

ある物体の写真を数枚見て、それが他の角度からどのように見えるか想像できますか?人間にはそれができるし、見たことのない部分や、見たことのない角度がどのように見えるかを推測することができます。実際、モデルにはこれを行う方法があり、いくつかのシーン写真を与えて、見えない角度から画像をブレインストーミングすることもできます。
新しい視点をレンダリングする、最近最も注目を集めているのは、ECCV 2020 Best Paper の名誉賞にノミネートされた NeRF (Neural Radiance Field) です。三次元再構成プロセスは、数枚の写真と撮影時のカメラの位置を考慮するだけで、新しい視点からの画像を合成します。 NeRF の驚くべき効果は多くの視覚研究者を魅了し、その後、優れた作品が次々と生み出されました。
しかし、問題は、そのようなモデルの構築が複雑であり、それらを実装するための統一されたコード ベース フレームワークが現在存在しないことであり、このことが間違いなくこの分野のさらなる探索と開発を妨げることになります。この目的を達成するために、OpenXRLab レンダリング生成プラットフォームは、高度にモジュール化されたアルゴリズム ライブラリ XRNeRF を構築し、NeRF のようなモデルの構築、トレーニング、推論を迅速に実現できるようにしました。
オープンソース アドレス: https://github.com/openxrlab/xrnerf
NeRF クラス モデルとはNeRF クラスのタスクは一般に、キャプチャされた画像や各画像に対応する内部および外部パラメータを含む、既知の視点の下でシーン情報をキャプチャし、それによって新しい画像を合成することを指します。視点。 NeRF 論文の図を利用すると、このタスクを非常に明確に理解できます。
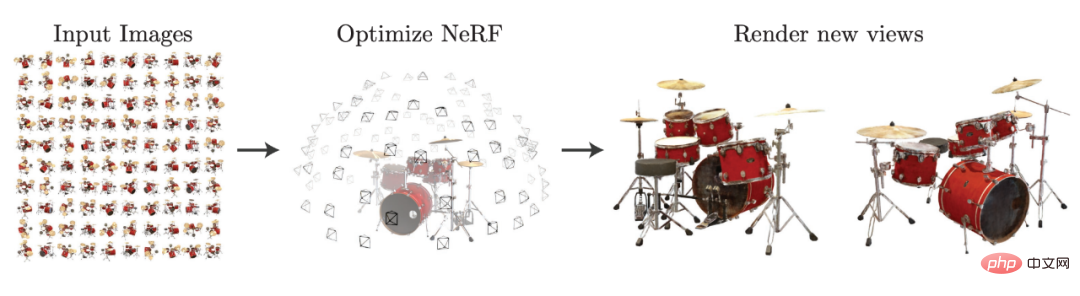
arxiv から選択: 2003.08934。
#NeRF は、画像を収集するときに 5 次元のシーン情報も収集します。つまり、1 つの画像は 3 次元の座標値と他の 2 つの光放射角度に対応します。このようなシーンは、多層パーセプトロンを通じてラディアンス フィールドとしてモデル化されます。これは、多層パーセプトロンが 3 次元座標点を入力し、それをその点の密度と RGB カラーにマッピングすることを意味し、それによってボクセル レンダリングを使用します。 (ボリューム レンダリング) を使用して、ラディアンス フィールドをフォトリアリスティックな仮想パースペクティブにレンダリングします。
