

機械学習は本当にインテリジェントな意思決定を生み出すことができるのでしょうか?

3 年を経て、私たちは 2022 年にジュディを完成させました。ジュディはチューリング賞を受賞し、カリフォルニア大学ロサンゼルス校のコンピューター サイエンスの教授であり、全米科学アカデミーの会員であり、「科学の父」として知られています。ベイジアンネットワーク』A. Perlの名著『Causation: Models, Reasoning, and Inference』。
この本の初版は 2000 年に書かれ、因果分析と推論の新しいアイデアと方法を開拓しました。出版されるやいなや広く賞賛され、データ サイエンスを推進しました。 、人工知能、機械学習、因果分析などの分野は学術コミュニティに大きな影響を与えています。
その後、2009 年に第 2 版が改訂されました。当時の因果関係研究の新たな展開に基づいて内容が大幅に変更されました。現在翻訳中の本の英語版の原書は2009年に出版されているので、もう10年以上前になります。
本書の中国語版の出版は、さまざまな分野の中国の学者、学生、実務家が因果モデル、推論、推論に関連する内容を理解し、習得するのに役立ちます。特に統計や機械学習が普及している現代において、「データフィッティング」から「データ理解」への変革をどのように実現するか。 「すべての知識はデータ自体から得られる」という現在支配的な前提から、今後 10 年でまったく新しい機械学習パラダイムに移行するにはどうすればよいでしょうか?それは「第二次人工知能革命」を引き起こすだろうか?
パール氏がチューリング賞を受賞したように、彼の業績は「人工知能分野への根本的な貢献」として評価されました。彼は、確率論的および因果的推論アルゴリズムを提案し、人工知能の世界を完全に変えました。人工知能の初期開発。「ルールとロジックに基づく方向性」。私たちは、このパラダイムが機械学習に新たな技術的方向性と推進力をもたらし、最終的には実用的なアプリケーションで役割を果たすことができると期待しています。
正 Pearl氏が述べたように、「データフィッティングは現在、統計と機械学習の現在の分野を確実に支配しており、今日のほとんどの機械学習研究者の主な焦点となっています。研究パラダイム、特に「データフィッティング」を中核としたこのパラダイムは、コンピュータビジョン、音声認識、自動運転などの応用分野で大きな成功を収めました。しかし、データ サイエンスの分野の多くの研究者は、現在の実践から、機械学習ではインテリジェントな意思決定に必要な種類の理解を生み出すことができないことにも気づいています。これらの問題には、堅牢性、転送可能性、解釈可能性などが含まれます。以下に例を見てみましょう。
#1. 統計は信頼できますか?
近年、セルフメディアの多くの人が自分は統計学者だと思っています。なぜなら、「データ フィッティング」と「すべての知識はデータ自体から得られる」ため、多くの重要な意思決定に統計的根拠が提供されるからです。ただし、この分析を行う場合は注意が必要です。結局のところ、物事は必ずしも一見したとおりであるとは限りません。私たちの生活に深く関わる事件。 10年前、都市中心部の住宅価格は8,000元/平方メートル、合計1,000万平方メートルが販売されましたが、ハイテクゾーンでは4,000元/平方メートル、合計100万平方メートルが販売されました。販売メートル数、全体として、市の平均住宅価格は 7,636 元/平方メートルでした。現在、都市中心部の価格は1万元/平方メートルですが、都市中心部の土地供給が少ないため、200万平方メートルしか売れていません、ハイテクゾーンは6,000元/平方メートルですが、さらに新たに開発された土地があり、2,000万平方メートルが販売されており、全体的に見て、都市の平均住宅価格は現在6,363元/平方メートルです。したがって、地域ごとに見れば、個別に住宅価格は上がっているけれども、全体として見ると、なぜ今住宅価格が下がっているのかという疑問が生じます。
