

上海科技大学などがDreamFaceをリリース:テキストだけで「超リアルな3Dデジタルヒューマン」を生成できる

ラージ言語モデル (LLM) や拡散 (Diffusion) などのテクノロジーの発展に伴い、ChatGPT や Midjourney などの製品の誕生により AI ブームの新たな波が起こり、生成 AI も非常に懸念される話題です。
テキストや画像とは異なり、3D 生成はまだ技術探索の段階にあります。
2022 年末、Google、NVIDIA、Microsoft は相次いで独自の 3D 生成作業を開始しましたが、そのほとんどは高度な Neural Radiation Field (NeRF) の暗黙的表現に基づいており、産業用 3D ソフトウェアと互換性がない Unity、Unreal Engine、Maya などのレンダリング パイプラインには互換性がありません。
従来のソリューションでメッシュで表現される幾何学マップやカラーマップに変換したとしても、精度不足やビジュアル品質の低下を引き起こすため、映画やテレビの制作や制作に直接適用することはできません。ゲーム制作。

#プロジェクトのウェブサイト: https://sites.google.com/view/dreamface
#論文アドレス: https://arxiv.org/abs/2304.03117
Web デモ: https://arxiv.org/abs/2304.03117 ://hyperhuman.top
HuggingFace スペース: https://huggingface.co/spaces/DEEMOSTECH/ChatAvatar
これらの問題を解決するために、Yingmo Technology と上海科技大学の研究開発チームは、テキストガイドによるプログレッシブ 3D 生成フレームワークを提案しました。このフレームワークは、CG 制作標準に準拠した外部データセット (ジオメトリや PBR マテリアルを含む) を導入し、テキストに基づいてこの標準に準拠した 3D アセットを直接生成できます。 3D アセット生成のための Production-Ready A フレームワークを初めてサポートしました。
テキスト生成主導の 3D ハイパーリアルなデジタル ヒューマンを実現するために、チームはこのフレームワークをプロダクション グレードの 3D デジタル ヒューマン データセットと組み合わせました。この作品は、コンピュータ グラフィックス分野のトップ国際ジャーナルである Transactions on Graphics に受理され、トップの国際コンピュータ グラフィックス会議である SIGGRAPH 2023 で発表される予定です。
DreamFace には主に、ジオメトリ生成、物理ベースのマテリアル拡散、アニメーション機能生成の 3 つのモジュールが含まれています。