上の図に示すように、いくつかの写真を通じてラディアンス フィールドを構築した後、新しい視点からのドラム セットのイメージを生成できます。 NeRF は、必要な新しい視点を取得するために明示的な 3D 再構成を必要としないため、深層学習に基づく 3D 暗黙的表現パラダイムを提供し、2D ポーズ画像データのみを使用して 3D シーンをトレーニングできる情報用のディープ ニューラル ネットワークです。
NeRF 以来、NeRF のようなモデルが際限なく登場しました。Mip-NeRF は、微細構造の生成を最適化するために光線の代わりに円錐を使用し、KiloNeRF は、代わりに数千のマイクロ多層パーセプトロンを使用します。単一の大きな多層パーセプトロンにより、計算量が削減され、リアルタイム レンダリング機能が実現されます。さらに、AniNeRF や Neural Body などのモデルは、短いビデオ フレームから人間の視点変換を学習して、優れた視点合成と駆動効果を取得します。 , GN 'R モデルは、まばらな透視画像と幾何学的事前分布を使用して、異なる ID 間で一般化可能な人間のレンダリングを実現します。

# GN'R が提案する一般化可能な人体の暗黙的なフィールド表現は、単一モデルの人体のレンダリング効果を実現しますNeRF に車輪を付ける
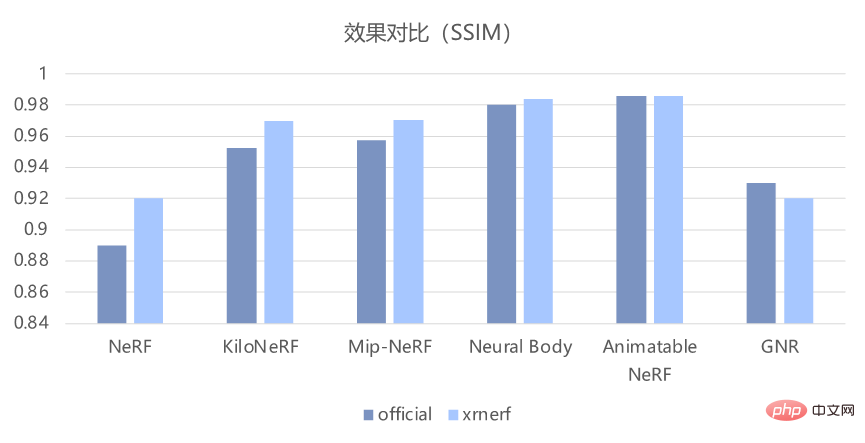
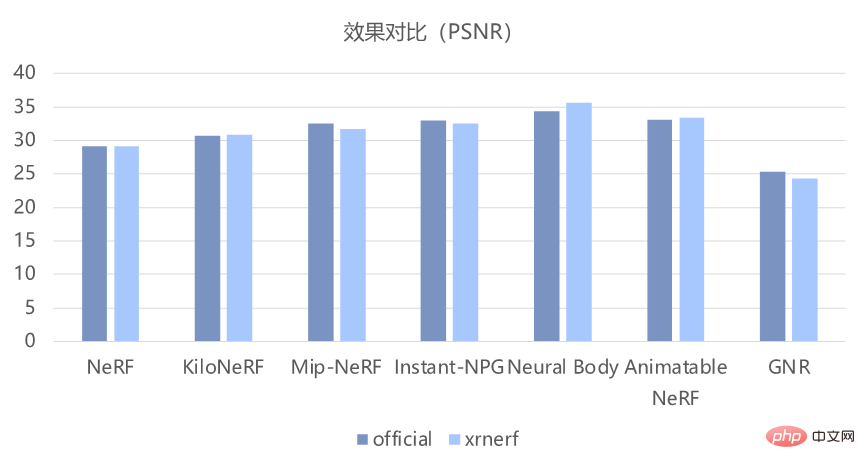
現在の NeRF アルゴリズムは研究分野で非常に人気がありますが、結局のところ比較的新しい手法であるため、モデルの実装には少し時間がかかる必要があります。もっと面倒です。 PyTorch や TensorFlow などの従来のフレームワークを使用している場合は、まず類似の NeRF モデルを見つけて、それに基づいて変更する必要があります。 これを行うと、いくつかの明らかな問題が発生します。まず、必要なものに変更する前に、実装を完全に理解する必要があります。この部分の作業負荷は実際にはかなり大きくなります。; 第 2 に、異なる論文の公式実装は統一されていないため、異なる NeRF モデルのソース コードを比較する際に多くのエネルギーを消費します 結局のところ、特定の論文のトレーニング プロセスに新しいトリックがあるかどうかは誰も知りません; 最後に、統一されたコードのセットがなければ、新しいモデルの新しいアイデアを検証するのに間違いなくはるかに時間がかかります。 