

深層学習アーキテクチャの比較分析

ディープ ラーニングの概念は、人工ニューラル ネットワークの研究に由来しており、複数の隠れ層を含む多層パーセプトロンがディープ ラーニング構造です。ディープラーニングは、低レベルの特徴を組み合わせて、データのカテゴリや特性を表すより抽象的な高レベルの表現を形成します。データの分散された特徴表現を検出できます。ディープラーニングは機械学習の一種であり、機械学習は人工知能を実現する唯一の方法です。
それでは、さまざまな深層学習システム アーキテクチャの違いは何でしょうか?
1. 完全接続ネットワーク (FCN)
完全接続ネットワーク (FCN) は、完全に接続された一連の層で構成され、各層の各ニューロンは別の層に接続されています。その主な利点は、「構造に依存しない」ことです。つまり、入力に関する特別な仮定が必要ありません。この構造に依存しないため、完全に接続されたネットワークは非常に広く適用可能になりますが、そのようなネットワークは、問題空間の構造に特化して調整された特殊なネットワークよりもパフォーマンスが低下する傾向があります。
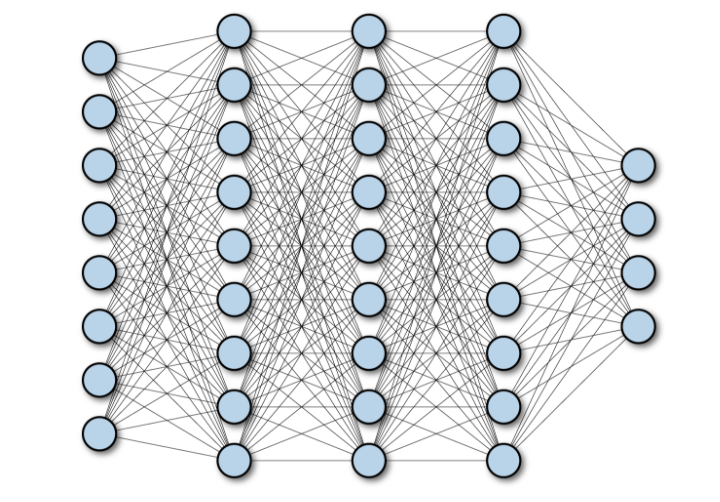
次の図は、多層深度完全接続ネットワークを示しています:
2. 畳み込みニューラル ネットワーク (CNN)
畳み込みニューラル ネットワーク (CNN) は、主に画像処理アプリケーションで使用される多層ニューラル ネットワーク アーキテクチャです。 CNN アーキテクチャは、入力に画像などの空間次元 (およびオプションで深度次元) があることを明示的に想定しており、これにより特定のプロパティをモデル アーキテクチャにエンコードできます。 Yann LeCun は、もともと手書き文字を認識するために使用されていたアーキテクチャである最初の CNN を作成しました。
2.1 CNN のアーキテクチャ機能
CNN を使用したコンピューター ビジョン モデルの技術的な詳細を説明します:
- モデルの入力: CNN モデルの入力通常は画像またはテキストです。 CNN はテキストにも使用できますが、通常はあまり使用されません。
画像は、ここではピクセルのグリッドとして表されます。これは正の整数のグリッドであり、各数値に色が割り当てられています。
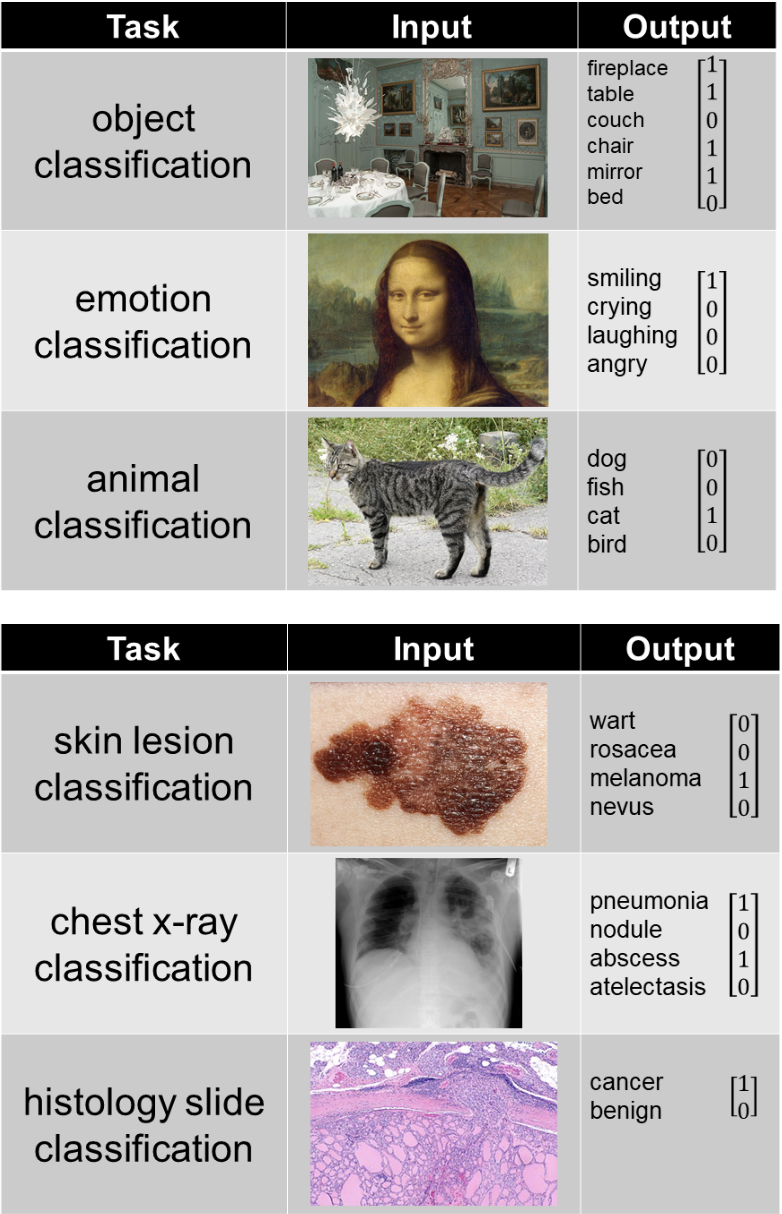
- # モデルの出力: モデルの出力は、予測しようとしている内容によって異なります。次の例は、いくつかの一般的なタスクを示しています。
-
 #単純な畳み込みニューラル ネットワークは一連の層で構成され、各層は微分可能関数を通じてアクティベーション ボリュームを別の表現に変換します。畳み込みニューラル ネットワークのアーキテクチャでは、主に畳み込み層、プーリング層、全結合層の 3 種類の層が使用されます。以下の画像は、畳み込みニューラル ネットワーク層のさまざまな部分を示しています。
#単純な畳み込みニューラル ネットワークは一連の層で構成され、各層は微分可能関数を通じてアクティベーション ボリュームを別の表現に変換します。畳み込みニューラル ネットワークのアーキテクチャでは、主に畳み込み層、プーリング層、全結合層の 3 種類の層が使用されます。以下の画像は、畳み込みニューラル ネットワーク層のさまざまな部分を示しています。
 #単純な畳み込みニューラル ネットワークは一連の層で構成され、各層は微分可能関数を通じてアクティベーション ボリュームを別の表現に変換します。畳み込みニューラル ネットワークのアーキテクチャでは、主に畳み込み層、プーリング層、全結合層の 3 種類の層が使用されます。以下の画像は、畳み込みニューラル ネットワーク層のさまざまな部分を示しています。
#単純な畳み込みニューラル ネットワークは一連の層で構成され、各層は微分可能関数を通じてアクティベーション ボリュームを別の表現に変換します。畳み込みニューラル ネットワークのアーキテクチャでは、主に畳み込み層、プーリング層、全結合層の 3 種類の層が使用されます。以下の画像は、畳み込みニューラル ネットワーク層のさまざまな部分を示しています。 畳み込み: 畳み込みフィルターは、加算と乗算の演算を使用して画像をスキャンします。 CNN は、畳み込みフィルターの値を学習して、目的の出力を予測しようとします。
