

Pythonのrange関数の使い方

1. range() 関数とは何ですか?
range() 関数は Python の組み込み関数で、連続して加算された一連の整数を返し、リスト オブジェクトを生成できます。
それらのほとんどは for ループに現れることが多く、for ループのインデックスとして使用できます。
簡単な質問の練習: for..range の練習
1: for ループと range を使用して、0 ~ 100 の範囲内のすべての偶数を検索し、リストに追加します。 。
list1 = []
for i in range(0,100,2):
list1.append(i)
print(list1)2: for ループと range を使用して、0 ~ 50 の範囲で 3 で割り切れる数値を見つけてリストに追加します。
list2 = []
for j in range(0,50):
if j%3 ==0:
list2.append(j)
print(list2)3: for ループと range を使用して、0 ~ 50 の範囲で 3 で割り切れる数値を検索し、リストの 0 番目のインデックス位置に挿入します。最終的な結果は次のようになります: [48, 45,42.. .]
list3 = []
for k in range(0,50):
if k%3 == 0:
list3.insert(0,k)
print(list3)4: リスト li 内の要素を見つけて、各要素の前後のスペースを削除し、「a」で始まる要素を見つけて、新しいリストに追加します。そして最後に新しいリストをループリストに出力します。
li = ["alexC", "AbC ", "egon", " riTiAn", "WuSir", " aqc"]'''
li = ["alexC", "AbC ", "egon", " riTiAn", "WuSir", " aqc"]
li1 = []
for m in li:
b = m.strip().startswith('a')
if b == True :
li1.append(m.strip())
for n in li1:
print(n)2. 文法形式
range(start, stop [,step])
パラメータの紹介:
start はカウントの開始値を指し、次の値を指定できます。省略 書かれていない場合、デフォルトは 0 です;
stop はカウントの終了値を指しますが、stop は含まれません;
step はステップ サイズで、デフォルトは 1 であり、0 にすることはできません。
(特記事項: パラメーターが 3 つある場合、最後のパラメーターはステップ サイズとして表されます。)
ps1: 1 つだけパラメータ : パラメータ自体を除く、0 からこのパラメータまでのすべての整数を示します。
ran = range(6) # 定义一个list,将range范围内的数都存入list arry_list = list(ran) print(ran) print(arry_list) #运行结果如下 range(0, 6) [0, 1, 2, 3, 4, 5]
ps2:
範囲関数に 2 つのパラメータがある場合、最初のパラメータは左境界を表します。 、2 番目のパラメーターは、右側ではなく左側を含む右側の境界を表します。
ran_new = range(1, 8) list_one = list(ran_new) # 将range范围内的数据都存入list print(list_one) #运行结果 [1, 2, 3, 4, 5, 6, 7]
ps3:
range に 3 つのパラメーターが含まれる場合、最初のパラメーターは左境界を表し、2 番目は右境界を表し、3 番目はステップ サイズを表します。 、つまり、2 つの整数の差 (左側は含むが右側は含まない)。
# range含有3个参数时,第一个表示左边界,第二个表示右边界,第三个表示步长step,即两个整数之间相差的数,含左不含右 ran_two = range(1, 16,2) list_two = list(ran_two) # list_two= print(ran_new) print(ran_two) print(list_two)
実行結果は次のとおりです:
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12、13、14、15]
範囲(1, 16)
範囲(1, 16, 2)
[1, 3, 5, 7, 9, 11, 13, 15]
例:
print("实例一:起始值为1,结束值为10")
for i in range(1,10):
print(i,end='')
print("\n实例二:结束值为10")
for i in range(10): print(i,end='')
print("\n实例三:结束值为10,步长为2")
for i in range(1,10,2):
print(i,end='')実行結果:
例 1: 開始値は 1 です。終了値は 10123456789 例 2: 終了値は 100123456789 例 3: 終了値は 10、ステップ サイズは 213579
3. エラー報告問題
(1) エラーレポート: TypeError: ‘list&rsquo ; オブジェクトは呼び出し可能ではありません。
はエラーの種類を示します: 「リスト」オブジェクトを呼び出すことができません
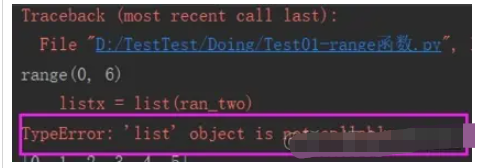
理由:
変数 list と関数 list は同じ名前であるため、関数が list 関数を使用すると、list が定義されたリストであることがわかり、リストを呼び出すことができないため、型エラーがスローされます。したがって、今後変数を定義するときは、他の言語と同様に、関数名、メソッド名、キーワードの重複を避ける必要があります。
(2) range 関数が次のエラーを報告した場合はどうなりますか?