多くの問題を解決するために、OpenXRLab は、NeRF クラス モデル用に統合された高度にモジュール化されたコード ベース フレームワーク XRNeRF を構築します。 XRNeRF は多くの NeRF モデルを実装しているため、開始が容易になり、対応する論文の実験結果を簡単に再現できます。 XRNeRF は、これらのモデルをデータセット、mlp、ネットワーク、エンベッダー、レンダーの 5 つのモジュールに分割します。 XRNeRF の使いやすさは、構成メカニズムを通じてさまざまなモジュールを組み立てて完全なモデルを形成できることにあり、非常にシンプルで使いやすく、再利用性も大幅に向上します。 使いやすさを確保することに基づいて、柔軟性も必要です。XRNeRF は、別のレジスタ メカニズムのセットを通じて、さまざまなモジュールの特定の特性や実装をカスタマイズできるため、XRNeRF はより優れたものになります。分離するとコードが理解しやすくなります。 また、XRNeRF が実装するアルゴリズムはすべてパイプライン モードを採用しており、データ上のパイプラインは元のデータを読み込み、一連の処理を経てモデルの入力を取得します。入力データが処理され、対応する出力が取得されます。このようなパイプラインは、構成メカニズムと登録マシン メカニズムを接続して、完全なアーキテクチャを形成します。 XRNeRF は、多くのコア NeRF モデルを実装し、上記の 3 つのメカニズムを通じてそれらをつなぎ合わせて、使いやすく柔軟な高度にモジュール化されたコード フレームワークを構築します。 XRNeRF は、Pytorch フレームワークに基づく NeRF クラス アルゴリズム ライブラリであり、シーンとボディの両方の方向で 8 つの古典的な論文を再現しています。直接モデリングと比較して、XRNeRF はモデル構築の効率、コスト、柔軟性が大幅に向上しており、完全な使用ドキュメント、例、および問題のフィードバック メカニズムを備えています。要約すると、XRNeRF のコア機能は次の 5 点です。 1. 多くの主流アルゴリズムとコア アルゴリズムを実装 たとえば、先駆的な作品である NeRF、CVPR 2021 Best論文候補 (NeuralBody)、ICCV 2021 最優秀論文佳作 (Mip-NeRF)、および Siggraph 2022 最優秀論文 (Instant NGP)。 