以前の 3D 生成作品と比較して、この作品の主な貢献は次のとおりです:
· DreamFace の提案 この小説生成的アプローチでは、幾何学、外観、およびアニメーション機能を分離するための漸進的学習を使用して、最近の視覚言語モデルとアニメーション化可能かつ物理的に実体化可能な顔アセットを組み合わせます。
· 新しいマテリアル拡散モデルと事前トレーニング済みモデルを潜在空間と画像空間で同時に組み合わせた、デュアルチャネル外観生成の設計を紹介します。 2 段階の最適化を実行します。
· BlendShape または生成されたパーソナライズされた BlendShape を使用した顔アセットにはアニメーション機能があり、自然なキャラクター デザインのための DreamFace の使用をさらに実証します。 ジオメトリ生成
ジオメトリ生成モジュールは、テキスト プロンプトに基づいて一貫したジオメトリ モデルを生成できます。ただし、顔の生成に関しては、監視して収束することが困難な場合があります。したがって、DreamFace は、最初に顔の幾何学的パラメータ空間でランダムにサンプリングされた候補から最適な候補を選択する、CLIP (Contrastive Language-Image Pre-Training) に基づく選択フレームワークを提案します。適切な大まかなジオメトリ モデルを作成し、その後、ジオメトリの詳細を彫刻して、頭部モデルとテキスト プロンプトの一貫性を高めます。
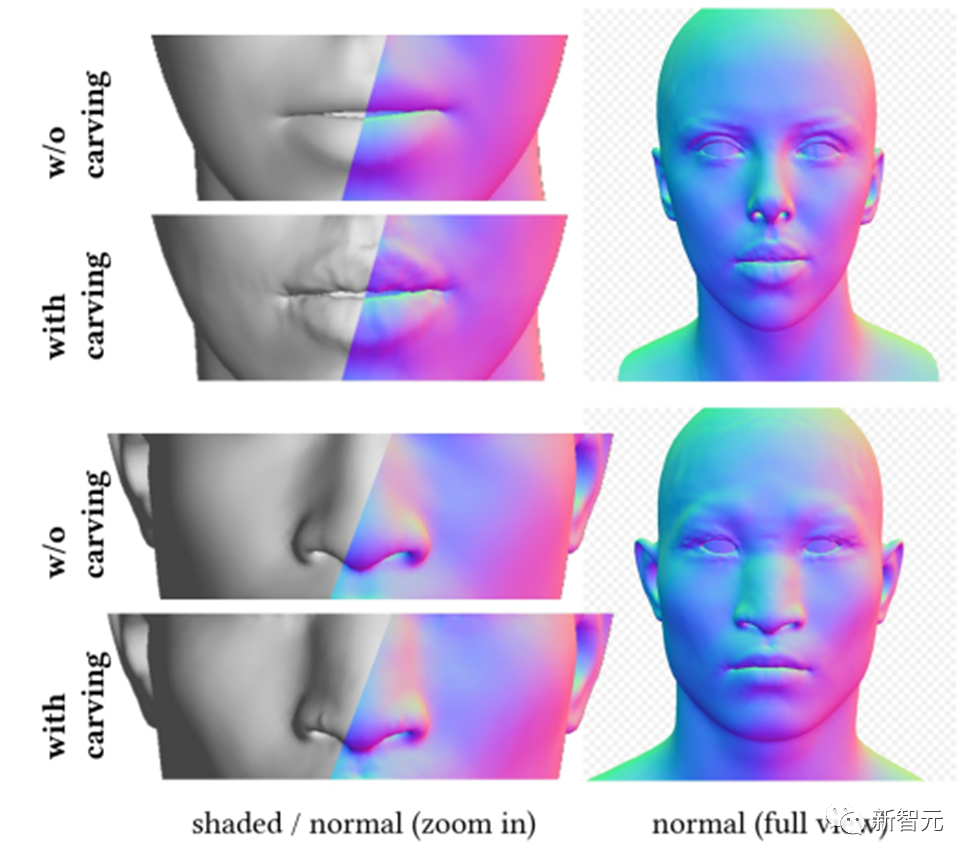
これにより、DreamFace は頂点ディスプレイスメントと詳細な法線マップを通じて大まかなジオメトリ モデルに顔の詳細を追加できるようになり、結果として非常に詳細なジオメトリが得られます。
頭部モデルと同様に、DreamFace もこのフレームワークに基づいて髪型と色の選択を行います。 物理ベースのマテリアル拡散モジュールは、予測されたジオメトリおよびテキスト キューと一致する顔のテクスチャを予測するように設計されています。 まず、DreamFace は、収集された大規模な UV マテリアル データ セットに基づいて事前トレーニングされた LDM を微調整し、2 つの LDM 拡散モデルを取得しました。 物理ベースのマテリアル拡散生成

DreamFace は、2 つの拡散プロセスを調整する共同トレーニング スキームを使用します。1 つは UV テクスチャ マップを直接ノイズ除去するためのもので、もう 1 つは拡散プロセスです。は、レンダリングされたイメージを監視して、顔の UV マップとレンダリングされたイメージがテキスト キューと一貫して正しく形成されていることを確認するために使用されます。
