

GPT-4 は、最も困難な数学的推論データセットの新しい SOTA を獲得し、新しいプロンプトは大規模モデルの推論能力を大幅に向上させます

最近、Huawei Lianhe Port Chinese は、人間の質問プロセスをシミュレートするプログレッシブ ヒント プロンプティング (PHP) を提案する論文「プログレッシブ ヒント プロンプティングが大規模言語モデルの推論を改善する」を発表しました。 PHP フレームワークの下では、ラージ言語モデル (LLM) は、過去数回に生成された推論の答えをその後の推論のヒントとして使用し、最終的な正解に徐々に近づけることができます。 PHP を使用するには、次の 2 つの要件を満たすだけで済みます: 1) 質問を推論の回答と結合して新しい質問を形成できること、2) モデルがこの新しい質問を処理し、新しい推論の回答を提供できること。
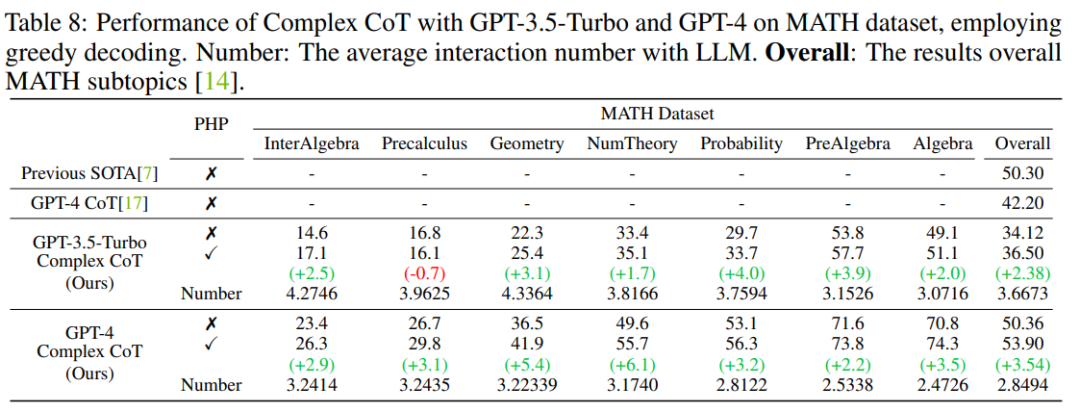
#結果は、GP-T-4 PHP が SVAMP を含む複数のデータセットで SOTA 結果を達成したことを示しています (91.9%) 、AQuA (79.9%)、GSM8K (95.5%)、MATH (53.9%)。この方法は GPT-4 CoT を大幅に上回ります。たとえば、最も難しい数学的推論データ セット MATH では、GPT-4 CoT は 42.5% にすぎませんが、MATH データ セットのネンバー理論 (数論) サブセットでは GPT-4 PHP が 6.1% 向上し、全体的な MATH が向上します。 53.9% に達し、SOTA に達します。

- 紙のリンク: https://arxiv 。 org/abs/2304.09797
- コードリンク: https://github.com/chuanyang-Zheng/Progressive-Hint はじめに
LLM の開発に伴い、プロンプトに関する取り組みがいくつか登場しましたが、その中には 2 つの主流の方向性があります。
1 つは Chain-Of-Thought (CoT、思考の連鎖) で表され、推論プロセスを明確に記述することでモデルの推論能力を刺激します。
- もう 1 つは、自己一貫性 (SC) で表されるものは、複数の回答をサンプリングし、最終的な回答を得るために投票することで表されます。
- 明らかに、既存の 2 つの方法では質問に変更は加えられません。これは、回答に戻らずに質問を 1 回終了することと同じです。再確認してください。 PHP は、より人間らしい推論プロセスをシミュレートしようとします。つまり、最後の推論プロセスを処理し、それを元の質問にマージし、LLM に再度推論を依頼します。最新の 2 つの推論答えが一致する場合、得られた答えは正確であり、最終的な答えが返されます。具体的なフローチャートは次のとおりです。