これらのモデルの実装に基づいて、XRNeRF は再現効果が論文の効果と基本的に一致していることを確認することもできます。以下の図に示すように、客観的な PSNR および SSIM 指標から判断すると、元のコードの効果をよく再現できます。 #2. モジュラー設計 XRNeRF はコード フレームワーク全体をモジュール化してコードの再利用性を最大化し、研究者が既存のコードを読み取って変更できるようにします。既存の NeRF クラス モデル メソッドを分析することにより、XRNeRF 設計の特定のモジュール プロセスを次の図に示します。 # #モジュール性の利点は、データ形式を変更する必要がある場合、データセット モジュールのロジックを変更するだけで済むことです。イメージのレンダリング ロジックを変更する必要がある場合、レンダリング モデル モジュールを変更するだけで済みます。 3. 標準データ処理パイプライン XRNeRF は、NeRF アルゴリズムのデータ前処理における一連の複雑で多様な問題を提供します。手順。複数のデータ処理操作から連続的に取得されるため、config 構成ファイルのデータ パイプライン部分を変更するだけで、スムーズなデータ処理の構築が完了します。 #NeRF 構成データ フロー セクション。 複数のデータ セットに必要なデータ処理操作が XRNeRF に実装されています。データ処理プロセスを完了するには、構成内でこれらの操作を定義するだけで済みます。工事。将来新しい演算を追加する必要がある場合は、対応するフォルダーに新しい演算の実装を完了するだけでよく、データ処理プロセス全体に 1 行のコードを追加するだけで済みます。 4. モジュール型ネットワーク構築方法 エンベッダーはポイントの位置と視点を入力し、埋め込まれた特徴データを出力します。MLP はエンベッダーの出力を入力として使用し、サンプリング ポイントの密度と RGB カラーを出力します。 ; レンダー モデルは MLP の出力を入力します。その結果、レイ上の点に沿って積分などの操作が実行され、画像上のピクセルの RGB 値が取得されます。これら 3 つのモジュールは、標準ネットワーク モジュールを介して接続され、完全なモデルを形成します。
5. 優れた再現効果 最速60秒、30リアルでトレーニングネットワークをサポートします。 - 1 秒あたりのフレーム数のレンダリング、高解像度、アンチエイリアシング、マルチスケール シーンおよび人体イメージのレンダリングをサポートします。客観的な PSNR および SSIM インジケーターを見ても、主観的なデモ表示効果を見ても、XRNeRF は元のコードの効果をうまく再現できます。 XRNeRF の使い方
