

コンピューター ビジョンを理解するための 1 つの記事、役立つ情報が満載

1. はじめに
コンピューター ビジョン (コンピューター ビジョン) は通常 CV と呼ばれ、コンピューターが画像を「見て」「理解できる」ようにするテクノロジーを使用する研究分野です。写真またはビデオ、コンテンツ。
この記事では、コンピューター ビジョンについての全体的な概要を説明します。この記事は 6 つの部分に分かれています。
- #コンピュータ ビジョンが重要な理由
- コンピュータ ビジョンとは
- コンピュータ ビジョンの基本原理
- コンピュータ ビジョンの典型的なタスク
- 日常生活におけるコンピュータ ビジョンの応用シナリオ
- コンピュータ ビジョンが直面する課題
2. コンピュータ ビジョンが重要な理由
生理学的に、視覚は視覚器官の受容細胞の興奮から始まり、視覚神経系が収集した情報を処理した後に形成されます。私たち人間は、目の前の物の形や状態を直観的に理解するために視覚を使用しており、ほとんどの人は、料理を完成させたり、障害物を乗り越えたり、道路標識を読んだり、ビデオを見たり、その他数え切れないほどの作業を視覚に頼っています。実際、視覚障害者のような特別なグループがなければ、大多数の人は視覚を通じて外部情報を取得しており、この割合は 80% にも達します。有名な実験心理学者トレイヒャーによると、この割合には根拠がないわけではありません。人間が得る情報の 83% は視覚から、11% は聴覚から、残りの 6% は嗅覚、触覚、味覚から得られることが多数の実験によって確認されています。したがって、人間にとって視覚は間違いなく最も重要な感覚です。
人間だけが「視覚動物」であるわけではありませんが、ほとんどの動物にとって視覚も非常に重要な役割を果たしています。人間や動物は、視覚を通じて外部の物体の大きさ、明暗、色、動きなどを認識し、身体の生存に重要なさまざまな情報を得ることで、周囲の世界の様子や周囲の様子を知ることができます。世界とどのように対話するか。

#コンピュータ ビジョンが登場するまで、画像はコンピュータにとってブラック ボックス状態でした。コンピュータにとって、画像は単なるファイルまたはデータ文字列にすぎません。コンピュータは画像の内容を知りません。画像のサイズ、占有メモリ量、形式などだけを知っています。
コンピュータと人工知能が現実世界で重要な役割を果たしたいのであれば、画像を理解する必要があります。そのため、半世紀にわたり、コンピューター科学者はコンピューターに視覚を与える方法を解明しようと試み、「コンピューター ビジョン」という分野を生み出しました。

