
hadoop namenode -format
start-yarn.sh
start-dfs.sh
start-yarn.sh

Linux に Hadoop をインストールする方法

1: JDK のインストール
1. 次のコマンドを実行して、JDK1.8 インストール パッケージをダウンロードします。
wget --no-check-certificate https://repo.huaweicloud.com/java/jdk/8u151-b12/jdk-8u151-linux-x64.tar.gz
2. 以下のコマンドを実行して、ダウンロードした JDK1.8 インストールパッケージを解凍します。
tar -zxvf jdk-8u151-linux-x64.tar.gz
3. JDK パッケージを移動し、名前を変更します。
mv jdk1.8.0_151/ /usr/java8
4. Java 環境変数を設定します。
echo 'export JAVA_HOME=/usr/java8' >> /etc/profile echo 'export PATH=$PATH:$JAVA_HOME/bin' >> /etc/profile source /etc/profile
5. Java が正常にインストールされているかどうかを確認します。
java -version
2: Hadoop のインストール
注: Hadoop インストール パッケージをダウンロードするには、Huawei ソースを選択できます (速度は中程度で許容範囲内、フル バージョンに重点が置かれています)。 、清華大学のソース (3.0.0 以降。バージョンのダウンロード速度が遅すぎてバージョンが少ない)、北京外国語大学のソース (ダウンロード速度は非常に速いですが、バージョンが少ない) - 私は個人的にテストしました
1. 次のコマンドを実行して、Hadoop インストール バッグをダウンロードします。
wget --no-check-certificate https://repo.huaweicloud.com/apache/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz
2. 次のコマンドを実行して、Hadoop インストール パッケージを /opt/hadoop に解凍します。
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/ mv /opt/hadoop-3.1.3 /opt/hadoop
3. 次のコマンドを実行して、Hadoop 環境変数を設定します。
echo 'export HADOOP_HOME=/opt/hadoop/' >> /etc/profile echo 'export PATH=$PATH:$HADOOP_HOME/bin' >> /etc/profile echo 'export PATH=$PATH:$HADOOP_HOME/sbin' >> /etc/profile source /etc/profile
4. 次のコマンドを実行して、設定ファイルyarn-env.shおよびhadoop-env.shを変更します。
echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/yarn-env.sh echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/hadoop-env.sh
5. 次のコマンドを実行して、Hadoop が正常にインストールされているかどうかをテストします。
hadoop version
バージョン情報が返されれば、インストールは成功です。
3: Hadoop の構成
1. Hadoop 構成ファイル core-site.xml を変更します。
a. 次のコマンドを実行して編集ページに入ります。
vim /opt/hadoop/etc/hadoop/core-site.xml
b. i と入力して編集モードに入ります。 c. 次のコンテンツを <configuration></configuration> ノードに挿入します。
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop/tmp</value>
<description>location to store temporary files</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>d. Esc キーを押して編集モードを終了し、「wq」と入力して保存して終了します。
2. Hadoop 構成ファイル hdfs-site.xml を変更します。
a. 次のコマンドを実行して編集ページに入ります。
vim /opt/hadoop/etc/hadoop/hdfs-site.xml
b. i と入力して編集モードに入ります。 c. 次のコンテンツを <configuration></configuration> ノードに挿入します。
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop/tmp/dfs/data</value>
</property>d. Esc キーを押して編集モードを終了し、「wq」と入力して保存して終了します。
4: SSH パスワードなしログインの設定
1. 次のコマンドを実行して、公開キーと秘密キーを作成します。
ssh-keygen -t rsa
2. 次のコマンドを実行して、authorized_keys ファイルに公開キーを追加します。
cd ~ cd .ssh cat id_rsa.pub >> authorized_keys
エラーが報告された場合は、次の操作を実行してから、上記の 2 つのコマンドを再実行します。エラーが報告されない場合は、直接手順 5 に進みます。 #環境変数に次のコマンドを入力します。 次の構成を追加します。
vi /etc/profile
export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root
source /etc/profile
5: Hadoop を開始します1.
次のコマンドを実行して、namenode を初期化します。 hadoop namenode -format
ログイン後にコピー2.
hadoop namenode -format
以下のコマンドを順番に実行してHadoopを起動します。 start-dfs.sh
ログイン後にコピーY/N が選択されている場合は Y を選択し、それ以外の場合は Enter を直接押してくださいstart-yarn.sh
ログイン後にコピー
start-dfs.sh
start-yarn.sh
3.
起動に成功したら、次のコマンドを実行します。 、正常に開始されたプロセスを表示します。 jps
ログイン後にコピー
jps
通常は 6 つのプロセスがあります;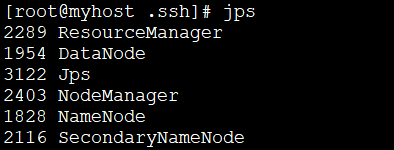
4.
ブラウザを開いて、 http://:8088 および http://:50070 にアクセスし、以下のインターフェイスが表示されれば、Hadoop 擬似分散環境が完成しています。
 #
#
以上がLinux に Hadoop をインストールする方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7469
7469
 15
1376
52
77
11
19
29
15
1376
52
77
11
19
29