生成時間を短縮するために、DreamFace は粗いテクスチャ ポテンシャル拡散ステージを採用し、詳細なテクスチャ生成に先験的なポテンシャルを提供します。
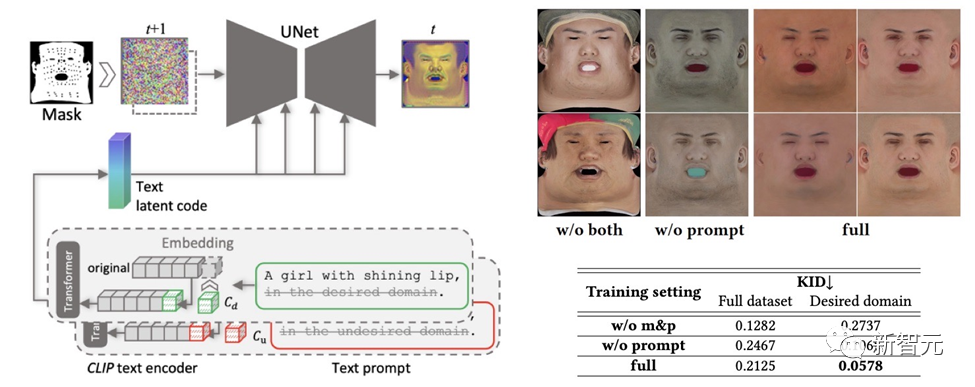
#作成されたテクスチャ マップに多様性を維持しながら、望ましくない特徴や照明状況が含まれないようにするため、デザインは手がかりとなる学習戦略。
チームは、次の 2 つの方法を使用して高品質の拡散反射マップを生成します。
(1) プロンプト チューニング。手作りのドメイン固有のテキスト キューとは異なり、DreamFace は 2 つのドメイン固有の連続テキスト キュー Cd および Cu を対応するテキスト キューと組み合わせます。これらは U-Net デノイザー トレーニング中に最適化され、不安定性や時間のかかるプロンプトの手動作成を回避します。
(2) 顔以外の領域のマスキング。 LDM ノイズ除去プロセスは、結果として得られる拡散マップに不要な要素が含まれないようにするために、非顔領域マスクによってさらに制約されます。
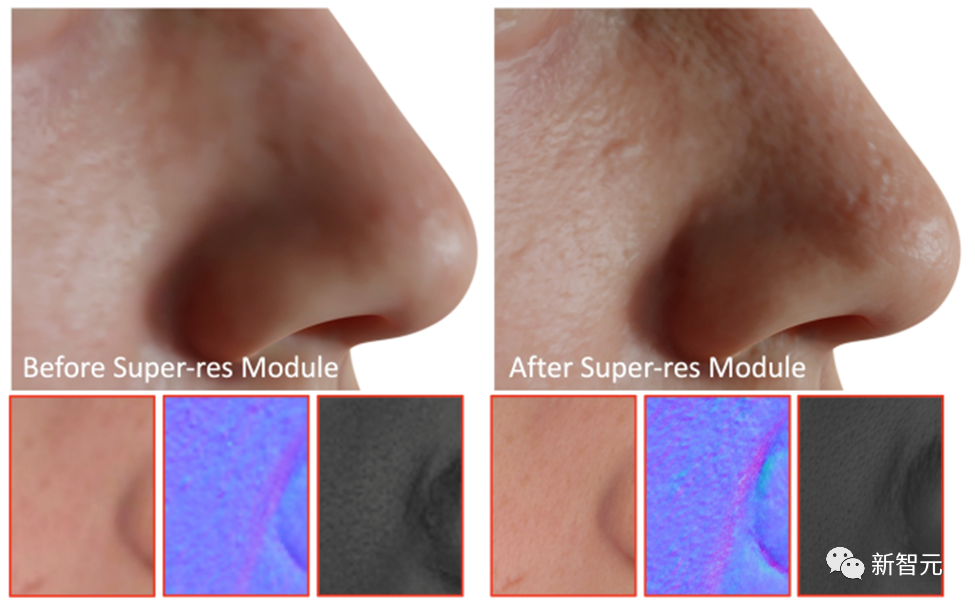
最終ステップとして、DreamFace は超解像度モジュールを適用して、高品質の 4K 物理ベースのテクスチャを生成します。レンダリング。

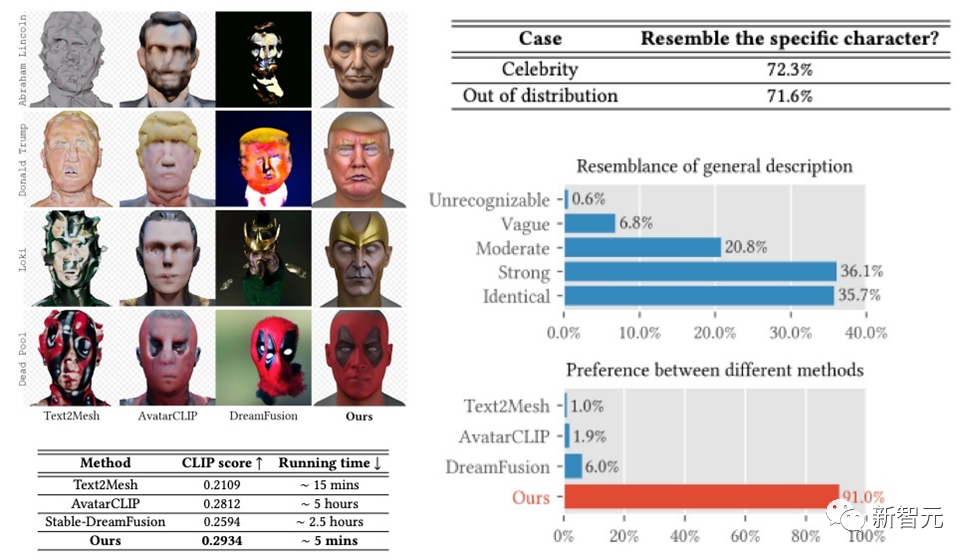
DreamFace フレームワークは、有名人の生成と説明に基づいたキャラクターの生成において非常に良い結果を達成しました。前作を遥かに超える成果が得られました。以前の作品と比較すると、実行時間においても明らかな利点があります。
# これに加えて、DreamFace はヒントとスケッチを使用したテクスチャ編集もサポートしています。エイジングやメイクアップなどのグローバルな編集効果は、微調整されたテクスチャ LDM とキューを直接使用して実現できます。さらにマスクやスケッチを組み合わせることで、タトゥーやヒゲ、あざなどさまざまな効果を生み出すことができます。

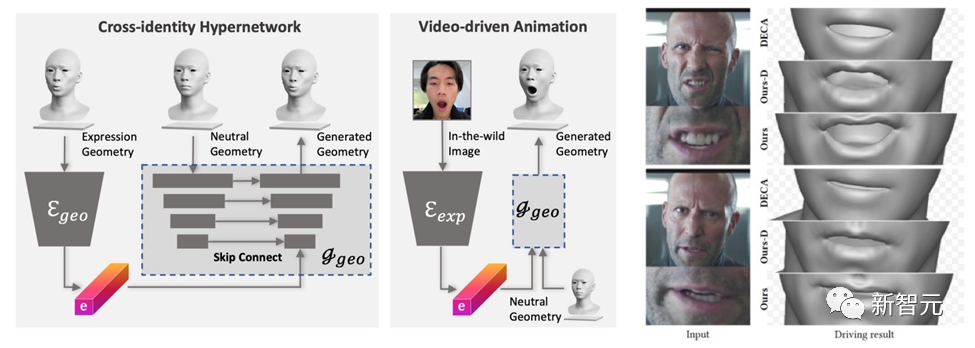
まず、幾何学的ジェネレーターは式の潜在空間を学習するようにトレーニングされ、デコーダーは中立的な幾何学的形状に条件付けされるように拡張されます。次に、表情エンコーダは、RGB 画像から表情特徴を抽出するようにさらにトレーニングされます。したがって、DreamFace は、単眼の RGB 画像を使用して、ニュートラルな幾何学的形状を条件としたパーソナライズされたアニメーションを生成できます。
表現制御に汎用の BlendShape を使用する DECA と比較して、DreamFace のフレームワークは表現の詳細を提供し、パフォーマンスを詳細にキャプチャすることができます。