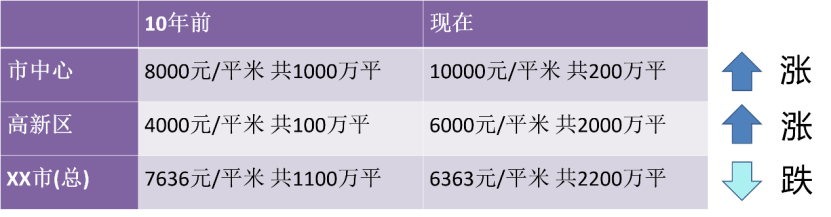
図 1 地域ごとに分けた住宅価格の傾向は、全体的な結論に反しています。
私たちは、この現象はシンプソンのパラドックスと呼ばれています。これらの事例は、十分な観測変数が与えられていない場合に、統計データから完全に間違ったモデルや結論が得られることを明確に示しています。このパンデミックの場合、通常は全国的な統計が取得されます。地域、都市、郡ごとにグループ化すると、まったく異なる結論に達する可能性があります。全国的には、新型コロナウイルス感染症の感染者数の減少が見られますが、一部の地域では感染者数が増加しています(これは次の波の始まりを示している可能性があります)。これは、人口が大きく異なる地域など、大きく異なるグループが存在する場合にも発生する可能性があります。全国的なデータでは、人口密度の低い地域での感染者数の急増は、人口密度の高い地域での感染者数の減少に比べて小さく見えている可能性があります。
「データフィッティング」に基づく同様の統計問題はたくさんあります。次の 2 つの興味深い例を見てみましょう。
ニコラス・ケイジが上映した映画の数と米国での溺死の数に関するデータを毎年収集すると、これら 2 つの変数には高い相関関係があり、データの適合度が非常に高いことがわかります。
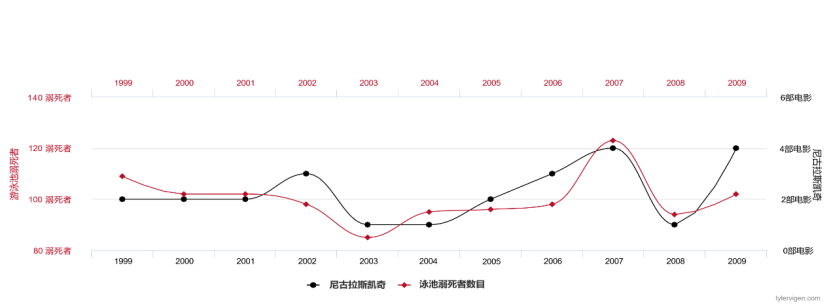
図 2 ニコラス ケイジが上映した映画の数と米国で毎年溺死する人の数
各国の一人当たりの牛乳販売量とノーベル賞受賞者数に関するデータを収集すると、これら 2 つの変数に高い相関があることがわかります。
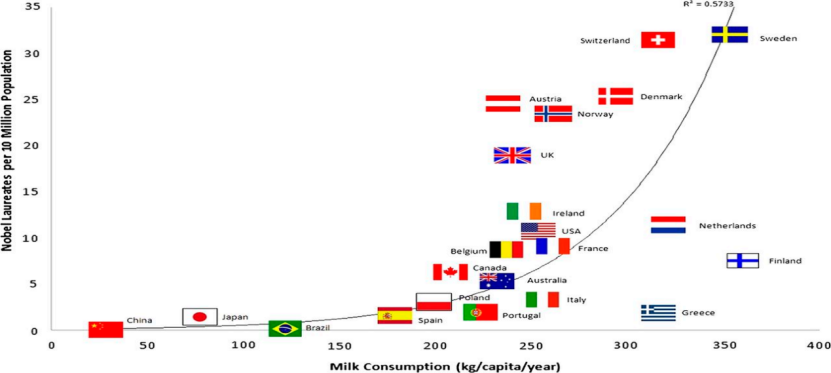
図 3 一人当たりの牛乳消費量とノーベル賞受賞者数
私たちの常識から知的に言えば、これらは偽りの相関関係であり、逆説ですらあります。しかし、数学と確率論の観点から見ると、偽の相関やパラドックスを示すケースは、統計的観点からも計算上の観点からも問題になりません。何らかの因果関係の根拠がある人なら誰でも、いわゆる隠れ変数、つまり観測されていない交絡因子がデータに隠されているためにこのようなことが起こることを知っています。
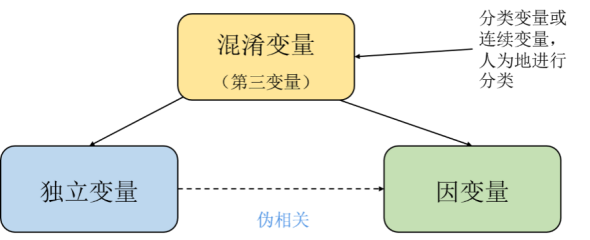
#図 4 独立変数により 2 つの変数間に偽の相関関係が生じる
#Perl は、「因果関係の理論」で解決策のパラダイムを示し、上記の問題を詳細に分析して導き出し、因果関係の分析と推論は依然として統計に基づいていますが、因果関係と統計の本質的な違いを強調しました。学ぶ。パールは、バックドア原理と特定の計算式を含む介入操作 (オペレーター) の基本的な計算モデルを提案しました。これは現在、因果関係を数学的に説明するものとして最も優れています。 「因果関係とそれに関連する概念(ランダム化、交絡、介入など)は統計的な概念ではない。」 これはパールの因果分析思考を貫く基本原則であり、パールはこれを第一原則と呼んでいる[2]。したがって、現在のデータ駆動型機械学習手法、特に統計的手法に大きく依存するアルゴリズムでは、学習されたモデルは半分真か半分偽である可能性が非常に高くなります。誤解を招く、または逆効果な結果。これは、これらのモデルが、データが生成されるメカニズムではなく、観察されたデータの分布に基づいて学習する傾向があるためです。
2. 機械学習において早急に解決すべき 3 つの課題