TypeError: ‘float‘ オブジェクトは整数として解釈できません。
その理由は、range が float 型ではなく整数のみを生成できるためです。問題を解決するには、numpy の arange 関数を使用してください:
import numpy as np for i in np.arange(0.1,0.5,0.05): print(i) # 0.1,0.15,0.2,...,0.4,0.45, 不包含0.5! # 或者 l = list(np.arange(0.1,0.5,0.05))
4. range() 関数に関する注意事項
① 左側が閉じ、右側が開いている間隔を表します;
② 受け取るパラメータは整数である必要があり、負の数も可能ですが、浮動小数点数は使用できませんまたは他の型;
'''判断指定的整数 在序列中是否存在 in ,not in''' print(10 in r) #False ,10不在当前的r这个整数序列中 print(9 in r) #true ,9在当前的这个r序列里 print(9 not in r) #false ,9不在当前的这个r序列里
③ 不変です シーケンス型は要素の判断、要素の検索、スライスなどの操作を実行できますが、要素を変更することはできません;
④ 反復可能ですオブジェクトですが、イテレータではありません。
# (1)左闭右开
>>> for i in range(3, 6):>>>
print(i,end=" ")3 4 5
# (2)参数类型
>>> for i in range(-8, -2, 2):>>>
print(i,end=" ")-8 -6 -4>>> range(2.2)----------------------------TypeError Traceback (most recent call last)...TypeError:
'float' object cannot be interpreted as an integer
# (3)序列操作
>>> b = range(1,10)>>> b[0]1>>> b[:-3]range(1, 7)>>> b[0] = 2TypeError Traceback (most recent call last)...TypeError:
'range' object does not support item assignment
# (4)不是迭代器
>>> hasattr(range(3),'__iter__')True>>>
hasattr(range(3),'__next__')False>>> hasattr(iter(range(3)),'__next__')True5. Range オブジェクトは不変シーケンスです
公式の区分は次のように明確です - リスト、タプル、範囲 (範囲) オブジェクトの 3 つの基本的なシーケンス タイプがあります。
(基本的なシーケンス タイプは、リスト、タプル、レンジ オブジェクトの 3 つです。)
レンジ タイプは、リストやタプルと同じ位置にある基本的なシーケンスです。 レンジ シーケンスと他のシーケンス タイプの違いは何ですか?
通常のシーケンスでは 12 の演算がサポートされますが、範囲シーケンスではそのうち 10 の演算のみがサポートされます。加算スプライシングと乗算の繰り返しはサポートされていません。
>>> range(2) + range(3)-----------------------------------------TypeError Traceback (most recent call last)...TypeError: unsupported operand type(s) for +: 'range' and 'range' >>> range(2)*2-----------------------------------------TypeError Traceback (most recent call last)...TypeError: unsupported operand type(s) for *: 'range' and 'int'
次に疑問が生じます: も不変シーケンスです。なぜ文字列とタプルは上記 2 つの操作をサポートしているのに、範囲シーケンスはサポートしていないのでしょうか?
不変シーケンスを直接変更することはできませんが、それらを新しいシーケンスにコピーして操作することはできます。なぜ範囲オブジェクトはこれをサポートしないのでしょうか?
