

Google の内部文書が流出: オープンソースの大規模モデルは怖すぎて、OpenAI も耐えられない!

今日、Google が「私たちには堀はなく、OpenAI にもありません。」という文書をリークしたという記事を目にしました。この文書には、オープンソース AI に関する特定の Google 従業員 (Google 以外の企業) の見解が記載されています。その見解は次のとおりです。非常に興味深いです、大まかに言うと、これが意味するのは次のとおりです:
ChatGPT が普及した後、すべての大手メーカーが LLM に群がり、狂ったように投資を行っています。
Googleも復活を目指して懸命に取り組んでいるが、サードパーティがこの大きなケーキを黙って食べているため、この軍拡競争には誰も勝てない。
このサードパーティは大規模なオープンソース モデルです。
オープンソースの大規模モデルではこれがすでに行われています:
1. 基本モデルを Pixel 6 上で 1 秒あたり 5 トークンの速度で実行します。
2. PC 上でパーソナライズされた AI を一晩で微調整できます:
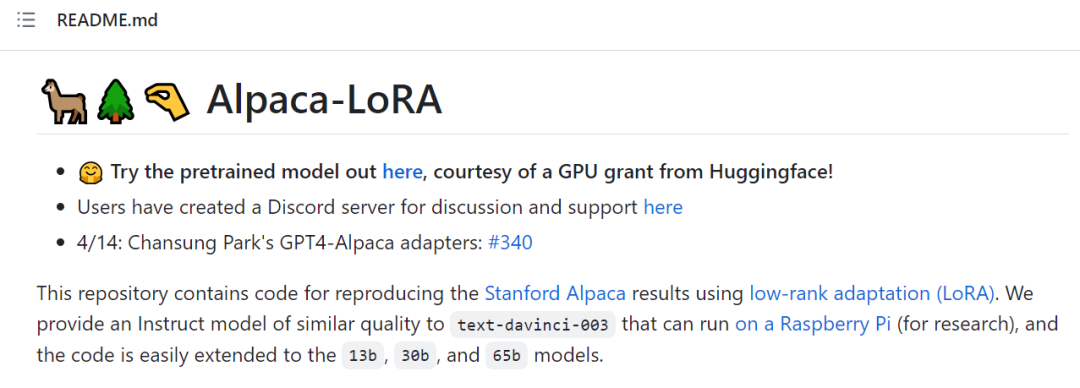
OpenAI と Google のモデルには品質の点で利点がありますが、ギャップは次のとおりです。驚くべき速度で閉鎖されています:
オープン ソース モデルは、より高速で、カスタマイズ可能で、よりプライベートで、より強力です。
オープンソースの大規模モデルは、処理に 100 ドルと 130 億のパラメータを使用し、数週間以内に完了しますが、Google は数か月以内に 1000 万ドルと 5,400 億のパラメータに苦労しています。
無料で制限のない代替手段がクローズド モデルと同じくらい優れている場合、人々は間違いなくクローズド モデルを放棄するでしょう。
すべては、Facebook が LLaMA をオープンソース化したときに始まりました。3 月初旬、オープンソース コミュニティは、この本当に有能な基本モデルを入手しました。説明、会話のチューニング、RLHF はありませんでしたが、コミュニティはすぐにこの重要性を認識しましたもの。 。
その後のイノベーションは、数日で測っても驚異的です:
2-24: Facebook が LLaMA を立ち上げますが、現時点では研究機関にのみライセンスが供与され、政府機関によって使用されています
3-03: LLaMA がインターネット上に流出し、商用利用は禁止されていましたが、突然誰でもプレイできるようになりました。
3-12: Raspberry Pi で LLaMA を実行するのは非常に遅く、非現実的です
3-13: スタンフォード大学が Alpaca をリリースし、LLaMA 用の命令チューニングを追加しました。これはさらに「恐ろしい」ものです はい、エリックスタンフォード大学の J. Wang 氏は、RTX 4090 グラフィックス カードを使用して、Alpaca と同等のモデルをわずか 5 時間でトレーニングし、そのようなモデルの計算能力要件を消費者レベルまで削減しました。
3-18: 5 日後、Georgi Gerganov は 4 ビット量子化テクノロジーを使用して、初の「GPU レス」ソリューションである LLaMA を MacBook CPU 上で実行しました。