堅牢性:深層学習手法の普及により、コンピューター 視覚、自然言語処理、および音声認識の研究では、最先端のディープ ニューラル ネットワーク構造が広範囲に利用されています。しかし、現実の世界では、収集したデータの分布が完了することはほとんどなく、現実世界の分布と一致しない可能性があるという長期的な問題が依然として残っています。コンピュータ ビジョン アプリケーションでは、トレーニング セットとテスト セットのデータの分布は、ピクセルの違い、圧縮品質、カメラの変位、回転、角度などの要因の影響を受ける可能性があります。これらの変数は、実際には原因と結果の概念における「介入」問題です。このことから、空間オフセット、ぼかし、明るさまたはコントラストの変化、背景の制御と回転、複数の環境での画像の取得など、分類および認識モデルの一般化機能を具体的にテストするための介入をシミュレートするための単純なアルゴリズムが提案されています。これまでのところ、データ拡張、事前トレーニング、自己教師あり学習などの方法を使用して堅牢性がある程度進歩しましたが、これらの問題を解決する方法については明確なコンセンサスはありません。これらの修正は十分ではない可能性があり、独立した同一分布の仮定を超えて一般化するには、変数間の統計的関連だけでなく、データが生成されたメカニズムを明らかにし、介入によるシミュレーションを可能にする根底にある因果モデルも学習する必要があると主張されています。概念 分布の変更。
伝達性: 幼児の物体理解は、時間の経過とともに一貫して動作する物体を追跡することに基づいています。このようなアプローチにより、幼児は物体に関する知識と直感的な理解により、新しいタスクをすぐに学ぶことができます。再利用できます。同様に、現実世界のタスクを効率的に解決するには、学習した知識とスキルを新しいシナリオで再利用する必要があります。研究により、環境知識を学習する機械学習システムの方が効率的で汎用性が高いことが証明されています。現実世界をモデル化すると、多くのモジュールがさまざまなタスクや環境で同様の動作を示します。したがって、新しい環境やタスクに直面したとき、人間や機械は内部表現のいくつかのモジュールを調整するだけで済む場合があります。因果モデルを学習する場合、ほとんどの知識 (つまり、モジュール) は追加のトレーニングなしで再利用できるため、新しい環境やタスクに適応するために必要なサンプルが少なくなります。
解釈可能性: 解釈可能性は、ブール論理や統計的確率の言語だけを使用して完全に説明することはできない微妙な概念であり、追加の介在概念、さらには反事実の概念。因果関係における操作可能性の定義は、条件付き確率 (「人々が傘を開いているのを見るのは、雨が降っていることを示している」) では、積極的な介入の結果 (「傘をしまっても雨が降るのを防ぐことはできない」) を確実に予測できないという事実に焦点を当てています。因果関係は、観察された分布から大きくかけ離れた状況の予測を提供できる推論の連鎖の不可欠な部分として見なされ、純粋に仮説的なシナリオの結論を提供することさえできます。この意味で、因果関係を発見するということは、観察されたデータの分布やトレーニング タスクに制限されない信頼できる知識を取得することを意味し、解釈可能な学習のための明確な仕様を提供します。
3. 因果学習モデリングの 3 つのレベル