公式ドキュメントからの説明:
...範囲オブジェクトは、厳密なパターンと繰り返しと連結に従うシーケンスのみを表現できるという事実のため通常、そのパターンに違反します。
その理由は、範囲オブジェクトは厳密なパターンに従うシーケンスのみを表しており、繰り返しとスプライシングは通常、このパターンに違反するためです...
问题的关键就在于 range 序列的 pattern!仔细想想,其实它表示的就是一个等差数列,拼接两个等差数列,或者重复拼接一个等差数列,这就是为啥 range 类型不支持这两个操作的原因了。因此可以得出结论,任何修改行为都会破坏等差数列的结构,因此最好不要进行任何修改。
【range类型的优点】
不管range对象表示的整数序列有多长,所有range对象占用的内存空间都是相同的,因为仅仅需要存储start、stop和step。只有当用到range对象时,才会去计算序列中的相关元素。
6、range函数实现逆序遍历
range函数实现逆序遍历两种实现方式
1)先创建一个列表,然后对列表中的元素进行逆序
例如:a=range(4)
a=range(4) # [0, 1, 2, 3]new =[]for i in reversed(a): new.append(i)print(new) # [3, 2, 1, 0]
2)直接使用range()函数完成逆序遍历
//第三个参数表示的是100所有进行的操作,每次加上-1,直到0for i in range(100,0,-1): print(i)
7、与列表list的使用
list1 = ["看不", "见你", "的", "笑", "我怎么", "睡", "得", "着"] for i in range(len(list1)): print(i, list1[i])
运行结果:

【range与list的区别】
range()是依次取顺序的数值,常与for循环一起用,如for范围内的每个(0, 5):for循环执行5次,每个取值是0〜4。而list()是把字符串转换为列表,如a = ’01234’ , b = list(a), a打印出来会是一个列表:[‘0’,‘1’,‘2’,‘3’,‘4’],如a = [0, 1, 2, 3, 4],输出的结果就会是[0, 1, 2, 3, 4]
#对比range与list
for i in range(0, 5):
print(i)
a = [0, 1, 2, 3, 4]
print(a)8、关于range函数小结
(1)range对象的使用和理解都不难,但是在python的使用中非常常用!
(2)range对象既不是函数也不是迭代器,可以叫它“懒序列”;
(3)参数解释:start为范围开始,stop为范围结束,step为步长;
(4)range对象经常和for循环配合使用;
(5)可以对range对象进行索引;
关于range()函数还有一点需要注意的地方:range() 方法生成的只是可迭代对象,并不是迭代器!(Python2 中 range() 生成的是列表,本文基于Python3,生成的是可迭代对象)可以获得迭代器的内置方法很多,例如 zip() 、enumerate()、map()、filter() 和 reversed() 等等,但是像 range() 这样仅仅得到的是可迭代对象的方法就少有了。
在 for-循环 遍历时,可迭代对象与迭代器的性能是一样的,即它们都是惰性求值的,在空间复杂度与时间复杂度上并无差异。两者的差别概括是:相同的是都可惰性迭代,不同的是可迭代对象不支持自遍历(即next()方法),而迭代器本身不支持切片(即__getitem__() 方法)。虽然有这些差别,但很难得出结论说它们哪个更优。
那为什么给 5 种内置方法都设计了迭代器,偏偏给 range() 方法设计的就是可迭代对象呢?把它们都统一起来,不是更好么?事实上,Pyhton 为了规范性就干过不少这种事,例如,Python2 中有 range() 和 xrange() 两种方法,而 Python3 就干掉了其中一种。为什么不更规范点,令 range() 生成的是迭代器呢?
