

DAMO アカデミーの mPLUG-Owl がデビュー: GPT-4 マルチモーダル機能に追いつくモジュール式マルチモーダル大型モデル

純粋なテキストのラージ モデルが優勢であり、マルチモーダルなラージ モデルの研究がマルチモーダル分野で出現し始めています。表面上最も強力な GPT-4 は、画像を読み取るマルチモーダル機能を備えていますが、まだ実現されていません。経験のために一般に公開されているため、胡研究コミュニティはこの方向で研究とオープンソースを開始しました。 MiniGPT-4 と LLaVA の出現直後、Alibaba DAMO Academy は、モジュール実装に基づく大規模なマルチモーダル モデルである mPLUG-Owl を立ち上げました。
mPLUG-Owl は、Alibaba Damo Academy の mPLUG シリーズの最新作であり、mPLUG シリーズのモジュール型トレーニングのアイデアを継承し、LLM を大規模なマルチモーダル モデルにアップグレードしています。 mPLUG シリーズの研究では、これまでの E2E-VLP、mPLUG、mPLUG-2 がそれぞれ ACL2021、EMNLP2022、ICML2023 に承認され、その中でも mPLUG の研究は超人的な結果で VQA リストのトップに輝きました。
今日紹介したいのは mPLUG-Owl です。この研究は、多数の事例を通じて優れたマルチモーダル機能を実証するだけでなく、視覚関連の指示を理解するための包括的なテスト セットを提案しますOwlEval は、LLaVA、MiniGPT-4、BLIP-2、システムベースの MM-REACT など、手動評価を通じて既存のモデルを比較しました。実験結果は、mPLUG-Owl が、特にマルチモードで優れたマルチモーダル機能を発揮することを示しています。 modal 動的な指示の理解力、複数ターンの対話能力、知識推論能力などの面で優れたパフォーマンス

##ペーパーリンク: https://arxiv.org/abs/2304.14178
コードリンク: https://github. com/X-PLUG /mPLUG-Owl
ModelScope エクスペリエンス アドレス:
https ://modelscope.cn/studios/damo/mPLUG-Owl/summary
HuggingFace 体験アドレス:
https://huggingface.co/spaces/MAGAer13/mPLUG-Owl