PHP プロンプトはベース プロンプトに基づいて変更されます。基本プロンプトが与えられると、定式化された PHP プロンプト設計原則を通じて、対応する PHP プロンプトを取得できます。以下の図に示すように:
 ##著者は、PHP プロンプトを使用して大規模なモデルが 2 つのマッピング モードを学習できるようにしたいと考えています。
##著者は、PHP プロンプトを使用して大規模なモデルが 2 つのマッピング モードを学習できるようにしたいと考えています。
##1) 指定されたヒントが正しい答えである場合、返される答えも正しい答えである必要があります (具体的には、上の図に示すように、「ヒントは正しい答えです」)。
##2) 指定されたヒントが不正解の場合、LLM は推論を使用して不正解のヒントから飛び出し、正しい答えを返さなければなりません (具体的には、「ヒントは不正解です」上の図に示すように、回答」と入力します)。この PHP プロンプト設計ルールに従って、既存のベース プロンプトがあれば、作成者は対応する PHP プロンプトを設定できます。
著者は、AddSub、MultiArith、SingleEQ、SVAMP、GSM8K、AQuA、MATH を含む 7 つのデータ セットを使用します。同時に、著者は、text-davinci-002、text-davinci-003、GPT-3.5-Turbo、GPT-4 の合計 4 つのモデルを使用して、著者のアイデアを検証しました。 #主な結果実験
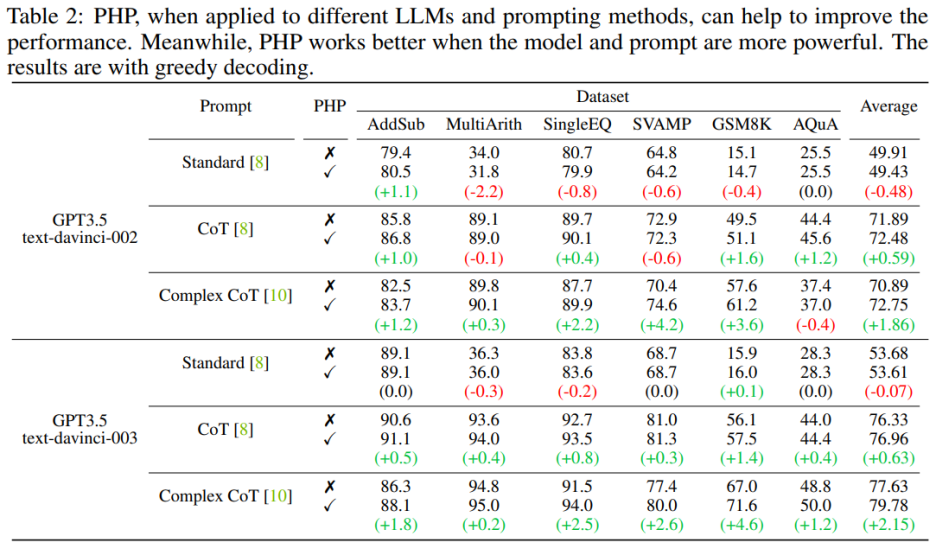
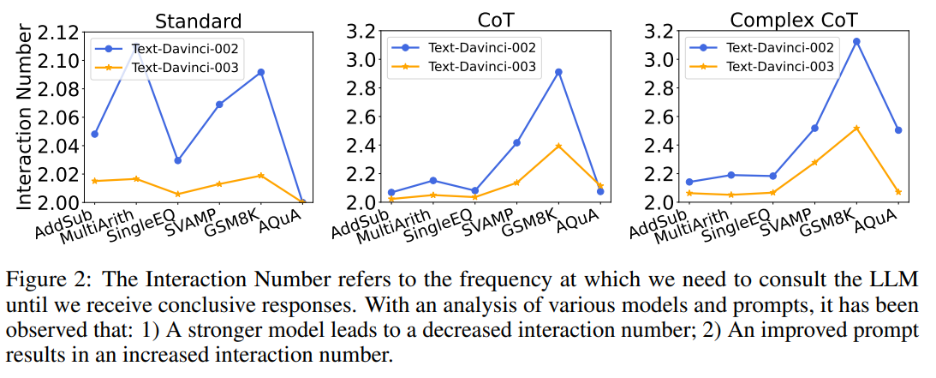
1) 同じプロンプトを与えた場合、text-davinci-003 のインタラクションの数は、text-davinci-002 のインタラクションの数よりも一般に少ないです。これは主に、text-davinci-003 の精度が高いためです。その結果、基本的な回答とその後の回答がより正確になり、最終的な正解を得るために必要な操作が少なくなります。
2) 同じモデルを使用する場合、通常、プロンプトが強力になるにつれてインタラクションの数が増加します。これは、プロンプトがより効果的になると、LLM の推論能力がより有効に活用され、プロンプトを使用して間違った答えにジャンプできるようになり、最終的には最終的な答えに到達するまでにより多くのインタラクションが必要となり、その結果、回答の数が増加するためです。相互作用。
#ヒントの品質への影響