結論
この文書では、最新の視覚言語モデル、暗黙的拡散モデル、物理的モデルを組み合わせたテキストガイドによるプログレッシブ 3D 生成フレームワークである DreamFace について紹介します。ベースの材料拡散技術。
DreamFace の主な革新には、ジオメトリ生成、物理ベースのマテリアル拡散生成、およびアニメーション機能の生成が含まれます。従来の 3D 生成方法と比較して、DreamFace は精度が高く、実行速度が速く、CG パイプラインの互換性が優れています。
DreamFace のプログレッシブ生成フレームワークは、複雑な 3D 生成タスクを解決するための効果的なソリューションを提供し、同様の研究と技術開発をさらに促進することが期待されています。
さらに、物理ベースのマテリアル拡散生成とアニメーション機能生成により、映画やテレビの制作、ゲーム開発、その他の関連産業における 3D 生成テクノロジーの応用が促進されます。
以上が上海科技大学などがDreamFaceをリリース:テキストだけで「超リアルな3Dデジタルヒューマン」を生成できるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7448
7448
 15
1374
52
76
11
14
6
15
1374
52
76
11
14
6

 上海科技大学などがDreamFaceをリリース:テキストだけで「超リアルな3Dデジタルヒューマン」を生成できる
May 17, 2023 am 08:02 AM
上海科技大学などがDreamFaceをリリース:テキストだけで「超リアルな3Dデジタルヒューマン」を生成できる
May 17, 2023 am 08:02 AM
大規模言語モデル (LLM) や拡散 (Diffusion) などの技術の発展に伴い、ChatGPT や Midjourney などの製品の誕生により AI ブームの新たな波が起こり、生成 AI も大きな関心事となっています。テキストや画像とは異なり、3D 生成はまだ技術探索の段階にあります。 2022 年末に、Google、NVIDIA、Microsoft が相次いで独自の 3D 生成作業を開始しましたが、そのほとんどは高度な神経放射場 (NeRF) の暗黙的表現に基づいており、次のような産業用 3D ソフトウェアのレンダリング パイプラインと互換性がありません。 Unity、UnrealEngine、Maya。従来のソリューションでメッシュで表現される幾何学マップやカラーマップに変換しても精度不足が生じます。
 大きなモデルはデジタル派に人気です。1 つの文を 5 分でカスタマイズでき、ダンス、司会、商品の配達中に保持することができます。
May 08, 2024 pm 08:10 PM