非線形性: これは畳み込みフィルターに適用される方程式で、CNN が入力画像と出力画像の間の複雑な関係を学習できるようになります。
- プーリング: 「最大プーリング」とも呼ばれ、一連の数値の中から最大の数値のみを選択します。これにより、式のサイズが小さくなり、CNN が実行する必要がある計算の量が減り、効率が向上します。
- これら 3 つの操作を組み合わせると、完全な畳み込みネットワークが形成されます。
- 2.2 CNN の使用例
畳み込み層では、入力は形状の画像 (Hin、Win、Cin) であり、重みは指定されたピクセルの近傍サイズを K×K とみなします。出力は、特定のピクセルとその近傍のピクセルの加重合計です。入力チャネルと出力チャネルのペア (Cin、Cout) ごとに個別のカーネルがありますが、カーネルの重みは位置に依存しない形状テンソル (K、K、Cin、Cout) です。実際、このレイヤーは任意の解像度の画像を受け入れることができますが、完全に接続されたレイヤーは固定解像度のみを使用できます。最後に、層パラメータは (K, K, Cin, Cout) です。カーネル サイズ K が入力解像度よりもはるかに小さい場合、変数の数は大幅に減少します。
AlexNet が ImageNet コンペティションで優勝して以来、優勝したすべてのニューラル ネットワークが CNN コンポーネントを使用しているという事実は、CNN が画像データに対してより効果的であることを証明しています。 CNN は画像データを処理できる一方で、FC レイヤーのみを使用して画像データを処理することは現実的ではないため、意味のある比較が見つからない可能性が非常に高くなります。なぜ?
FC 層内の 1,000 個のニューロンを含む重みの数は、画像では約 1 億 5,000 万個になります。これは、レイヤーのウェイトの数にすぎません。最新の CNN アーキテクチャには、合計数十万のパラメーターを備えた 50 ~ 100 のレイヤーがあります (たとえば、ResNet50 には 2,300 万のパラメーターがあり、Inception V3 には 2,100 万のパラメーターがあります)。
数学的な観点から、入力画像が 500×500×3 の場合、CNN と FCN (100 個の隠れユニットあり) の重みの数を比較します:
- FC層 Wx = 100×(500×500×3)=100×750000=75M
- CNN 層 =
<code>((shape of width of the filter * shape of height of the filter * number of filters in the previous layer+1)*number of filters)( +1 是为了偏置) = (Fw×Fh×D+1)×F=(5×5×3+1)∗2=152</code>
翻訳不変性
不変性はオブジェクトを指します位置が変わっても正しく識別できます。これは、オブジェクトのアイデンティティ (またはカテゴリ) を維持するため、通常は肯定的な機能です。ここでの「平行移動」は幾何学において特別な意味を持ちます。下の画像は、異なる場所にある同じオブジェクトを示しています。変換の不変性により、CNN はそれらが両方とも猫であることを正しく識別できます。
3. リカレント ニューラル ネットワーク (RNN)
RNN は、他の深層学習アーキテクチャが構築される基本的なネットワーク アーキテクチャの 1 つです。主な違いは、通常のフィードフォワード ネットワークとは異なり、RNN は前の層または同じ層にフィードバックする接続を持つことができることです。ある意味、RNN は以前の計算の「メモリ」を持っており、この情報を現在の処理に使用します。
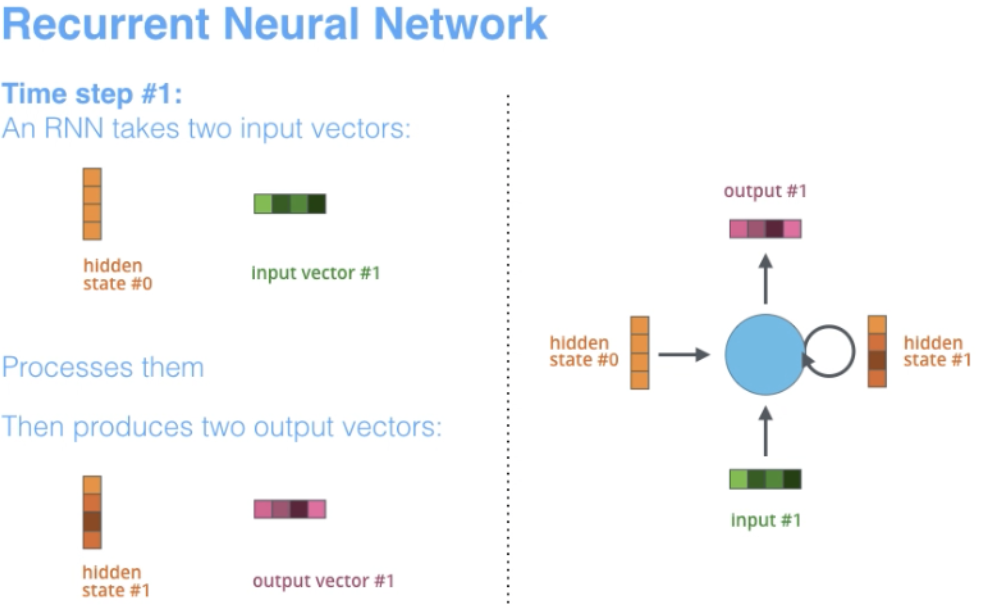
3.1 RNN のアーキテクチャ上の特徴
「リカレント」という用語は、各シーケンス インスタンスで同じタスクを実行するネットワークに適用されます。したがって、出力は以前の計算と結果に依存します。
RNN は、言語モデリングなどの多くの NLP タスクに当然適しています。これらは「犬」と「ホットドッグ」の意味の違いを捉えることができるため、RNN は言語におけるこの種のコンテキスト依存性のモデリングや同様のシーケンス モデリング タスク向けにカスタマイズされており、これらの領域ではむしろ RNN を使用する必要があります。 CNNの主な理由より。 RNN のもう 1 つの利点は、入力サイズによってモデル サイズが増加しないため、任意の長さの入力を処理できることです。