具体的には、統計モデルに基づく機械学習モデルは相関関係のみをモデル化できますが、相関関係は環境の変化に応じて変化する傾向があります。データの分布; 一方、因果モデルは、データ生成の本質を捉え、データ生成メカニズム間の関係を反映する因果関係モデリングに基づいています。このような関係は、より堅牢であり、分布の外で一般化する機能を備えています。たとえば、意思決定理論では、因果関係と統計の区別がより明確になります。意思決定理論には 2 種類の問題があり、1 つは現在の環境を知り、介入を計画し、結果を予測することです。もう1つは、現在の環境と結果を知り、原因を推測するタイプです。前者は結果的問題と呼ばれ、後者はアブダクション問題と呼ばれます[3]。
独立した同一分布条件下での予測能力
統計モデルは相関関係のみに焦点を当てているため、観察された現実世界の表面的な記述にすぎません。サンプルとラベルについては、推定値を使用して、「この特定の写真に犬が写っている確率はどのくらいですか?」「いくつかの症状を考慮すると、心不全の確率はどのくらいですか?」などの質問に答えることができます。このような質問は、生成された i.i.d. データを十分に観察することで解決できます。機械学習アルゴリズムはこれらのことをうまく実行できますが、正確な予測だけでは意思決定には十分ではなく、因果学習は有用な補足となります。前の例と同様に、ニコラス・ケイジが映画に出演する頻度は、米国の溺死死亡率と正の相関関係があり、統計学習モデルをトレーニングして、米国の溺死率を予測することができます。ニコラス・ケイジは映画で主演を務めていますが、明らかにこの両者の間には直接の因果関係はありません。統計モデルは、独立して同一に分布している場合にのみ正確であるため、データ分布を変更する介入を行うと、統計学習モデルにエラーが発生します。
分布シフト/介入下の予測能力
介入問題についてさらに議論しますが、介入(操作)は統計学習における独立した同一分布から抜け出すため、より困難です。 。ニコラス・ケイジの例を続けると、「今年ニコラス・ケイジの映画の本数が増えると、米国の溺死率が増加しますか?」という質問が介入問題になります。明らかに、人間の介入によりデータの分布が変化し、統計学習が存続するための条件が崩れるため、失敗します。一方で、介入が存在する状態で予測モデルを学習できれば、現実世界の設定における分布変化に対してより堅牢なモデルを取得できる可能性があります。実際、ここでのいわゆる介入は新しいものではなく、人々の興味の好みや、モデルのトレーニング セットとテスト セット自体の分布の不一致など、多くのこと自体が時間の経過とともに変化します。以前にも述べたように、ニューラル ネットワークの堅牢性はますます注目を集めており、因果推論と密接に関係する研究テーマとなっています。分布シフトの場合の予測は、テストセット上で高い精度を達成することに限定されるわけではなく、機械学習アルゴリズムを実用化したいのであれば、環境条件が変化するとモデルの予測結果も変化すると考える必要があります。正確な。実際のアプリケーションにおける分布シフトのカテゴリーは多様である可能性があります。モデルが一部のテスト セットでのみ良好な結果を達成するということは、どのような状況でもこのモデルを信頼できるという意味ではありません。これらのテスト セットはこれらのテスト セットにちょうど適合する可能性があります。サンプルの分布。できるだけ多くの状況で予測モデルを信頼できるようにするには、少なくとも統計学習モデルを使用するだけでなく、介入の質問に答える能力を備えたモデルを採用する必要があります。
反事実的な質問に答える能力
反事実的な質問には、なぜ物事が起こったのかを推論し、さまざまなアクションを実行した場合の結果を想像することが含まれます。望ましい結果を達成するためのアクション。反事実的な質問に答えるのは介入よりも難しいですが、AI にとっては重要な課題でもあります。介入の質問が「今から定期的に運動を始めたら、患者の心不全のリスクはどうなるでしょうか?」である場合、対応する反事実の質問は「すでに心不全を患っているこの患者が 1 年前に運動を始めたらどうなりますか?」になります。明らかに、このような反事実的な質問に答えることは、強化学習にとって非常に重要です。私たちの科学研究と同じように、強化学習は自分の決定を振り返り、反事実的な仮説を立て、実践を通じてそれらを検証することができます。