这个问题看到有大佬说的比较好的观点,这里引用一下:
zip() 等方法都需要接收确定的可迭代对象的参数,是对它们的一种再加工的过程,因此也希望马上产出确定的结果来,所以 Python 开发者就设计了这个结果是迭代器。
这样还有一个好处,即当作为参数的可迭代对象发生变化的时候,作为结果的迭代器因为是消耗型的,不会被错误地使用。
而 range() 方法就不同了,它接收的参数不是可迭代对象,本身是一种初次加工的过程,所以设计它为可迭代对象,既可以直接使用,也可以用于其它再加工用途。
例如,zip() 等方法就完全可以接收 range 类型的参数。
>>> for i in zip(range(1,6,2), range(2,7,2)):>>> print(i, end="")(1, 2)(3, 4)(5, 6)
也就是说,range() 方法作为一种初级生产者,它生产的原料本身就有很大用途,早早把它变为迭代器的话,无疑是一种画蛇添足的行为。重点不在于range对象是什么,而在于我们如何使用它
以上がPythonのrange関数の使い方の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7478
7478
 15
1377
52
77
11
19
33
15
1377
52
77
11
19
33

 mysqlは支払う必要がありますか
Apr 08, 2025 pm 05:36 PM
mysqlは支払う必要がありますか
Apr 08, 2025 pm 05:36 PM
MySQLには、無料のコミュニティバージョンと有料エンタープライズバージョンがあります。コミュニティバージョンは無料で使用および変更できますが、サポートは制限されており、安定性要件が低く、技術的な能力が強いアプリケーションに適しています。 Enterprise Editionは、安定した信頼性の高い高性能データベースを必要とするアプリケーションに対する包括的な商業サポートを提供し、サポートの支払いを喜んでいます。バージョンを選択する際に考慮される要因には、アプリケーションの重要性、予算編成、技術スキルが含まれます。完璧なオプションはなく、最も適切なオプションのみであり、特定の状況に応じて慎重に選択する必要があります。
 インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
この記事では、MySQLデータベースの操作を紹介します。まず、MySQLWorkBenchやコマンドラインクライアントなど、MySQLクライアントをインストールする必要があります。 1. mysql-uroot-pコマンドを使用してサーバーに接続し、ルートアカウントパスワードでログインします。 2。CreatedAtaBaseを使用してデータベースを作成し、データベースを選択します。 3. createTableを使用してテーブルを作成し、フィールドとデータ型を定義します。 4. INSERTINTOを使用してデータを挿入し、データをクエリし、更新することでデータを更新し、削除してデータを削除します。これらの手順を習得することによってのみ、一般的な問題に対処することを学び、データベースのパフォーマンスを最適化することでMySQLを効率的に使用できます。
 MySQLはダウンロード後にインストールできません
Apr 08, 2025 am 11:24 AM
MySQLはダウンロード後にインストールできません
Apr 08, 2025 am 11:24 AM
MySQLのインストール障害の主な理由は次のとおりです。1。許可の問題、管理者として実行するか、SUDOコマンドを使用する必要があります。 2。依存関係が欠落しており、関連する開発パッケージをインストールする必要があります。 3.ポート競合では、ポート3306を占めるプログラムを閉じるか、構成ファイルを変更する必要があります。 4.インストールパッケージが破損しているため、整合性をダウンロードして検証する必要があります。 5.環境変数は誤って構成されており、環境変数はオペレーティングシステムに従って正しく構成する必要があります。これらの問題を解決し、各ステップを慎重に確認して、MySQLを正常にインストールします。
 MySQLダウンロードファイルが破損しており、インストールできません。修復ソリューション
Apr 08, 2025 am 11:21 AM
MySQLダウンロードファイルが破損しており、インストールできません。修復ソリューション
Apr 08, 2025 am 11:21 AM
mysqlダウンロードファイルは破損していますが、どうすればよいですか?残念ながら、MySQLをダウンロードすると、ファイルの破損に遭遇できます。最近は本当に簡単ではありません!この記事では、誰もが迂回を避けることができるように、この問題を解決する方法について説明します。それを読んだ後、損傷したMySQLインストールパッケージを修復するだけでなく、将来の行き詰まりを避けるために、ダウンロードとインストールプロセスをより深く理解することもできます。最初に、ファイルのダウンロードが破損した理由について話しましょう。これには多くの理由があります。ネットワークの問題は犯人です。ダウンロードプロセスの中断とネットワーク内の不安定性は、ファイル腐敗につながる可能性があります。ダウンロードソース自体にも問題があります。サーバーファイル自体が壊れており、もちろんダウンロードすると壊れています。さらに、いくつかのウイルス対策ソフトウェアの過度の「情熱的な」スキャンもファイルの破損を引き起こす可能性があります。診断問題:ファイルが本当に破損しているかどうかを判断します
 mysqlはインターネットが必要ですか?