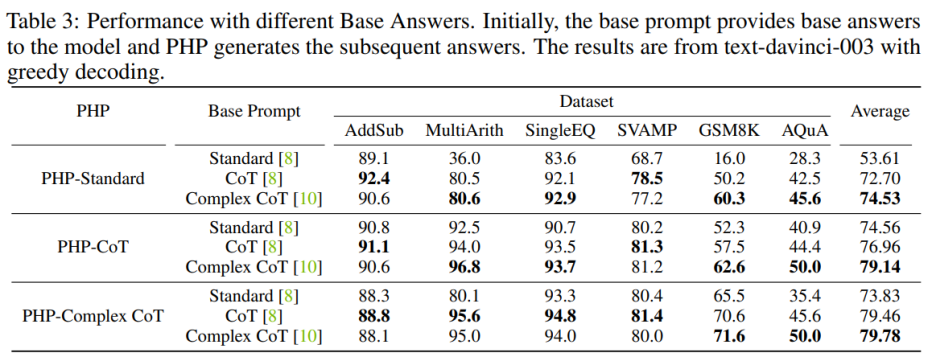 対象者: PHP 標準のパフォーマンスを向上させるには、Base Prompt Standard を Complex CoT または CoT に置き換えることで、最終的なパフォーマンスを大幅に向上させることができます。 PHP 標準の場合、著者らは、GSM8K のパフォーマンスが、Base Prompt Standard での 16.0%、Base Prompt CoT での 50.2%、Base Prompt Complex CoT での 60.3% に向上したことを観察しました。逆に、Base Prompt Complex CoT を Standard に置き換えると、パフォーマンスが低下します。たとえば、ベース プロンプト Complex CoT を Standard に置き換えた後、GSM8K データセットでの PHP-Complex CoT のパフォーマンスは 71.6% から 65.5% に低下しました。
対象者: PHP 標準のパフォーマンスを向上させるには、Base Prompt Standard を Complex CoT または CoT に置き換えることで、最終的なパフォーマンスを大幅に向上させることができます。 PHP 標準の場合、著者らは、GSM8K のパフォーマンスが、Base Prompt Standard での 16.0%、Base Prompt CoT での 50.2%、Base Prompt Complex CoT での 60.3% に向上したことを観察しました。逆に、Base Prompt Complex CoT を Standard に置き換えると、パフォーマンスが低下します。たとえば、ベース プロンプト Complex CoT を Standard に置き換えた後、GSM8K データセットでの PHP-Complex CoT のパフォーマンスは 71.6% から 65.5% に低下しました。
PHP が対応するベース プロンプトに基づいて設計されていない場合、効果はさらに向上する可能性があります。 Base Prompt Complex CoT を使用した PHP-CoT は、6 つのデータセットのうち 4 つで CoT を使用した PHP-CoT よりも優れたパフォーマンスを示しました。同様に、Base Prompt CoT を使用する PHP-Complex CoT は、6 つのデータセットのうち 4 つで Base Prompt Complex CoT を使用する PHP-Complex CoT よりも優れたパフォーマンスを示します。著者は、これは 2 つの理由によるものであると推測しています: 1) 6 つのデータ セットすべてで、CoT と Complex CoT のパフォーマンスは類似しているため、2) 基本の答えは CoT (または Complex CoT) によって提供され、その後の答えは次のとおりです。 PHP-Complex CoT (または PHP-CoT) に基づいています。これは、2 人が協力して問題を解決することに相当します。したがって、この場合には、システムのパフォーマンスがさらに向上する可能性がある。