さらに、CNN とは異なり、RNN には柔軟な計算ステップがあり、より優れたモデリング機能が提供され、履歴情報が考慮され、その重みが時間共有されるため、無制限のコンテキストをキャプチャする可能性が生まれます。ただし、リカレント ニューラル ネットワークには勾配消失の問題があります。勾配が非常に小さくなるため、バックプロパゲーションの更新重みが非常に小さくなります。各ラベルに必要な逐次処理と、勾配の消失/爆発の存在により、RNN トレーニングは遅くなり、場合によっては収束が困難になります。
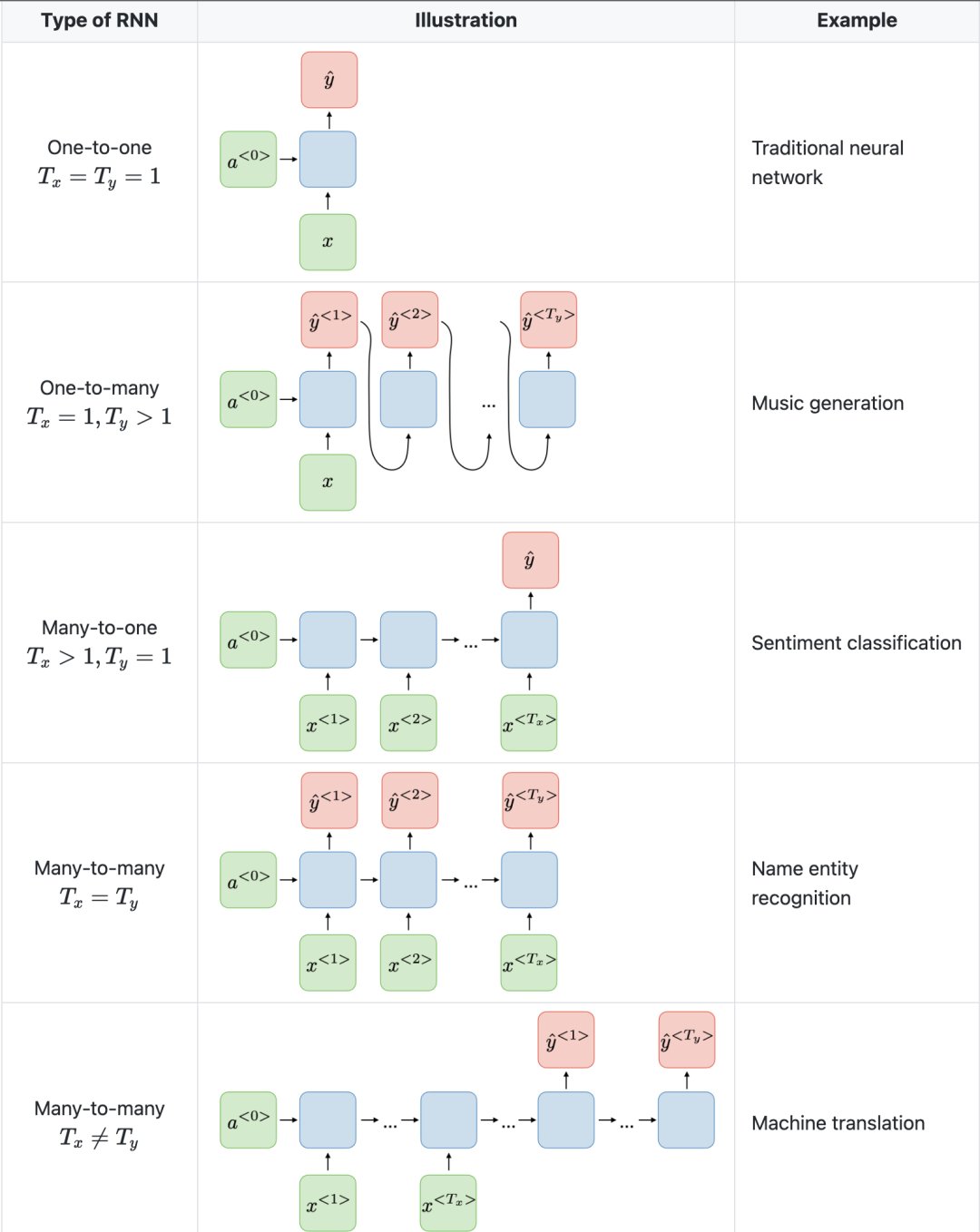
スタンフォード大学からの以下の図は、RNN アーキテクチャの例です。
もう 1 つ注意すべき点は、CNN と RNN のアーキテクチャが異なることです。 CNN はフィルターとプーリング層を使用するフィードフォワード ニューラル ネットワークですが、RNN は自己回帰を通じて結果をネットワークにフィードバックします。
3.2 RNN の一般的な使用例
RNN は、時系列データを分析するために特別に設計されたニューラル ネットワークです。このうち時系列データとは、テキストや動画など、時系列に並べられたデータのことを指します。 RNN は、テキスト翻訳、自然言語処理、感情分析、音声分析に幅広く応用できます。たとえば、音声録音を分析して話者の発話を識別し、テキストに変換するために使用できます。さらに、RNN は、電子メールやソーシャル メディア投稿用のテキストの作成などのテキスト生成にも使用できます。
3.3 RNN と CNN の比較利点
CNN では、入力サイズと出力サイズが固定されています。これは、CNN が固定サイズの画像を取得し、それを予測の信頼性とともに適切なレベルに出力することを意味します。ただし、RNN では、入力サイズと出力サイズが異なる場合があります。この機能は、テキストの生成など、可変サイズの入出力が必要なアプリケーションに役立ちます。
ゲート型リカレント ユニット (GRU) と長期短期記憶ユニット (LSTM) はどちらも、リカレント ニューラル ネットワーク (RNN) が遭遇する勾配消失問題の解決策を提供します。
4. ロング ショート メモリ ニューラル ネットワーク (LSTM)
ロング ショート メモリ ニューラル ネットワーク (LSTM) は、特殊なタイプの RNN です。これにより、RNN は長期的な依存関係を学習することで、多数のタイムスタンプにわたって情報を保持しやすくなります。以下の図は、LSTM アーキテクチャを視覚的に表現したものです。
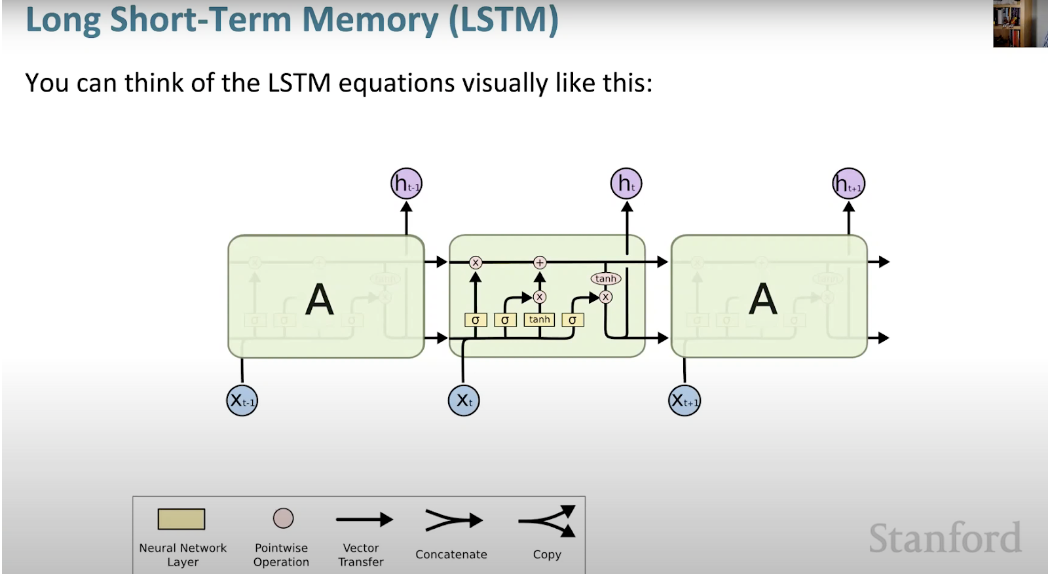
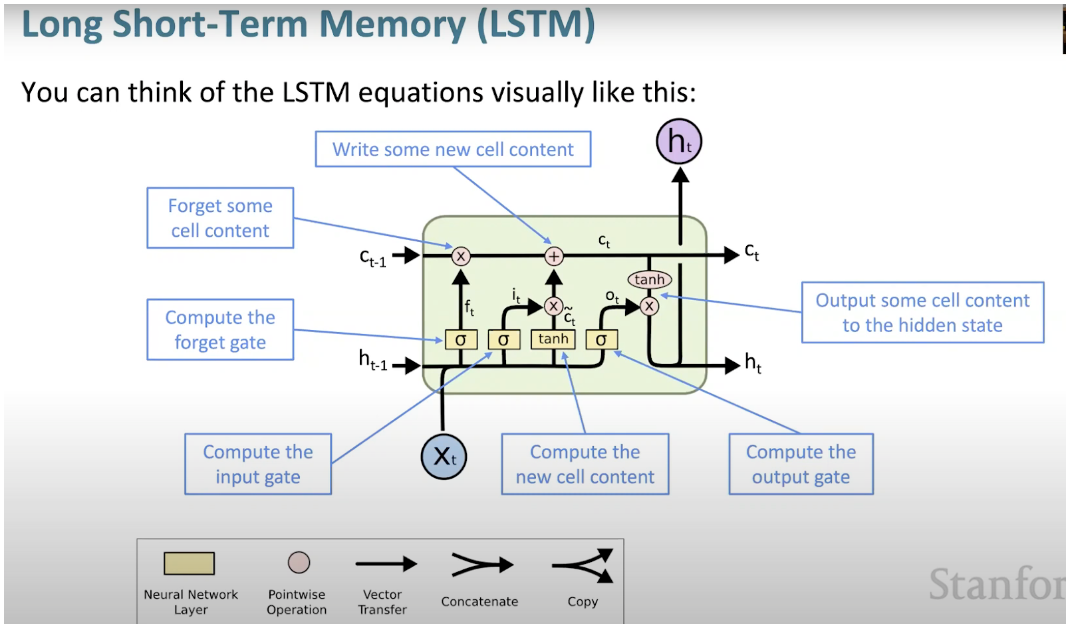
LSTM は遍在しており、多くのアプリケーションや製品で使用できます。スマートフォンとして。その威力は、典型的なニューロンベースのアーキテクチャから離れ、代わりにメモリユニットの概念を採用しているという事実にあります。このメモリ ユニットは、入力の機能に従ってその値を保持し、その値を短期間または長期間保持できます。これにより、ユニットは最後に計算された値だけでなく、重要なことを記憶できるようになります。
LSTM メモリ ユニットには、ユニット内の情報の流入または流出を制御する 3 つのゲートが含まれています。
- 入力ゲート: 情報がいつメモリに流入できるかを制御します。
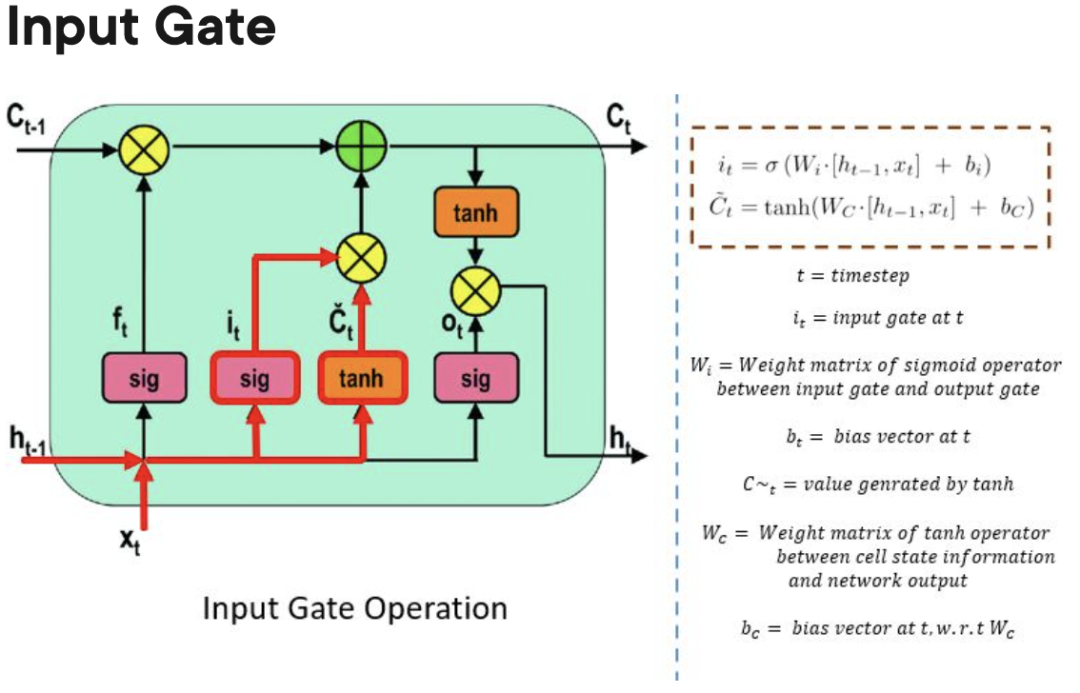
忘れゲート: 処理装置が新しいデータを記憶する余地を作るために、どの情報が「忘れられる」可能性があるかを追跡する責任を負います。
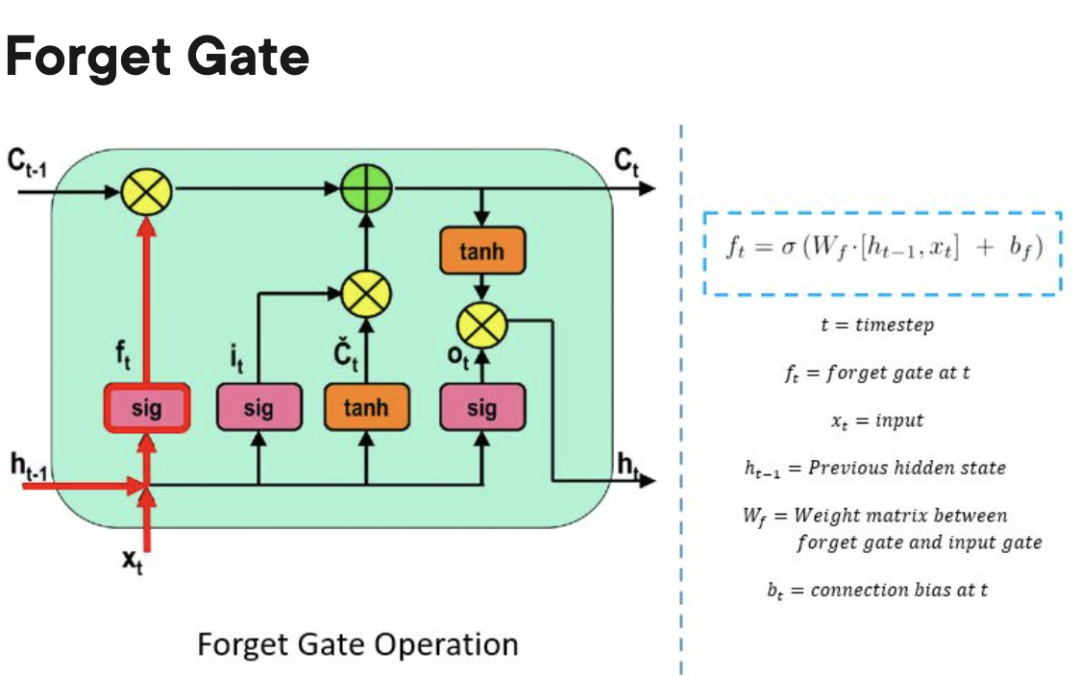
出力ゲート: 処理ユニット内に保存された情報をいつセルの出力として使用できるかを決定します。
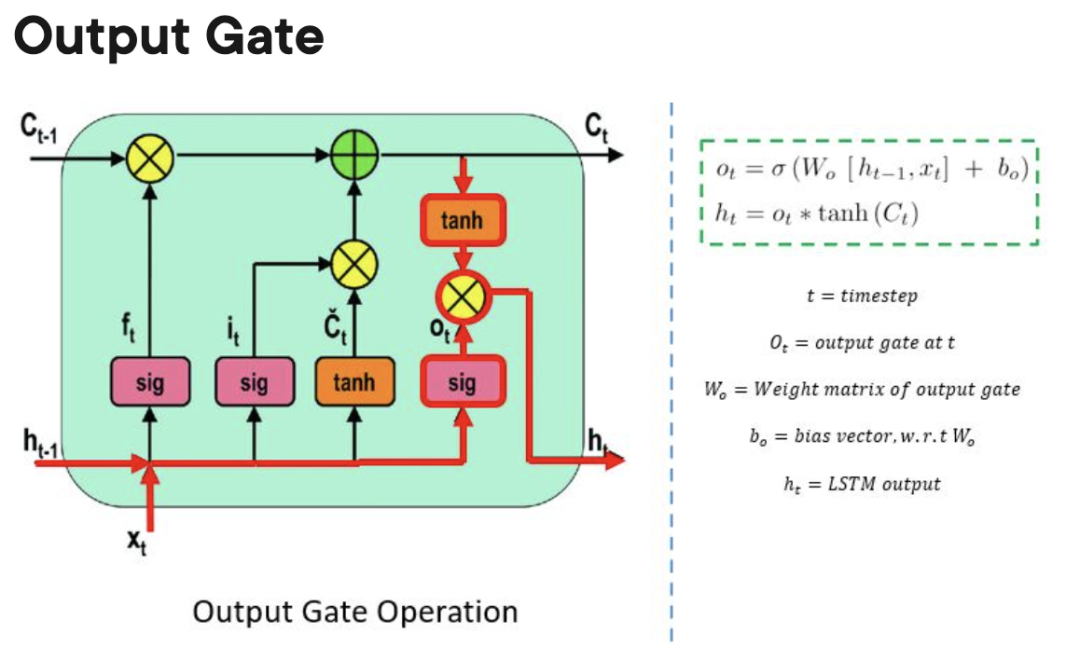
GRU および RNN と比較した LSTM の長所と短所