Apr 08, 2025 pm 02:18 PM
mysqlはインターネットが必要ですか?
Apr 08, 2025 pm 02:18 PM
MySQLは、基本的なデータストレージと管理のためにネットワーク接続なしで実行できます。ただし、他のシステムとのやり取り、リモートアクセス、または複製やクラスタリングなどの高度な機能を使用するには、ネットワーク接続が必要です。さらに、セキュリティ対策(ファイアウォールなど)、パフォーマンスの最適化(適切なネットワーク接続を選択)、およびデータバックアップは、インターネットに接続するために重要です。
 高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
MySQLデータベースパフォーマンス最適化ガイドリソース集約型アプリケーションでは、MySQLデータベースが重要な役割を果たし、大規模なトランザクションの管理を担当しています。ただし、アプリケーションのスケールが拡大すると、データベースパフォーマンスのボトルネックが制約になることがよくあります。この記事では、一連の効果的なMySQLパフォーマンス最適化戦略を検討して、アプリケーションが高負荷の下で効率的で応答性の高いままであることを保証します。実際のケースを組み合わせて、インデックス作成、クエリ最適化、データベース設計、キャッシュなどの詳細な主要なテクノロジーを説明します。 1.データベースアーキテクチャの設計と最適化されたデータベースアーキテクチャは、MySQLパフォーマンスの最適化の基礎です。いくつかのコア原則は次のとおりです。適切なデータ型を選択し、ニーズを満たす最小のデータ型を選択すると、ストレージスペースを節約するだけでなく、データ処理速度を向上させることもできます。
 MySQLインストール後に開始できないサービスのソリューション
Apr 08, 2025 am 11:18 AM
MySQLインストール後に開始できないサービスのソリューション
Apr 08, 2025 am 11:18 AM
MySQLは開始を拒否しましたか?パニックにならないでください、チェックしてみましょう!多くの友人は、MySQLのインストール後にサービスを開始できないことを発見し、彼らはとても不安でした!心配しないでください、この記事はあなたがそれを落ち着いて対処し、その背後にある首謀者を見つけるためにあなたを連れて行きます!それを読んだ後、あなたはこの問題を解決するだけでなく、MySQLサービスの理解と問題のトラブルシューティングのためのあなたのアイデアを改善し、より強力なデータベース管理者になることができます! MySQLサービスは開始に失敗し、単純な構成エラーから複雑なシステムの問題に至るまで、多くの理由があります。最も一般的な側面から始めましょう。基本知識:サービススタートアッププロセスMYSQLサービススタートアップの簡単な説明。簡単に言えば、オペレーティングシステムはMySQL関連のファイルをロードし、MySQLデーモンを起動します。これには構成が含まれます
 MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLパフォーマンスの最適化は、インストール構成、インデックス作成、クエリの最適化、監視、チューニングの3つの側面から開始する必要があります。 1。インストール後、INNODB_BUFFER_POOL_SIZEパラメーターやclose query_cache_sizeなど、サーバーの構成に従ってmy.cnfファイルを調整する必要があります。 2。過度のインデックスを回避するための適切なインデックスを作成し、説明コマンドを使用して実行計画を分析するなど、クエリステートメントを最適化します。 3. MySQL独自の監視ツール(ShowProcessList、ShowStatus)を使用して、データベースの健康を監視し、定期的にデータベースをバックアップして整理します。これらの手順を継続的に最適化することによってのみ、MySQLデータベースのパフォーマンスを改善できます。
