

とんでもない!最新の研究: 中国人が書いた英語論文の 61% が ChatGPT 検出器によって AI によって生成されたものと判断される

ChatGPT が普及してから、その使用方法は非常にたくさんあります。
これを人生のアドバイスを求めるために使用する人もいれば、単に検索エンジンとして使用する人も、論文を書くために使用する人もいます。
この論文は...書くのが楽しくありません。
米国の一部の大学は、学生が ChatGPT を使用して宿題を書くことを禁止し、また、学生が提出した論文が GPT によって生成されたかどうかを識別するためのソフトウェアを多数開発しました。
#ここで問題が発生しました。
誰かの論文はもともと下手に書かれていましたが、その文章を判定したAIはそれが同僚によって書かれたものだと判断しました。
さらに興味深いのは、中国人が書いた英語論文がAIによって生成されたものと判定される確率は61%にも上ることです。

非ネイティブスピーカーには価値がありませんか?
現在、生成言語モデルは急速に発展しており、実際にデジタル コミュニケーションに大きな進歩をもたらしています。しかし、虐待は本当にたくさんあります。
研究者たちは、AI と人間が生成したコンテンツを区別するために多くの検出方法を提案してきましたが、これらの検出方法の公平性と安定性はまだ改善の必要があります。
これを行うために、研究者らは、英語を母国語とする著者および英語を母国語としない著者によって書かれた作品を使用して、広く使用されているいくつかの GPT 検出器のパフォーマンスを評価しました。
研究結果によると、これらの検出器は、非ネイティブ スピーカーによって書かれたサンプルは AI によって生成されたものであると常に誤って判断されますが、ネイティブ スピーカーによって書かれたサンプルは基本的に正確に識別できます。
さらに、研究者らは、いくつかの簡単な戦略を使用してこのバイアスを軽減し、GPT 検出器を効果的にバイパスできることを実証しました。 ############これはどういう意味ですか?これは、GPT 検出器が言語スキルがあまり高くない著者を見下していることを示しており、非常に迷惑です。
AIが本物の人間かどうかを判定するあのゲームを思わずにはいられません、相手が本物の人間だけどAIだと推測した場合、システムは
複雑さが足りない = AI 世代?
研究者らは、中国の教育フォーラムから 91 件の TOEFL エッセイと、7 つの広く使用されている GPT 検出器を検出するためのヒューレット財団のデータセットからアメリカの 8 年生が書いた 88 件のエッセイを入手しました。
#グラフ内のパーセンテージは、「誤った判断」の割合を表しています。つまり、人間によって書かれたものですが、検出ソフトウェアは AI によって生成されたものであると考えます。
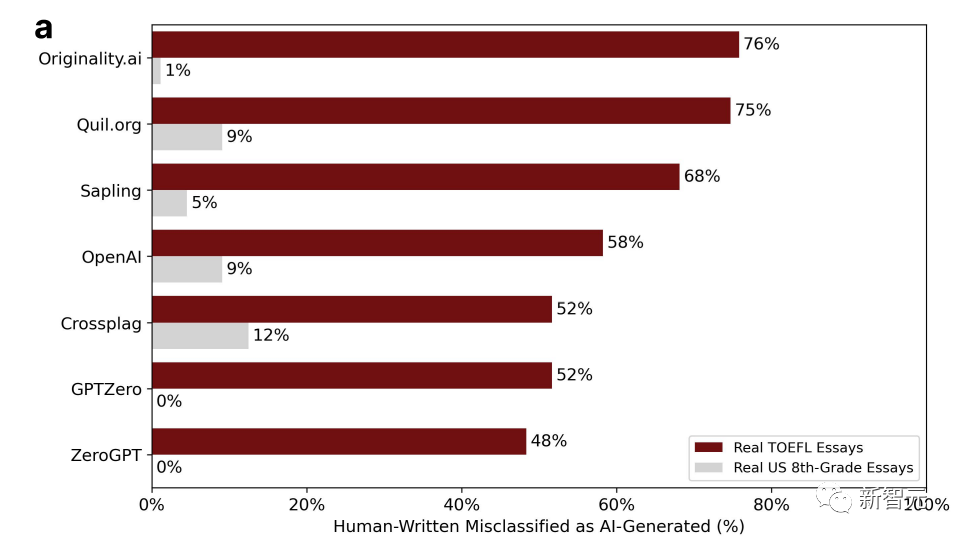