3-19: わずか 1 日後、カリフォルニア大学バークレー校、CMU、スタンフォード大学、カリフォルニア大学サンディエゴ校の研究者が共同で Vicuna を立ち上げ、90% 以上の達成率を達成したと主張しています。 OpenAI ChatGPT と Google Bard の品質は高く、90% 以上のケースで LLaMA や Stanford Alpaca などの他のモデルよりも優れています。
3-25: Nomic は、モデルでありエコシステムでもある GPT4all を作成しました。複数のモデルが 1 か所に集まっているのは初めてです
…
In just 1 か月で、命令チューニング、量子化、品質向上、ヒューマン評価、マルチモダリティ、RLHF などがすべて登場しました。
さらに重要なのは、オープンソース コミュニティによってスケーラビリティの問題が解決され、トレーニングの敷居が大企業から 1 人、一晩、強力なパーソナル コンピューターに引き下げられたことです。
つまり、著者は最後にこう言いました。OpenAI も私たちと同じ間違いを犯したので、オープンソースの影響に耐えることはできません。オープンソースを Google で機能させるにはエコシステムを構築する必要があります。
Google はこのパラダイムを Android と Chrome に適用し、大きな成功を収めました。大規模モデルのオープンソースのリーダーとしての地位を確立し、思想的リーダーおよびリーダーとしての地位を確固たるものにし続ける必要があります。
正直に言うと、ここ 1 か月ほどの大規模な言語モデルの開発は本当に目まぐるしく圧倒され、毎日衝撃を受けています。
これを聞くと、インターネットが始まったばかりの初期の頃を思い出します。今日、あるエキサイティングな Web サイトが現れ、明日にはまた別の Web サイトが現れます。そして、モバイル インターネットが勃発すると、今日あるアプリが人気になり、明日には別のアプリが人気になる...
個人的には、これらの大きな言語モデルが巨人によって制御されることは望ましくありません。私たちができるのは、これらの巨大なモデルに「寄生」し、その API を呼び出し、いくつかのアプリケーションを開発することだけです。これは非常に不快です。百の花を咲かせ、大衆がアクセスできるようにして、誰もが自分のプライベートモデルを構築できるようにするのが最善です。
現在、中小企業でも研修費用は手頃な価格になっているはずですが、プログラマーに研修能力があれば、特定の業界や分野と組み合わせる良い機会になるかもしれません。
プログラマーが大規模な民営化モデルに習熟したい場合は、原則に加えて、やはり自分で練習する必要があります。また、地球上にはチームで練習している人が何十人もいます。コミュニティのコストは大幅に下がったが、それでも必要なモデルをトレーニングしたいが、ハードウェア環境要件が高すぎる グラフィックカードが非常に高価である RTX4090 は数万かかるのが痛い GPU のレンタル料金クラウドでのトレーニングはさらに制御不能です。トレーニングが失敗するとお金が失われます。無駄に捨ててください。言語やフレームワークを学習していくつかのインストール パッケージをダウンロードするのとは異なります。費用はほぼゼロです。
もっと敷居が下がってくれると嬉しいです!