大きなモデルはデジタル派に人気です。1 つの文を 5 分でカスタマイズでき、ダンス、司会、商品の配達中に保持することができます。
May 08, 2024 pm 08:10 PM
わずか 5 分で、そのまま仕事に取り組める 3D デジタル ヒューマンを作成できます。これは、大型モデルがデジタルヒューマンの分野にもたらした最新の衝撃です。このように、需要を一文で説明すると、生成されたデジタル人材が直接ライブ放送室に入り、アンカーとして機能することができます。ガールズグループダンスを踊るのは問題ありません。制作プロセス全体で、思いついたことを言うだけで、大きなモデルが自動的に要件を分解し、即座にデザインを取得してアイデアを修正できます。 △2倍速なら、上司・Aのアイデアが奇抜すぎても気にしなくて済みます。このような Vincent デジタル ヒューマン テクノロジーは、Baidu Intelligent Cloud の最新リリースから生まれました。言うか言わないかはわかりませんが、デジタル担当者がデジタルを使用する敷居を一気に下げる時期が来ています。このようなアーティファクトについて聞いた後、私たちはいつものようにすぐに内部テストの資格を確保しました。詳細をこっそり見てみましょう〜一言で5分で、3Dデジタルマンが直接勤務します。
 なんてことだ、私の周りにはデジタルの同僚がたくさんいる! Xiaobing AI のデジタル従業員が再びアップグレードされ、ゼロサンプルのカスタマイズと即時雇用が実現
Jul 19, 2024 pm 05:52 PM
なんてことだ、私の周りにはデジタルの同僚がたくさんいる! Xiaobing AI のデジタル従業員が再びアップグレードされ、ゼロサンプルのカスタマイズと即時雇用が実現
Jul 19, 2024 pm 05:52 PM
「こんにちは、私はこの会社に入社したばかりです。ビジネスについて質問がある場合は、アドバイスをお願いします!」 なんと、この同僚は全員、大型モデルを駆動する「デジタル担当者」です。現実の人間と何ら変わらない「デジタル同僚」をすばやくカスタマイズするには、画像が 30 秒、音声が 10 秒、そして 10 分しかかかりません。リアルタイムで直接対話でき、通信事業者レベルでの高品質かつ低遅延の音声とビデオの送信が可能です。このように: これは、Xiaoice が発表した最新の「ゼロショット Xiaoice ニューラル レンダリング、Zero-XNR」テクノロジーです。1,000 億を超える大規模なモデル ベースに基づいた新しいテクノロジーです。
 デジタル担当者がアジア競技大会のメイントーチに火を灯す、そしてこの ICCV 論文は Ant の生成 AI ブラック テクノロジーを明らかにします
Sep 29, 2023 pm 11:57 PM
