

100,000 を超える AI モデルをワンクリックで制御、HuggingFace は ChatGPT のようなモデル用の「APP Store」を作成します

チャットからプログラミング、さまざまなプラグインのサポートに至るまで、強力な ChatGPT は長い間、単なる会話アシスタントではなく、AI の世界の「管理」を目指してきました。
3 月 23 日、OpenAI は、ChatGPT が有名な科学工学成果物 Wolfram Alpha などのさまざまなサードパーティ プラグインのサポートを開始したと発表しました。このアーティファクトのおかげで、もともと同じ檻の中のニワトリとウサギだった ChatGPT は、科学と工学のトップの学生になりました。 Twitter 上の多くの人は、ChatGPT プラグインのリリースは 2008 年の iPhone App Store のリリースに少し似ているとコメントしました。これは、AI チャットボットが進化の新たな段階、つまり「メタアプリ」段階に入りつつあることも意味します。 ######################4 4月上旬、浙江大学とマイクロソフト・アジア・リサーチの研究者らは「HuggingGPT」と呼ばれる重要な手法を提案した。上記ルートの大規模なデモンストレーションとみなすことができます。 HuggingGPT を使用すると、ChatGPT がコントローラー (管理層として理解できます) として機能できるようになり、他の多数の AI モデルを管理して、いくつかの複雑な AI タスクを解決できます。具体的には、HuggingGPT は、ユーザーのリクエストを受信したときに ChatGPT をタスク計画に使用し、HuggingFace で利用可能な機能の説明に基づいてモデルを選択し、選択された AI モデルで各サブタスクを実行し、実行結果に基づいて応答を集計します。
このアプローチは、処理できるモダリティが限られているなど、現在の大規模モデルの多くの欠点を補うことができますが、いくつかの側面ではプロのモデルほど優れていません。 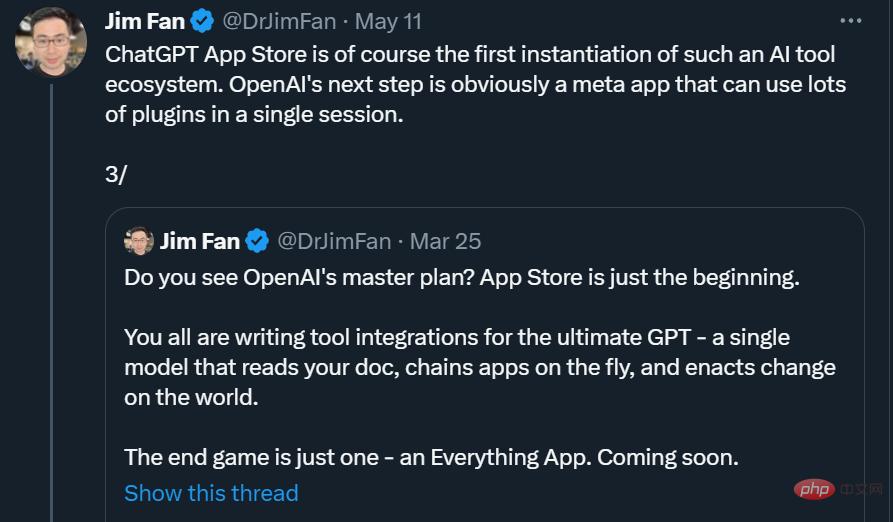
HuggingFace モデルも予定されていますが、結局のところ、HuggingGPT は HuggingFace の公式製品ではありません。たった今、HuggingFace がついに行動を起こしました。
HuggingGPT と同様に、新しい API、HuggingFace Transformers Agents をリリースしました。トランスフォーマー エージェントを使用すると、100,000 を超えるハグ フェイス モデルを制御して、さまざまなマルチモーダル タスクを完了できます。
たとえば、以下の例では、トランスフォーマー エージェントに絵に何が描かれているかを声に出して説明してもらいたいとします。あなたの指示 (画像の内容を読み上げます) を理解しようとして、それをプロンプトに変換し、指定されたタスクを完了するために適切なモデルとツールを選択します。 
NVIDIA AI 科学者 Jim Fan 氏は次のようにコメントしました: ついにこの日が来ました。これは「Everything APP」に向けた重要な一歩です。
ただし、これは AutoGPT の自動反復と同じではないと言う人もいます。プロンプトを作成し、ツールのこれらの手順を手動で指定するには、Master of All Things APP には時期尚早です。

トランスフォーマー エージェントのアドレス: https://huggingface.co/docs/transformers/transformers_agents
トランスフォーマーエージェントの使い方? 