アブレーション実験
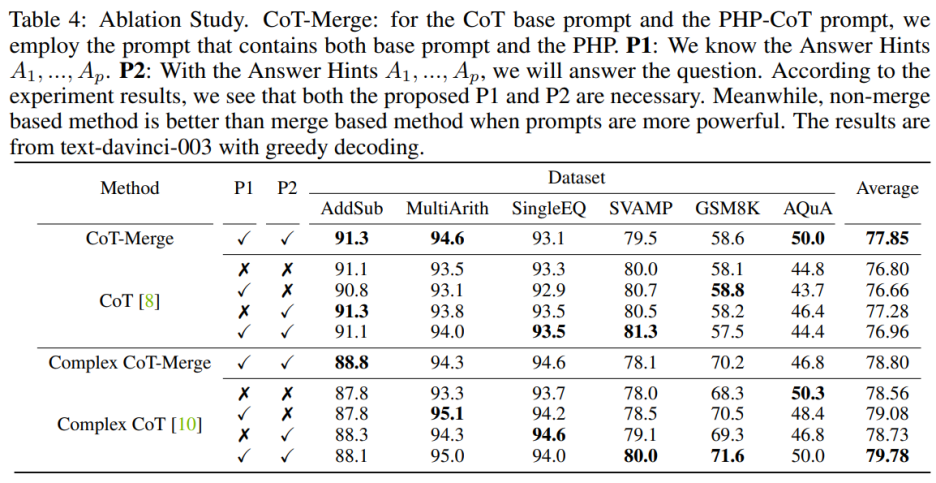
センテンス P1 と P2 をモデルに組み込むと、3 つのデータセットに対する CoT のパフォーマンスを向上させることができますが、Complex CoT メソッドを使用する場合、これらのこの文の重要性は特に明らかです。 P1 と P2 を追加すると、6 つのデータセットのうち 5 つでメソッドのパフォーマンスが向上しました。たとえば、Complex CoT のパフォーマンスは、SVAMP データセットでは 78.0% から 80.0% に、GSM8K データセットでは 68.3% から 71.6% に向上しました。これは、特にモデルの論理能力が高い場合、文 P1 と P2 の効果がより顕著であることを示しています。
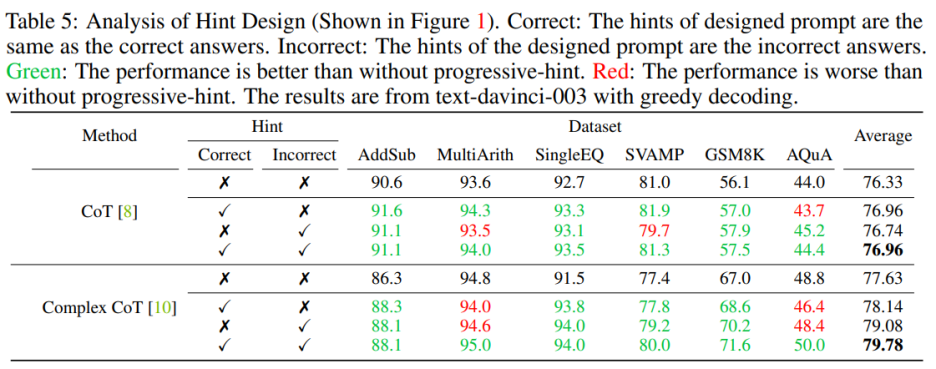
#プロンプトを設計するときは、正しいプロンプトと間違ったプロンプトの両方を含める必要があります。正しいヒントと間違ったヒントの両方を含むヒントを設計する場合は、PHP を使用しないよりも PHP を使用した方が良いでしょう。具体的には、プロンプトに正しいヒントを提供すると、指定されたヒントと一致する回答の生成が容易になります。逆に、プロンプトに誤ったヒントを提供すると、指定されたプロンプトを通じて代替回答の生成が促進されます。
PHP 自己一貫性
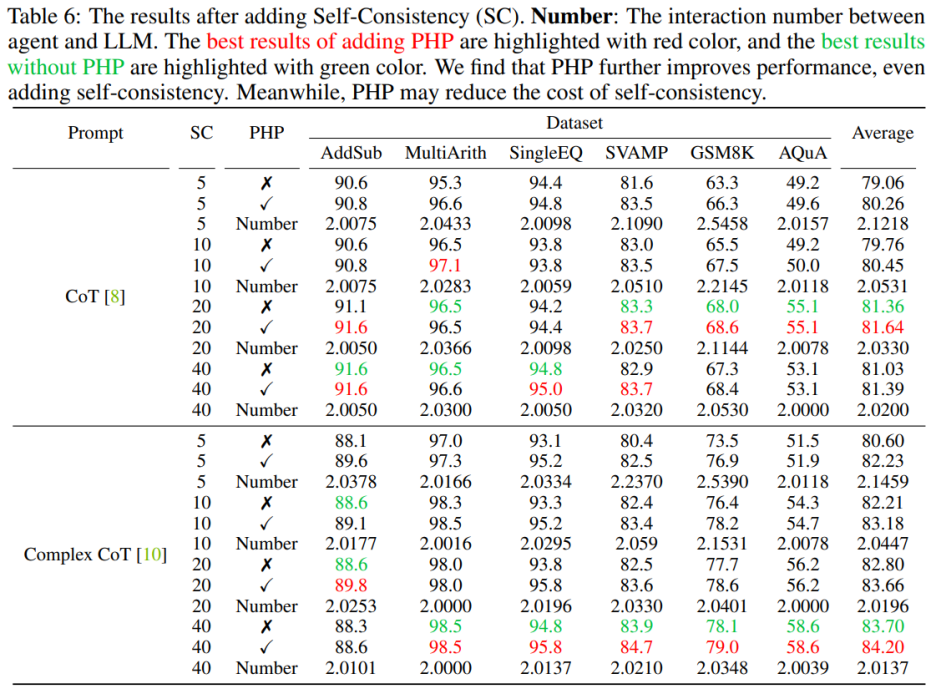
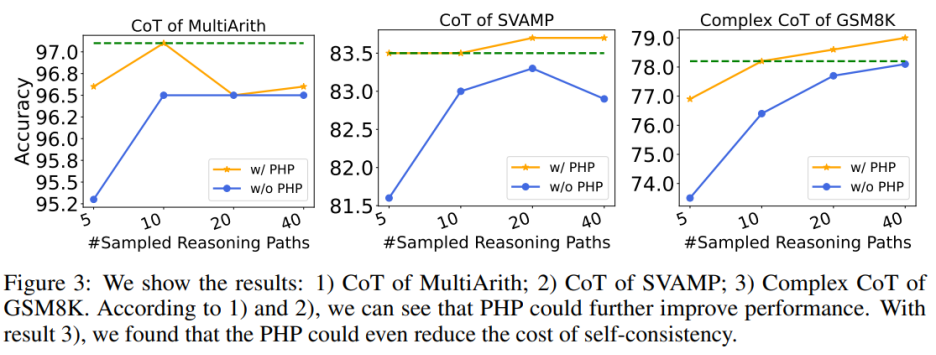
PHP を使用すると、SC のコストを削減できます。ご存知のとおり、SC にはより多くの推論パスが含まれるため、コストが高くなります。表 6 は、PHP がパフォーマンスの向上を維持しながらコストを削減する効果的な方法であることを示しています。図 3 に示すように、SC Complex CoT を使用すると、40 のサンプル パスを使用して 78.1% の精度を達成できますが、PHP を追加すると、必要な平均推論パスが 10×2.1531=21.531 パスに減少し、結果と精度が向上します。 78.2%に達しています。
GPT-3.5-Turbo および GPT-4