GRU との比較特に RNN と LSTM は長期的な依存関係を学習できます。ゲートが 3 つあるため (GRU には 2 つ、RNN には 0 つ)、LSTM には RNN や GRU と比較してより多くのパラメーターがあります。これらの追加パラメーターにより、LSTM モデルは自然言語や時系列データなどの複雑なシーケンス データをより適切に処理できるようになります。さらに、LSTM はゲート構造により不要な入力を無視できるため、可変長の入力シーケンスも処理できます。その結果、LSTM は音声認識、機械翻訳、株式市場予測などの多くのアプリケーションで良好なパフォーマンスを発揮します。
5. ゲート付きリカレント ユニット (GRU)
GRU には、どの情報を出力に渡すかを決定するための 2 つのゲート、更新ゲートとリセット ゲート (基本的に 2 つのベクトル) があります。
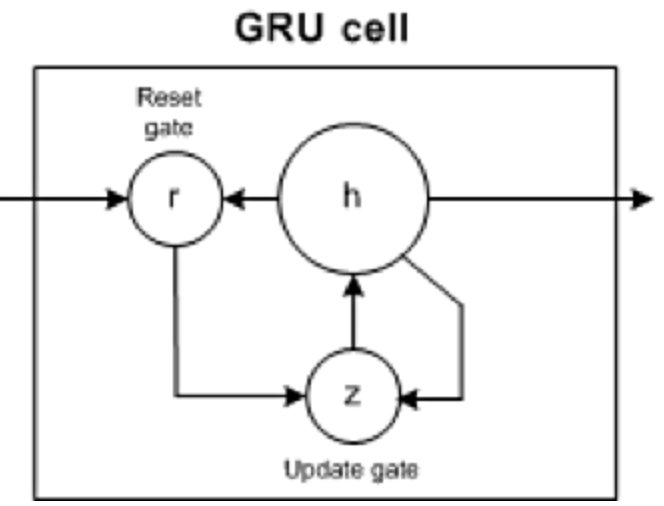
- #リセット ゲート: モデルがどの程度の過去の情報を忘れてもよいかを決定するのに役立ちます。
- 更新ゲート: モデルがどれだけの過去の情報 (前の時間ステップ) を将来に渡す必要があるかを決定するのに役立ちます。
6.トランスフォーマー
トランスフォーマーに関する論文「Attending is All You Need」は、Arxiv 上でほぼナンバーワンの論文です。 Transformer は、複雑なアテンション メカニズムを使用してシーケンス全体を処理できる大規模なエンコーダ/デコーダ モデルです。
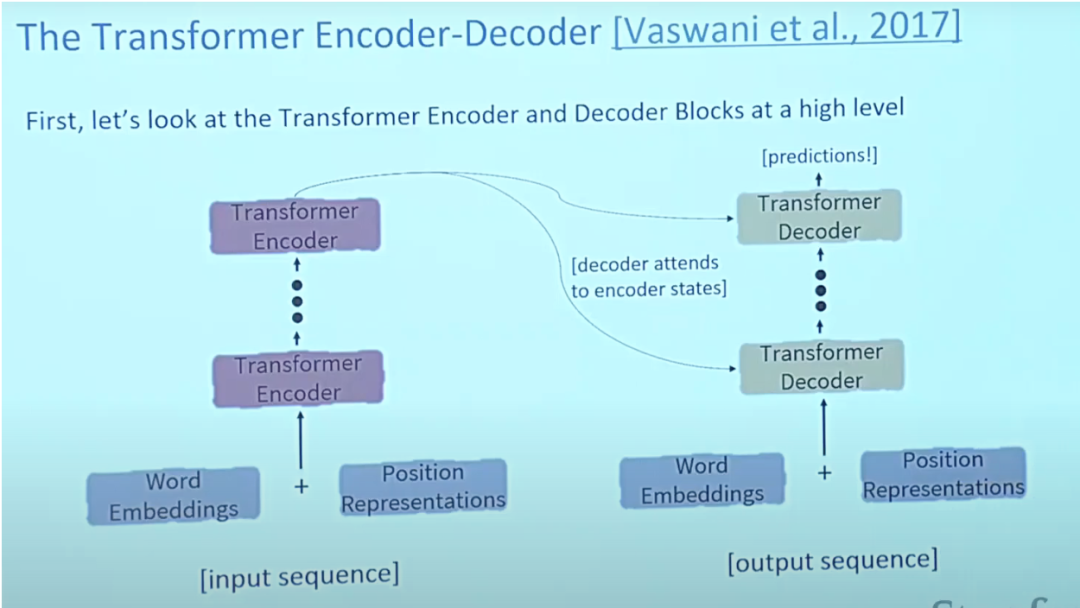
# 通常、自然言語処理アプリケーションでは、各入力単語はまず埋め込みアルゴリズムを使用してベクトルに変換されます。埋め込みは最下位レベルのエンコーダでのみ行われます。すべてのエンコーダで共有される抽象化は、サイズ 512 のベクトルのリストを受け取ることです。これは単語の埋め込みになりますが、他のエンコーダでは、それはエンコーダ出力の直下になります。
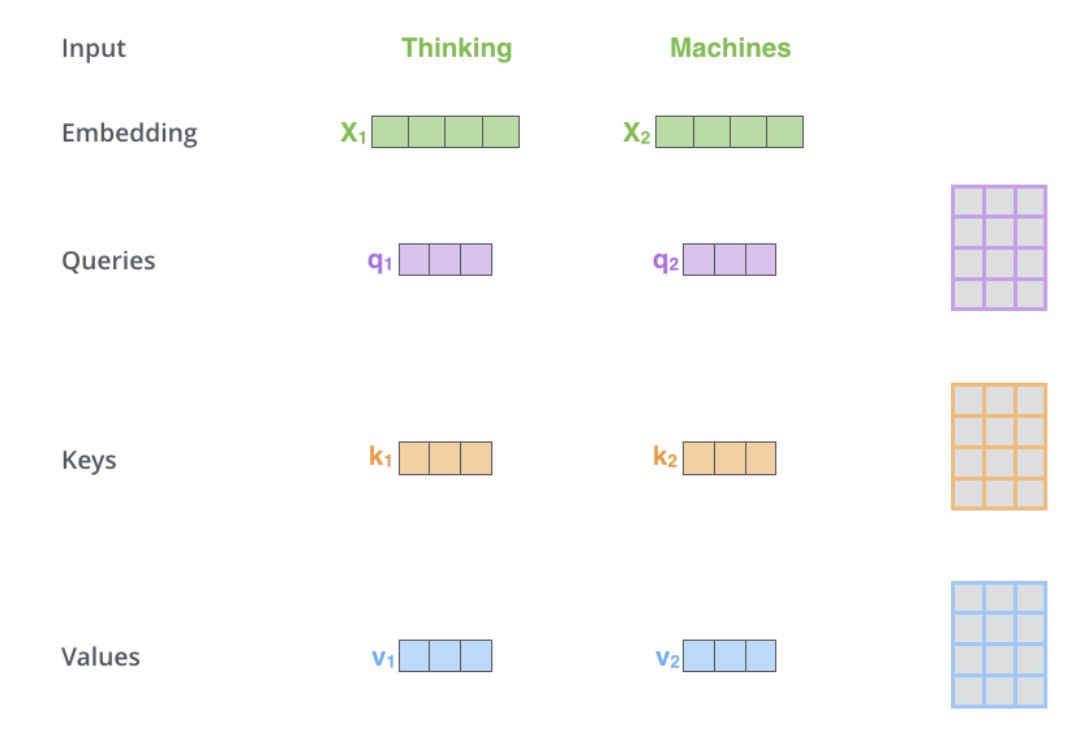
#Attention はボトルネック問題の解決策を提供します。このようなタイプのモデルでは、コンテキスト ベクトルがボトルネックとなり、モデルが長い文を処理することが困難になります。アテンションにより、モデルは必要に応じて入力シーケンスの関連部分に焦点を当て、各単語の表現をクエリとして扱い、一連の値の情報にアクセスして結合することができます。 6.1 Transformer アーキテクチャの特徴一般に、Transformer アーキテクチャでは、エンコーダはすべての隠れた状態をデコーダに渡すことができます。ただし、デコーダは出力を生成する前に注意を払って追加のステップを実行します。デコーダは各隠れ状態にそのソフトマックス スコアを乗算することで、よりスコアの高い隠れ状態を増幅し、他の隠れ状態をフラッディングします。これにより、モデルは出力に関連する入力の部分に焦点を当てることができます。 セルフ アテンションはエンコーダ内にあります。最初のステップは、各エンコーダ入力ベクトル (各単語の埋め込み) から 3 つのベクトルを作成することです: キー ベクトル、クエリ ベクトル、および値ベクトルです。これらのベクトルは、埋め込みを変換することによって取得されます。トレーニング中にトレーニングされた 3 つの行列を乗算して作成されます。 K、V、Q の次元は 64 ですが、埋め込みベクトルとエンコーダの入出力ベクトルの次元は 512 です。下の写真は Jay Alammar の Illustrated Transformer からのもので、これはおそらくインターネット上で最も優れた視覚的解釈です。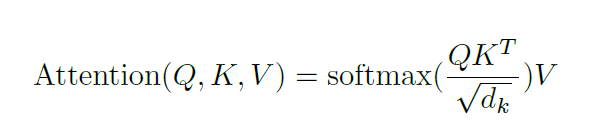
- 注意:
Transformer が登場する前は、AI 言語タスクの進歩は他の分野の発展に大きく遅れをとっていた。実際、過去 10 年ほどの深層学習革命では、自然言語処理は後発であり、NLP はコンピューター ビジョンにある程度遅れをとっていました。しかし、Transformers の出現により、NLP 分野は大きな後押しを受け、さまざまな NLP タスクで良好な結果を達成する一連のモデルが発売されました。