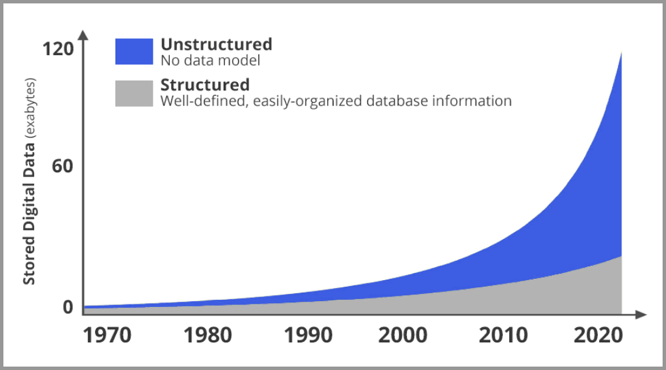
インターネットの急速な発展により、コンピューター ビジョンも特に重要になってきました。以下の図は、2020 年以降のネットワーク上の新規データ量の傾向グラフです。灰色のグラフィックは構造化データ、青色のグラフィックは非構造化データ (主に写真とビデオ) です。写真やビデオの数が指数関数的に増加していることは明らかです。
3. コンピューター ビジョンとは
コンピューター ビジョンは人工知能分野の重要な分野であり、簡単に言えば、コンピューターに画像やビデオの内容を理解させることで解決できる問題です。例: 写真のペットは猫ですか、それとも犬ですか?写真の人物はラオ・チャンですか、それともラオ・ワンですか?ビデオの中の人たちは何をしているのですか?さらに、コンピュータビジョンとは、人間の目の代わりにカメラやコンピュータを使用してターゲットを識別、追跡、測定し、さらにグラフィック処理を実行して、人間の目での観察や検出用の機器への送信により適した画像を取得することを指します。科学分野として、コンピューター ビジョンは関連する理論と技術を研究し、画像や多次元データから高レベルの情報を取得できる人工知能システムの構築を試みています。エンジニアリングの観点から見ると、自動化システムを活用して人間の視覚システムを模倣し、タスクを完了することを目指しています。コンピューター ビジョンの最終目標は、コンピューターが人間と同じように視覚を通じて世界を観察および理解できるようにし、自律的に環境に適応できるようにすることです。しかし、コンピュータがカメラを通して世界を認識できることを真に理解することは非常に困難です。カメラで捉えた画像は私たちが普段見ているものと同じですが、コンピュータにとってはどんな画像も単なるピクセルの配置と組み合わせにすぎないからです。値: 厳格な数値の束。コンピューターがこれらの厳密な数値から意味のある視覚的な手がかりを読み取ることができるようにする方法は、コンピューター ビジョンが解決すべき問題です。
4. コンピューター ビジョンの基本原理
カメラや携帯電話を使ったことがある人なら誰でも、コンピューターが驚くほど忠実で詳細な写真を撮るのが得意であることを知っています。ある程度、コンピューターは人工的なものです。 「視覚」は人間の自然な視覚能力よりもはるかに強力です。しかし、私たちがよく「聞いても理解できない」と言われるように、「見える」ことが「理解できる」わけではないので、コンピュータに画像を真に「理解」してもらいたいと思うと、それは簡単なことではありません。画像はピクセルの大きなグリッドであり、各ピクセルには、赤、緑、青の 3 原色の組み合わせである色があります。 RGB 値と呼ばれる 3 つの色の強度を組み合わせることで、任意の色を得ることができます。始めるのに最も単純で最も適したコンピューター ビジョン アルゴリズムは次のとおりです。ピンクのボールなどの色付きのオブジェクトを追跡するには、まずボールの色を記録し、中心ピクセルの RGB 値を保存し、次に画像をプログラムにこの色に最も近いピクセルを見つけさせます。アルゴリズムは左上隅から開始して各ピクセルを調べ、ターゲットの色との差を計算します。各ピクセルをチェックした後、ピクセルの最も近い部分がボールがあるピクセルである可能性があります。このアルゴリズムはこの 1 つの画像での実行に限定されず、ビデオの各フレームでアルゴリズムを実行してボールの位置を追跡することができます。もちろん、光や影などの影響でボールの色は変化しますので、保存したRGB値と全く同じではありませんが、かなり近いものにはなります。ただし、夜間のフットボールの試合などの極端な場合には、追跡効果が非常に劣る可能性があり、チームのジャージの 1 つがボールと同じ色の場合、アルゴリズムは完全に「失神」します。したがって、環境を厳密に制御できない限り、このような色追跡アルゴリズムが実用化されることはほとんどありません。現在、コンピュータ ビジョンのアルゴリズムには「深層学習」の手法や技術が使われることが多くなっていますが、その中でも性能が優れている畳み込みニューラル ネットワーク (CNN) が最も広く使われています。 「ディープラーニング」に関連する知識は広すぎるため、この記事ではこれ以上詳しく説明しません。 「ディープラーニング」についてさらに詳しく知りたい場合は、AI 入門コース「インテル® OpenVINO™ ツールスイート初級コース」をご覧ください。 AI の基本概念から始まり、人工知能とビジョン アプリケーションに関する関連知識を紹介し、ユーザーがインテル® OpenVINO™ ツール スイートの基本概念とアプリケーション シナリオをすぐに理解できるようにします。コース全体には、ビデオ処理、ディープ ラーニングに関連する知識、人工知能アプリケーションの推論アクセラレーション、インテル® OpenVINO™ ツール スイートのデモ デモンストレーションが含まれており、ディープ ラーニングを浅いところから深いところまで段階的にマスターすることができます。
5. コンピューター ビジョンの典型的なタスク
- 画像分類
画像分類は、画像の意味情報に基づいて画像のさまざまなカテゴリを区別することです。 . それはコンピュータです 視覚の中核は、物体検出、画像セグメンテーション、物体追跡、行動分析、顔認識などの他の高レベルの視覚タスクの基礎です。たとえば、下の図では、コンピューターは画像分類を通じて、画像内の人物、木、草、空を認識します。