作者は以前の作業設定に従い、テキスト生成モデルを使用しています実験を行う。 GPT-3.5-Turbo および GPT-4 の API リリースを使用して、著者らは同じ 6 つのデータセット上で PHP を使用した Complex CoT のパフォーマンスを検証しました。著者らは、両方のモデルのヒントとして貪欲なデコード (つまり、温度 = 0) と Complex CoT を使用しています。表 7 に示すように、提案された PHP は、GSM8K で 2.3%、AQuA で 3.2% パフォーマンスを向上させます。ただし、GPT-3.5-Turbo は、text-davinci-003 と比較して、合図に従う能力が低下していることが示されました。著者はこの点を説明するために 2 つの例を示しています: a) ヒントが欠落している場合、GPT-3.5-Turbo は質問に答えることができず、次のような応答をします。続行します」というステートメント。対照的に、text-davinci-003 は、質問に回答する前に、不足している回答ヒントを自律的に生成して埋めます。b) 10 個を超えるヒントが提供された場合、GPT-3.5-Turbo は、「複数の回答が与えられているため、ヒントを得ることができません」と応答することがあります。正しい答えを判断するには、質問に対する答えのヒントを入力してください。"
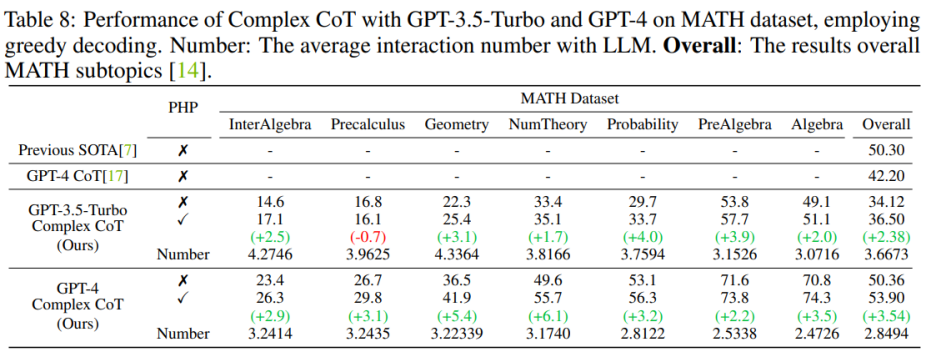
GPT-4 モデルをデプロイした後、著者は SVAMP、GSM8K、AQuA、および MATH ベンチマークで新しい SOTA パフォーマンスを達成することができました。著者が提案した PHP メソッドは、GPT-4 のパフォーマンスを継続的に向上させます。さらに、著者らは、GPT-4 が GPT-3.5-Turbo モデルと比較して必要な相互作用が少ないことを観察しました。これは、モデルがより強力になると相互作用の数が減少するという発見と一致します。
概要
この記事では、PHP が LLM と対話するための新しい方法を紹介します。これには複数の利点があります。 1) PHP は、数学的推論タスクのパフォーマンスを大幅に向上させ、優れたパフォーマンスを実現します。複数の推論ベンチマークでの最先端の結果; 2) PHP は、より強力なモデルとヒントを使用して LLM により良い利益をもたらします; 3) PHP は CoT および SC と簡単に組み合わせて、パフォーマンスをさらに向上させることができます。
PHP メソッドをさらに強化するために、今後の研究では、質問段階の手動プロンプトと回答部分のプロンプト文のデザインの改善に焦点を当てることができます。さらに、回答をヒントとして扱うだけでなく、LLM が問題を再考するのに役立つ新しいヒントを特定して抽出することもできます。
以上がGPT-4 は、最も困難な数学的推論データセットの新しい SOTA を獲得し、新しいプロンプトは大規模モデルの推論能力を大幅に向上させますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7455