デジタル担当者がアジア競技大会のメイントーチに火を灯す、そしてこの ICCV 論文は Ant の生成 AI ブラック テクノロジーを明らかにします
Sep 29, 2023 pm 11:57 PM
デジタル ヒューマンを開くと、そこには生成 AI が満載されています。 9月23日の夜、杭州アジア競技大会の開会式で、メイントーチの点灯は銭塘江に集まった数億人のオンラインデジタル聖火ランナーの「小さな炎」を示し、デジタルヒューマンのイメージを形成した。 。その後、デジタルヒューマン聖火ランナーと会場の6人目の聖火ランナーが一緒に聖火ステージに上がり、一緒にメイントーチに点火したのですが、開会式の核となるアイデアとして、デジタルとリアルが連動した聖火点灯形式が注目を集めました。 、人々の興味を呼び起こします。書き換えられた内容: 開会式の核となるアイデアとして、デジタル リアリティ インターネットの聖火点火方式が熱い議論を引き起こし、人々の注目を集めた。デジタル ヒューマン点火は前例のない取り組みである。数億人が参加し、多数の高度で複雑なテクノロジー。最も重要な質問の 1 つは、どのようにして
 Unity Greater China プラットフォーム テクニカル ディレクター、Yang Dong 氏: メタバースでのデジタル ヒューマン ジャーニーの開始
Apr 08, 2023 pm 06:11 PM
Unity Greater China プラットフォーム テクニカル ディレクター、Yang Dong 氏: メタバースでのデジタル ヒューマン ジャーニーの開始
Apr 08, 2023 pm 06:11 PM
メタバース コンテンツ構築の基礎として、デジタル ピープルは、実装および持続的に開発できるメタバース サブディビジョンの最も初期に成熟したシナリオです。現在、バーチャル アイドル、電子商取引配信、テレビ ホスティング、バーチャル アンカーなどの商用アプリケーションが認知されています。公共。メタバースの世界で最も核となるコンテンツの 1 つはデジタル ヒューマンに他なりません。デジタル ヒューマンは、メタバースにおける現実世界の人間の「化身」であるだけでなく、私たちにとって重要な手段の 1 つでもあるからです。メタバース内でさまざまなインタラクションを実行します。リアルなデジタル ヒューマン キャラクターの作成とレンダリングは、コンピューター グラフィックスにおいて最も困難な問題の 1 つであることはよく知られています。最近、51CTO が主催する MetaCon メタバース テクノロジー カンファレンスの「ゲームと AI インタラクション」支部会場で、Unity Greater China プラットフォーム テクニカル ディレクターの Yang Dong 氏が一連のデモ デモンストレーションを行いました。
 デジタルヒューマンとは何か、そして未来はどうなるのか?