画像分類は、セキュリティ分野での顔認識とインテリジェントビデオ分析、交通分野での交通シーン認識、インターネットベースなど、多くの分野で広く使用されています。コンテンツの画像検索やフォトアルバムの自動分類、医療分野での画像認識など。
- オブジェクト検出
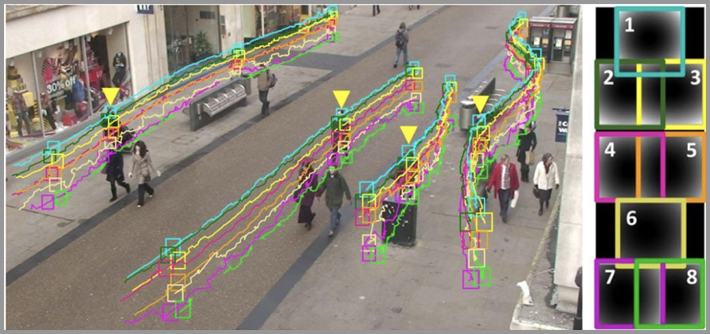
ターゲット検出タスクの目標は、画像またはビデオ フレームを与え、コンピューターにその中のすべてのターゲットの位置を検出させ、各ターゲットを与えることです。特定のカテゴリー。以下の図に示すように、人物の認識と検出を例として、境界線を使用して画像内のすべての人物の位置をマークします。

マルチカテゴリのターゲット検出では、通常、次の図に示すように、さまざまな色の境界線を使用して、さまざまな検出されたオブジェクトの位置をマークします。

- セマンティック セグメンテーション
セマンティック セグメンテーションは、コンピューター ビジョンの基本的なタスクです。セマンティック セグメンテーションでは、視覚入力を次のように分割する必要があります。意味的に解釈可能なさまざまなカテゴリ。画像全体をピクセルのグループに分割し、ラベルを付けて分類します。たとえば、画像内の車に属するすべてのピクセルを区別し、それらのピクセルを青に色付けしたい場合があります。以下に示すように、画像は人物 (赤)、木 (深緑)、草 (薄緑)、空 (青) のラベルに分割されます。
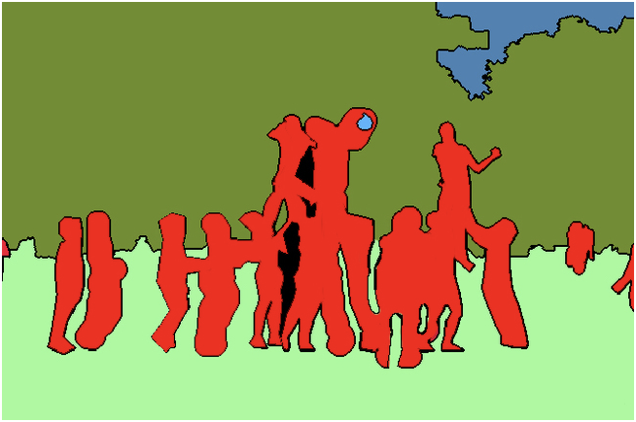
インスタンス セグメンテーションインスタンス セグメンテーションは、ターゲット検出とセマンティック セグメンテーションを組み合わせたものです。画像内でターゲットが検出され (ターゲット検出)、各ピクセルにラベルが付けられます (セマンティック セグメンテーション)。 ))。上の図と下の図を比較すると、人間のターゲットが使用されている場合、セマンティック セグメンテーションでは同じカテゴリに属する異なるインスタンスが区別されない (すべての人が赤でマークされている) のに対し、インスタンス セグメンテーションでは同じカテゴリの異なるインスタンスが区別されることがわかります (異なる人を区別するために異なる色が使用されます)。


- 駐車場と料金所のナンバー プレート認識

- # Web サイトやアプリにビデオをアップロードする際のリスクの特定

- Douyin やその他の APP 上のさまざまな自撮り小道具 (必須。最初に位置を特定する)
以上がコンピューター ビジョンを理解するための 1 つの記事、役立つ情報が満載の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7463
7463
 15
1376
52
77
11
18
17
15
1376
52
77
11
18
17