マルチモーダル機能のデモンストレーションmPLUG を組み合わせます-Owl と既存の作品を比較して mPLUG-Owl のマルチモーダル効果を実感してください この作品で評価されたテストサンプルは基本的に既存の作品からのものであり、チェリーピックの問題を回避していることは言及する価値があります。
以下の図 6 は、mPLUG-Owl の強力なマルチラウンド対話機能を示しています。
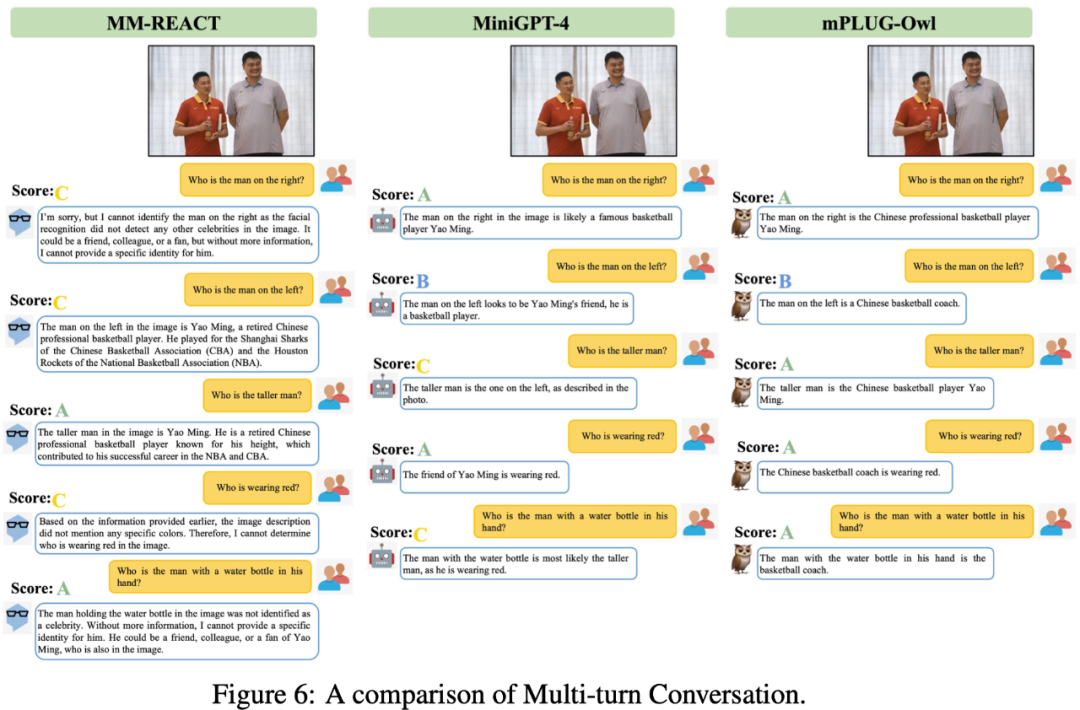

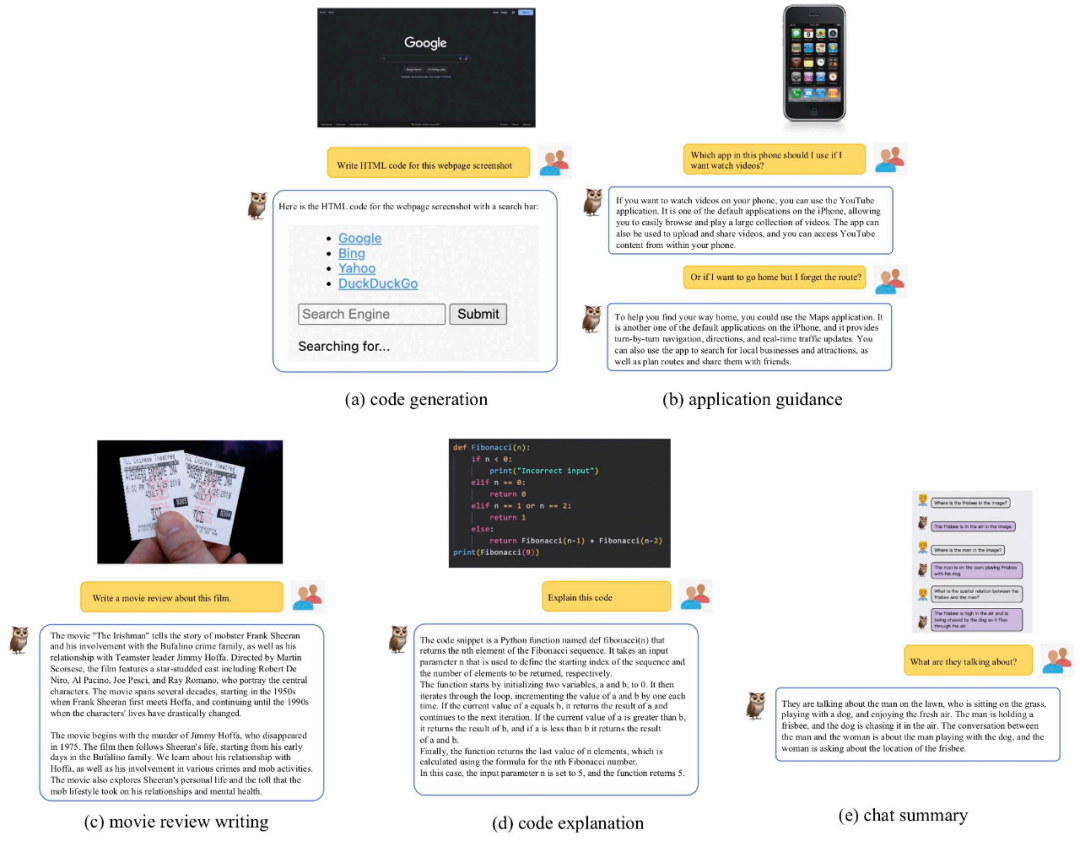
 この研究では、評価と比較に加えて、研究チームは、mPLUG-Owl が最初はある程度の関心を示したことも観察しました。複数画像の関連付け、複数言語、テキスト認識、文書理解などの予期しない機能。
この研究では、評価と比較に加えて、研究チームは、mPLUG-Owl が最初はある程度の関心を示したことも観察しました。複数画像の関連付け、複数言語、テキスト認識、文書理解などの予期しない機能。
図 10 に示すように、マルチグラフ相関データはトレーニング フェーズ中にトレーニングされませんでしたが、mPLUG-Owl は特定のマルチグラフ相関機能を実証しました。
図 11 に示すように、mPLUG-Owl はトレーニング段階では英語データのみを使用しますが、興味深い多言語が開発されたことが示されています。能力。これは、mPLUG-Owl の言語モデルが LLaMA を使用しているため、この現象が発生している可能性があります。 

mPLUG-Owl は注釈付き文書データでトレーニングされていませんが、それでも一定のテキスト認識と文書理解を実証しました。機能、テスト結果は示されています。図 12 にあります。
この研究で提案する mPLUG-Owl の全体的なアーキテクチャを図に示します。 2 表示します。
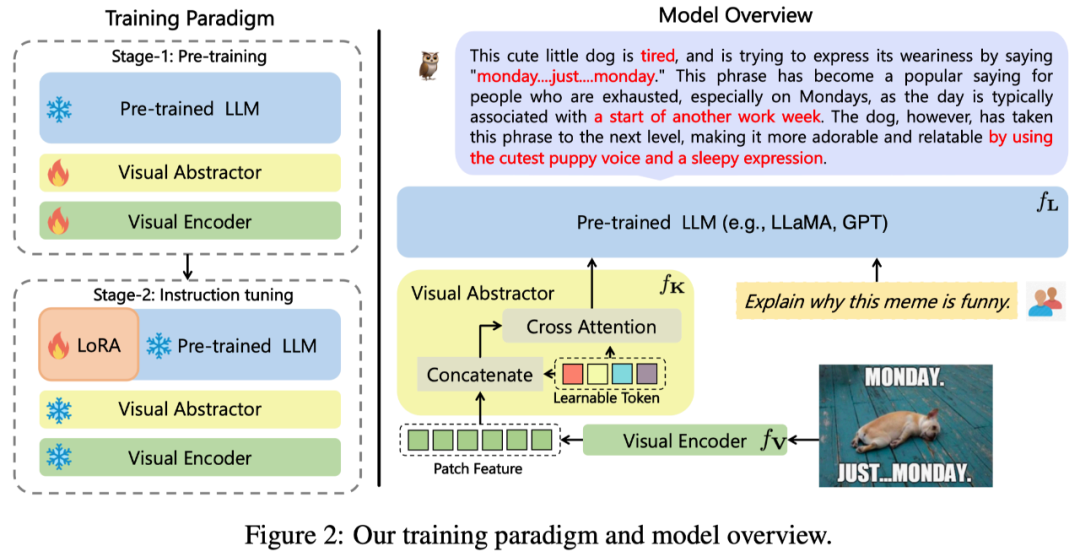
モデル構造: Visual Basic モジュールで構成されます
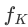
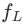
#モデル トレーニング: 2 段階のトレーニング方法を採用
第一段階: 主な目的また、最初に視覚的モダリティと言語的モダリティの対立を学ぶことも重要です。以前の研究とは異なり、mPLUG-Owl は、基本的な視覚モジュールを凍結すると、視覚的な知識とテキストの知識を関連付けるためのモデルの能力が制限されることを提案しています。したがって、mPLUG-Owl は、最初の段階で LLM のパラメータのみをフリーズし、LAION-400M、COYO-700M、CC、および MSCOCO を使用してビジュアルベーシックモジュールとビジュアルサマリーモジュールをトレーニングします。