7 つの検出器の中で、米国の 8 年生が書いた作文で誤判定される確率が最も高いのはわずか 12% であり、誤判定がゼロの GPT が 2 つあります。
中国のフォーラムで TOEFL エッセイが誤判定される確率は半分以上で、最も高い誤判定確率は 76% に達することがあります。
91 件の TOEFL エッセイのうち 18 件は、7 つの GPT 検出器すべてによって AI によって生成されたと満場一致でみなされましたが、91 件のエッセイのうち 89 件は、少なくとも 1 つの GPT 検出器によって誤って生成されたと判断されました。
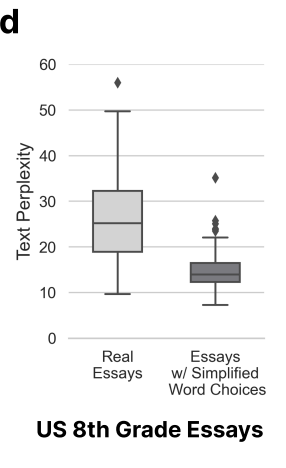
上の図から、7 つの GPT すべてで誤判定された TOEFL エッセイの複雑さは低いことがわかります (複雑さ)は他の論文に比べて大幅に低いです。
これは、冒頭の結論を裏付けるものです。GPT 検出器は、言語表現能力が限られた著者に対して一定の偏見を持ちます。
したがって、研究者らは、GPT 検出器は非母語話者によって書かれた記事をより多く読み取るべきであり、より多くのサンプルを使用することでのみバイアスを除去できると考えています。
次に、研究者らは、言語を豊かにし、ネイティブ スピーカーの単語使用習慣を模倣するために、非ネイティブ スピーカーが書いた TOEFL エッセイを ChatGPT に投入しました。
同時に、対照グループとして、アメリカの 8 年生の子供たちが書いた作文も ChatGPT に投入され、言語は非ネイティブの文章の特徴を模倣するように簡略化されました。スピーカー。下の写真は修正後の新たな判定結果です。
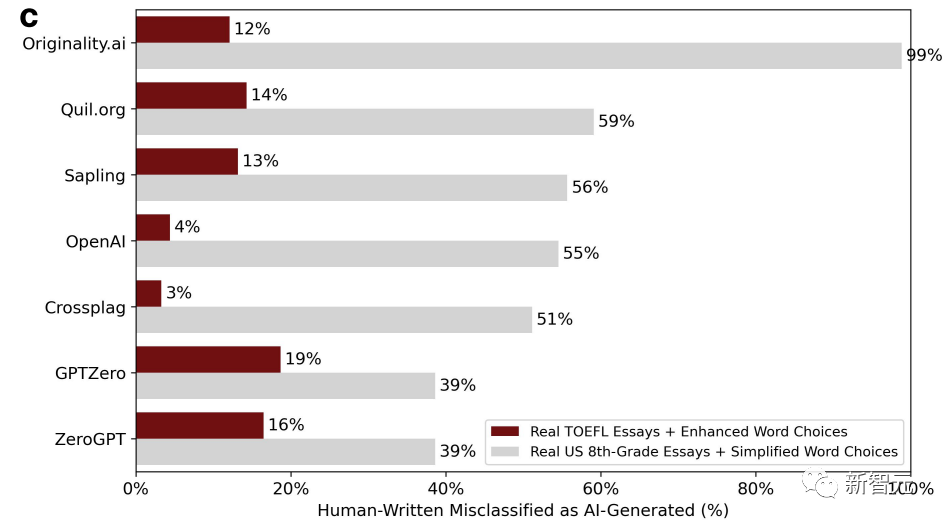
状況は劇的に変化し、言語を豊かにする TOEFL エッセイの誤判定率が急減したことがわかります。 、最低は 3%、最高は 19% です。以前の誤検知率とは異なり、基本的に半分以上でした。
それどころか、8 年生の子供たちが書いた作文の偽陽性率は急増しており、偽陽性率が 99% という高い GPT 検出器さえあります。基本的にすべてのエラー。
記事の複雑さの変数が変化したためです。
#研究者らは、非母語話者によって書かれたものは本物ではなく、複雑さが低く、誤解されやすいという結論に達しました。 。
これは技術的な問題にもつながりますが、価値の問題にもつながります。 AI と人間のどちらが作成者であるかを判断するために複雑さを利用することは、合理的で包括的かつ厳密です。
#結果は明らかにそうではありません。
複雑さを基準として使用すると、非母語話者は非母語話者であるという理由で大きな損失を被ることになります(ナンセンス)。
AI ポリッシュ = 人間が書いたもの? ?研究者らは、言語の多様性を高めることで、非母語話者に対する偏見を軽減できるだけでなく、GPT で生成されたコンテンツが GPT 検出器をバイパスできるようになると考えています。