 2024 CSRankings 全国コンピュータ サイエンス ランキングが発表されました! CMUがリストを独占、MITはトップ5から外れる
Mar 25, 2024 pm 06:01 PM
2024 CSRankings 全国コンピュータ サイエンス ランキングが発表されました! CMUがリストを独占、MITはトップ5から外れる
Mar 25, 2024 pm 06:01 PM
2024CSRankings 全国コンピューターサイエンス専攻ランキングが発表されました。今年、米国の最高のCS大学のランキングで、カーネギーメロン大学(CMU)が国内およびCSの分野で最高の大学の一つにランクされ、イリノイ大学アーバナシャンペーン校(UIUC)は6年連続2位となった。 3位はジョージア工科大学。次いでスタンフォード大学、カリフォルニア大学サンディエゴ校、ミシガン大学、ワシントン大学が世界第4位タイとなった。 MIT のランキングが低下し、トップ 5 から外れたことは注目に値します。 CSRankings は、マサチューセッツ大学アマースト校コンピューター情報科学部のエメリー バーガー教授が始めたコンピューター サイエンス分野の世界的な大学ランキング プロジェクトです。ランキングは客観的なものに基づいています
 リモート デスクトップがリモート コンピュータの ID を認証できない
Feb 29, 2024 pm 12:30 PM
リモート デスクトップがリモート コンピュータの ID を認証できない
Feb 29, 2024 pm 12:30 PM
Windows リモート デスクトップ サービスを使用すると、ユーザーはコンピュータにリモート アクセスできるため、リモートで作業する必要がある人にとっては非常に便利です。ただし、ユーザーがリモート コンピュータに接続できない場合、またはリモート デスクトップがコンピュータの ID を認証できない場合、問題が発生する可能性があります。これは、ネットワーク接続の問題または証明書の検証の失敗が原因である可能性があります。この場合、ユーザーはネットワーク接続をチェックし、リモート コンピュータがオンラインであることを確認して、再接続を試行する必要がある場合があります。また、リモート コンピュータの認証オプションが正しく構成されていることを確認することが、問題を解決する鍵となります。 Windows リモート デスクトップ サービスに関するこのような問題は、通常、設定を注意深く確認して調整することで解決できます。時間または日付の違いにより、リモート デスクトップはリモート コンピューターの ID を確認できません。計算を確認してください
 このコンピュータではグループ ポリシー オブジェクトを開けません
Feb 07, 2024 pm 02:00 PM
このコンピュータではグループ ポリシー オブジェクトを開けません
Feb 07, 2024 pm 02:00 PM
コンピュータを使用しているときに、オペレーティング システムが誤動作することがあります。今日私が遭遇した問題は、gpedit.msc にアクセスすると、正しいアクセス許可がない可能性があるためグループ ポリシー オブジェクトを開けないというメッセージがシステムから表示されることでした。このコンピュータ上のグループ ポリシー オブジェクトを開けませんでした。解決策: 1. gpedit.msc にアクセスすると、アクセス許可がないため、このコンピュータ上のグループ ポリシー オブジェクトを開けないというメッセージが表示されます。詳細: システムは指定されたパスを見つけることができません。 2. ユーザーが閉じるボタンをクリックすると、次のエラー ウィンドウがポップアップ表示されます。 3. ログ レコードをすぐに確認し、記録された情報を組み合わせて、問題が C:\Windows\System32\GroupPolicy\Machine\registry.pol ファイルにあることを確認します。
 Stable Diffusion 3 の論文がついに公開され、アーキテクチャの詳細が明らかになりましたが、Sora の再現に役立つでしょうか?
Mar 06, 2024 pm 05:34 PM
Stable Diffusion 3 の論文がついに公開され、アーキテクチャの詳細が明らかになりましたが、Sora の再現に役立つでしょうか?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3 の論文がついに登場しました!このモデルは2週間前にリリースされ、Soraと同じDiT(DiffusionTransformer)アーキテクチャを採用しており、リリースされると大きな話題を呼びました。前バージョンと比較して、StableDiffusion3で生成される画像の品質が大幅に向上し、マルチテーマプロンプトに対応したほか、テキスト書き込み効果も向上し、文字化けが発生しなくなりました。 StabilityAI は、StableDiffusion3 はパラメータ サイズが 800M から 8B までの一連のモデルであると指摘しました。このパラメーター範囲は、モデルを多くのポータブル デバイス上で直接実行できることを意味し、AI の使用を大幅に削減します。
