

この記事では株式取引を例に説明します。 AI モデルを使用して、翌日の株価が上昇するか下落するかを予測します。これに関連して、3 つの分類アルゴリズム、XGBoost、ランダム フォレスト、ロジスティック分類器が比較されます。この記事のもう 1 つの焦点はデータの準備です。モデルがデータを処理できるようにするには、データをどのように変換する必要がありますか。

この記事では、CRISP-DM プロセス モデルの手順に従い、構造化されたアプローチを使用してビジネス ケースを解決します。 CRISP-DM は潜在分析で広く使用されている手法であり、データ サイエンス プロジェクトの構築でもよく使用されます。
もう 1 つは、Python パッケージ openbb を使用することです。このパッケージには金融分野のデータ ソースがいくつか含まれており、非常に使いやすいです。
最初のステップは、必要なライブラリをインストールすることです:
<code>pip install pandas numpy “openbb[all]” swifter scikit-learn</code>
まず、解決したい問題を理解する必要があります。この例では、問題は次のとおりです。次のように定義されます:
<code>预测股票代码 AAPL 的股价第二天会上涨还是下跌。</code>
次に、どのような種類の機械学習モデルを検討する必要があるかという問題があります。翌日株価が上がるか下がるかを予測したいと考えています。したがって、ここで扱っているのは、翌日に株価が上昇するか (値が 1)、下落するか (値が 0) を予測する二項分類問題です。分類問題では、クラスを予測します。私たちの場合、それはクラス 0 と 1 のバイナリ分類です。
データ理解フェーズでは、データ セットの特定、収集、分析に焦点を当てます。最初のステップとして、Apple の株価データをダウンロードします。 openbb を使用してこれを行う方法は次のとおりです。
<code>data = openbb.stocks.load(symbol = 'AAPL',start_date = '2023-01-01',end_date = '2023-04-01',monthly = False) data</code>
このコードは、2023-01-01 から 2023-04-01 までのデータをダウンロードします。ダウンロードされたデータには、次の情報が含まれています。
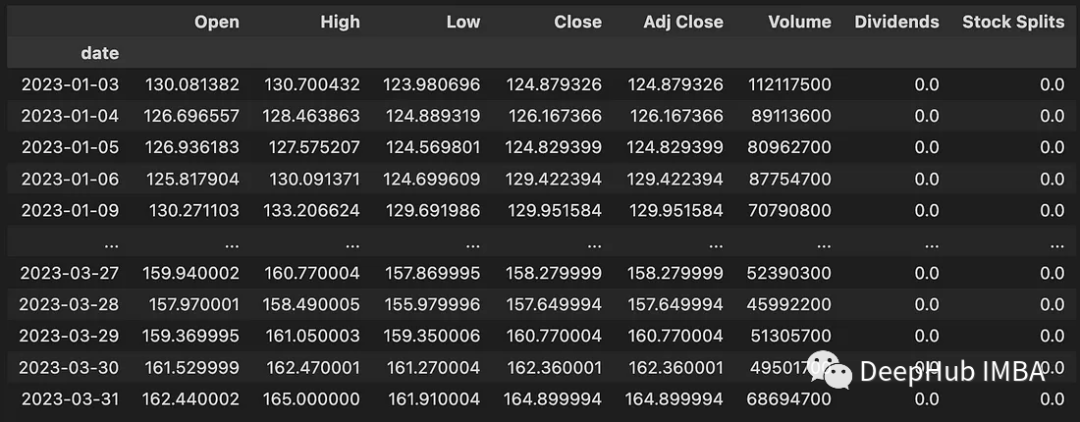
データをダウンロードしましたが、データは分類モデルのモデリングにはまだ適していません。したがって、モデリングのためにデータを準備する必要があります。そのため、データをダウンロードしてモデリング用に変換する機能を開発する必要があります。次のコードは、この関数を示しています。
<code>def get_training_data(symbol, start_date, end_date, monthly_bool=True, lookback=10): data = openbb.stocks.load( symbol = symbol, start_date = start_date, end_date = end_date, monthly = monthly_bool) data = get_label(data) data_up_down = data['up_down'].to_numpy() training_data = get_sequence_data(data_up_down, lookback) return training_data</code>
ここに含まれる最初の関数は get_label() です。
<code>def encoding(n): if n > 0: return 1 else: return 0 def get_label(data): data['Delta'] = data['Close'] - data['Open'] data['up_down'] = data['Delta'].swifter.apply(lambda d: encoding(d)) return data</code>
彼の主な仕事は、終値と始値の差を計算することです。株価が上昇した日をすべて 1 としてマークし、株価が下落した日をすべて 0 としてマークします。追加の up_down 列には、特定の日に株価が上昇したか下落したかが含まれます。 swifter はマルチコア サポートを提供するため、ここでは pandas apply() の代わりに swifter.apply() 関数が使用されます。
2 番目の関数は get_sequence_data() です。パラメーター ルックバックは、過去の何日間を予測に含めるかを指定します。 get_sequence_data() コードは次のとおりです。