7455
 15
1375
52
77
11
14
9
15
1375
52
77
11
14
9

 vue.jsのストリングをオブジェクトに変換するためにどのような方法が使用されますか?
Apr 07, 2025 pm 09:39 PM
vue.jsのストリングをオブジェクトに変換するためにどのような方法が使用されますか?
Apr 07, 2025 pm 09:39 PM
vue.jsのオブジェクトに文字列を変換する場合、標準のjson文字列にはjson.parse()が推奨されます。非標準のJSON文字列の場合、文字列は正規表現を使用して処理し、フォーマットまたはデコードされたURLエンコードに従ってメソッドを削減できます。文字列形式に従って適切な方法を選択し、バグを避けるためにセキュリティとエンコードの問題に注意してください。
 インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
この記事では、MySQLデータベースの操作を紹介します。まず、MySQLWorkBenchやコマンドラインクライアントなど、MySQLクライアントをインストールする必要があります。 1. mysql-uroot-pコマンドを使用してサーバーに接続し、ルートアカウントパスワードでログインします。 2。CreatedAtaBaseを使用してデータベースを作成し、データベースを選択します。 3. createTableを使用してテーブルを作成し、フィールドとデータ型を定義します。 4. INSERTINTOを使用してデータを挿入し、データをクエリし、更新することでデータを更新し、削除してデータを削除します。これらの手順を習得することによってのみ、一般的な問題に対処することを学び、データベースのパフォーマンスを最適化することでMySQLを効率的に使用できます。
 MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLの起動が失敗する理由はたくさんあり、エラーログをチェックすることで診断できます。一般的な原因には、ポートの競合(ポート占有率をチェックして構成の変更)、許可の問題(ユーザー許可を実行するサービスを確認)、構成ファイルエラー(パラメーター設定のチェック)、データディレクトリの破損(テーブルスペースの復元)、INNODBテーブルスペースの問題(IBDATA1ファイルのチェック)、プラグインロード障害(エラーログのチェック)が含まれます。問題を解決するときは、エラーログに基づいてそれらを分析し、問題の根本原因を見つけ、問題を防ぐために定期的にデータをバックアップする習慣を開発する必要があります。
 vue.js文字列タイプの配列をオブジェクトの配列に変換する方法は?
