

nginx ログを elasticsearch にインポートする方法

filebeat で nginx ログを収集し、logstash に転送し、logstash で処理した後、elasticsearch に書き込みます。 Filebeat は収集作業のみを担当しますが、logstash はログを elasticsearch に書き込んだ後のログのフォーマット、データ置換、分割、インデックスの作成を完了します。
1. nginx ログ形式の設定
log_format main '$remote_addr $http_x_forwarded_for [$time_local] $server_name $request '
'$status $body_bytes_sent $http_referer '
'"$http_user_agent" '
'"$connection" '
'"$http_cookie" '
'$request_time '
'$upstream_response_time';2. filebeat のインストールと設定、nginx モジュールの有効化
tar -zxvf filebeat-6.2.4-linux-x86_64.tar.gz -c /usr/local cd /usr/local;ln -s filebeat-6.2.4-linux-x86_64 filebeat cd /usr/local/filebeat
nginx の有効化module
./filebeat modules enable nginx
View module
./filebeat modules list
構成ファイルの作成
vim /usr/local/filebeat/blog_module_logstash.yml filebeat.modules: - module: nginx access: enabled: true var.paths: ["/home/weblog/blog.cnfol.com_access.log"] #error: # enabled: true # var.paths: ["/home/weblogerr/blog.cnfol.com_error.log"] output.logstash: hosts: ["192.168.15.91:5044"]
Start filebeat
./filebeat -c blog_module_logstash.yml -e
3. logstash の構成
tar -zxvf logstash-6.2.4.tar.gz /usr/local cd /usr/local;ln -s logstash-6.2.4 logstash 创建一个nginx日志的pipline文件 cd /usr/local/logstash
logstash 組み込みテンプレート ディレクトリ
vendor/bundle/jruby/2.3.0/gems/logstash-patterns-core-4.1.2/patterns
grok-patterns を編集して、複数の IP をサポートする通常のパターンを追加します
forword (?:%{ipv4}[,]?[ ]?)+|%{word}公式 grok
#logstash パイプライン構成ファイルの作成
#input {
# stdin {}
#}
# 从filebeat接受数据
input {
beats {
port => 5044
host => "0.0.0.0"
}
}
filter {
# 添加一个调试的开关
mutate{add_field => {"[@metadata][debug]"=>true}}
grok {
# 过滤nginx日志
#match => { "message" => "%{nginxaccess_test2}" }
#match => { "message" => '%{iporhost:clientip} # (?<http_x_forwarded_for>[^\#]*) # \[%{httpdate:[@metadata][webtime]}\] # %{notspace:hostname} # %{word:verb} %{uripathparam:request} http/%{number:httpversion} # %{number:response} # (?:%{number:bytes}|-) # (?:"(?:%{notspace:referrer}|-)"|%{notspace:referrer}|-) # (?:"(?<http_user_agent>[^#]*)") # (?:"(?:%{number:connection}|-)"|%{number:connection}|-) # (?:"(?<cookies>[^#]*)") # %{number:request_time:float} # (?:%{number:upstream_response_time:float}|-)' }
#match => { "message" => '(?:%{iporhost:clientip}|-) (?:%{two_ip:http_x_forwarded_for}|%{ipv4:http_x_forwarded_for}|-) \[%{httpdate:[@metadata][webtime]}\] (?:%{hostname:hostname}|-) %{word:method} %{uripathparam:request} http/%{number:httpversion} %{number:response} (?:%{number:bytes}|-) (?:"(?:%{notspace:referrer}|-)"|%{notspace:referrer}|-) %{qs:agent} (?:"(?:%{number:connection}|-)"|%{number:connection}|-) (?:"(?<cookies>[^#]*)") %{number:request_time:float} (?:%{number:upstream_response_time:float}|-)' }
match => { "message" => '(?:%{iporhost:clientip}|-) %{forword:http_x_forwarded_for} \[%{httpdate:[@metadata][webtime]}\] (?:%{hostname:hostname}|-) %{word:method} %{uripathparam:request} http/%{number:httpversion} %{number:response} (?:%{number:bytes}|-) (?:"(?:%{notspace:referrer}|-)"|%{notspace:referrer}|-) %{qs:agent} (?:"(?:%{number:connection}|-)"|%{number:connection}|-) %{qs:cookie} %{number:request_time:float} (?:%{number:upstream_response_time:float}|-)' }
}
# 将默认的@timestamp(beats收集日志的时间)的值赋值给新字段@read_tiimestamp
ruby {
#code => "event.set('@read_timestamp',event.get('@timestamp'))"
#将时区改为东8区
code => "event.set('@read_timestamp',event.get('@timestamp').time.localtime + 8*60*60)"
}
# 将nginx的日志记录时间格式化
# 格式化时间 20/may/2015:21:05:56 +0000
date {