https://huggingface co/docs/transformers/en/transformers_agents
つまり、トランスフォーマー上に自然言語 API を提供します。まず、厳選されたツールのセットを定義し、エージェントを定義します。は自然言語を解釈し、これらのツールを使用するように設計されています。
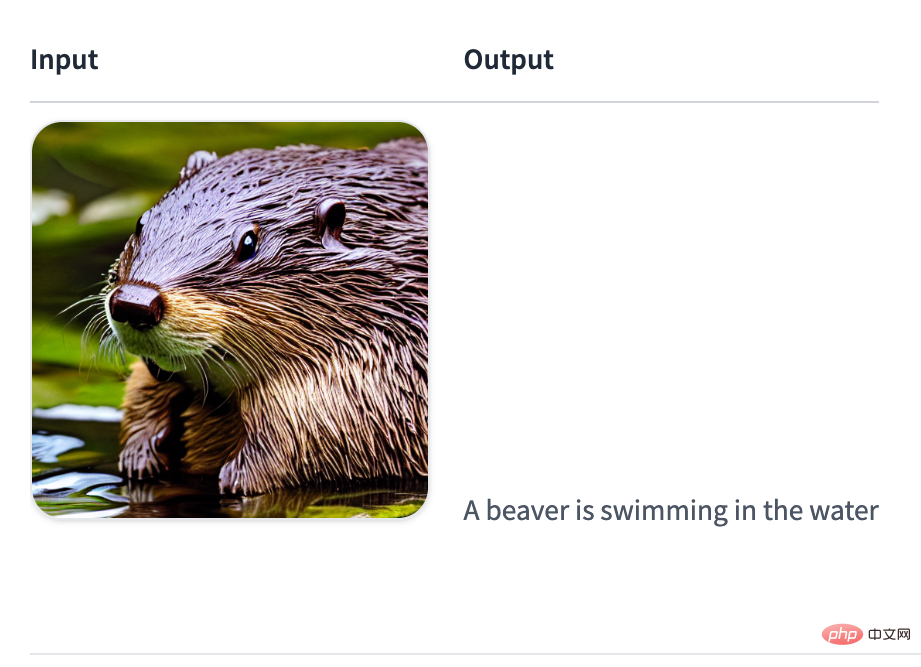
さらに、Transformers Agent は設計により拡張可能です。 チームは、エージェントに権限を与えることができる一連のツールを特定しました。統合ツールのリストは次のとおりです: これらのツールは次のとおりです。トランスフォーマーに統合されるか、手動で使用できます: ユーザーは、次のようにツールのコードを Hugging Face Space またはモデル リポジトリにプッシュして、エージェントを通じてツールを直接利用することもできます。 #画像の説明を生成します:
<code>from transformers import load_tooltool = load_tool("text-to-speech")audio = tool("This is a text to speech tool")</code>
<code>agent.run("Caption the following image", image=image)</code>
<code>agent.run("Read the following text out loud", text=text)</code>#出力:
#tts_example音声:
00:0000:01##ファイルの読み取り:
agent.run を実行する前に、大規模言語モデル エージェントをインスタンス化する必要があります。 OpenAI モデルと、BigCode や OpenAssistant などのオープンソース モデルをサポートします。

<code>pip install transformers[agents]</code>
<code>pip install openaifrom transformers import OpenAiAgentagent = OpenAiAgent(model="text-davinci-003", api_key="<your_api_key>")</code>
<code>from huggingface_hub import loginlogin("<YOUR_TOKEN>")</code><code>from transformers import HfAgentStarcoderagent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder")StarcoderBaseagent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoderbase")OpenAssistantagent = HfAgent(url_endpoint="https://api-inference.huggingface.co/models/OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5")</code>接下来,我们了解一下 Transformers Agents 提供的两个 API:
单次执行
单次执行是在使用智能体的 run () 方法时:
<code>agent.run("Draw me a picture of rivers and lakes.")</code>它会自动选择适合要执行的任务的工具并适当地执行,可在同一指令中执行一项或多项任务(不过指令越复杂,智能体失败的可能性就越大)。
<code>agent.run("Draw me a picture of the sea then transform the picture to add an island")</code>每个 run () 操作都是独立的,因此可以针对不同的任务连续运行多次。如果想在执行过程中保持状态或将非文本对象传递给智能体,用户可以通过指定希望智能体使用的变量来实现。例如,用户可以生成第一张河流和湖泊图像,并通过执行以下操作要求模型更新该图片以添加一个岛屿:
<code>picture = agent.run("Generate a picture of rivers and lakes.")updated_picture = agent.run("Transform the image in picture to add an island to it.", picture=picture)</code>当模型无法理解用户的请求并混合使用工具时,这会很有帮助。一个例子是:
<code>agent.run("Draw me the picture of a capybara swimming in the sea")</code>在这里,模型可以用两种方式解释:
- 让 text-to-image 水豚在海里游泳
- 或者,生成 text-to-image 水豚,然后使用 image-transformation 工具让它在海里游泳
如果用户想强制执行第一种情况,可以通过将 prompt 作为参数传递给它来实现:
<code>agent.run("Draw me a picture of the prompt", prompt="a capybara swimming in the sea")</code>基于聊天的执行
智能体还有一种基于聊天的方法:
<code>agent.chat("Generate a picture of rivers and lakes")</code><code>agent.chat ("Transform the picture so that there is a rock in there")</code>这是一种可以跨指令保持状态时。它更适合实验,但在单个指令上表现更好,而 run () 方法更擅长处理复杂指令。如果用户想传递非文本类型或特定 prompt,该方法也可以接受参数。
以上が100,000 を超える AI モデルをワンクリックで制御、HuggingFace は ChatGPT のようなモデル用の「APP Store」を作成しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7474
7474
 15
1377
52
77
11
19
31
15
1377
52
77
11
19
31

 Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
700万のレコードを効率的に処理し、地理空間技術を使用したインタラクティブマップを作成します。この記事では、LaravelとMySQLを使用して700万を超えるレコードを効率的に処理し、それらをインタラクティブなマップの視覚化に変換する方法について説明します。最初の課題プロジェクトの要件:MySQLデータベースに700万のレコードを使用して貴重な洞察を抽出します。多くの人は最初に言語をプログラミングすることを検討しますが、データベース自体を無視します。ニーズを満たすことができますか?データ移行または構造調整は必要ですか? MySQLはこのような大きなデータ負荷に耐えることができますか?予備分析:キーフィルターとプロパティを特定する必要があります。分析後、ソリューションに関連している属性はわずかであることがわかりました。フィルターの実現可能性を確認し、検索を最適化するためにいくつかの制限を設定しました。都市に基づくマップ検索
 MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLの起動が失敗する理由はたくさんあり、エラーログをチェックすることで診断できます。一般的な原因には、ポートの競合(ポート占有率をチェックして構成の変更)、許可の問題(ユーザー許可を実行するサービスを確認)、構成ファイルエラー(パラメーター設定のチェック)、データディレクトリの破損(テーブルスペースの復元)、INNODBテーブルスペースの問題(IBDATA1ファイルのチェック)、プラグインロード障害(エラーログのチェック)が含まれます。問題を解決するときは、エラーログに基づいてそれらを分析し、問題の根本原因を見つけ、問題を防ぐために定期的にデータをバックアップする習慣を開発する必要があります。
 インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
この記事では、MySQLデータベースの操作を紹介します。まず、MySQLWorkBenchやコマンドラインクライアントなど、MySQLクライアントをインストールする必要があります。 1. mysql-uroot-pコマンドを使用してサーバーに接続し、ルートアカウントパスワードでログインします。 2。CreatedAtaBaseを使用してデータベースを作成し、データベースを選択します。 3. createTableを使用してテーブルを作成し、フィールドとデータ型を定義します。 4. INSERTINTOを使用してデータを挿入し、データをクエリし、更新することでデータを更新し、削除してデータを削除します。これらの手順を習得することによってのみ、一般的な問題に対処することを学び、データベースのパフォーマンスを最適化することでMySQLを効率的に使用できます。
 酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
データベース酸属性の詳細な説明酸属性は、データベーストランザクションの信頼性と一貫性を確保するための一連のルールです。データベースシステムがトランザクションを処理する方法を定義し、システムのクラッシュ、停電、または複数のユーザーの同時アクセスの場合でも、データの整合性と精度を確保します。酸属性の概要原子性:トランザクションは不可分な単位と見なされます。どの部分も失敗し、トランザクション全体がロールバックされ、データベースは変更を保持しません。たとえば、銀行の譲渡が1つのアカウントから控除されているが別のアカウントに増加しない場合、操作全体が取り消されます。 TRANSACTION; updateaccountssetbalance = balance-100wh
 mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
MySQLはJSONデータを返すことができます。 json_extract関数はフィールド値を抽出します。複雑なクエリについては、Where句を使用してJSONデータをフィルタリングすることを検討できますが、そのパフォーマンスへの影響に注意してください。 JSONに対するMySQLのサポートは絶えず増加しており、最新バージョンと機能に注意を払うことをお勧めします。
 リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニアの求人事業者:サークル場所:リモートオフィスジョブタイプ:フルタイム給与:$ 130,000- $ 140,000職務記述書サークルモバイルアプリケーションとパブリックAPI関連機能の研究開発に参加します。ソフトウェア開発ライフサイクル全体をカバーします。主な責任は、RubyonRailsに基づいて独立して開発作業を完了し、React/Redux/Relay Front-Endチームと協力しています。 Webアプリケーションのコア機能と改善を構築し、機能設計プロセス全体でデザイナーとリーダーシップと緊密に連携します。肯定的な開発プロセスを促進し、反復速度を優先します。 6年以上の複雑なWebアプリケーションバックエンドが必要です
 バングラ部分モデル検索のlaravelEloquent orm)
Apr 08, 2025 pm 02:06 PM
バングラ部分モデル検索のlaravelEloquent orm)
Apr 08, 2025 pm 02:06 PM
LaravelEloquentモデルの検索:データベースデータを簡単に取得するEloquentormは、データベースを操作するための簡潔で理解しやすい方法を提供します。この記事では、さまざまな雄弁なモデル検索手法を詳細に紹介して、データベースからのデータを効率的に取得するのに役立ちます。 1.すべてのレコードを取得します。 ALL()メソッドを使用して、データベーステーブルですべてのレコードを取得します:useapp \ models \ post; $ post = post :: all();これにより、コレクションが返されます。 Foreach Loopまたはその他の収集方法を使用してデータにアクセスできます。
 マスターSQL制限条項:クエリの行数を制御する
Apr 08, 2025 pm 07:00 PM
マスターSQL制限条項:クエリの行数を制御する
Apr 08, 2025 pm 07:00 PM
sqllimit句:クエリ結果の行数を制御します。 SQLの制限条項は、クエリによって返される行数を制限するために使用されます。これは、大規模なデータセット、パジネートされたディスプレイ、テストデータを処理する場合に非常に便利であり、クエリ効率を効果的に改善することができます。構文の基本的な構文:SelectColumn1、column2、... FromTable_nameLimitnumber_of_rows; number_of_rows:返された行の数を指定します。オフセットの構文:SelectColumn1、column2、... FromTable_nameLimitoffset、number_of_rows; offset:skip