第 2 段階: mPLUG と mPLUG-2 の異なるモダリティの混合トレーニングが相互に有益であるという発見を続け、Owl は指導の第 2 段階でも純粋なトレーニングを使用します。チューニング トレーニング テキスト コマンド データ (Alpaca から 52k、Vicuna から 90k、Baize から 50k) およびマルチモーダル コマンド データ (LLaVA から 150k)。詳細なアブレーション実験を通じて、著者は、指示の理解などの面で純粋なテキストによる指示の微調整の導入によってもたらされる利点を検証しました。第 2 段階では、ビジュアルベーシックモジュール、ビジュアルサマリーモジュール、およびオリジナルの LLM のパラメータが凍結され、LoRA を参照して、命令の微調整のために少数のパラメータを持つアダプタ構造のみが LLM に導入されます。
実験結果
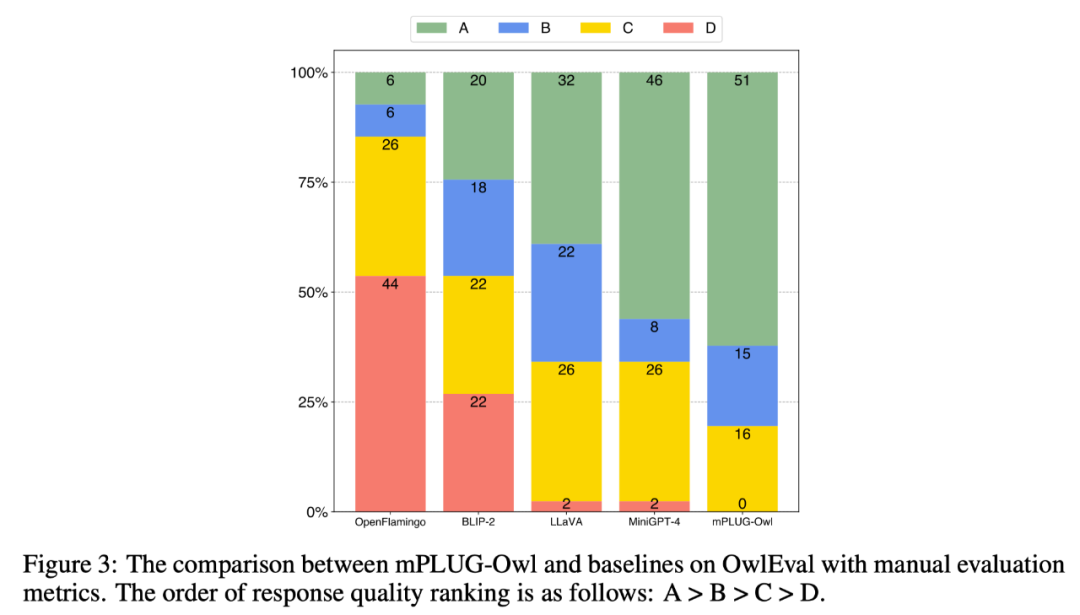
SOTA の比較SOTA のマルチモーダル機能を比較するために、この作業では、マルチモーダル命令評価セット OwlEval を構築します。現在、適切な自動化された指標がないため、モデルの応答を手動で評価するには自己啓発を参照してください。スコア付けルールは次のとおりです: A="正確で満足"; B="いくつかの不完全性はあるが許容範囲"; C =指示はありましたが、応答に明らかな誤りがありました"; D="完全に無関係または不正確な応答"。
比較結果は以下の図 3 に示されており、視覚関連のコマンド応答タスクにおいて Owl が既存の OpenFlamingo、BLIP-2、LLaVA、および MiniGPT-4 よりも優れていることが実験により証明されています。
マルチモーダル コマンド応答タスクには、コマンドの理解、視覚的な理解、画像上のテキストの理解、推論など、さまざまな能力が必要です。モデルのさまざまな機能のレベルをきめ細かく調査するために、この記事ではマルチモーダル シナリオにおける 6 つの主要な機能をさらに定義し、各 OwlEval テスト命令に関連する機能要件とそれに反映されたモデルの応答を手動で注釈付けします。 . どのような能力が身についたのか。 結果は以下の表 6 に示されています。実験のこの部分では、著者はトレーニング戦略とマルチモーダル指導の有効性を検証するためにオウル アブレーション実験を行っただけではありません。データの調整だけでなく、前の実験で最もパフォーマンスの良かったベースラインである MiniGPT4 も比較したところ、その結果は、機能のあらゆる側面において Owl が MiniGPT4 よりも優れていることを示しました。 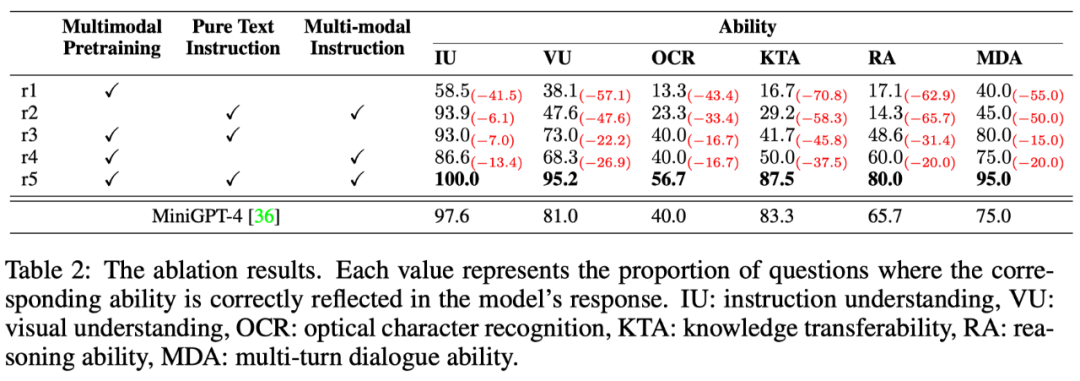