locale => "en"
match => ["[@metadata][webtime]","dd/mmm/yyyy:hh:mm:ss z"]
}
# 将bytes字段由字符串转换为数字
mutate {
convert => {"bytes" => "integer"}
}
# 将cookie字段解析成一个json
#mutate {
# gsub => ["cookies",'\;',',']
#}
# 如果有使用到cdn加速http_x_forwarded_for会有多个ip,第一个ip是用户真实ip
if[http_x_forwarded_for] =~ ", "{
ruby {
code => 'event.set("http_x_forwarded_for", event.get("http_x_forwarded_for").split(",")[0])'
}
}
# 解析ip,获得ip的地理位置
geoip {
source => "http_x_forwarded_for"
# # 只获取ip的经纬度、国家、城市、时区
fields => ["location","country_name","city_name","region_name"]
}
# 将agent字段解析,获得浏览器、系统版本等具体信息
useragent {
source => "agent"
target => "useragent"
}
#指定要删除的数据
#mutate{remove_field=>["message"]}
# 根据日志名设置索引名的前缀
ruby {
code => 'event.set("@[metadata][index_pre]",event.get("source").split("/")[-1])'
}
# 将@timestamp 格式化为2019.04.23
ruby {
code => 'event.set("@[metadata][index_day]",event.get("@timestamp").time.localtime.strftime("%y.%m.%d"))'
}
# 设置输出的默认索引名
mutate {
add_field => {
#"[@metadata][index]" => "%{@[metadata][index_pre]}_%{+yyyy.mm.dd}"
"[@metadata][index]" => "%{@[metadata][index_pre]}_%{@[metadata][index_day]}"
}
}
# 将cookies字段解析成json
# mutate {
# gsub => [
# "cookies", ";", ",",
# "cookies", "=", ":"
# ]
# #split => {"cookies" => ","}
# }
# json_encode {
# source => "cookies"
# target => "cookies_json"
# }
# mutate {
# gsub => [
# "cookies_json", ',', '","',
# "cookies_json", ':', '":"'
# ]
# }
# json {
# source => "cookies_json"
# target => "cookies2"
# }
# 如果grok解析存在错误,将错误独立写入一个索引
if "_grokparsefailure" in [tags] {
#if "_dateparsefailure" in [tags] {
mutate {
replace => {
#"[@metadata][index]" => "%{@[metadata][index_pre]}_failure_%{+yyyy.mm.dd}"
"[@metadata][index]" => "%{@[metadata][index_pre]}_failure_%{@[metadata][index_day]}"
}
}
# 如果不存在错误就删除message
}else{
mutate{remove_field=>["message"]}
}
}
output {
if [@metadata][debug]{
# 输出到rubydebuyg并输出metadata
stdout{codec => rubydebug{metadata => true}}
}else{
# 将输出内容转换成 "."
stdout{codec => dots}
# 将输出到指定的es
elasticsearch {
hosts => ["192.168.15.160:9200"]
index => "%{[@metadata][index]}"
document_type => "doc"
}
}
}logstash の開始
nohup bin/logstash -f test_pipline2.conf &
以上がnginx ログを elasticsearch にインポートする方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7488
7488
 15
1377
52
77
11
19
40
15
1377
52
77
11
19
40

 Tomcat サーバーへの外部ネットワーク アクセスを許可する方法
Apr 21, 2024 am 07:22 AM
Tomcat サーバーへの外部ネットワーク アクセスを許可する方法
Apr 21, 2024 am 07:22 AM
Tomcat サーバーが外部ネットワークにアクセスできるようにするには、以下を行う必要があります。 外部接続を許可するように Tomcat 構成ファイルを変更します。 Tomcat サーバー ポートへのアクセスを許可するファイアウォール ルールを追加します。 Tomcat サーバーのパブリック IP を指すドメイン名を指す DNS レコードを作成します。オプション: リバース プロキシを使用して、セキュリティとパフォーマンスを向上させます。オプション: セキュリティを強化するために HTTPS を設定します。
 HTMLファイルからURLを生成する方法
Apr 21, 2024 pm 12:57 PM
HTMLファイルからURLを生成する方法
Apr 21, 2024 pm 12:57 PM
HTML ファイルを URL に変換するには Web サーバーが必要です。これには次の手順が含まれます。 Web サーバーを取得します。 Webサーバーをセットアップします。 HTMLファイルをアップロードします。ドメイン名を作成します。リクエストをルーティングします。
 Nodejsプロジェクトをサーバーにデプロイする方法
Apr 21, 2024 am 04:40 AM
Nodejsプロジェクトをサーバーにデプロイする方法
Apr 21, 2024 am 04:40 AM
Node.js プロジェクトのサーバー デプロイメント手順: デプロイメント環境を準備します。サーバー アクセスの取得、Node.js のインストール、Git リポジトリのセットアップ。アプリケーションをビルドする: npm run build を使用して、デプロイ可能なコードと依存関係を生成します。コードをサーバーにアップロードします: Git またはファイル転送プロトコル経由。依存関係をインストールする: サーバーに SSH で接続し、npm install を使用してアプリケーションの依存関係をインストールします。アプリケーションを開始します。node Index.js などのコマンドを使用してアプリケーションを開始するか、pm2 などのプロセス マネージャーを使用します。リバース プロキシの構成 (オプション): Nginx や Apache などのリバース プロキシを使用して、トラフィックをアプリケーションにルーティングします。
 外部からnodejsにアクセスできますか?