4. 因果学習の応用
最後に、因果学習をさまざまな分野に応用する方法を見てみましょう。 2021年のノーベル経済学賞は、「因果関係の分析に対する方法論的な貢献」により、ジョシュア・D・アングリスト氏とグイド・W・インベンス氏に授与された。彼らは、経験的労働経済学における因果推論の応用を研究しています。ノーベル経済学賞選考委員会は、「自然実験(ランダム化試験または対照試験)は重要な疑問の解決に役立つ」と考えているが、「因果関係に答えるために観察データを使用する」方法はさらに難しい。経済学における重要な問題は因果関係の問題です。たとえば、移民は地元住民の労働市場の見通しにどのような影響を与えるのでしょうか?大学院進学で収入は増えるのか?最低賃金は熟練労働者の雇用の見通しにどのような影響を与えますか?私たちは反事実を解釈する適切な手段を欠いているため、これらの質問に答えるのは困難です。
1970 年代以来、統計学者は 2 つの変数間の因果関係を明らかにするために「反事実」を計算するためのフレームワークを発明してきました。これに基づいて、経済学者は不連続回帰、差異の差分、傾向スコアなどの手法をさらに開発し、さまざまな経済政策問題の因果関係研究に広く適用してきました。 6 世紀の宗教文書から、因果的自然言語処理を含む 2021 年の因果的機械学習に至るまで、機械学習、統計、計量経済学を使用して因果効果をモデル化できます。経済学やその他の社会科学における分析は、主に因果効果、つまり結果変数に対する特性変数の介入効果の推定を中心に展開します。実際、ほとんどの場合、私たちが関心があるのは介入効果と呼ばれるものです。介入効果とは、介入または治療が結果変数に及ぼす因果的な影響を指します。たとえば、経済学において最も分析されている介入効果の 1 つは、企業への補助金が企業収益に与える因果関係です。この目的のために、ルービンは潜在的な結果の枠組みを提案しました。
経済学者やその他の社会科学者は、因果関係を予測するよりも正確に推定する方が得意ですが、機械学習手法の予測上の利点にも関心を持っています。たとえば、正確なサンプル予測機能や、多数の特徴を処理する機能などです。しかし、これまで見てきたように、古典的な機械学習モデルは因果効果を推定するように設計されておらず、機械学習による既製の予測手法を使用すると、因果効果の推定に偏りが生じる可能性があります。次に、因果効果を継続的かつ効果的に推定するために機械学習を活用するには、既存の機械学習技術を改善する必要があります。これが因果的機械学習の誕生につながりました。
現在、因果的機械学習は、推定する因果効果の種類に応じて、大きく2つの研究方向に分けられます。重要な方向性は、平均介入効果を公平かつ一貫して推定するための機械学習方法を改善することです。この研究分野のモデルは、次の質問に答えようとします: マーケティング キャンペーンに対する顧客の平均的な反応は何ですか?価格変更が売上に与える平均的な影響はどれくらいですか?さらに、因果的機械学習研究における別の開発ラインは、介入効果の特異性を明らかにするための機械学習方法の改善、つまり、介入効果が平均よりも大きいまたは小さい個人の部分集団を特定することに焦点を当てています。このタイプのモデルは、次の質問に答えることを目的としています: どの顧客がマーケティング キャンペーンに最も反応しますか?価格変更が売上に与える影響は顧客の年齢によってどのように変化しますか?