以上がDAMO アカデミーの mPLUG-Owl がデビュー: GPT-4 マルチモーダル機能に追いつくモジュール式マルチモーダル大型モデルの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7552
7552
 15
1382
52
83
11
22
95
15
1382
52
83
11
22
95

 Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centos Shutdownコマンドはシャットダウンし、構文はシャットダウン[オプション]時間[情報]です。オプションは次のとおりです。-hシステムをすぐに停止します。 -pシャットダウン後に電源をオフにします。 -r再起動; -t待機時間。時間は、即時(現在)、数分(分)、または特定の時間(HH:mm)として指定できます。追加の情報をシステムメッセージに表示できます。
 Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosシステムの下でのGitlabのバックアップと回復ポリシーデータセキュリティと回復可能性を確保するために、Gitlab on Centosはさまざまなバックアップ方法を提供します。この記事では、いくつかの一般的なバックアップ方法、構成パラメーター、リカバリプロセスを詳細に紹介し、完全なGitLabバックアップと回復戦略を確立するのに役立ちます。 1.手動バックアップGitlab-RakeGitlabを使用:バックアップ:コマンドを作成して、マニュアルバックアップを実行します。このコマンドは、gitlabリポジトリ、データベース、ユーザー、ユーザーグループ、キー、アクセスなどのキー情報をバックアップします。デフォルトのバックアップファイルは、/var/opt/gitlab/backupsディレクトリに保存されます。 /etc /gitlabを変更できます
 CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CENTOSシステムでHDFS構成をチェックするための完全なガイドこの記事では、CENTOSシステム上のHDFSの構成と実行ステータスを効果的に確認する方法をガイドします。次の手順は、HDFSのセットアップと操作を完全に理解するのに役立ちます。 Hadoop環境変数を確認します。最初に、Hadoop環境変数が正しく設定されていることを確認してください。端末では、次のコマンドを実行して、Hadoopが正しくインストールおよび構成されていることを確認します。HDFS構成をチェックするHDFSファイル:HDFSのコア構成ファイルは/etc/hadoop/conf/ディレクトリにあります。使用
 CentosでのZookeeperのパフォーマンスを調整する方法は何ですか
Apr 14, 2025 pm 03:18 PM
CentosでのZookeeperのパフォーマンスを調整する方法は何ですか
Apr 14, 2025 pm 03:18 PM
CENTOSでのZookeeperパフォーマンスチューニングは、ハードウェア構成、オペレーティングシステムの最適化、構成パラメーターの調整、監視、メンテナンスなど、複数の側面から開始できます。特定のチューニング方法を次に示します。SSDはハードウェア構成に推奨されます。ZookeeperのデータはDISKに書き込まれます。十分なメモリ:頻繁なディスクの読み取りと書き込みを避けるために、Zookeeperに十分なメモリリソースを割り当てます。マルチコアCPU:マルチコアCPUを使用して、Zookeeperが並行して処理できるようにします。
 CentosでPytorchモデルを訓練する方法
Apr 14, 2025 pm 03:03 PM
CentosでPytorchモデルを訓練する方法
Apr 14, 2025 pm 03:03 PM
CentOSシステムでのPytorchモデルの効率的なトレーニングには手順が必要であり、この記事では詳細なガイドが提供されます。 1。環境の準備:Pythonおよび依存関係のインストール:Centosシステムは通常Pythonをプリインストールしますが、バージョンは古い場合があります。 YumまたはDNFを使用してPython 3をインストールし、PIP:sudoyumupdatepython3(またはsudodnfupdatepython3)、pip3install-upgradepipをアップグレードすることをお勧めします。 cuda and cudnn(GPU加速):nvidiagpuを使用する場合は、cudatoolをインストールする必要があります
 CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