Apr 21, 2024 am 04:43 AM
外部からnodejsにアクセスできますか?
Apr 21, 2024 am 04:43 AM
はい、Node.js には外部からアクセスできます。次の方法を使用できます。 Cloud Functions を使用して関数をデプロイし、一般にアクセスできるようにします。 Express フレームワークを使用してルートを作成し、エンドポイントを定義します。 Nginx を使用して、Node.js アプリケーションへのリバース プロキシ リクエストを実行します。 Docker コンテナを使用して Node.js アプリケーションを実行し、ポート マッピングを通じて公開します。
 PHP を使用して Web サイトを展開および維持する方法
May 03, 2024 am 08:54 AM
PHP を使用して Web サイトを展開および維持する方法
May 03, 2024 am 08:54 AM
PHP Web サイトを正常に展開して維持するには、次の手順を実行する必要があります。 Web サーバー (Apache や Nginx など) を選択する PHP をインストールする データベースを作成して PHP に接続する コードをサーバーにアップロードする ドメイン名と DNS を設定する Web サイトのメンテナンスを監視する手順には、PHP および Web サーバーの更新、Web サイトのバックアップ、エラー ログの監視、コンテンツの更新が含まれます。
 Fail2Ban を使用してサーバーをブルート フォース攻撃から保護する方法
Apr 27, 2024 am 08:34 AM
Fail2Ban を使用してサーバーをブルート フォース攻撃から保護する方法
Apr 27, 2024 am 08:34 AM
Linux 管理者にとっての重要なタスクは、サーバーを違法な攻撃やアクセスから保護することです。デフォルトでは、Linux システムには、iptables、Uncomplicated Firewall (UFW)、ConfigServerSecurityFirewall (CSF) などの適切に構成されたファイアウォールが付属しており、さまざまな攻撃を防ぐことができます。インターネットに接続されているマシンはすべて、悪意のある攻撃のターゲットになる可能性があります。サーバーへの不正アクセスを軽減するために使用できる Fail2Ban と呼ばれるツールがあります。 Fail2Ban とは何ですか? Fail2Ban[1] は、ブルート フォース攻撃からサーバーを保護する侵入防止ソフトウェアです。 Python プログラミング言語で書かれています
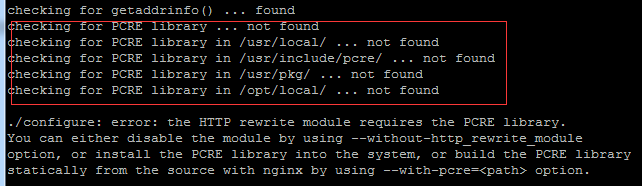 Linux を学び、Nginx をインストールするために私と一緒に来てください
Apr 28, 2024 pm 03:10 PM
Linux を学び、Nginx をインストールするために私と一緒に来てください
Apr 28, 2024 pm 03:10 PM
今回は、Linux 環境に Nginx をインストールする方法を説明します。 ここで使用する Linux システムは CentOS7.2 です。 インストール ツールを準備します。 1. Nginx 公式 Web サイトから Nginx をダウンロードします。ここで使用するバージョンは 1.13.6.2. ダウンロードした Nginx を Linux にアップロードする ここでは例として /opt/nginx ディレクトリを使用します。 「tar-zxvfnginx-1.13.6.tar.gz」を実行して解凍します。 3. /opt/nginx/nginx-1.13.6 ディレクトリに切り替え、./configure を実行して初期設定を行います。次のプロンプトが表示された場合は、マシンに PCRE がインストールされていないため、Nginx がインストールする必要があることを意味します。
 keepalived+nginx で高可用性を構築する際の注意点
Apr 23, 2024 pm 05:50 PM
keepalived+nginx で高可用性を構築する際の注意点
Apr 23, 2024 pm 05:50 PM
yum が keepalived をインストールした後、keepalived 設定ファイルを設定します。マスターおよびバックアップの keepalived 設定ファイルでは、通常、高可用性では VIP のネットワーク カード名が選択されています。 LAN 環境 他にもあるため、この VIP は 2 台のマシンと同じネットワーク セグメント内のイントラネット IP です。外部ネットワーク環境で使用する場合、クライアントがアクセスできれば同一ネットワークセグメント上にあるかは関係ありません。 nginx サービスを停止し、keepalived サービスを開始します。 keepalived が nginx サービスを開始できないことがわかりますが、それは基本的に設定ファイルとスクリプトに問題があるか、防止の問題です。