イメージをビルドし、そのイメージからコンテナーを起動した後、docker cp コマンドを使用してプロジェクトのコードとデータをコンテナーに転送できます。ただし、コンテナの作成時に -v パラメータを使用して、プロジェクト アドレスをコンテナの内部に直接マップすることもできます。ただし、ここでは、データ セットを XRNeRF プロジェクトの下のデータ フォルダーなどの特定の場所に配置する必要があることに注意してください (そうでない場合は、構成ファイルを変更する必要があります)。 一般的に、データをダウンロードした後のおおよそのフォルダー構造は次のようになります。

XRNeRF のコア機能

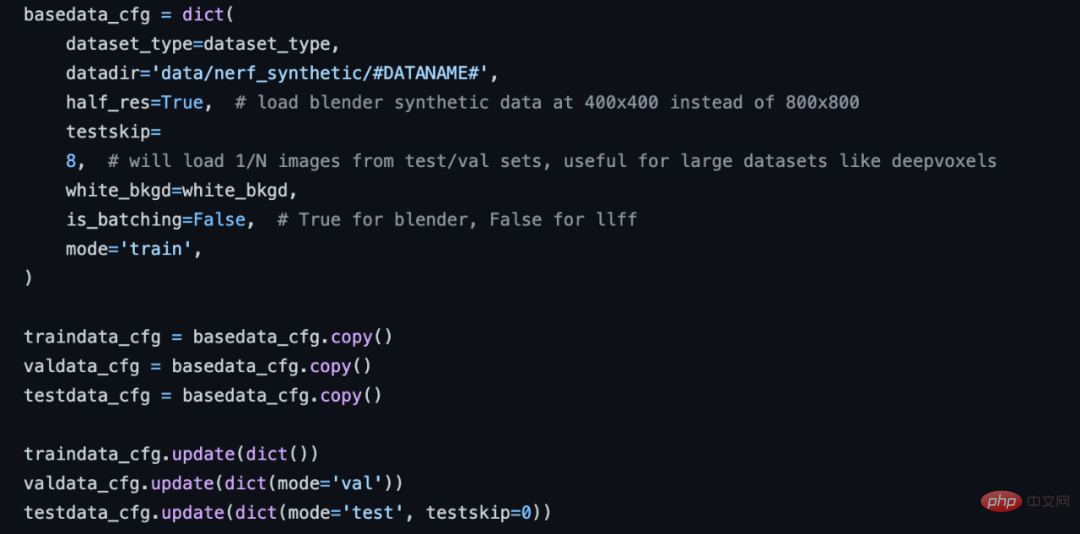

XRNeRF フレームワークは非常に優れた機能を備えているようで、非常にシンプルで使いやすいです。たとえば、インストール プロセス中、XRNeRF は PyTorch、CUDA 環境、ビジュアル処理ライブラリなどの多くの開発環境に依存します。ただし、XRNeRF は Docker 環境を提供し、イメージ ファイルは DockerFile を通じて直接ビルドできます。
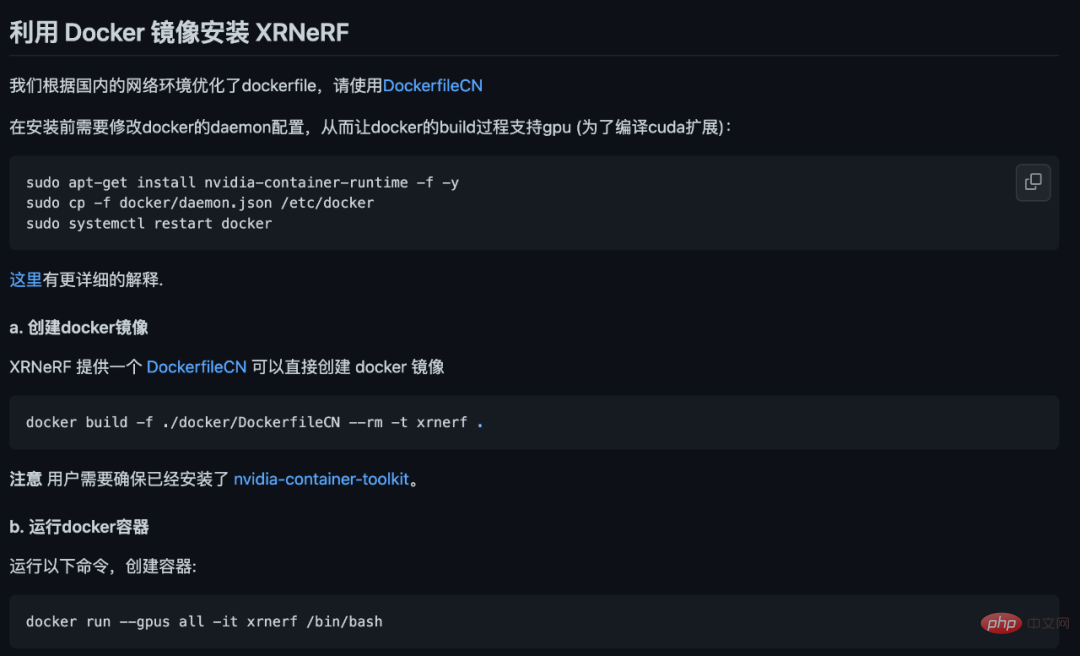 #さまざまな動作環境やパッケージを段階的に設定するのに比べ、docker build の 1 行コマンドのみの設定方法は、明らかに便利です。多すぎます。また、Dockerイメージを構築する際には、DockerFileに国内イメージのアドレスが設定されるため、やはり高速であり、基本的にネットワークの問題を心配する必要はありません。
#さまざまな動作環境やパッケージを段階的に設定するのに比べ、docker build の 1 行コマンドのみの設定方法は、明らかに便利です。多すぎます。また、Dockerイメージを構築する際には、DockerFileに国内イメージのアドレスが設定されるため、やはり高速であり、基本的にネットワークの問題を心配する必要はありません。  これで、環境、データ、コードの準備がすべて整いました。たった 1 行の短いコードで、NeFR モデルのトレーニングと検証を実行できます:
これで、環境、データ、コードの準備がすべて整いました。たった 1 行の短いコードで、NeFR モデルのトレーニングと検証を実行できます: python run_nerf.py --config configs/nerf/nerf_blender_base01.py --dataname lego