以上がGoogle の内部文書が流出: オープンソースの大規模モデルは怖すぎて、OpenAI も耐えられない!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7364
7364
 15
1628
14
1353
52
1265
25
1214
29
15
1628
14
1353
52
1265
25
1214
29

 Googleアプリのベータ版APK分解により、Gemini AIアシスタントに新たな拡張機能が追加されることが明らかになりました
Jul 30, 2024 pm 01:06 PM
Googleアプリのベータ版APK分解により、Gemini AIアシスタントに新たな拡張機能が追加されることが明らかになりました
Jul 30, 2024 pm 01:06 PM
最新アップデート (v15.29.34.29 ベータ版) の APK 分解を考慮すると、Google の AI アシスタント Gemini はさらに高性能になる予定です。このテクノロジー巨人の新しい AI アシスタントには、いくつかの新しい拡張機能が追加される可能性があると伝えられています。これらの拡張機能は
 Pixel 9 Pro XL の Google Tensor G4 は 原神 で Tensor G2 に遅れをとっています
Aug 24, 2024 am 06:43 AM
Pixel 9 Pro XL の Google Tensor G4 は 原神 で Tensor G2 に遅れをとっています
Aug 24, 2024 am 06:43 AM
Googleは最近、Pixel 9ラインのTensor G4に関するパフォーマンスの懸念に対応しました。同社は、このSoCはベンチマークを上回るように設計されていないと述べた。代わりに、チームは Google が求めている分野でパフォーマンスを向上させることに重点を置きました。
 Google Pixel 9スマートフォンは7年間のアップデート契約にもかかわらずAndroid 15では発売されない
Aug 01, 2024 pm 02:56 PM
Google Pixel 9スマートフォンは7年間のアップデート契約にもかかわらずAndroid 15では発売されない
Aug 01, 2024 pm 02:56 PM
Pixel 9 シリーズは、8 月 13 日のリリースが予定されており、もうすぐ登場します。最近の噂によると、Pixel 9、Pixel 9 Pro、Pixel 9 Pro XLは、128 GBのストレージから始まるPixel 8とPixel 8 Pro(Amazonで現在749ドル)をミラーリングします。
 Google Pixel 9 Pro XLはデスクトップモードでテストされる
Aug 29, 2024 pm 01:09 PM
Google Pixel 9 Pro XLはデスクトップモードでテストされる
Aug 29, 2024 pm 01:09 PM
Google は、Pixel 8 シリーズで DisplayPort 代替モードを導入しており、新たに発売された Pixel 9 ラインナップにも搭載されています。これは主に、接続された画面でスマートフォンのディスプレイをミラーリングするためにありますが、デスクトップにも使用できます。
 新しい Google Pixel デスクトップ モードは、Motorola Ready For と Samsung DeX の代替として新鮮なビデオで紹介されています
Aug 08, 2024 pm 03:05 PM
新しい Google Pixel デスクトップ モードは、Motorola Ready For と Samsung DeX の代替として新鮮なビデオで紹介されています
Aug 08, 2024 pm 03:05 PM
Android Authority が、Google が Android 14 QPR3 Beta 2.1 内に隠していた新しい Android デスクトップ モードをデモンストレーションしてから数か月が経過しました。 Google が Pixel 8 と Pixel 8 に DisplayPort Alt Mode サポートを追加することに追随して登場
 Google、AI Test Kitchen & Imagen 3 をほとんどのユーザーに公開
Sep 12, 2024 pm 12:17 PM
Google、AI Test Kitchen & Imagen 3 をほとんどのユーザーに公開
Sep 12, 2024 pm 12:17 PM
Google の AI Test Kitchen には、ユーザーが遊べる一連の AI 設計ツールが含まれており、現在、世界 100 か国をはるかに超える国のユーザーに公開されています。この動きにより、世界中の多くの人が Imagen 3、Google を使用できるようになるのは初めてです。
 流出した Google Pixel 9 の広告には、「Add Me」カメラ機能を含む新しい AI 機能が示されています
Jul 30, 2024 am 11:18 AM
流出した Google Pixel 9 の広告には、「Add Me」カメラ機能を含む新しい AI 機能が示されています
Jul 30, 2024 am 11:18 AM
Pixel 9 シリーズに関連するさらなるプロモーション資料がオンラインに流出しました。参考までに、新たなリークは、91mobiles が Pixel Buds Pro 2 と Pixel Watch 3 または Pixel Watch 3 XL も紹介した複数の画像を共有した直後に到着しました。この時
 Googleの新しいChromecast「TV Streamer」は、イーサネットとスレッド接続を備えて発売されると噂されている
Aug 01, 2024 am 10:21 AM
Googleの新しいChromecast「TV Streamer」は、イーサネットとスレッド接続を備えて発売されると噂されている
Aug 01, 2024 am 10:21 AM
Googleが新しいハードウェアを完全に公開するまでにおよそ2週間かかる。いつものように、Pixel Watch 3、Pixel Buds Pro 2、Pixel 9 スマートフォンなど、数え切れないほどの情報源が新しい Pixel デバイスの詳細をリークしています。同社もそうらしい
