
1. 解決策
各ワーカー プロセスが作成されると、 ngx_worker_process_init() メソッドが呼び出され、現在のワーカー プロセスが初期化されます。このプロセスのステップ、つまり、各ワーカー プロセスは epoll_create() メソッドを呼び出して、それ自体に一意の epoll ハンドルを作成します。監視する必要があるポートごとに、それに対応するファイル記述子があり、ワーカー プロセスは epoll_ctl() メソッドを通じて現在のプロセスの epoll ハンドルにファイル記述子を追加し、accept イベントをリッスンするだけです。クライアントの接続確立イベントを使用してイベントを処理します。ここから、ワーカー プロセスが監視する必要があるポートに対応するファイル記述子をプロセスの epoll ハンドルに追加しない場合、対応するイベントをトリガーできないこともわかります。この原則に基づいて、nginx は共有ロックを使用して、現在のプロセスに監視する必要があるポートを現在のプロセスの epoll ハンドルに追加する権限があるかどうかを制御します。つまり、ロックを取得したプロセスのみがリッスンします。ターゲットポートに接続します。このようにして、イベントが発生するたびに 1 つのワーカー プロセスのみがトリガーされることが保証されます。次の図は、ワーカー プロセスの作業サイクルの概略図です。
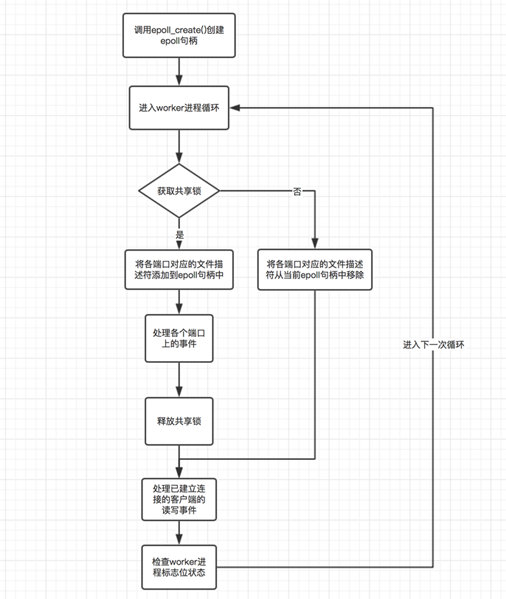
図のプロセスに関して説明する必要があるのは、各ワーカー プロセスがサイクルに入ります。共有ロックの取得を試みます。取得できない場合は、監視対象ポートのファイル記述子が現在のプロセスの epoll ハンドルから削除されます (存在しない場合でも削除されます)。これの主な目的は損失を防ぐことです。クライアント接続イベントは、少量の雷を伴う群れの問題を引き起こす可能性がありますが、深刻なものではありません。想像してみてください。理論によれば、現在のプロセスがロックを解放するときにリスニング ポートのファイル記述子が epoll ハンドルから削除され、次のワーカー プロセスがロックを取得する前に、この期間中の各ポートに対応するファイル記述子は次のようになります。リッスンする epoll ハンドルがない場合、イベントは失われます。一方、図のようにロックの取得に失敗した場合にのみ監視対象のファイル記述子が削除される場合、ロックの取得に失敗するということは、現在そのファイル記述子を監視しているプロセスが存在するはずなので安全です。現時点でそれらを削除するには。しかし、これによって引き起こされる問題の 1 つは、上の図によると、現在のプロセスがループの実行を完了すると、ロックを解放してから他のイベントを処理することです。このプロセス中に監視対象のファイル記述子は解放されないことに注意してください。 。このとき、別のプロセスがロックを取得してファイルディスクリプタを監視している場合、この時点でファイルディスクリプタを監視しているプロセスは2つあるため、クライアント上でコネクション確立イベントが発生すると2つのワーカーが起動されることになります。この問題は、次の 2 つの主な理由により許容されます:
この種の激しい群れ現象は、少数のワーカー プロセスのみをトリガーするため、毎回すべてのワーカー プロセスを起動するよりも優れています。
2. ソースコードの説明
void ngx_process_events_and_timers(ngx_cycle_t *cycle) {
ngx_uint_t flags;
ngx_msec_t timer, delta;
if (ngx_trylock_accept_mutex(cycle) == ngx_error) {
return;
}
// 这里开始处理事件,对于kqueue模型,其指向的是ngx_kqueue_process_events()方法,
// 而对于epoll模型,其指向的是ngx_epoll_process_events()方法
// 这个方法的主要作用是,在对应的事件模型中获取事件列表,然后将事件添加到ngx_posted_accept_events
// 队列或者ngx_posted_events队列中
