#Meta が提案する SAM モデルは、統一されたフレームワークで指定できます。プロンプト エンコーダ: ポイント、境界ボックス、および文章をワンクリックでオブジェクトをセグメント化できます。


オープン セット セグメンテーションでは、高レベルのセマンティクスも必要ですが、対話は必要ありません。
SAM と比較して、SEEM はより広範囲のインタラクションとセマンティック レベルをカバーします。
SAM は、ポイントや境界ボックスなどの限定されたインタラクション タイプのみをサポートし、セマンティック ラベル自体を出力しないため、高度なセマンティック タスクを無視します。
SEEM について、研究者は 2 つのハイライトを強調しました:
まず、SEEM には、すべての視覚的手がかりと言語的手がかりがエンコードされる統合プロンプト エンコーダーがあります。共同表現空間に。したがって、SEEM はより一般的な使用法をサポートでき、カスタム プロンプトに拡張できる可能性があります。
第 2 に、SEEM はテキスト マスキングと出力セマンティクスを意識した予測に優れています。
論文の筆頭著者 Xueyan Zou
彼女は現在、ウィスコンシン大学マディソン校のコンピュータ サイエンス学科で、ヨン ジェ リー教授の指導の下、博士課程の学生です。
これに先立ち、鄒氏は同じ指導者の指導の下、カリフォルニア大学デービス校で 3 年間を過ごし、Fanyi Xiao 博士と緊密に連携しました。
彼女は、PC Yuen 教授と Chu Xiaowen 教授の指導の下、香港バプテスト大学で学士号を取得しました。

##ヤン・ジャンウェイ

Yang の研究は主に、コンピューター ビジョン、視覚と言語、機械学習に焦点を当てています。彼は、さまざまなレベルの構造化された視覚的理解と、それらを言語と環境の具体化を通じて人間との知的相互作用にさらに活用する方法に焦点を当てています。
2020 年 3 月にマイクロソフトに入社する前に、ヤンはジョージア工科大学インタラクティブ コンピューティング学部でコンピューター サイエンスの博士号を取得しました。そこでの指導教官はデヴィ パリク教授であり、ドゥルブ バトラ教授とも協力しました。緊密に協力してください。
Gao Jianfeng
##Gao Jianfeng は、著名な科学者であり、大学の准教授です。 Microsoft Research 社長、IEEE 会員、ACM Distinguished Member。 
現在、Gao Jianfeng は深層学習グループを率いています。このグループの使命は、最先端の深層学習と自然言語と画像理解におけるその応用を推進し、会話モデルと手法を進歩させることです。
研究には主に、自然言語の理解と生成のためのニューラル言語モデル、ニューラルシンボリックコンピューティング、視覚言語の基礎と理解、会話型人工知能などが含まれます。
2014 年から 2018 年まで、Gao Jianfeng は、Microsoft 人工知能研究部門およびレドモンド Microsoft Research の深層学習テクノロジ センター (DLTC) で商用人工知能のパートナー研究マネージャーを務めました。 。
2006 年から 2014 年まで、Gao Jianfeng は自然言語処理グループの主任研究員を務めました。
ヨン・ジェ・リー
リーは大学のコンピューター科学者です。ワシントンのマディソン理学部准教授。 
2021 年の秋にマディソン大学に入社する前に、クルーズで人工知能の客員講師を 1 年間務め、その前はカリフォルニア大学デービス校に在籍していました。助教授、准教授として6年間勤務。
彼はまた、カーネギー メロン大学のロボット研究所で博士研究員として 1 年間過ごしました。
彼は、2012 年 5 月にテキサス大学オースティン校でクリステン グローマンとともに博士号を取得し、2006 年 5 月にイリノイ大学アーバナ シャンペーン校で学士号を取得しました。
彼は、Microsoft Research で、Larry Zitnick および Michael Cohen とともにサマー インターンとしても働きました。
現在、Lee の研究はコンピューター ビジョンと機械学習に焦点を当てています。 Lee 氏は、人間の監視を最小限に抑えながら視覚データを理解できる強力な視覚認識システムの作成に特に興味を持っています。
現在、SEEM はデモを公開しています:
https://huggingface.co/spaces/xdecoder/SEEM
ぜひ試してみてください。
以上が中国チームが履歴書を覆す! SEEMはすべての爆発を完璧に分割し、ワンクリックで「瞬間的な宇宙」を分割しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