Apr 07, 2025 pm 09:36 PM
vue.js文字列タイプの配列をオブジェクトの配列に変換する方法は?
Apr 07, 2025 pm 09:36 PM
概要:Vue.js文字列配列をオブジェクト配列に変換するための次の方法があります。基本方法:定期的なフォーマットデータに合わせてマップ関数を使用します。高度なゲームプレイ:正規表現を使用すると、複雑な形式を処理できますが、慎重に記述して考慮する必要があります。パフォーマンスの最適化:大量のデータを考慮すると、非同期操作または効率的なデータ処理ライブラリを使用できます。ベストプラクティス:コードスタイルをクリアし、意味のある変数名とコメントを使用して、コードを簡潔に保ちます。
 Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
700万のレコードを効率的に処理し、地理空間技術を使用したインタラクティブマップを作成します。この記事では、LaravelとMySQLを使用して700万を超えるレコードを効率的に処理し、それらをインタラクティブなマップの視覚化に変換する方法について説明します。最初の課題プロジェクトの要件:MySQLデータベースに700万のレコードを使用して貴重な洞察を抽出します。多くの人は最初に言語をプログラミングすることを検討しますが、データベース自体を無視します。ニーズを満たすことができますか?データ移行または構造調整は必要ですか? MySQLはこのような大きなデータ負荷に耐えることができますか?予備分析:キーフィルターとプロパティを特定する必要があります。分析後、ソリューションに関連している属性はわずかであることがわかりました。フィルターの実現可能性を確認し、検索を最適化するためにいくつかの制限を設定しました。都市に基づくマップ検索
 Vue Axiosのタイムアウトを設定する方法
Apr 07, 2025 pm 10:03 PM
Vue Axiosのタイムアウトを設定する方法
Apr 07, 2025 pm 10:03 PM
Vue axiosのタイムアウトを設定するために、Axiosインスタンスを作成してタイムアウトオプションを指定できます。グローバル設定:Vue.Prototype。$ axios = axios.create({Timeout:5000});単一のリクエストで:this。$ axios.get( '/api/users'、{timeout:10000})。
 MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLパフォーマンスの最適化は、インストール構成、インデックス作成、クエリの最適化、監視、チューニングの3つの側面から開始する必要があります。 1。インストール後、INNODB_BUFFER_POOL_SIZEパラメーターやclose query_cache_sizeなど、サーバーの構成に従ってmy.cnfファイルを調整する必要があります。 2。過度のインデックスを回避するための適切なインデックスを作成し、説明コマンドを使用して実行計画を分析するなど、クエリステートメントを最適化します。 3. MySQL独自の監視ツール(ShowProcessList、ShowStatus)を使用して、データベースの健康を監視し、定期的にデータベースをバックアップして整理します。これらの手順を継続的に最適化することによってのみ、MySQLデータベースのパフォーマンスを改善できます。
 リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニアの求人事業者:サークル場所:リモートオフィスジョブタイプ:フルタイム給与:$ 130,000- $ 140,000職務記述書サークルモバイルアプリケーションとパブリックAPI関連機能の研究開発に参加します。ソフトウェア開発ライフサイクル全体をカバーします。主な責任は、RubyonRailsに基づいて独立して開発作業を完了し、React/Redux/Relay Front-Endチームと協力しています。 Webアプリケーションのコア機能と改善を構築し、機能設計プロセス全体でデザイナーとリーダーシップと緊密に連携します。肯定的な開発プロセスを促進し、反復速度を優先します。 6年以上の複雑なWebアプリケーションバックエンドが必要です