(void) ngx_process_events(cycle, timer, flags);
// 这里开始处理accept事件,将其交由ngx_event_accept.c的ngx_event_accept()方法处理;
ngx_event_process_posted(cycle, &ngx_posted_accept_events);
// 开始释放锁
if (ngx_accept_mutex_held) {
ngx_shmtx_unlock(&ngx_accept_mutex);
}
// 如果不需要在事件队列中进行处理,则直接处理该事件
// 对于事件的处理,如果是accept事件,则将其交由ngx_event_accept.c的ngx_event_accept()方法处理;
// 如果是读事件,则将其交由ngx_http_request.c的ngx_http_wait_request_handler()方法处理;
// 对于处理完成的事件,最后会交由ngx_http_request.c的ngx_http_keepalive_handler()方法处理。
// 这里开始处理除accept事件外的其他事件
ngx_event_process_posted(cycle, &ngx_posted_events);
}ngx_int_t ngx_trylock_accept_mutex(ngx_cycle_t *cycle) {
// 尝试使用cas算法获取共享锁
if (ngx_shmtx_trylock(&ngx_accept_mutex)) {
// ngx_accept_mutex_held为1表示当前进程已经获取到了锁
if (ngx_accept_mutex_held && ngx_accept_events == 0) {
return ngx_ok;
}
// 这里主要是将当前连接的文件描述符注册到对应事件的队列中,比如kqueue模型的change_list数组
// nginx在启用各个worker进程的时候,默认情况下,worker进程是会继承master进程所监听的socket句柄的,
// 这就导致一个问题,就是当某个端口有客户端事件时,就会把监听该端口的进程都给唤醒,
// 但是只有一个worker进程能够成功处理该事件,而其他的进程被唤醒之后发现事件已经过期,
// 因而会继续进入等待状态,这种现象称为"惊群"现象。
// nginx解决惊群现象的方式一方面是通过这里的共享锁的方式,即只有获取到锁的worker进程才能处理
// 客户端事件,但实际上,worker进程是通过在获取锁的过程中,为当前worker进程重新添加各个端口的监听事件,
// 而其他worker进程则不会监听。也就是说同一时间只有一个worker进程会监听各个端口,
// 这样就避免了"惊群"问题。
// 这里的ngx_enable_accept_events()方法就是为当前进程重新添加各个端口的监听事件的。
if (ngx_enable_accept_events(cycle) == ngx_error) {
ngx_shmtx_unlock(&ngx_accept_mutex);
return ngx_error;
}
// 标志当前已经成功获取到了锁
ngx_accept_events = 0;
ngx_accept_mutex_held = 1;
return ngx_ok;
}
// 前面获取锁失败了,因而这里需要重置ngx_accept_mutex_held的状态,并且将当前连接的事件给清除掉
if (ngx_accept_mutex_held) {
// 如果当前进程的ngx_accept_mutex_held为1,则将其重置为0,并且将当前进程在各个端口上的监听
// 事件给删除掉
if (ngx_disable_accept_events(cycle, 0) == ngx_error) {
return ngx_error;
}
ngx_accept_mutex_held = 0;
}
return ngx_ok;
}以上がnginxパニックグループの問題を解決する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