Oct 16, 2023 pm 02:25 PM
デジタルヒューマンとは何か、そして未来はどうなるのか?
Oct 16, 2023 pm 02:25 PM
今日の技術的に進歩した世界では、本物のようなデジタルヒューマンが大きな注目を集める新興分野となっています。デジタルヒューマンは、コンピュータグラフィックス(CG)技術や人工知能技術をもとに作られた人間のイメージに近いデジタル仮想イメージとして、より便利で効率的かつパーソナライズされたサービスを人々に提供することができます。同時に、デジタル人材の出現は仮想経済の発展を促進し、デジタルコンテンツの革新とデジタル消費の機会を増やすこともできます。 International Data Corporation (IDC) が発表したレポートによると、世界のバーチャル デジタル ヒューマン市場は 2025 年に 270 億米ドルに達し、年平均成長率は 22.5% になると予想されています。デジタル ヒューマンには非常に幅広い応用の可能性と市場の可能性があることがわかります。デジタルパーソンとは何ですか?デジタルの人は幸運です
 DreamFace: 一文で 3D デジタル ヒューマンを生成しますか?
May 16, 2023 pm 09:46 PM
DreamFace: 一文で 3D デジタル ヒューマンを生成しますか?
May 16, 2023 pm 09:46 PM
現在、科学技術の急速な発展に伴い、生成型人工知能やコンピュータグラフィックス分野の研究がますます注目を集めており、映画やテレビの制作、ゲーム開発などの業界は大きな課題とチャンスに直面しています。この記事では、3D 生成分野の研究について紹介します。DreamFace は、Production-Ready3D アセット生成をサポートする初のテキストガイドによるプログレッシブ 3D 生成フレームワークであり、テキスト生成主導の 3D 超現実的なデジタル ピープルを実現できます。この作品は、コンピュータ グラフィックス分野のトップ国際ジャーナルである Transactionson Graphics に受理され、トップの国際コンピュータ グラフィックス会議 SIGGRAPH2023 で発表されます。プロジェクトの Web サイト: https://sites.
 大型モデルによる人間とコンピューターの対話型対話
Apr 11, 2023 pm 07:27 PM
大型モデルによる人間とコンピューターの対話型対話
Apr 11, 2023 pm 07:27 PM
はじめに: 対話テクノロジーはデジタル ヒューマン インタラクションの中核機能の 1 つです。この共有は主に Baidu PLATO に関連する研究開発と応用から始まり、対話システムに対する大規模モデルの影響とデジタル ヒューマンにとってのいくつかの機会について話します。この共有のタイトルは「大規模モデルによる人間とコンピューターの対話対話」です。今日の紹介は以下の点から始まります: 対話システムの概要 Baidu PLATO と関連技術対話 大規模モデルの実装、課題と展望 1. 対話システムの概要 1. 対話システムの概要 日常生活において、私たちはタスク指向のタスクに触れることがよくあります。たとえば、モバイル アシスタントにアラームを設定するように依頼したり、スマート スピーカーに曲を再生するように依頼したりできます。特定の分野におけるこの種の垂直対話のテクノロジーは比較的成熟しており、システム設計は通常、対話の理解、対話の管理、