ここで、dataname はデータ ディレクトリ内の特定のデータ セットを表し、config はモデルの特定の構成ファイルを表します。 XRNeRF は高度なモジュール設計を採用しているため、その構成は辞書を使用して構築されており、一見すると少し面倒に見えるかもしれませんが、実際に XRNeRF の設計構造を理解すると、非常に簡単に読むことができます。
主観的な観点から見ると、構成構成ファイル (nerf_blender_base01.py) には、オプティマイザー、分散戦略、モデル アーキテクチャ、データの前処理、反復など、モデルのトレーニングに必要なすべての情報が含まれています。など、画像処理関連の設定も多数含まれています。要約すると、構成構成ファイルには、特定のコード実装に加えて、トレーニングと推論のプロセス全体が記述されます。
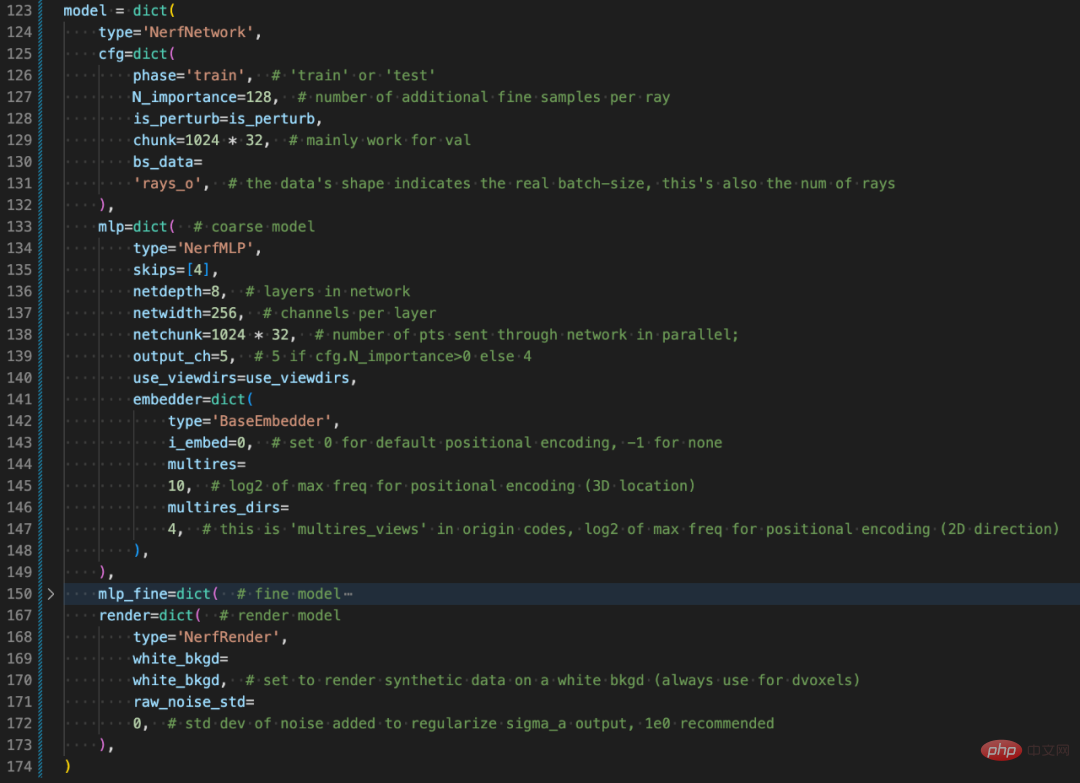
#モデル構造部分のConfig構成について説明します。
# 全体的な経験として、XRNeRF は基本的な動作環境のセットアップからトレーニング タスクの最終的な実行まで比較的スムーズです。さらに、構成ファイルを構成するか、特定の OP を実装することによって、非常に高いモデリングの柔軟性も得ることができます。深層学習フレームワーク モデリングを直接使用する場合と比較して、XRNeRF は間違いなく多くの開発作業を削減し、研究者やアルゴリズム エンジニアはモデルやタスクの革新により多くの時間を費やすことができます。
NeRF クラス モデルは、依然としてコンピューター ビジョンの分野で研究の焦点となっています。XRNeRF のような統一されたコード ベースは、HuggingFace の Transformer ライブラリと同様に、ますます優れた研究を収集できます。新しいコードや新しいアイデアをどんどん集めていきます。同様に、XRNeRF は研究者による NeRF タイプのモデルの探索を大幅に加速し、この新しい分野を新しいシナリオやタスクに適用することを容易にし、NeRF の可能性も加速します。
以上が新しい視点をブレインストーミングし、統合された NeRF コード ベース フレームワークがオープンソース化されましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