 マルチスレッドをC言語で実装する4つの方法
Apr 03, 2025 pm 03:00 PM
マルチスレッドをC言語で実装する4つの方法
Apr 03, 2025 pm 03:00 PM
言語のマルチスレッドは、プログラムの効率を大幅に改善できます。 C言語でマルチスレッドを実装する4つの主な方法があります。独立したプロセスを作成します。独立して実行される複数のプロセスを作成します。各プロセスには独自のメモリスペースがあります。擬似マルチスレッド:同じメモリ空間を共有して交互に実行するプロセスで複数の実行ストリームを作成します。マルチスレッドライブラリ:pthreadsなどのマルチスレッドライブラリを使用して、スレッドを作成および管理し、リッチスレッド操作機能を提供します。 Coroutine:タスクを小さなサブタスクに分割し、順番に実行する軽量のマルチスレッド実装。
 web.xmlを開く方法
Apr 03, 2025 am 06:51 AM
web.xmlを開く方法
Apr 03, 2025 am 06:51 AM
web.xmlファイルを開くには、次の方法を使用できます。テキストエディター(メモ帳やテキストエディットなど)を使用して、統合開発環境(EclipseやNetBeansなど)を使用してコマンドを編集できます(Windows:Notepad web.xml; Mac/Linux:Open -A Textedit Web.xml)
 PythonインタープリターはLinuxシステムで削除できますか?
Apr 02, 2025 am 07:00 AM
PythonインタープリターはLinuxシステムで削除できますか?
Apr 02, 2025 am 07:00 AM
Linux Systemsに付属するPythonインタープリターを削除する問題に関して、多くのLinuxディストリビューションは、インストール時にPythonインタープリターをプリインストールし、パッケージマネージャーを使用しません...
 Linuxは何に最適なものですか?
Apr 03, 2025 am 12:11 AM
Linuxは何に最適なものですか?
Apr 03, 2025 am 12:11 AM
Linuxは、サーバー管理、組み込みシステム、デスクトップ環境として最適です。 1)サーバー管理では、LinuxはWebサイト、データベース、アプリケーションをホストするために使用され、安定性と信頼性を提供します。 2)組み込みシステムでは、Linuxは柔軟性と安定性のため、スマートホームおよび自動車電子システムで広く使用されています。 3)デスクトップ環境では、Linuxは豊富なアプリケーションと効率的なパフォーマンスを提供します。
 Debian Hadoopの互換性はどうですか
Apr 02, 2025 am 08:42 AM
Debian Hadoopの互換性はどうですか
Apr 02, 2025 am 08:42 AM
DebianLinuxは、その安定性とセキュリティで知られており、サーバー、開発、デスクトップ環境で広く使用されています。現在、DebianとHadoopとの直接的な互換性に関する公式の指示が不足していますが、この記事では、DebianシステムにHadoopを展開する方法について説明します。 Debianシステムの要件:Hadoop構成を開始する前に、DebianシステムがHadoopの最小動作要件を満たしていることを確認してください。これには、必要なJavaランタイム環境(JRE)とHadoopパッケージのインストールが含まれます。 Hadoop展開手順:Hadoopをダウンロードして解凍:公式ApachehadoopのWebサイトから必要なHadoopバージョンをダウンロードして解決します
 GOを使用してOracleデータベースに接続するときにOracleクライアントをインストールする必要がありますか?
Apr 02, 2025 pm 03:48 PM
GOを使用してOracleデータベースに接続するときにOracleクライアントをインストールする必要がありますか?
Apr 02, 2025 pm 03:48 PM
GOを使用してOracleデータベースに接続するときにOracleクライアントをインストールする必要がありますか? GOで開発するとき、Oracleデータベースに接続することは一般的な要件です...
 Debian文字列は、複数のブラウザと互換性があります
Apr 02, 2025 am 08:30 AM
Debian文字列は、複数のブラウザと互換性があります
Apr 02, 2025 am 08:30 AM
「DebianStrings」は標準的な用語ではなく、その特定の意味はまだ不明です。この記事は、ブラウザの互換性について直接コメントすることはできません。ただし、「DebianStrings」がDebianシステムで実行されているWebアプリケーションを指す場合、そのブラウザの互換性はアプリケーション自体の技術アーキテクチャに依存します。ほとんどの最新のWebアプリケーションは、クロスブラウザーの互換性に取り組んでいます。これは、次のWeb標準と、適切に互換性のあるフロントエンドテクノロジー(HTML、CSS、JavaScriptなど)およびバックエンドテクノロジー(PHP、Python、Node.jsなど)を使用することに依存しています。アプリケーションが複数のブラウザと互換性があることを確認するには、開発者がクロスブラウザーテストを実施し、応答性を使用する必要があることがよくあります