この点を証明するために、研究者らは、2022年から2023年にアメリカの大学に申請された入学エッセイのトピックを選択し、ChatGPT-3.5に入力し、合計31の偽エッセイを生成しました。 。
GPT 検出器は最初は非常に効果的でしたが、2 回目では効果がありませんでした。これは、第 2 ラウンドで研究者がこれらの論文を ChatGPT に投入し、テキストの品質を向上させるために文学的な言語を使用して洗練したためです。
その結果、GPT 検出器の精度は 100% から 0% に低下しました。以下に示すように:
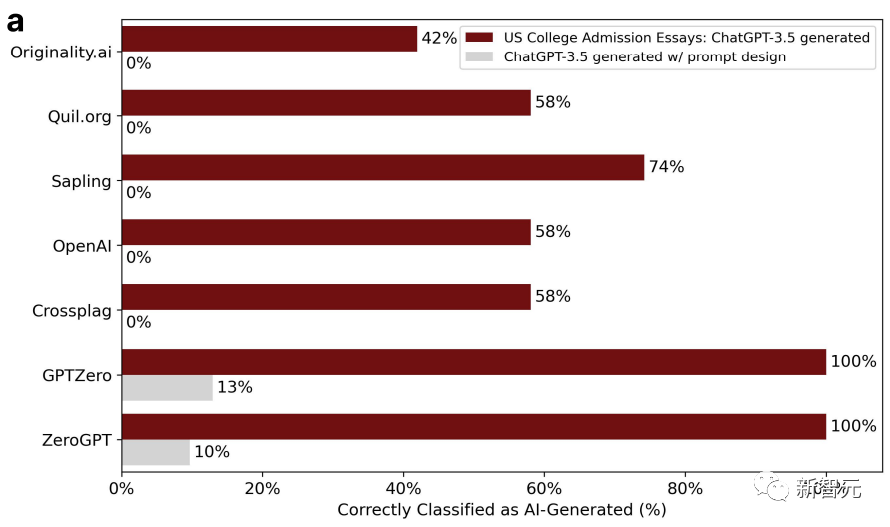
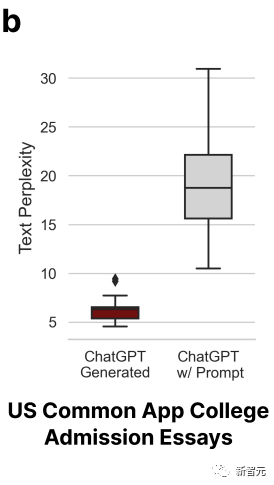
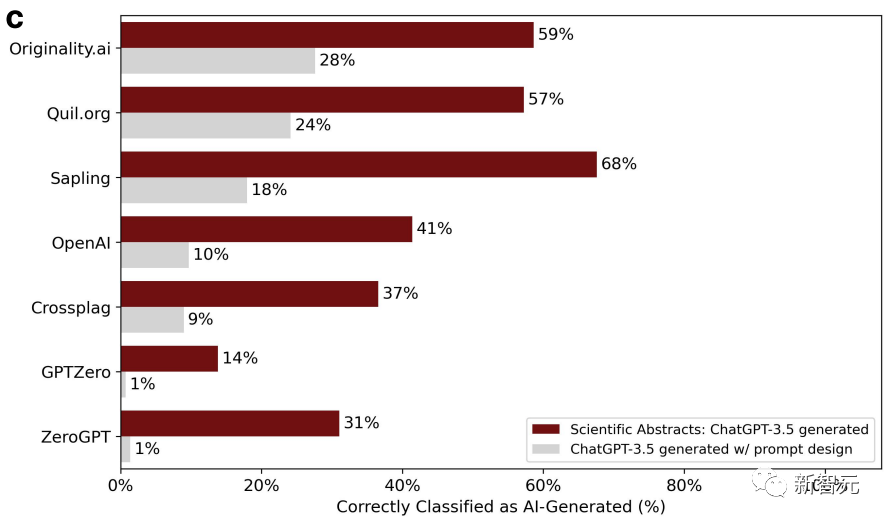
研究者らは、洗練された論文は誤判定されやすく、AI によって生成されたものであると改めて結論付けました。
GPT検出器?まだまだ練習不足です
要するに、総合的に見て、さまざまな GPT 検出器は依然として AI 生成とデータ間の関係を捉えることができていないようです。人間の文章、それらの最も本質的な違いです。
人々の文章も 3 つ、6 つ、または 9 つのレベルに分かれており、複雑さだけで判断するのはあまり合理的ではありません。
バイアス要因はさておき、テクノロジー自体にも改善が必要です。
以上がとんでもない!最新の研究: 中国人が書いた英語論文の 61% が ChatGPT 検出器によって AI によって生成されたものと判断されるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7552
7552
 15
1382
52
83
11
22
95
15
1382
52
83
11
22
95

 Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centos Shutdownコマンドはシャットダウンし、構文はシャットダウン[オプション]時間[情報]です。オプションは次のとおりです。-hシステムをすぐに停止します。 -pシャットダウン後に電源をオフにします。 -r再起動; -t待機時間。時間は、即時(現在)、数分(分)、または特定の時間(HH:mm)として指定できます。追加の情報をシステムメッセージに表示できます。
 Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosシステムの下でのGitlabのバックアップと回復ポリシーデータセキュリティと回復可能性を確保するために、Gitlab on Centosはさまざまなバックアップ方法を提供します。この記事では、いくつかの一般的なバックアップ方法、構成パラメーター、リカバリプロセスを詳細に紹介し、完全なGitLabバックアップと回復戦略を確立するのに役立ちます。 1.手動バックアップGitlab-RakeGitlabを使用:バックアップ:コマンドを作成して、マニュアルバックアップを実行します。このコマンドは、gitlabリポジトリ、データベース、ユーザー、ユーザーグループ、キー、アクセスなどのキー情報をバックアップします。デフォルトのバックアップファイルは、/var/opt/gitlab/backupsディレクトリに保存されます。 /etc /gitlabを変更できます
 CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CENTOSシステムでHDFS構成をチェックするための完全なガイドこの記事では、CENTOSシステム上のHDFSの構成と実行ステータスを効果的に確認する方法をガイドします。次の手順は、HDFSのセットアップと操作を完全に理解するのに役立ちます。 Hadoop環境変数を確認します。最初に、Hadoop環境変数が正しく設定されていることを確認してください。端末では、次のコマンドを実行して、Hadoopが正しくインストールおよび構成されていることを確認します。HDFS構成をチェックするHDFSファイル:HDFSのコア構成ファイルは/etc/hadoop/conf/ディレクトリにあります。使用
 CentosでのZookeeperのパフォーマンスを調整する方法は何ですか
Apr 14, 2025 pm 03:18 PM
CentosでのZookeeperのパフォーマンスを調整する方法は何ですか
Apr 14, 2025 pm 03:18 PM
CENTOSでのZookeeperパフォーマンスチューニングは、ハードウェア構成、オペレーティングシステムの最適化、構成パラメーターの調整、監視、メンテナンスなど、複数の側面から開始できます。特定のチューニング方法を次に示します。SSDはハードウェア構成に推奨されます。ZookeeperのデータはDISKに書き込まれます。十分なメモリ:頻繁なディスクの読み取りと書き込みを避けるために、Zookeeperに十分なメモリリソースを割り当てます。マルチコアCPU:マルチコアCPUを使用して、Zookeeperが並行して処理できるようにします。
 CentosでPytorchモデルを訓練する方法
Apr 14, 2025 pm 03:03 PM
CentosでPytorchモデルを訓練する方法
Apr 14, 2025 pm 03:03 PM
CentOSシステムでのPytorchモデルの効率的なトレーニングには手順が必要であり、この記事では詳細なガイドが提供されます。 1。環境の準備:Pythonおよび依存関係のインストール:Centosシステムは通常Pythonをプリインストールしますが、バージョンは古い場合があります。 YumまたはDNFを使用してPython 3をインストールし、PIP:sudoyumupdatepython3(またはsudodnfupdatepython3)、pip3install-upgradepipをアップグレードすることをお勧めします。 cuda and cudnn(GPU加速):nvidiagpuを使用する場合は、cudatoolをインストールする必要があります
 CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
Pytorch GPUアクセラレーションを有効にすることで、CentOSシステムでは、PytorchのCUDA、CUDNN、およびGPUバージョンのインストールが必要です。次の手順では、プロセスをガイドします。CUDAおよびCUDNNのインストールでは、CUDAバージョンの互換性が決定されます。NVIDIA-SMIコマンドを使用して、NVIDIAグラフィックスカードでサポートされているCUDAバージョンを表示します。たとえば、MX450グラフィックカードはCUDA11.1以上をサポートする場合があります。 cudatoolkitのダウンロードとインストール:nvidiacudatoolkitの公式Webサイトにアクセスし、グラフィックカードでサポートされている最高のCUDAバージョンに従って、対応するバージョンをダウンロードしてインストールします。 cudnnライブラリをインストールする:
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
DockerはLinuxカーネル機能を使用して、効率的で孤立したアプリケーションランニング環境を提供します。その作業原則は次のとおりです。1。ミラーは、アプリケーションを実行するために必要なすべてを含む読み取り専用テンプレートとして使用されます。 2。ユニオンファイルシステム(UnionFS)は、違いを保存するだけで、スペースを節約し、高速化する複数のファイルシステムをスタックします。 3.デーモンはミラーとコンテナを管理し、クライアントはそれらをインタラクションに使用します。 4。名前空間とcgroupsは、コンテナの分離とリソースの制限を実装します。 5.複数のネットワークモードは、コンテナの相互接続をサポートします。これらのコア概念を理解することによってのみ、Dockerをよりよく利用できます。
 Centosの下でPytorchバージョンを選択する方法
Apr 14, 2025 pm 02:51 PM
Centosの下でPytorchバージョンを選択する方法
Apr 14, 2025 pm 02:51 PM
CentOSでPytorchバージョンを選択する場合、次の重要な要素を考慮する必要があります。1。CUDAバージョンの互換性GPUサポート:NVIDIA GPUを使用してGPU加速度を活用したい場合は、対応するCUDAバージョンをサポートするPytorchを選択する必要があります。 NVIDIA-SMIコマンドを実行することでサポートされているCUDAバージョンを表示できます。 CPUバージョン:GPUをお持ちでない場合、またはGPUを使用したくない場合は、PytorchのCPUバージョンを選択できます。 2。PythonバージョンPytorch