 自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転では軌道予測が重要な役割を果たしており、自動運転軌道予測とは、車両の走行過程におけるさまざまなデータを分析し、将来の車両の走行軌跡を予測することを指します。自動運転のコアモジュールとして、軌道予測の品質は下流の計画制御にとって非常に重要です。軌道予測タスクには豊富な技術スタックがあり、自動運転の動的/静的知覚、高精度地図、車線境界線、ニューラル ネットワーク アーキテクチャ (CNN&GNN&Transformer) スキルなどに精通している必要があります。始めるのは非常に困難です。多くのファンは、できるだけ早く軌道予測を始めて、落とし穴を避けたいと考えています。今日は、軌道予測に関するよくある問題と入門的な学習方法を取り上げます。関連知識の紹介 1. プレビュー用紙は整っていますか? A: まずアンケートを見てください。
 DualBEV: BEVFormer および BEVDet4D を大幅に上回る、本を開いてください!
Mar 21, 2024 pm 05:21 PM
DualBEV: BEVFormer および BEVDet4D を大幅に上回る、本を開いてください!
Mar 21, 2024 pm 05:21 PM
この論文では、自動運転においてさまざまな視野角 (遠近法や鳥瞰図など) から物体を正確に検出するという問題、特に、特徴を遠近法 (PV) 空間から鳥瞰図 (BEV) 空間に効果的に変換する方法について検討します。 Visual Transformation (VT) モジュールを介して実装されます。既存の手法は、2D から 3D への変換と 3D から 2D への変換という 2 つの戦略に大別されます。 2D から 3D への手法は、深さの確率を予測することで高密度の 2D フィーチャを改善しますが、特に遠方の領域では、深さ予測に固有の不確実性により不正確さが生じる可能性があります。 3D から 2D への方法では通常、3D クエリを使用して 2D フィーチャをサンプリングし、Transformer を通じて 3D と 2D フィーチャ間の対応のアテンション ウェイトを学習します。これにより、計算時間と展開時間が増加します。
 リモート デスクトップからローカル コンピュータにデータをコピーできない
Feb 19, 2024 pm 04:12 PM
リモート デスクトップからローカル コンピュータにデータをコピーできない
Feb 19, 2024 pm 04:12 PM
リモート デスクトップからローカル コンピューターにデータをコピーする際に問題が発生した場合は、この記事が問題の解決に役立ちます。リモート デスクトップ テクノロジを使用すると、複数のユーザーが中央サーバー上の仮想デスクトップにアクセスできるようになり、データ保護とアプリケーション管理が実現します。これにより、データのセキュリティが確保され、企業はアプリケーションをより効率的に管理できるようになります。ユーザーは、リモート デスクトップの使用中に問題に直面することがあります。その 1 つは、リモート デスクトップからローカル コンピューターにデータをコピーできないことです。これはさまざまな要因によって引き起こされる可能性があります。したがって、この記事では、この問題を解決するためのガイダンスを提供します。リモート デスクトップからローカル コンピュータにコピーできないのはなぜですか?コンピュータ上のファイルをコピーすると、そのファイルはクリップボードと呼ばれる場所に一時的に保存されます。この方法を使用してリモート デスクトップからローカル コンピュータにデータをコピーできない場合
 「Minecraft」が AI の街に変わり、NPC の住人が本物の人間のようにロールプレイ
Jan 02, 2024 pm 06:25 PM
「Minecraft」が AI の街に変わり、NPC の住人が本物の人間のようにロールプレイ
Jan 02, 2024 pm 06:25 PM
この四角い男性は、目の前にいる「招かれざる客」の正体について考えながら眉をひそめていることに注意してください。彼女が危険な状況にあることが判明し、これに気づくと、彼女は問題を解決するための戦略を見つけるためにすぐに頭の中で探索を始めました。最終的に、彼女は現場から逃走し、できるだけ早く助けを求め、直ちに行動を起こすことにしました。同時に、反対側の人も彼女と同じことを考えていた……『マインクラフト』では、登場人物全員が人工知能によって制御されている、そんなシーンがありました。それぞれに個性的な設定があり、例えば先ほどの女の子は17歳ながら賢くて勇敢な配達員です。彼らは記憶力と思考力を持ち、Minecraft の舞台となるこの小さな町で人間と同じように暮らしています。彼らを動かすのはまったく新しいものであり、