Pytorch GPUアクセラレーションを有効にすることで、CentOSシステムでは、PytorchのCUDA、CUDNN、およびGPUバージョンのインストールが必要です。次の手順では、プロセスをガイドします。CUDAおよびCUDNNのインストールでは、CUDAバージョンの互換性が決定されます。NVIDIA-SMIコマンドを使用して、NVIDIAグラフィックスカードでサポートされているCUDAバージョンを表示します。たとえば、MX450グラフィックカードはCUDA11.1以上をサポートする場合があります。 cudatoolkitのダウンロードとインストール:nvidiacudatoolkitの公式Webサイトにアクセスし、グラフィックカードでサポートされている最高のCUDAバージョンに従って、対応するバージョンをダウンロードしてインストールします。 cudnnライブラリをインストールする:
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
DockerはLinuxカーネル機能を使用して、効率的で孤立したアプリケーションランニング環境を提供します。その作業原則は次のとおりです。1。ミラーは、アプリケーションを実行するために必要なすべてを含む読み取り専用テンプレートとして使用されます。 2。ユニオンファイルシステム(UnionFS)は、違いを保存するだけで、スペースを節約し、高速化する複数のファイルシステムをスタックします。 3.デーモンはミラーとコンテナを管理し、クライアントはそれらをインタラクションに使用します。 4。名前空間とcgroupsは、コンテナの分離とリソースの制限を実装します。 5.複数のネットワークモードは、コンテナの相互接続をサポートします。これらのコア概念を理解することによってのみ、Dockerをよりよく利用できます。
 Centosの下でPytorchバージョンを選択する方法
Apr 14, 2025 pm 02:51 PM
Centosの下でPytorchバージョンを選択する方法
Apr 14, 2025 pm 02:51 PM
CentOSでPytorchバージョンを選択する場合、次の重要な要素を考慮する必要があります。1。CUDAバージョンの互換性GPUサポート:NVIDIA GPUを使用してGPU加速度を活用したい場合は、対応するCUDAバージョンをサポートするPytorchを選択する必要があります。 NVIDIA-SMIコマンドを実行することでサポートされているCUDAバージョンを表示できます。 CPUバージョン:GPUをお持ちでない場合、またはGPUを使用したくない場合は、PytorchのCPUバージョンを選択できます。 2。PythonバージョンPytorch