たとえば、従来の言語モデル (RNN、LSTM、GRU などの再帰的アーキテクチャに基づく) と Transformers の違いを理解するために、次のような例を挙げることができます。爪でそれをつかみましたが、尻尾の端だけを手に入れました。」 2 番目の文の構造は混乱しています。その「それ」は何を意味しますか? 「それ」の周囲の単語のみに焦点を当てる従来の言語モデルでは困難ですが、各単語を他の単語に接続するトランスフォーマーは、フクロウがリスを捕まえたこと、リスが尻尾の一部を失ったことを伝えることができます。
6.2.2 ビジョンフィールド
CNN では、ローカルから始めて、徐々にグローバルな視点を獲得します。 CNN は、ローカルからグローバルまで特徴を構築してコーナーや線などの特徴を識別することにより、画像をピクセルごとに認識します。しかし、変換器では、自己注意を通じて、情報処理の第一レベルでも(言語と同様に)遠隔の画像位置間の接続が確立されます。 CNN アプローチが単一ピクセルから開始するスケーリングに似ている場合、トランスフォーマーはぼやけた画像全体に徐々に焦点を合わせます。

ただし、最大のメリットは、Transformer が並列化に適していることです。各タイム ステップで 1 つの単語を処理する RNN とは異なり、Transformer の重要な特性は、各位置の単語が独自のパスを介してエンコーダーを通過することです。セルフアテンション層では、その単語に対する各入力シーケンス内の他の単語の重要性を計算するため、これらのパス間に依存関係が存在します。ただし、セルフアテンション出力が生成されると、フィードフォワード層にはこれらの依存関係がなくなるため、個々のパスはフィードフォワード層を通過するときに並行して実行できます。これは、セルフアテンション層の後で各入力単語を他の単語と並行して処理する Transformer エンコーダの場合に特に便利な機能です。ただし、この機能は一度に 1 ワードのみを生成し、並列ワード パスを使用しないため、デコーダにとってはあまり重要ではありません。
Transformer アーキテクチャの実行時間は、入力シーケンスの長さに応じて二次関数的に増加します。つまり、長いドキュメントや文字を入力として処理する場合、処理が遅くなる可能性があります。言い換えれば、セルフアテンションの形成中に、すべての相互作用ペアを計算する必要があります。これは、計算がシーケンスの長さ、つまり O(T^2 d) に応じて二次関数的に増大することを意味します。ここで、T はシーケンスの長さ、D は次元。例えば、単文 d=1000 に対応すると、T≤30⇒T^2≤900⇒T^2d≈900Kとなります。そして、循環神経の場合、直線的にのみ成長します。
Transformer が文内のすべての単語のペア間の相互作用を計算する必要がなければ、素晴らしいと思いませんか?すべての単語ペア間の相互作用を計算しなくても (ペアごとの注意を近似することによって) 非常に高いパフォーマンス レベルを達成できることを示す研究があります。
CNN と比較すると、Transformer には非常に高いデータ要件があります。 CNN は依然としてサンプル効率が高いため、リソースが少ないタスクには優れた選択肢となります。これは、CNN アーキテクチャであっても大量のデータを必要とする画像/ビデオ生成タスクに特に当てはまります (したがって、Transformer アーキテクチャの非常に高いデータ要件を意味します)。たとえば、Radford らが最近提案した CLIP アーキテクチャは、ビジュアル バックボーンとして (ViT のような Transformer アーキテクチャの代わりに) CNN ベースの ResNets を使用してトレーニングされています。 Transformer はデータ要件が満たされると精度が向上しますが、CNN は利用可能なデータの量が異常に多くないタスクで優れた精度パフォーマンスを提供する方法を提供します。したがって、どちらのアーキテクチャにもそれぞれの用途があります。
Transformer アーキテクチャの実行時間は、入力シーケンスの長さと 2 次の関係があるためです。つまり、すべての単語のペアに対するアテンションを計算するには、グラフ内のエッジの数がノードの数に応じて二次関数的に増加する必要があります。つまり、n 単語の文の場合、Transformer は n^2 の単語のペアを計算する必要があります。これは、パラメーターの数が膨大である (つまり、メモリ使用量が多い) ことを意味し、その結果、計算の複雑さが高くなります。高いコンピューティング要件は、特にモバイル デバイスの場合、電力とバッテリー寿命の両方に悪影響を及ぼします。全体として、より優れたパフォーマンス (精度など) を提供するために、Transformer はより高いコンピューティング能力、より多くのデータ、電力/バッテリー寿命、およびメモリー占有面積を必要とします。