<code>def get_sequence_data(data_up_down, lookback): shape = (data_up_down.shape[0] - lookback + 1, lookback) strides = data_up_down.strides + (data_up_down.strides[-1],) return np.lib.stride_tricks.as_strided(data_up_down, shape=shape, strides=strides)</code>
この関数は、data_up_down と lookback の 2 つのパラメータを受け入れます。ルックバック引数によって決定される、指定されたウィンドウ サイズを持つ data_up_down 配列のスライディング ウィンドウ ビューを表す新しい NumPy 配列を返します。この関数がどのように機能するかを説明するために、小さな例を見てみましょう。
<code>get_sequence_data(np.array([1, 2, 3, 4, 5, 6]), 3)</code>
結果は次のとおりです:
<code>array([[1, 2, 3],[2, 3, 4],[3, 4, 5],[4, 5, 6]])</code>
以下では、Apple 株のデータをダウンロードし、モデリング用に変換します。 10 日間のルックバック ウィンドウを使用します。
<code>data = get_training_data(symbol = 'AAPL', start_date = '2023-01-01', end_date = '2023-04-01', monthly_bool = False, lookback=10) pd.DataFrame(data).to_csv("data/data_aapl.csv")</code>データが準備されたので、モデルのモデリングと評価を開始します。
データを読み取り、テスト データとトレーニング データを生成します。
<code>data = pandas.read_csv("./data/data_aapl.csv") X=data.iloc[:,:-1] Y=data.iloc[:,-1] X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.33, random_state=4284, stratify=Y)</code>ロジスティック回帰:
この分類器は線形ベースのモデルであり、ベースライン モデルとしてよく使用されます。 scikit-learn の実装を使用します。
<code>model_lr = LogisticRegression(random_state = 42) model_lr.fit(X_train,y_train) y_pred = model_lr.predict(X_test)</code>
XGBoost:
XGBoost は、速度とパフォーマンスを重視して設計された勾配ブースト デシジョン ツリーの実装です。これは、多くの弱ツリー分類子を順番に接続するツリー ブースティング アルゴリズムに属します。
<code>model_xgb = XGBClassifier(random_state = 42) model_xgb.fit(X_train, y_train) y_pred = model_xgb.predict(X_test)</code>
ランダム フォレスト:
ランダム フォレストは複数のデシジョン ツリーを構築します。バギング法は、相互接続された複数の学習器を学習に利用するため、アンサンブル学習の一種と呼ばれます。 「バギング」という頭字語は、ブートストラップ集約を表します。ここでも scikit-learn の実装が使用されています:
<code>model_rf = RandomForestClassifier(random_state = 42) model_rf.fit(X_train, y_train) y_pred = model_rf.predict(X_test)</code>
モデルをモデリングしてトレーニングした後、テスト データでそのパフォーマンスを評価する必要があります。メトリクスの測定には、再現率、精度、および F1 スコアが使用されます。以下の表に結果を示します。
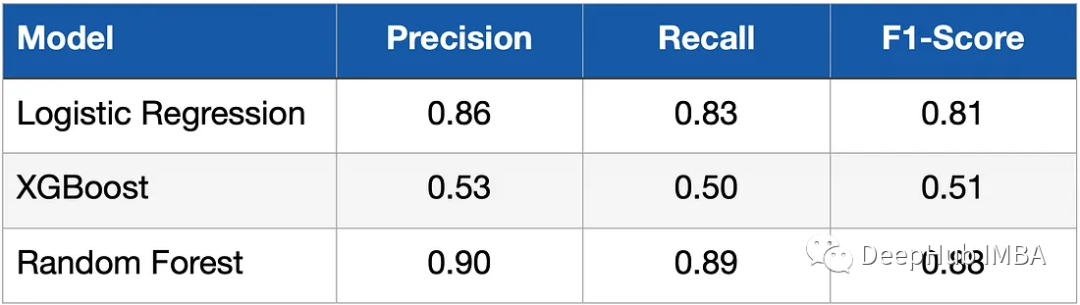
ロジスティック分類器 (ロジスティック回帰) とランダム フォレストが XGBoost モデルよりも大幅に優れた結果を達成していることがわかります。その理由は何ですか?このために?これは、データが比較的単純で、特徴の次元が数個しかなく、データの長さも非常に短く、すべてのモデルが調整されていないためです。
私たちの記事の主な目的は、株価の時系列を分類問題に変換する方法を紹介し、ウィンドウ関数を使用して時系列をシーケンスに変換する方法を示すことです。データ処理中はモデルをあまり調整する必要がないため、モデルがシンプルであるほどパフォーマンス評価に優れています。
以上が時系列を分類問題に変換するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