これらの実際の例に加えて、因果的機械学習がデータ サイエンティストの興味を惹く深い理由は、モデルの一般化能力にあると感じられます。データ間の因果関係を記述する機械学習モデルは、新しい環境に一般化できますが、これは今日の機械学習における最大の課題の 1 つです。
Perl はこれらの問題をより深いレベルで分析し、機械が因果関係に基づいて推論できなければ、真の人間レベルの人工知能を達成することは決してできないと信じています。なぜなら、因果関係は人間が処理し理解するものだからです。あなたの周りの複雑な世界の重要なメカニズム。パール氏は中国語版『因果関係』の序文で、「今後 10 年間で、このフレームワークは既存の機械学習システムと組み合わされ、『第 2 の因果関係革命』を引き起こす可能性がある。この本が中国語にも対応できることを願っています」と述べています。読者の皆様は、今後の革命に積極的に参加してください。」
以上が機械学習は本当にインテリジェントな意思決定を生み出すことができるのでしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7555
7555
 15
1382
52
83
11
28
96
15
1382
52
83
11
28
96

 Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
このサイトは6月27日、JianyingはByteDanceの子会社であるFaceMeng Technologyによって開発されたビデオ編集ソフトウェアであり、Douyinプラットフォームに依存しており、基本的にプラットフォームのユーザー向けに短いビデオコンテンツを作成すると報告しました。 Windows、MacOS、その他のオペレーティング システム。 Jianyingは会員システムのアップグレードを正式に発表し、インテリジェント翻訳、インテリジェントハイライト、インテリジェントパッケージング、デジタルヒューマン合成などのさまざまなAIブラックテクノロジーを含む新しいSVIPを開始しました。価格的には、クリッピングSVIPの月額料金は79元、年会費は599元(当サイト注:月額49.9元に相当)、継続月額サブスクリプションは月額59元、継続年間サブスクリプションは、年間499元(月額41.6元に相当)です。さらに、カット担当者は、ユーザーエクスペリエンスを向上させるために、オリジナルのVIPに登録している人は、
 Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
検索強化生成およびセマンティック メモリを AI コーディング アシスタントに組み込むことで、開発者の生産性、効率、精度を向上させます。 JanakiramMSV 著者の EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG から翻訳。基本的な AI プログラミング アシスタントは当然役に立ちますが、ソフトウェア言語とソフトウェア作成の最も一般的なパターンに関する一般的な理解に依存しているため、最も適切で正しいコードの提案を提供できないことがよくあります。これらのコーディング アシスタントによって生成されたコードは、彼らが解決する責任を負っている問題の解決には適していますが、多くの場合、個々のチームのコーディング標準、規約、スタイルには準拠していません。これにより、コードがアプリケーションに受け入れられるように修正または調整する必要がある提案が得られることがよくあります。
 微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
大規模言語モデル (LLM) は巨大なテキスト データベースでトレーニングされ、そこで大量の現実世界の知識を取得します。この知識はパラメータに組み込まれており、必要なときに使用できます。これらのモデルの知識は、トレーニングの終了時に「具体化」されます。事前トレーニングの終了時に、モデルは実際に学習を停止します。モデルを調整または微調整して、この知識を活用し、ユーザーの質問により自然に応答する方法を学びます。ただし、モデルの知識だけでは不十分な場合があり、モデルは RAG を通じて外部コンテンツにアクセスできますが、微調整を通じてモデルを新しいドメインに適応させることが有益であると考えられます。この微調整は、ヒューマン アノテーターまたは他の LLM 作成物からの入力を使用して実行され、モデルは追加の実世界の知識に遭遇し、それを統合します。
 GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
AIGC について詳しくは、51CTOAI.x コミュニティ https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou を参照してください。これらの質問は、インターネット上のどこでも見られる従来の質問バンクとは異なります。既成概念にとらわれずに考える必要があります。大規模言語モデル (LLM) は、データ サイエンス、生成人工知能 (GenAI)、および人工知能の分野でますます重要になっています。これらの複雑なアルゴリズムは人間のスキルを向上させ、多くの業界で効率とイノベーションを推進し、企業が競争力を維持するための鍵となります。 LLM は、自然言語処理、テキスト生成、音声認識、推奨システムなどの分野で幅広い用途に使用できます。 LLM は大量のデータから学習することでテキストを生成できます。
 あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
機械学習は人工知能の重要な分野であり、明示的にプログラムしなくてもコンピューターにデータから学習して能力を向上させる機能を提供します。機械学習は、画像認識や自然言語処理から、レコメンデーションシステムや不正行為検出に至るまで、さまざまな分野で幅広く応用されており、私たちの生活様式を変えつつあります。機械学習の分野にはさまざまな手法や理論があり、その中で最も影響力のある 5 つの手法は「機械学習の 5 つの流派」と呼ばれています。 5 つの主要な学派は、象徴学派、コネクショニスト学派、進化学派、ベイジアン学派、およびアナロジー学派です。 1. 象徴主義は、象徴主義とも呼ばれ、論理的推論と知識の表現のためのシンボルの使用を強調します。この学派は、学習は既存の既存の要素を介した逆演繹のプロセスであると信じています。
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
 SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
編集者 | KX 医薬品の研究開発の分野では、タンパク質とリガンドの結合親和性を正確かつ効果的に予測することが、医薬品のスクリーニングと最適化にとって重要です。しかし、現在の研究では、タンパク質とリガンドの相互作用における分子表面情報の重要な役割が考慮されていません。これに基づいて、アモイ大学の研究者らは、初めてタンパク質の表面、3D 構造、配列に関する情報を組み合わせ、クロスアテンション メカニズムを使用して異なるモダリティの特徴を比較する、新しいマルチモーダル特徴抽出 (MFE) フレームワークを提案しました。アライメント。実験結果は、この方法がタンパク質-リガンド結合親和性の予測において最先端の性能を達成することを実証しています。さらに、アブレーション研究は、この枠組み内でのタンパク質表面情報と多峰性特徴の位置合わせの有効性と必要性を実証しています。 「S」で始まる関連研究
 SKハイニックスは8月6日に12層HBM3E、321層NANDなどのAI関連新製品を展示する。
Aug 01, 2024 pm 09:40 PM
SKハイニックスは8月6日に12層HBM3E、321層NANDなどのAI関連新製品を展示する。
Aug 01, 2024 pm 09:40 PM
8月1日の本サイトのニュースによると、SKハイニックスは本日(8月1日)ブログ投稿を発表し、8月6日から8日まで米国カリフォルニア州サンタクララで開催されるグローバル半導体メモリサミットFMS2024に参加すると発表し、多くの新世代の製品。フューチャー メモリおよびストレージ サミット (FutureMemoryandStorage) の紹介。以前は主に NAND サプライヤー向けのフラッシュ メモリ サミット (FlashMemorySummit) でしたが、人工知能技術への注目の高まりを背景に、今年はフューチャー メモリおよびストレージ サミット (FutureMemoryandStorage) に名前が変更されました。 DRAM およびストレージ ベンダー、さらに多くのプレーヤーを招待します。昨年発売された新製品SKハイニックス