7. 推論バイアス
ニアレストネイバーから勾配ブースティングまで、実際に使用されるすべての機械学習アルゴリズムには、どのカテゴリが学習しやすいかについての独自の帰納的バイアスが伴います。ほとんどすべての学習アルゴリズムには、類似した (ある特徴空間で互いに「近い」) アイテムは同じクラスに属する可能性が高いという学習バイアスがあります。ロジスティック回帰などの線形モデルも、カテゴリが線形境界によって分離できると想定していますが、モデルは他に何も学習できないため、これは「ハード」バイアスとなります。機械学習でほぼ常に使用される正則化回帰の場合でも、特徴の重みが低く、少数の特徴が関与する境界の学習に偏りがあり、モデルは多くのクラスを学習できるため、これは「ソフト」バイアスです。重みの高い特徴を含む境界を作成しますが、これはより困難であり、より多くのデータが必要です。
ディープ ラーニング モデルにも推論バイアスがあります。たとえば、LSTM ニューラル ネットワークは、長いシーケンスにわたってコンテキスト情報を保持することを好むため、自然言語処理タスクに非常に効果的です。

各モデル構造には固有の推論バイアスがあり、データ内のパターンを理解するのに役立ち、それによって学習が可能になります。たとえば、CNN は空間パラメータ共有と変換/空間不変性を示しますが、RNN は時間パラメータ共有を示します。
8. 概要
古いプログラマーは、ディープ ラーニング アーキテクチャで Transformer、CNN、RNN/GRU/LSTM を比較および分析しようとしましたが、Transformer はより長い依存関係を学習できることを理解しましたが、それには、より高いデータ要件とコンピューティング能力。Transformer はマルチモーダルなタスクに適しており、読む/見る、話す、聞くなどの感覚をシームレスに切り替えることができます。各モデル構造には、学習を達成するためにデータ モデルを理解するのに役立つ固有の推論バイアスがあります。 。
【参考】
- 画像認識のための CNN と完全に接続されたネットワーク?、https://stats.stackexchange.com/questions/341863/cnn-vs-full-connected - network-for-image-recognition
- https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1184/lectures/lecture12.pdf
- LSTM ユニットの概要RNN、https://www.pluralsight.com/guides/introduction-to-lstm-units-in-rnn
- 自然言語監督からの転送可能なビジュアル モデルの学習、https://arxiv.org/ abs /2103.00020
- リンフォーマー: 線形複雑性による自己注意、https://arxiv.org/abs/2006.04768
- パフォーマーによる注意の再考、https://arxiv.org/abs/ 2009.14794
- Big Bird: より長いシーケンスのためのトランスフォーマー、https://arxiv.org/abs/2007.14062
- シンセサイザー: トランスフォーマー モデルにおける自己注意の再考、https://arxiv.org/ abs /2005.00743
- ビジョン トランスフォーマーは畳み込みニューラル ネットワークに似ていますか?、https://arxiv.org/abs/2108.08810
- イラスト付きトランスフォーマー、https://jalammar.github.io/illustrated -変成器/######
以上が深層学習アーキテクチャの比較分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7476
7476
 15
1377
52
77
11
19
32
15
1377
52
77
11
19
32

 ddrescue を使用して Linux 上のデータを回復する
Mar 20, 2024 pm 01:37 PM
ddrescue を使用して Linux 上のデータを回復する
Mar 20, 2024 pm 01:37 PM
DDREASE は、ハード ドライブ、SSD、RAM ディスク、CD、DVD、USB ストレージ デバイスなどのファイル デバイスまたはブロック デバイスからデータを回復するためのツールです。あるブロック デバイスから別のブロック デバイスにデータをコピーし、破損したデータ ブロックを残して正常なデータ ブロックのみを移動します。 ddreasue は、回復操作中に干渉を必要としないため、完全に自動化された強力な回復ツールです。さらに、ddasue マップ ファイルのおかげでいつでも停止および再開できます。 DDREASE のその他の主要な機能は次のとおりです。 リカバリされたデータは上書きされませんが、反復リカバリの場合にギャップが埋められます。ただし、ツールに明示的に指示されている場合は切り詰めることができます。複数のファイルまたはブロックから単一のファイルにデータを復元します
 オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
0.この記事は何をするのですか?私たちは、多用途かつ高速な最先端の生成単眼深度推定モデルである DepthFM を提案します。従来の深度推定タスクに加えて、DepthFM は深度修復などの下流タスクでも最先端の機能を実証します。 DepthFM は効率的で、いくつかの推論ステップ内で深度マップを合成できます。この作品について一緒に読みましょう〜 1. 論文情報タイトル: DepthFM: FastMonocularDepthEstimationwithFlowMatching 著者: MingGui、JohannesS.Fischer、UlrichPrestel、PingchuanMa、Dmytr
 ORB-SLAM3を超えて! SL-SLAM: 低照度、重度のジッター、弱いテクスチャのシーンはすべて処理されます。
May 30, 2024 am 09:35 AM
ORB-SLAM3を超えて! SL-SLAM: 低照度、重度のジッター、弱いテクスチャのシーンはすべて処理されます。
May 30, 2024 am 09:35 AM
以前に書きましたが、今日は、深層学習テクノロジーが複雑な環境におけるビジョンベースの SLAM (同時ローカリゼーションとマッピング) のパフォーマンスをどのように向上させることができるかについて説明します。ここでは、深部特徴抽出と深度マッチング手法を組み合わせることで、低照度条件、動的照明、テクスチャの弱い領域、激しいセックスなどの困難なシナリオでの適応を改善するように設計された多用途のハイブリッド ビジュアル SLAM システムを紹介します。当社のシステムは、拡張単眼、ステレオ、単眼慣性、ステレオ慣性構成を含む複数のモードをサポートしています。さらに、他の研究にインスピレーションを与えるために、ビジュアル SLAM と深層学習手法を組み合わせる方法も分析します。公開データセットと自己サンプリングデータに関する広範な実験を通じて、測位精度と追跡堅牢性の点で SL-SLAM の優位性を実証しました。
 Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google が推進する JAX のパフォーマンスは、最近のベンチマーク テストで Pytorch や TensorFlow のパフォーマンスを上回り、7 つの指標で 1 位にランクされました。また、テストは最高の JAX パフォーマンスを備えた TPU では行われませんでした。ただし、開発者の間では、依然として Tensorflow よりも Pytorch の方が人気があります。しかし、将来的には、おそらくより大規模なモデルが JAX プラットフォームに基づいてトレーニングされ、実行されるようになるでしょう。モデル 最近、Keras チームは、ネイティブ PyTorch 実装を使用して 3 つのバックエンド (TensorFlow、JAX、PyTorch) をベンチマークし、TensorFlow を使用して Keras2 をベンチマークしました。まず、主流のセットを選択します
 iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhone のモバイル データ接続に遅延や遅い問題が発生していませんか?通常、携帯電話の携帯インターネットの強度は、地域、携帯ネットワークの種類、ローミングの種類などのいくつかの要因によって異なります。より高速で信頼性の高いセルラー インターネット接続を実現するためにできることがいくつかあります。解決策 1 – iPhone を強制的に再起動する 場合によっては、デバイスを強制的に再起動すると、携帯電話接続を含む多くの機能がリセットされるだけです。ステップ 1 – 音量を上げるキーを 1 回押して放します。次に、音量小キーを押して、もう一度放します。ステップ 2 – プロセスの次の部分は、右側のボタンを押し続けることです。 iPhone の再起動が完了するまで待ちます。セルラーデータを有効にし、ネットワーク速度を確認します。もう一度確認してください 修正 2 – データ モードを変更する 5G はより優れたネットワーク速度を提供しますが、信号が弱い場合はより適切に機能します
 超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
世界は狂ったように大きなモデルを構築していますが、インターネット上のデータだけではまったく不十分です。このトレーニング モデルは「ハンガー ゲーム」のようであり、世界中の AI 研究者は、データを貪欲に食べる人たちにどのように餌を与えるかを心配しています。この問題は、マルチモーダル タスクで特に顕著です。何もできなかった当時、中国人民大学学部のスタートアップチームは、独自の新しいモデルを使用して、中国で初めて「モデル生成データフィード自体」を実現しました。さらに、これは理解側と生成側の 2 つの側面からのアプローチであり、両方の側で高品質のマルチモーダルな新しいデータを生成し、モデル自体にデータのフィードバックを提供できます。モデルとは何ですか? Awaker 1.0 は、中関村フォーラムに登場したばかりの大型マルチモーダル モデルです。チームは誰ですか?ソフォンエンジン。人民大学ヒルハウス人工知能大学院の博士課程学生、ガオ・イージャオ氏によって設立されました。
 アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
最近、軍事界は、米軍戦闘機が AI を使用して完全自動空戦を完了できるようになったというニュースに圧倒されました。そう、つい最近、米軍のAI戦闘機が初めて公開され、その謎が明らかになりました。この戦闘機の正式名称は可変安定性飛行シミュレーター試験機(VISTA)で、アメリカ空軍長官が自ら飛行させ、一対一の空戦をシミュレートした。 5 月 2 日、フランク ケンダル米国空軍長官は X-62AVISTA でエドワーズ空軍基地を離陸しました。1 時間の飛行中、すべての飛行動作が AI によって自律的に完了されたことに注目してください。ケンダル氏は「過去数十年にわたり、私たちは自律型空対空戦闘の無限の可能性について考えてきたが、それは常に手の届かないものだと思われてきた」と語った。しかし今では、
 柔軟かつ高速な 5 本の指を備え、人間のタスクを自律的に完了する初のロボットが登場、大型モデルが仮想空間トレーニングをサポート
Mar 11, 2024 pm 12:10 PM
柔軟かつ高速な 5 本の指を備え、人間のタスクを自律的に完了する初のロボットが登場、大型モデルが仮想空間トレーニングをサポート
Mar 11, 2024 pm 12:10 PM
今週、OpenAI、Microsoft、Bezos、Nvidiaが投資するロボット企業FigureAIは、7億ドル近くの資金調達を受け、来年中に自立歩行できる人型ロボットを開発する計画であると発表した。そしてテスラのオプティマスプライムには繰り返し良い知らせが届いている。今年が人型ロボットが爆発的に普及する年になることを疑う人はいないだろう。カナダに拠点を置くロボット企業 SanctuaryAI は、最近新しい人型ロボット Phoenix をリリースしました。当局者らは、多くのタスクを人間と同じ速度で自律的に完了できると主張している。人間のスピードでタスクを自律的に完了できる世界初のロボットである Pheonix は、各オブジェクトを優しくつかみ、動かし、左右にエレガントに配置することができます。自律的に物体を識別できる
